 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFADNet++: Real-Time and Accurate Disparity Estimation with Configurable Networks
Oct 06, 2021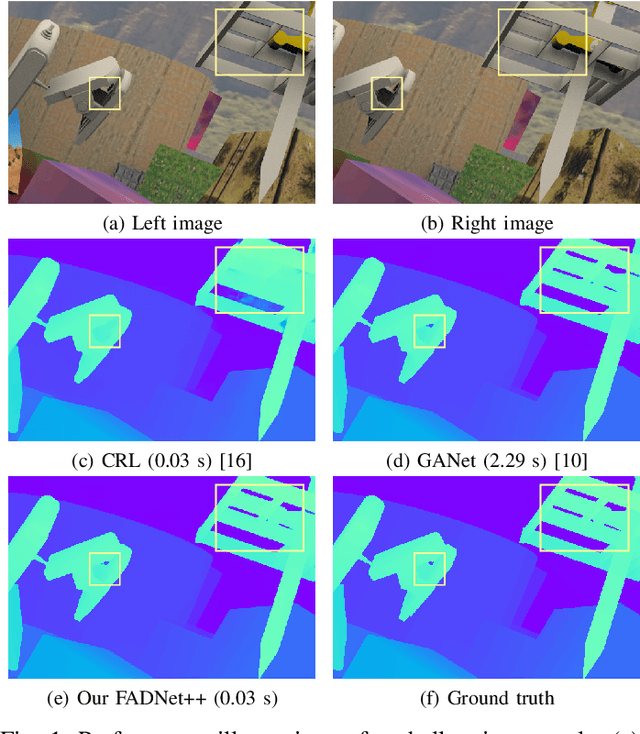
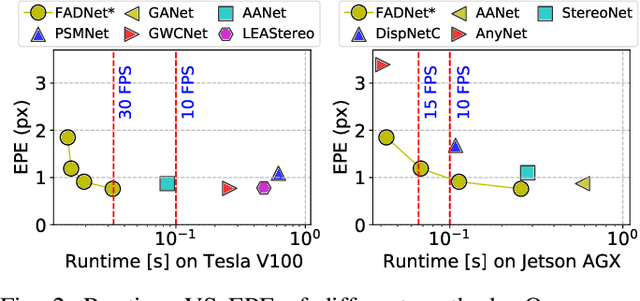
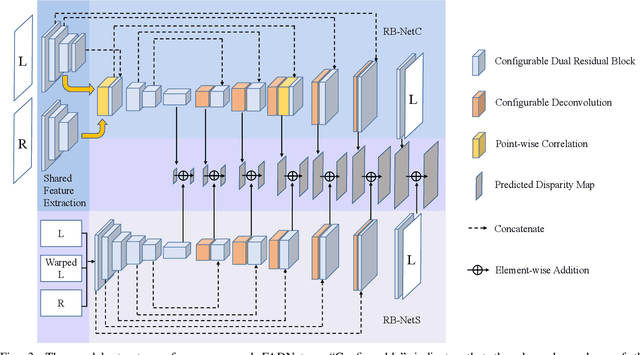
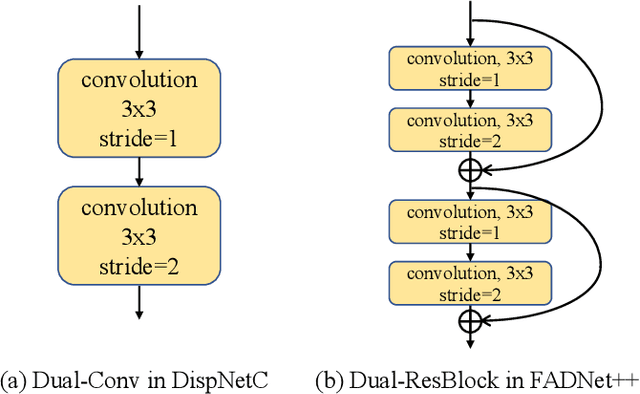
Deep neural networks (DNNs) have achieved great success in the area of computer vision. The disparity estimation problem tends to be addressed by DNNs which achieve much better prediction accuracy than traditional hand-crafted feature-based methods. However, the existing DNNs hardly serve both efficient computation and rich expression capability, which makes them difficult for deployment in real-time and high-quality applications, especially on mobile devices. To this end, we propose an efficient, accurate, and configurable deep network for disparity estimation named FADNet++. Leveraging several liberal network design and training techniques, FADNet++ can boost its accuracy with a fast model inference speed for real-time applications. Besides, it enables users to easily configure different sizes of models for balancing accuracy and inference efficiency. We conduct extensive experiments to demonstrate the effectiveness of FADNet++ on both synthetic and realistic datasets among six GPU devices varying from server to mobile platforms. Experimental results show that FADNet++ and its variants achieve state-of-the-art prediction accuracy, and run at a significant order of magnitude faster speed than existing 3D models. With the constraint of running at above 15 frames per second (FPS) on a mobile GPU, FADNet++ achieves a new state-of-the-art result for the SceneFlow dataset.
