 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable Joint Attribute-Identity Deep Learning for Unsupervised Person Re-Identification
Mar 26, 2018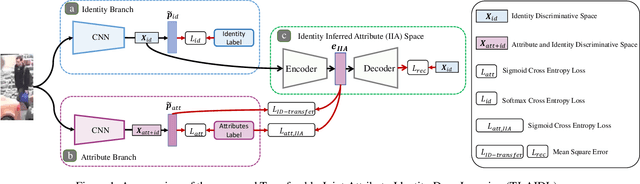
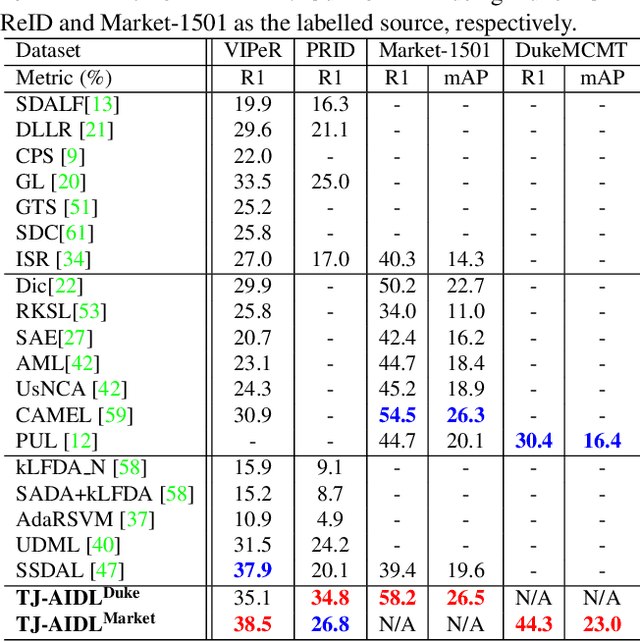
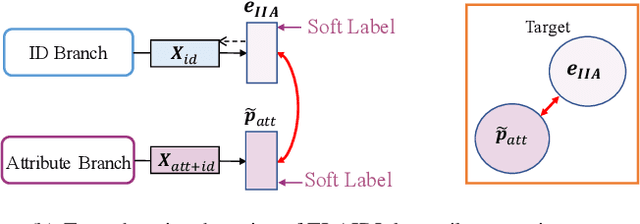

Most existing person re-identification (re-id) methods require supervised model learning from a separate large set of pairwise labelled training data for every single camera pair. This significantly limits their scalability and usability in real-world large scale deployments with the need for performing re-id across many camera views. To address this scalability problem, we develop a novel deep learning method for transferring the labelled information of an existing dataset to a new unseen (unlabelled) target domain for person re-id without any supervised learning in the target domain. Specifically, we introduce an Transferable Joint Attribute-Identity Deep Learning (TJ-AIDL) for simultaneously learning an attribute-semantic and identitydiscriminative feature representation space transferrable to any new (unseen) target domain for re-id tasks without the need for collecting new labelled training data from the target domain (i.e. unsupervised learning in the target domain). Extensive comparative evaluations validate the superiority of this new TJ-AIDL model for unsupervised person re-id over a wide range of state-of-the-art methods on four challenging benchmarks including VIPeR, PRID, Market-1501, and DukeMTMC-ReID.
