 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDC-CCL: Device-Cloud Collaborative Controlled Learning for Large Vision Models
Mar 18, 2023Many large vision models have been deployed on the cloud for real-time services. Meanwhile, fresh samples are continuously generated on the served mobile device. How to leverage the device-side samples to improve the cloud-side large model becomes a practical requirement, but falls into the dilemma of no raw sample up-link and no large model down-link. Specifically, the user may opt out of sharing raw samples with the cloud due to the concern of privacy or communication overhead, while the size of some large vision models far exceeds the mobile device's runtime capacity. In this work, we propose a device-cloud collaborative controlled learning framework, called DC-CCL, enabling a cloud-side large vision model that cannot be directly deployed on the mobile device to still benefit from the device-side local samples. In particular, DC-CCL vertically splits the base model into two submodels, one large submodel for learning from the cloud-side samples and the other small submodel for learning from the device-side samples and performing device-cloud knowledge fusion. Nevertheless, on-device training of the small submodel requires the output of the cloud-side large submodel to compute the desired gradients. DC-CCL thus introduces a light-weight model to mimic the large cloud-side submodel with knowledge distillation, which can be offloaded to the mobile device to control its small submodel's optimization direction. Given the decoupling nature of two submodels in collaborative learning, DC-CCL also allows the cloud to take a pre-trained model and the mobile device to take another model with a different backbone architecture.
Kernel-Based Distributed Q-Learning: A Scalable Reinforcement Learning Approach for Dynamic Treatment Regimes
Feb 21, 2023In recent years, large amounts of electronic health records (EHRs) concerning chronic diseases, such as cancer, diabetes, and mental disease, have been collected to facilitate medical diagnosis. Modeling the dynamic properties of EHRs related to chronic diseases can be efficiently done using dynamic treatment regimes (DTRs), which are a set of sequential decision rules. While Reinforcement learning (RL) is a widely used method for creating DTRs, there is ongoing research in developing RL algorithms that can effectively handle large amounts of data. In this paper, we present a novel approach, a distributed Q-learning algorithm, for generating DTRs. The novelties of our research are as follows: 1) From a methodological perspective, we present a novel and scalable approach for generating DTRs by combining distributed learning with Q-learning. The proposed approach is specifically designed to handle large amounts of data and effectively generate DTRs. 2) From a theoretical standpoint, we provide generalization error bounds for the proposed distributed Q-learning algorithm, which are derived within the framework of statistical learning theory. These bounds quantify the relationships between sample size, prediction accuracy, and computational burden, providing insights into the performance of the algorithm. 3) From an applied perspective, we demonstrate the effectiveness of our proposed distributed Q-learning algorithm for DTRs by applying it to clinical cancer treatments. The results show that our algorithm outperforms both traditional linear Q-learning and commonly used deep Q-learning in terms of both prediction accuracy and computation cost.
Group Fairness in Non-monotone Submodular Maximization
Feb 03, 2023Maximizing a submodular function has a wide range of applications in machine learning and data mining. One such application is data summarization whose goal is to select a small set of representative and diverse data items from a large dataset. However, data items might have sensitive attributes such as race or gender, in this setting, it is important to design \emph{fairness-aware} algorithms to mitigate potential algorithmic bias that may cause over- or under- representation of particular groups. Motivated by that, we propose and study the classic non-monotone submodular maximization problem subject to novel group fairness constraints. Our goal is to select a set of items that maximizes a non-monotone submodular function, while ensuring that the number of selected items from each group is proportionate to its size, to the extent specified by the decision maker. We develop the first constant-factor approximation algorithms for this problem. We also extend the basic model to incorporate an additional global size constraint on the total number of selected items.