Accelerating Distributed K-FAC with Smart Parallelism of Computing and Communication Tasks
Jul 14, 2021
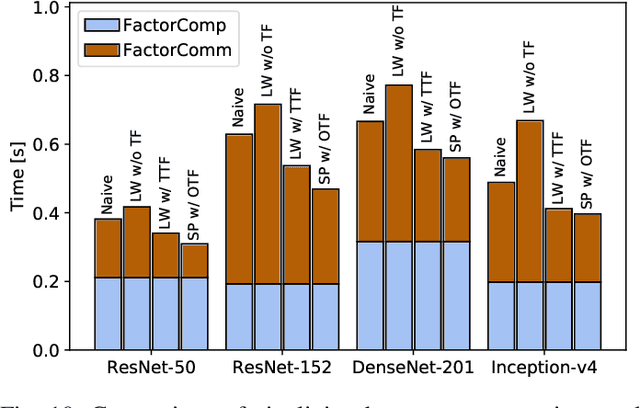
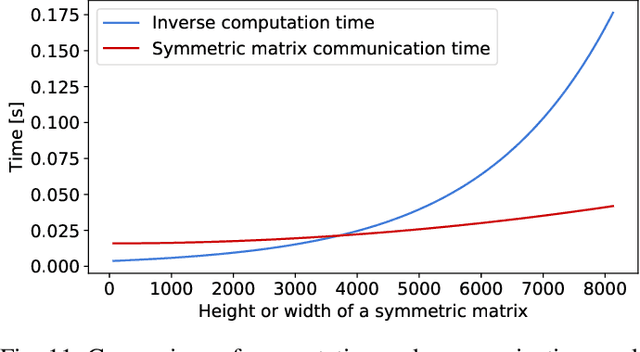
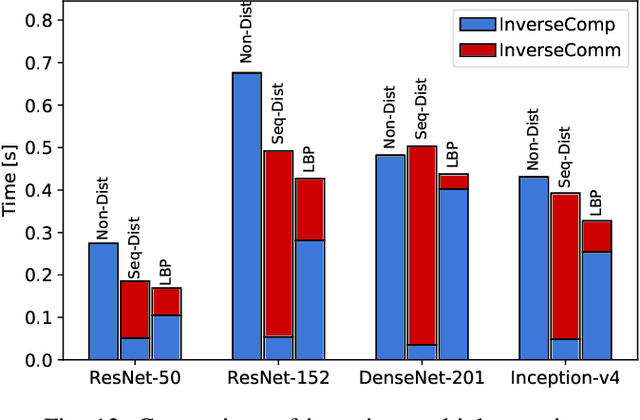
Distributed training with synchronous stochastic gradient descent (SGD) on GPU clusters has been widely used to accelerate the training process of deep models. However, SGD only utilizes the first-order gradient in model parameter updates, which may take days or weeks. Recent studies have successfully exploited approximate second-order information to speed up the training process, in which the Kronecker-Factored Approximate Curvature (KFAC) emerges as one of the most efficient approximation algorithms for training deep models. Yet, when leveraging GPU clusters to train models with distributed KFAC (D-KFAC), it incurs extensive computation as well as introduces extra communications during each iteration. In this work, we propose D-KFAC (SPD-KFAC) with smart parallelism of computing and communication tasks to reduce the iteration time. Specifically, 1) we first characterize the performance bottlenecks of D-KFAC, 2) we design and implement a pipelining mechanism for Kronecker factors computation and communication with dynamic tensor fusion, and 3) we develop a load balancing placement for inverting multiple matrices on GPU clusters. We conduct real-world experiments on a 64-GPU cluster with 100Gb/s InfiniBand interconnect. Experimental results show that our proposed SPD-KFAC training scheme can achieve 10%-35% improvement over state-of-the-art algorithms.