Deep Learning Logo Detection with Data Expansion by Synthesising Context
Mar 16, 2018
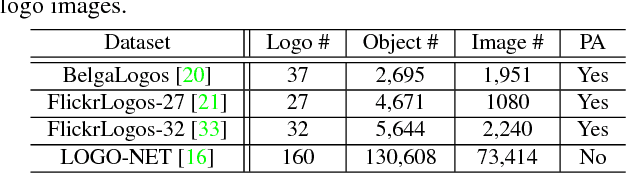

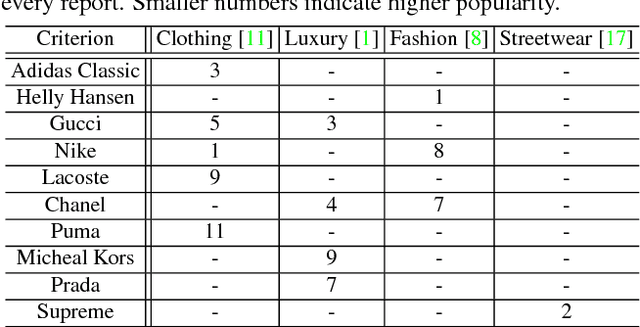
Logo detection in unconstrained images is challenging, particularly when only very sparse labelled training images are accessible due to high labelling costs. In this work, we describe a model training image synthesising method capable of improving significantly logo detection performance when only a handful of (e.g., 10) labelled training images captured in realistic context are available, avoiding extensive manual labelling costs. Specifically, we design a novel algorithm for generating Synthetic Context Logo (SCL) training images to increase model robustness against unknown background clutters, resulting in superior logo detection performance. For benchmarking model performance, we introduce a new logo detection dataset TopLogo-10 collected from top 10 most popular clothing/wearable brandname logos captured in rich visual context. Extensive comparisons show the advantages of our proposed SCL model over the state-of-the-art alternatives for logo detection using two real-world logo benchmark datasets: FlickrLogo-32 and our new TopLogo-10.
Harmonious Attention Network for Person Re-Identification
Feb 22, 2018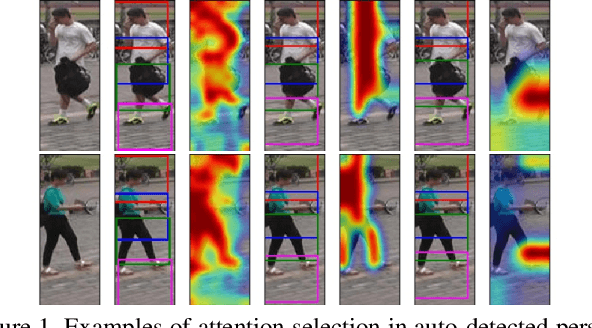
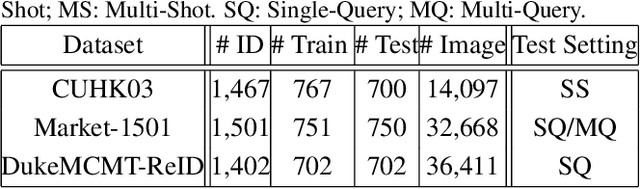
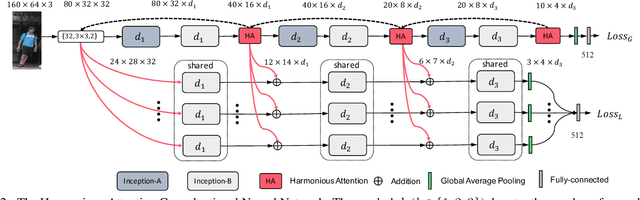
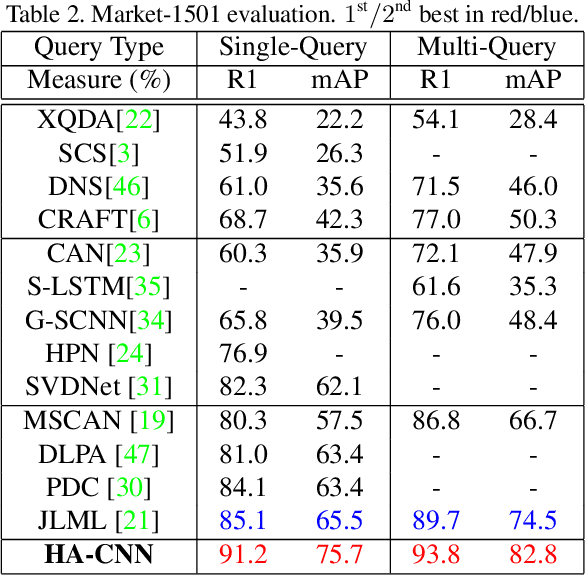
Existing person re-identification (re-id) methods either assume the availability of well-aligned person bounding box images as model input or rely on constrained attention selection mechanisms to calibrate misaligned images. They are therefore sub-optimal for re-id matching in arbitrarily aligned person images potentially with large human pose variations and unconstrained auto-detection errors. In this work, we show the advantages of jointly learning attention selection and feature representation in a Convolutional Neural Network (CNN) by maximising the complementary information of different levels of visual attention subject to re-id discriminative learning constraints. Specifically, we formulate a novel Harmonious Attention CNN (HA-CNN) model for joint learning of soft pixel attention and hard regional attention along with simultaneous optimisation of feature representations, dedicated to optimise person re-id in uncontrolled (misaligned) images. Extensive comparative evaluations validate the superiority of this new HA-CNN model for person re-id over a wide variety of state-of-the-art methods on three large-scale benchmarks including CUHK03, Market-1501, and DukeMTMC-ReID.