One-Time Model Adaptation to Heterogeneous Clients: An Intra-Client and Inter-Image Attention Design
Nov 11, 2022The mainstream workflow of image recognition applications is first training one global model on the cloud for a wide range of classes and then serving numerous clients, each with heterogeneous images from a small subset of classes to be recognized. From the cloud-client discrepancies on the range of image classes, the recognition model is desired to have strong adaptiveness, intuitively by concentrating the focus on each individual client's local dynamic class subset, while incurring negligible overhead. In this work, we propose to plug a new intra-client and inter-image attention (ICIIA) module into existing backbone recognition models, requiring only one-time cloud-based training to be client-adaptive. In particular, given a target image from a certain client, ICIIA introduces multi-head self-attention to retrieve relevant images from the client's historical unlabeled images, thereby calibrating the focus and the recognition result. Further considering that ICIIA's overhead is dominated by linear projection, we propose partitioned linear projection with feature shuffling for replacement and allow increasing the number of partitions to dramatically improve efficiency without scarifying too much accuracy. We finally evaluate ICIIA using 3 different recognition tasks with 9 backbone models over 5 representative datasets. Extensive evaluation results demonstrate the effectiveness and efficiency of ICIIA. Specifically, for ImageNet-1K with the backbone models of MobileNetV3-L and Swin-B, ICIIA can improve the testing accuracy to 83.37% (+8.11%) and 88.86% (+5.28%), while adding only 1.62% and 0.02% of FLOPs, respectively.
Worst-Case Adaptive Submodular Cover
Oct 31, 2022

In this paper, we study the adaptive submodular cover problem under the worst-case setting. This problem generalizes many previously studied problems, namely, the pool-based active learning and the stochastic submodular set cover. The input of our problem is a set of items (e.g., medical tests) and each item has a random state (e.g., the outcome of a medical test), whose realization is initially unknown. One must select an item at a fixed cost in order to observe its realization. There is an utility function which is defined over items and their states. Our goal is to sequentially select a group of items to achieve a ``goal value'' while minimizing the maximum cost across realizations (a.k.a. worst-case cost). To facilitate our study, we introduce a broad class of stochastic functions, called \emph{worst-case submodular function}. Assume the utility function is worst-case submodular, we develop a tight $(\log (Q/\eta)+1)$-approximation policy, where $Q$ is the ``goal value'' and $\eta$ is the minimum gap between $Q$ and any attainable utility value $\hat{Q}<Q$. We also study a worst-case maximum-coverage problem, whose goal is to select a group of items to maximize its worst-case utility subject to a budget constraint. This is a flipped problem of the minimum-cost-cover problem, and to solve this problem, we develop a $(1-1/e)/2$-approximation solution.
Evolution is Still Good: Theoretical Analysis of Evolutionary Algorithms on General Cover Problems
Oct 03, 2022Theoretical studies on evolutionary algorithms have developed vigorously in recent years. Many such algorithms have theoretical guarantees in both running time and approximation ratio. Some approximation mechanism seems to be inherently embedded in many evolutionary algorithms. In this paper, we identify such a relation by proposing a unified analysis framework for a generalized simple multi-objective evolutionary algorithm (GSEMO), and apply it on a minimum weight general cover problem. For a wide range of problems (including the the minimum submodular cover problem in which the submodular function is real-valued, and the minimum connected dominating set problem for which the potential function is non-submodular), GSEMO yields asymptotically tight approximation ratios in expected polynomial time.
Streaming Adaptive Submodular Maximization
Aug 17, 2022Many sequential decision making problems can be formulated as an adaptive submodular maximization problem. However, most of existing studies in this field focus on pool-based setting, where one can pick items in any order, and there have been few studies for the stream-based setting where items arrive in an arbitrary order and one must immediately decide whether to select an item or not upon its arrival. In this paper, we introduce a new class of utility functions, semi-policywise submodular functions. We develop a series of effective algorithms to maximize a semi-policywise submodular function under the stream-based setting.
Partial-Monotone Adaptive Submodular Maximization
Jul 26, 2022
Many sequential decision making problems, including pool-based active learning and adaptive viral marketing, can be formulated as an adaptive submodular maximization problem. Most of existing studies on adaptive submodular optimization focus on either monotone case or non-monotone case. Specifically, if the utility function is monotone and adaptive submodular, \cite{golovin2011adaptive} developed a greedy policy that achieves a $(1-1/e)$ approximation ratio subject to a cardinality constraint. If the utility function is non-monotone and adaptive submodular, \cite{tang2021beyond} showed that a random greedy policy achieves a $1/e$ approximation ratio subject to a cardinality constraint. In this work, we aim to generalize the above mentioned results by studying the partial-monotone adaptive submodular maximization problem. To this end, we introduce the notation of adaptive monotonicity ratio $m\in[0,1]$ to measure the degree of monotonicity of a function. Our main result is to show that a random greedy policy achieves an approximation ratio of $m(1-1/e)+(1-m)(1/e)$ if the utility function is $m$-adaptive monotone and adaptive submodular. Notably this result recovers the aforementioned $(1-1/e)$ and $1/e$ approximation ratios when $m = 0$ and $m = 1$, respectively. We further extend our results to consider a knapsack constraint. We show that a sampling-based policy achieves an approximation ratio of $(m+1)/10$ if the utility function is $m$-adaptive monotone and adaptive submodular. One important implication of our results is that even for a non-monotone utility function, we still can achieve an approximation ratio close to $(1-1/e)$ if this function is ``close'' to a monotone function. This leads to improved performance bounds for many machine learning applications whose utility functions are almost adaptive monotone.