Automated Model Design and Benchmarking of 3D Deep Learning Models for COVID-19 Detection with Chest CT Scans
Feb 12, 2021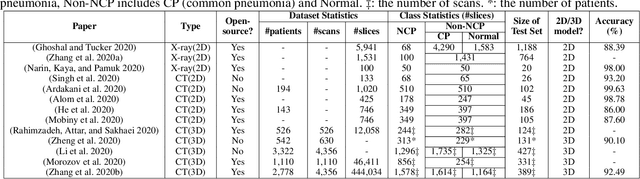
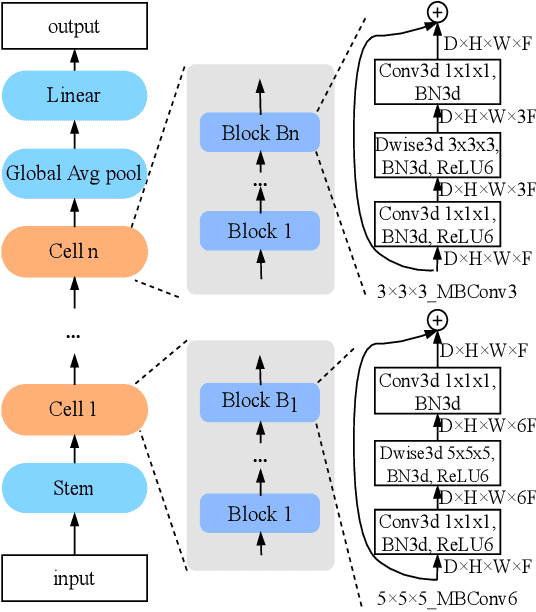
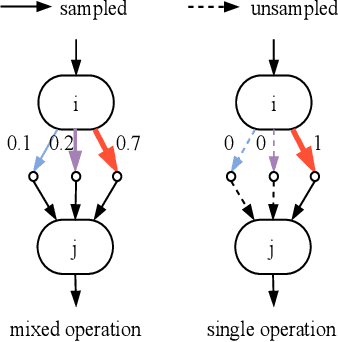
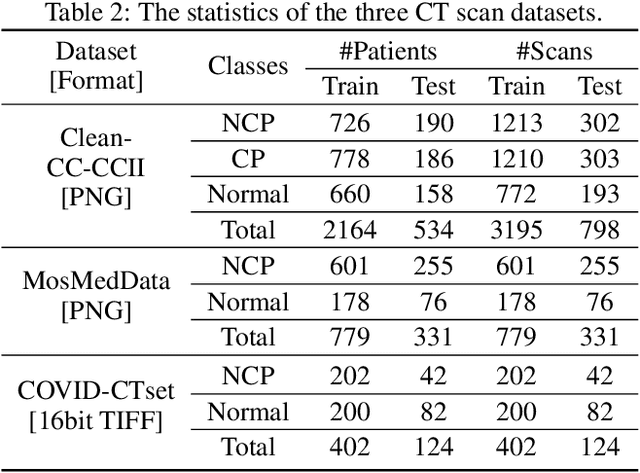
The COVID-19 pandemic has spread globally for several months. Because its transmissibility and high pathogenicity seriously threaten people's lives, it is crucial to accurately and quickly detect COVID-19 infection. Many recent studies have shown that deep learning (DL) based solutions can help detect COVID-19 based on chest CT scans. However, most existing work focuses on 2D datasets, which may result in low quality models as the real CT scans are 3D images. Besides, the reported results span a broad spectrum on different datasets with a relatively unfair comparison. In this paper, we first use three state-of-the-art 3D models (ResNet3D101, DenseNet3D121, and MC3\_18) to establish the baseline performance on the three publicly available chest CT scan datasets. Then we propose a differentiable neural architecture search (DNAS) framework to automatically search for the 3D DL models for 3D chest CT scans classification with the Gumbel Softmax technique to improve the searching efficiency. We further exploit the Class Activation Mapping (CAM) technique on our models to provide the interpretability of the results. The experimental results show that our automatically searched models (CovidNet3D) outperform the baseline human-designed models on the three datasets with tens of times smaller model size and higher accuracy. Furthermore, the results also verify that CAM can be well applied in CovidNet3D for COVID-19 datasets to provide interpretability for medical diagnosis.
Towards Scalable Distributed Training of Deep Learning on Public Cloud Clusters
Oct 20, 2020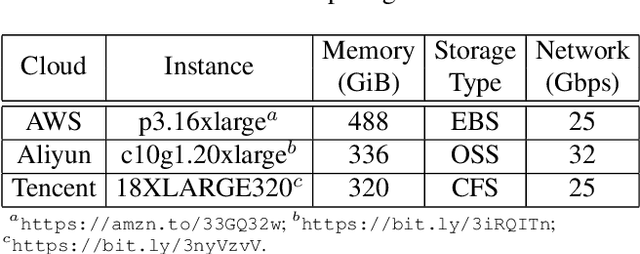
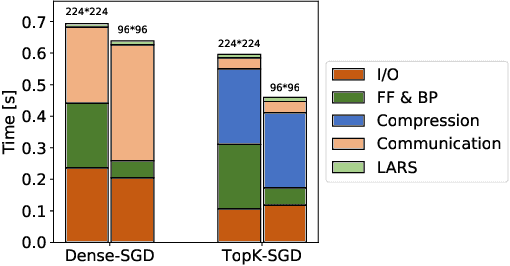
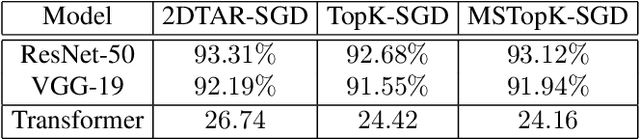
Distributed training techniques have been widely deployed in large-scale deep neural networks (DNNs) training on dense-GPU clusters. However, on public cloud clusters, due to the moderate inter-connection bandwidth between instances, traditional state-of-the-art distributed training systems cannot scale well in training large-scale models. In this paper, we propose a new computing and communication efficient top-k sparsification communication library for distributed training. To further improve the system scalability, we optimize I/O by proposing a simple yet efficient multi-level data caching mechanism and optimize the update operation by introducing a novel parallel tensor operator. Experimental results on a 16-node Tencent Cloud cluster (each node with 8 Nvidia Tesla V100 GPUs) show that our system achieves 25%-40% faster than existing state-of-the-art systems on CNNs and Transformer. We finally break the record on DAWNBench on training ResNet-50 to 93% top-5 accuracy on ImageNet.