Class Rectification Hard Mining for Imbalanced Deep Learning
Dec 08, 2017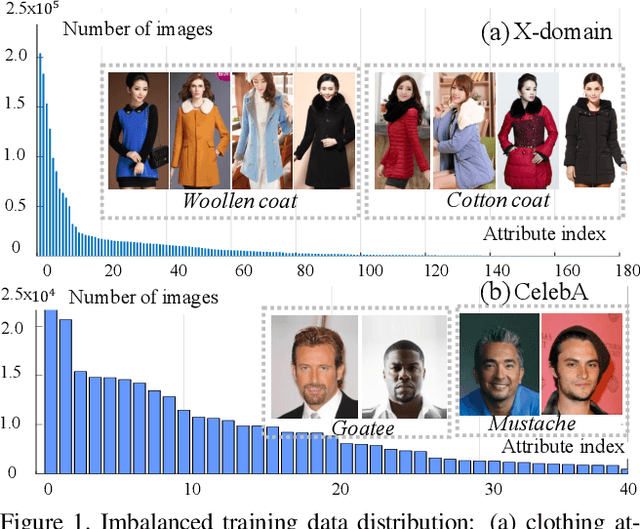
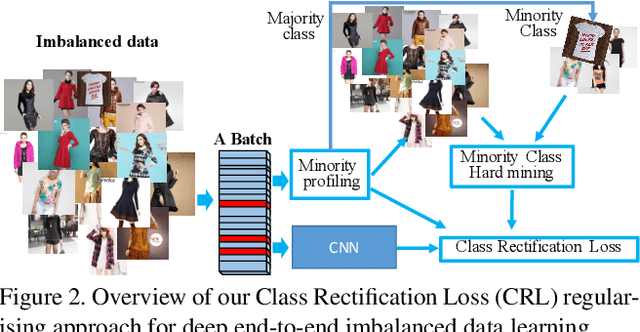
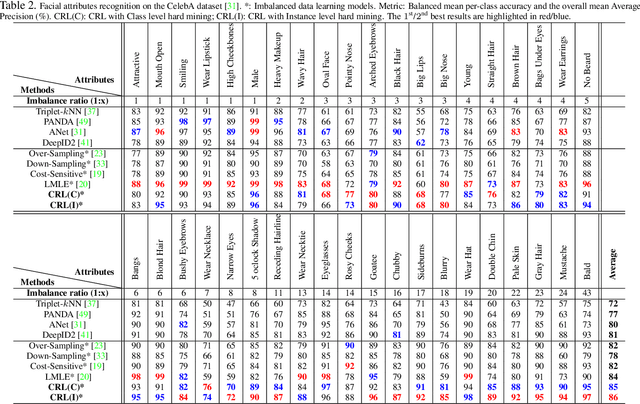
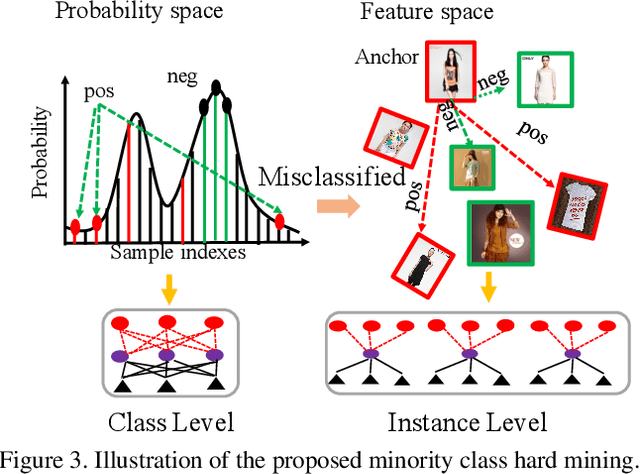
Recognising detailed facial or clothing attributes in images of people is a challenging task for computer vision, especially when the training data are both in very large scale and extremely imbalanced among different attribute classes. To address this problem, we formulate a novel scheme for batch incremental hard sample mining of minority attribute classes from imbalanced large scale training data. We develop an end-to-end deep learning framework capable of avoiding the dominant effect of majority classes by discovering sparsely sampled boundaries of minority classes. This is made possible by introducing a Class Rectification Loss (CRL) regularising algorithm. We demonstrate the advantages and scalability of CRL over existing state-of-the-art attribute recognition and imbalanced data learning models on two large scale imbalanced benchmark datasets, the CelebA facial attribute dataset and the X-Domain clothing attribute dataset.