Group Fairness in Adaptive Submodular Maximization
Jul 07, 2022In this paper, we study the classic submodular maximization problem subject to a group fairness constraint under both non-adaptive and adaptive settings. It has been shown that the utility function of many machine learning applications, including data summarization, influence maximization in social networks, and personalized recommendation, satisfies the property of submodularity. Hence, maximizing a submodular function subject to various constraints can be found at the heart of many of those applications. On a high level, submodular maximization aims to select a group of most representative items (e.g., data points). However, the design of most existing algorithms does not incorporate the fairness constraint, leading to under- or over-representation some particular groups. This motivates us to study the fair submodular maximization problem, where we aim to select a group of items to maximize a (possibly non-monotone) submodular utility function subject to a group fairness constraint. To this end, we develop the first constant-factor approximation algorithm for this problem. The design of our algorithm is robust enough to be extended to solving the submodular maximization problem under a more complicated adaptive setting. Moreover, we further extend our study to incorporating a global cardinality constraint.
A new method incorporating deep learning with shape priors for left ventricular segmentation in myocardial perfusion SPECT images
Jun 07, 2022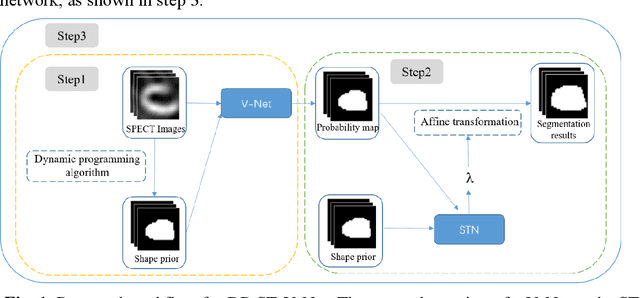


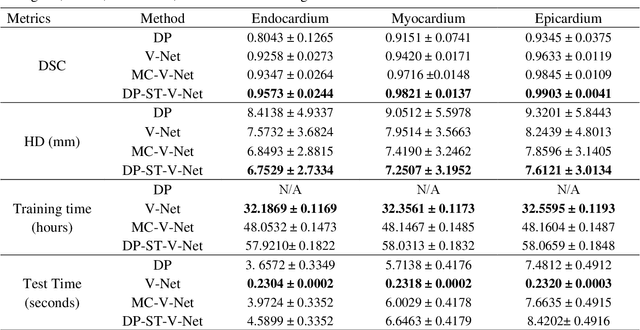
Background: The assessment of left ventricular (LV) function by myocardial perfusion SPECT (MPS) relies on accurate myocardial segmentation. The purpose of this paper is to develop and validate a new method incorporating deep learning with shape priors to accurately extract the LV myocardium for automatic measurement of LV functional parameters. Methods: A segmentation architecture that integrates a three-dimensional (3D) V-Net with a shape deformation module was developed. Using the shape priors generated by a dynamic programming (DP) algorithm, the model output was then constrained and guided during the model training for quick convergence and improved performance. A stratified 5-fold cross-validation was used to train and validate our models. Results: Results of our proposed method agree well with those from the ground truth. Our proposed model achieved a Dice similarity coefficient (DSC) of 0.9573(0.0244), 0.9821(0.0137), and 0.9903(0.0041), a Hausdorff distances (HD) of 6.7529(2.7334) mm, 7.2507(3.1952) mm, and 7.6121(3.0134) mm in extracting the endocardium, myocardium, and epicardium, respectively. Conclusion: Our proposed method achieved a high accuracy in extracting LV myocardial contours and assessing LV function.