Communication-Efficient Distributed Deep Learning: Survey, Evaluation, and Challenges
May 27, 2020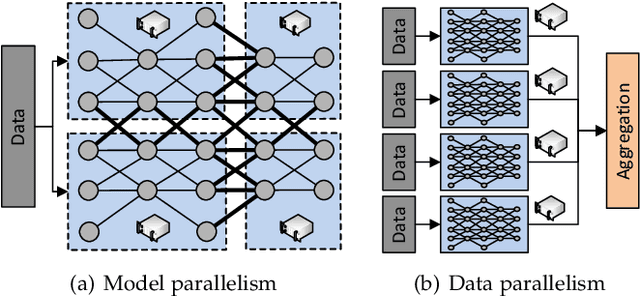
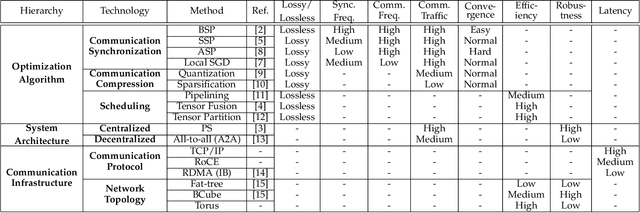
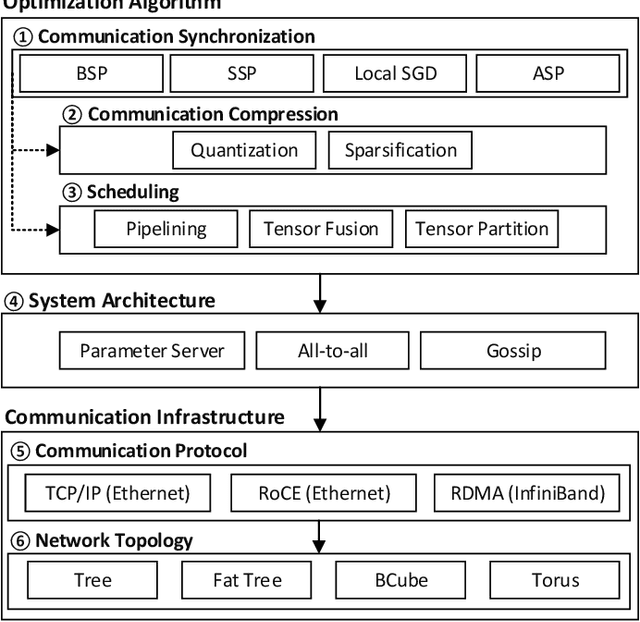

In recent years, distributed deep learning techniques are widely deployed to accelerate the training of deep learning models by exploiting multiple computing nodes. However, the extensive communications among workers dramatically limit the system scalability. In this article, we provide a systematic survey of communication-efficient distributed deep learning. Specifically, we first identify the communication challenges in distributed deep learning. Then we summarize the state-of-the-art techniques in this direction, and provide a taxonomy with three levels: optimization algorithm, system architecture, and communication infrastructure. Afterwards, we present a comparative study on seven different distributed deep learning techniques on a 32-GPU cluster with both 10Gbps Ethernet and 100Gbps InfiniBand. We finally discuss some challenges and open issues for possible future investigations.