Actor-Critic Sequence Training for Image Captioning
Nov 28, 2017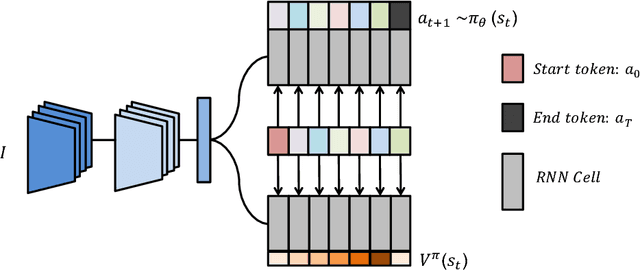
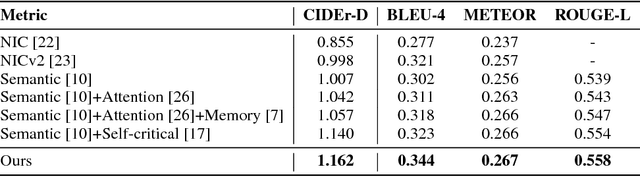
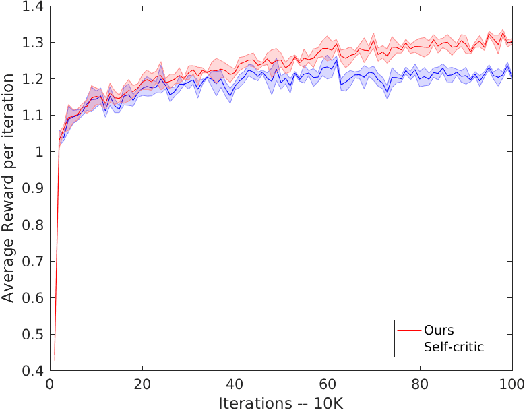
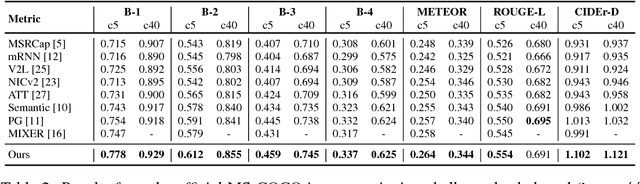
Generating natural language descriptions of images is an important capability for a robot or other visual-intelligence driven AI agent that may need to communicate with human users about what it is seeing. Such image captioning methods are typically trained by maximising the likelihood of ground-truth annotated caption given the image. While simple and easy to implement, this approach does not directly maximise the language quality metrics we care about such as CIDEr. In this paper we investigate training image captioning methods based on actor-critic reinforcement learning in order to directly optimise non-differentiable quality metrics of interest. By formulating a per-token advantage and value computation strategy in this novel reinforcement learning based captioning model, we show that it is possible to achieve the state of the art performance on the widely used MSCOCO benchmark.