FADNet: A Fast and Accurate Network for Disparity Estimation
Mar 24, 2020
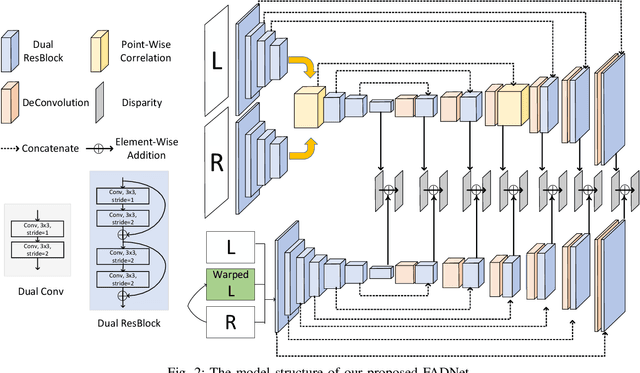


Deep neural networks (DNNs) have achieved great success in the area of computer vision. The disparity estimation problem tends to be addressed by DNNs which achieve much better prediction accuracy in stereo matching than traditional hand-crafted feature based methods. On one hand, however, the designed DNNs require significant memory and computation resources to accurately predict the disparity, especially for those 3D convolution based networks, which makes it difficult for deployment in real-time applications. On the other hand, existing computation-efficient networks lack expression capability in large-scale datasets so that they cannot make an accurate prediction in many scenarios. To this end, we propose an efficient and accurate deep network for disparity estimation named FADNet with three main features: 1) It exploits efficient 2D based correlation layers with stacked blocks to preserve fast computation; 2) It combines the residual structures to make the deeper model easier to learn; 3) It contains multi-scale predictions so as to exploit a multi-scale weight scheduling training technique to improve the accuracy. We conduct experiments to demonstrate the effectiveness of FADNet on two popular datasets, Scene Flow and KITTI 2015. Experimental results show that FADNet achieves state-of-the-art prediction accuracy, and runs at a significant order of magnitude faster speed than existing 3D models. The codes of FADNet are available at https://github.com/HKBU-HPML/FADNet.
Communication-Efficient Distributed Deep Learning: A Comprehensive Survey
Mar 10, 2020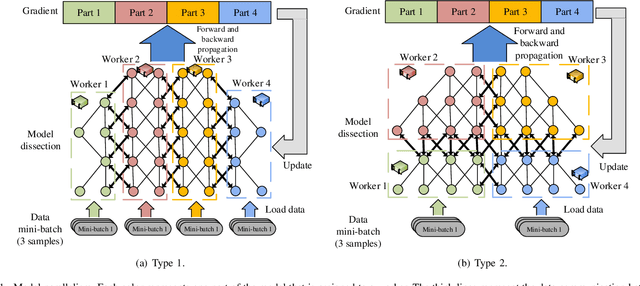
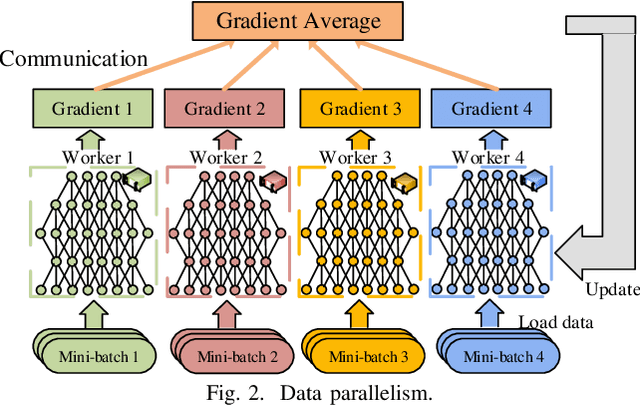
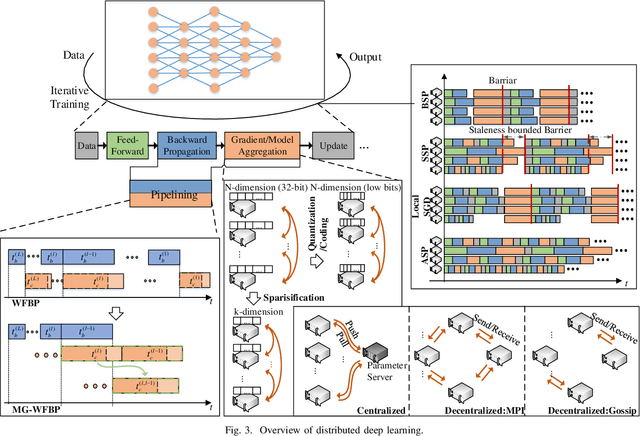
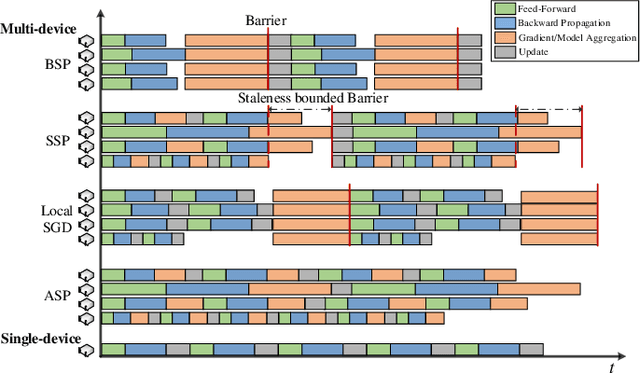
Distributed deep learning becomes very common to reduce the overall training time by exploiting multiple computing devices (e.g., GPUs/TPUs) as the size of deep models and data sets increases. However, data communication between computing devices could be a potential bottleneck to limit the system scalability. How to address the communication problem in distributed deep learning is becoming a hot research topic recently. In this paper, we provide a comprehensive survey of the communication-efficient distributed training algorithms in both system-level and algorithmic-level optimizations. In the system-level, we demystify the system design and implementation to reduce the communication cost. In algorithmic-level, we compare different algorithms with theoretical convergence bounds and communication complexity. Specifically, we first propose the taxonomy of data-parallel distributed training algorithms, which contains four main dimensions: communication synchronization, system architectures, compression techniques, and parallelism of communication and computing. Then we discuss the studies in addressing the problems of the four dimensions to compare the communication cost. We further compare the convergence rates of different algorithms, which enable us to know how fast the algorithms can converge to the solution in terms of iterations. According to the system-level communication cost analysis and theoretical convergence speed comparison, we provide the readers to understand what algorithms are more efficient under specific distributed environments and extrapolate potential directions for further optimizations.