Recent Advances in Zero-shot Recognition
Oct 13, 2017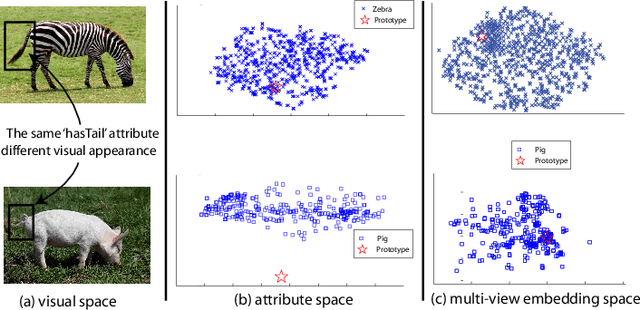
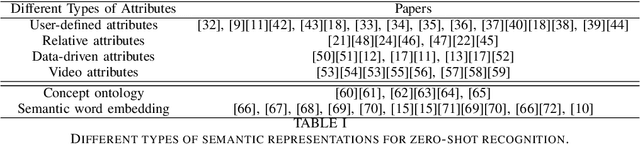
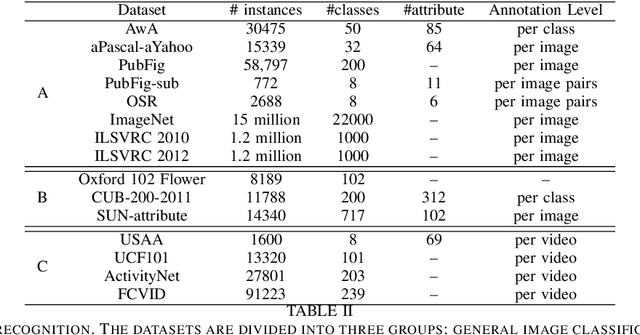
With the recent renaissance of deep convolution neural networks, encouraging breakthroughs have been achieved on the supervised recognition tasks, where each class has sufficient training data and fully annotated training data. However, to scale the recognition to a large number of classes with few or now training samples for each class remains an unsolved problem. One approach to scaling up the recognition is to develop models capable of recognizing unseen categories without any training instances, or zero-shot recognition/ learning. This article provides a comprehensive review of existing zero-shot recognition techniques covering various aspects ranging from representations of models, and from datasets and evaluation settings. We also overview related recognition tasks including one-shot and open set recognition which can be used as natural extensions of zero-shot recognition when limited number of class samples become available or when zero-shot recognition is implemented in a real-world setting. Importantly, we highlight the limitations of existing approaches and point out future research directions in this existing new research area.
Attribute Recognition by Joint Recurrent Learning of Context and Correlation
Sep 25, 2017
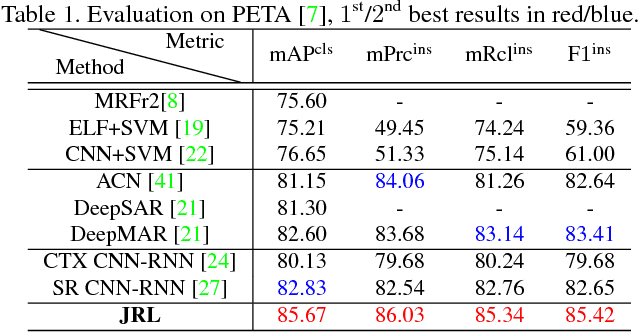
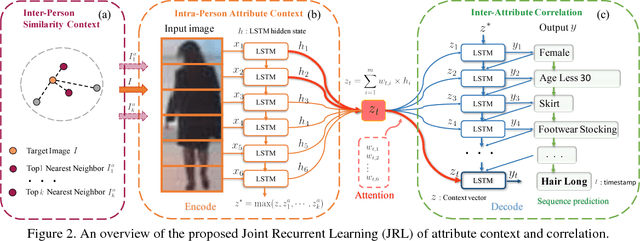
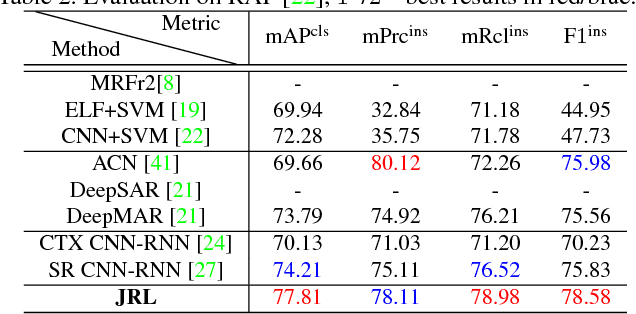
Recognising semantic pedestrian attributes in surveillance images is a challenging task for computer vision, particularly when the imaging quality is poor with complex background clutter and uncontrolled viewing conditions, and the number of labelled training data is small. In this work, we formulate a Joint Recurrent Learning (JRL) model for exploring attribute context and correlation in order to improve attribute recognition given small sized training data with poor quality