Communication Contention Aware Scheduling of Multiple Deep Learning Training Jobs
Feb 24, 2020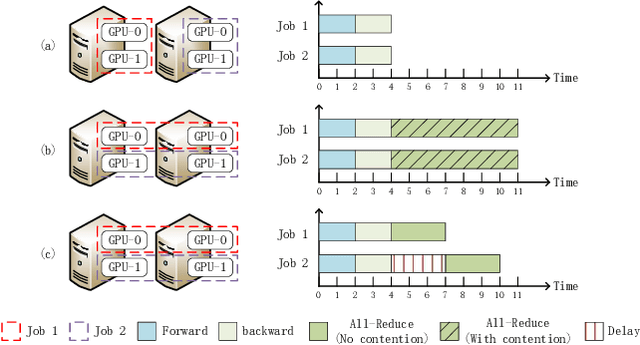
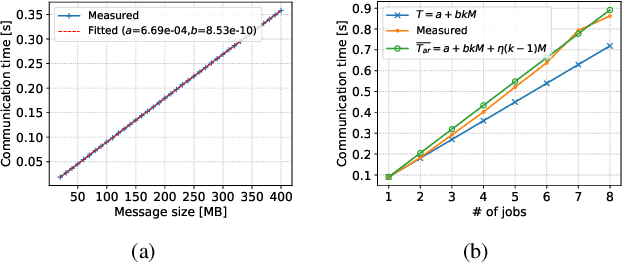
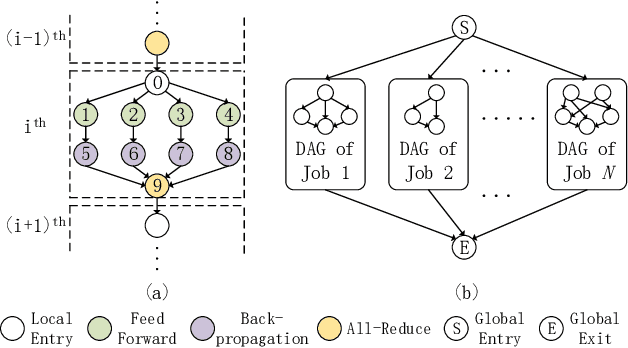
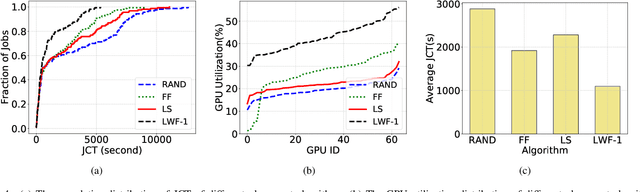
Distributed Deep Learning (DDL) has rapidly grown its popularity since it helps boost the training performance on high-performance GPU clusters. Efficient job scheduling is indispensable to maximize the overall performance of the cluster when training multiple jobs simultaneously. However, existing schedulers do not consider the communication contention of multiple communication tasks from different distributed training jobs, which could deteriorate the system performance and prolong the job completion time. In this paper, we first establish a new DDL job scheduling framework which organizes DDL jobs as Directed Acyclic Graphs (DAGs) and considers communication contention between nodes. We then propose an efficient algorithm, LWF-$\kappa$, to balance the GPU utilization and consolidate the allocated GPUs for each job. When scheduling those communication tasks, we observe that neither avoiding all the contention nor blindly accepting them is optimal to minimize the job completion time. We thus propose a provable algorithm, AdaDUAL, to efficiently schedule those communication tasks. Based on AdaDUAL, we finally propose Ada-SRSF for the DDL job scheduling problem. Simulations on a 64-GPU cluster connected with 10 Gbps Ethernet show that LWF-$\kappa$ achieves up to $1.59\times$ improvement over the classical first-fit algorithms. More importantly, Ada-SRSF reduces the average job completion time by $20.1\%$ and $36.7\%$, as compared to the SRSF(1) scheme (avoiding all the contention) and the SRSF(2) scheme (blindly accepting all of two-way communication contention) respectively.