images. The JRL model learns jointly pedestrian attribute correlations in a pedestrian image and in particular their sequential ordering dependencies (latent high-order correlation) in an end-to-end encoder/decoder recurrent network. We demonstrate the performance advantage and robustness of the JRL model over a wide range of state-of-the-art deep models for pedestrian attribute recognition, multi-label image classification, and multi-person image annotation on two largest pedestrian attribute benchmarks PETA and RAP.
Deep Learning Prototype Domains for Person Re-Identification
Sep 19, 2017
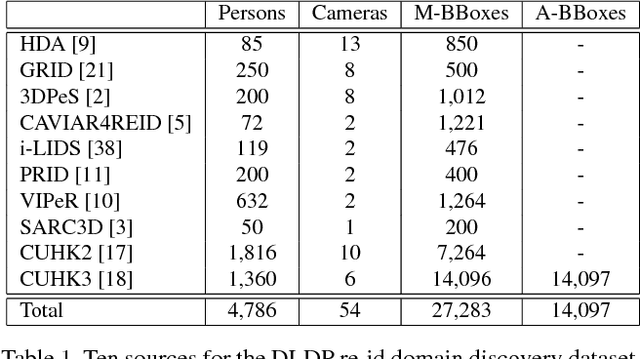
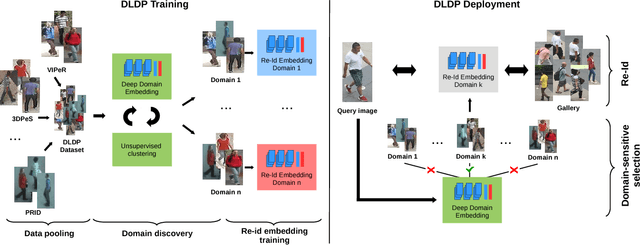
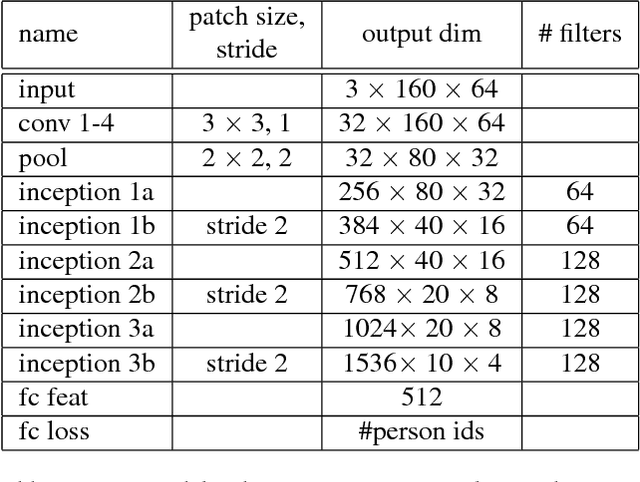
Person re-identification (re-id) is the task of matching multiple occurrences of the same person from different cameras, poses, lighting conditions, and a multitude of other factors which alter the visual appearance. Typically, this is achieved by learning either optimal features or matching metrics which are adapted to specific pairs of camera views dictated by the pairwise labelled training datasets. In this work, we formulate a deep learning based novel approach to automatic prototype-domain discovery for domain perceptive (adaptive) person re-id (rather than camera pair specific learning) for any camera views scalable to new unseen scenes without training data. We learn a separate re-id model for each of the discovered prototype-domains and during model deployment, use the person probe image to select automatically the model of the closest prototype domain. Our approach requires neither supervised nor unsupervised domain adaptation learning, i.e. no data available from the target domains. We evaluate extensively our model under realistic re-id conditions using automatically detected bounding boxes with low-resolution and partial occlusion. We show that our approach outperforms most of the state-of-the-art supervised and unsupervised methods on the latest CUHK-SYSU and PRW benchmarks.