Communication-Efficient Decentralized Learning with Sparsification and Adaptive Peer Selection
Feb 22, 2020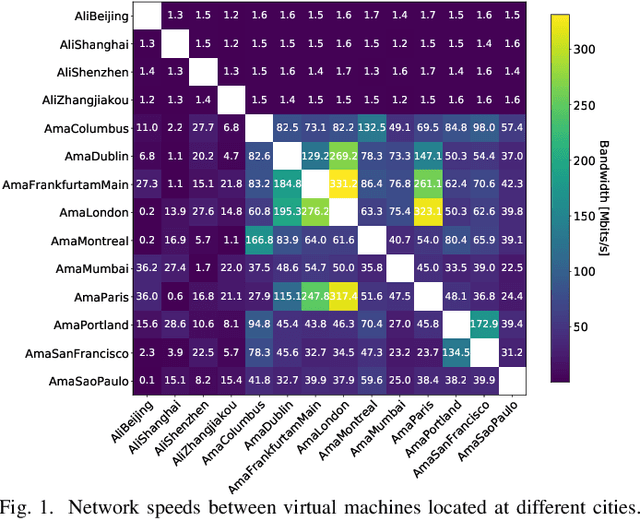
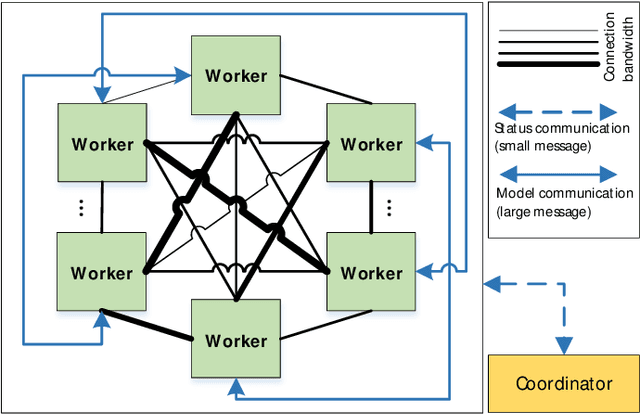
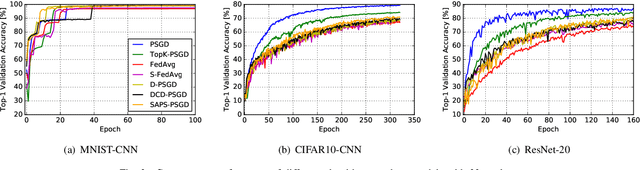
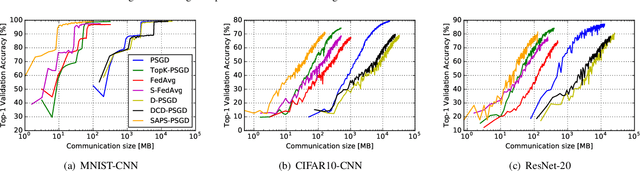
Distributed learning techniques such as federated learning have enabled multiple workers to train machine learning models together to reduce the overall training time. However, current distributed training algorithms (centralized or decentralized) suffer from the communication bottleneck on multiple low-bandwidth workers (also on the server under the centralized architecture). Although decentralized algorithms generally have lower communication complexity than the centralized counterpart, they still suffer from the communication bottleneck for workers with low network bandwidth. To deal with the communication problem while being able to preserve the convergence performance, we introduce a novel decentralized training algorithm with the following key features: 1) It does not require a parameter server to maintain the model during training, which avoids the communication pressure on any single peer. 2) Each worker only needs to communicate with a single peer at each communication round with a highly compressed model, which can significantly reduce the communication traffic on the worker. We theoretically prove that our sparsification algorithm still preserves convergence properties. 3) Each worker dynamically selects its peer at different communication rounds to better utilize the bandwidth resources. We conduct experiments with convolutional neural networks on 32 workers to verify the effectiveness of our proposed algorithm compared to seven existing methods. Experimental results show that our algorithm significantly reduces the communication traffic and generally select relatively high bandwidth peers.
MG-WFBP: Merging Gradients Wisely for Efficient Communication in Distributed Deep Learning
Dec 18, 2019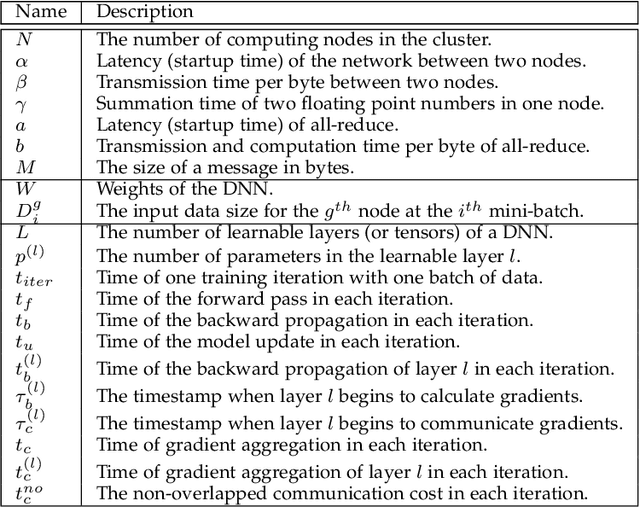
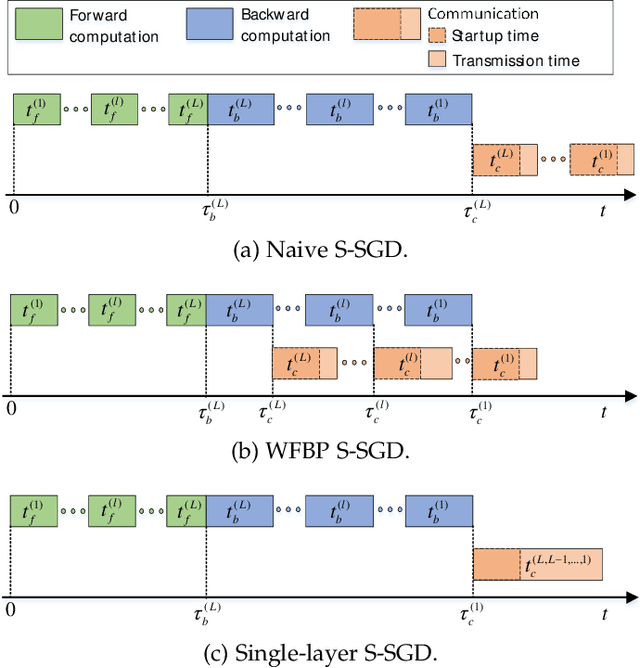

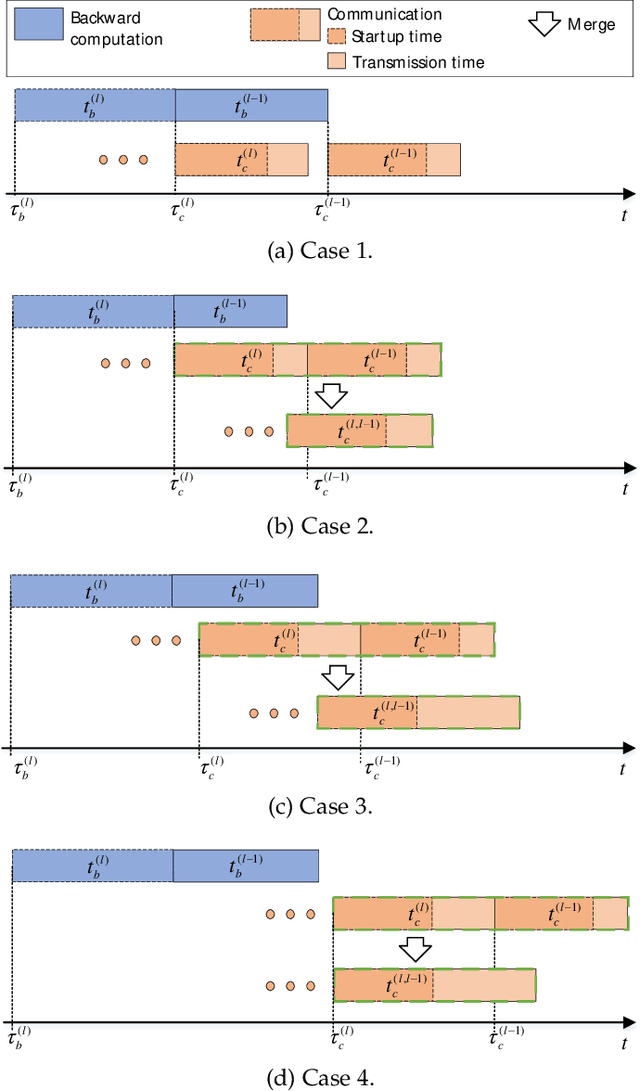
Distributed synchronous stochastic gradient descent has been widely used to train deep neural networks (DNNs) on computer clusters. With the increase of computational power, network communications generally limit the system scalability. Wait-free backpropagation (WFBP) is a popular solution to overlap communications with computations during the training process. In this paper, we observe that many DNNs have a large number of layers with only a small amount of data to be communicated at each layer in distributed training, which could make WFBP inefficient. Based on the fact that merging some short communication tasks into a single one can reduce the overall communication time, we formulate an optimization problem to minimize the training time in pipelining communications and computations. We derive an optimal solution that can be solved efficiently without affecting the training performance. We then apply the solution to propose a distributed training algorithm named merged-gradient WFBP (MG-WFBP) and implement it in two platforms Caffe and PyTorch. Extensive experiments in three GPU clusters are conducted to verify the effectiveness of MG-WFBP. We further exploit the trace-based simulation of 64 GPUs to explore the potential scaling efficiency of MG-WFBP. Experimental results show that MG-WFBP achieves much better scaling performance than existing methods.