Discovering Visual Concept Structure with Sparse and Incomplete Tags
May 30, 2017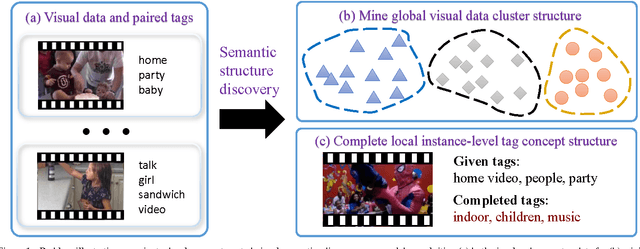
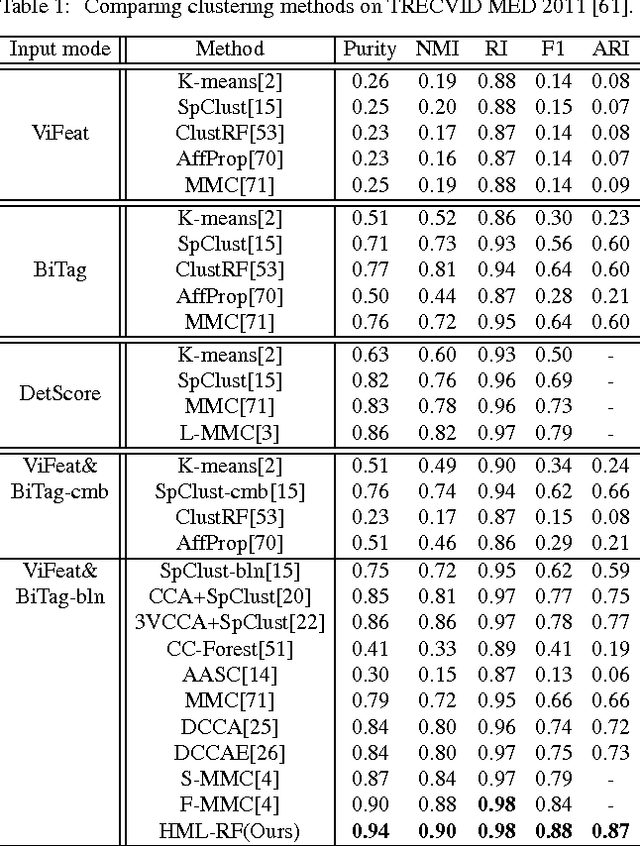
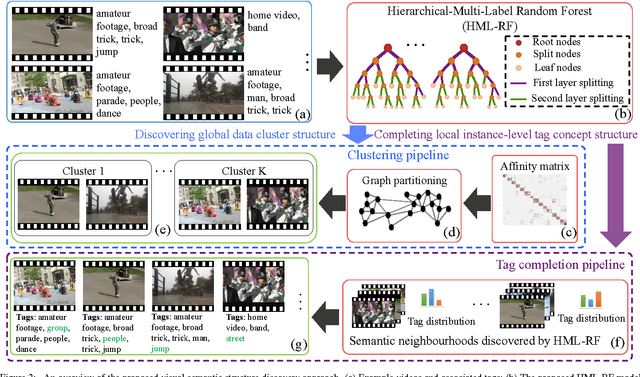
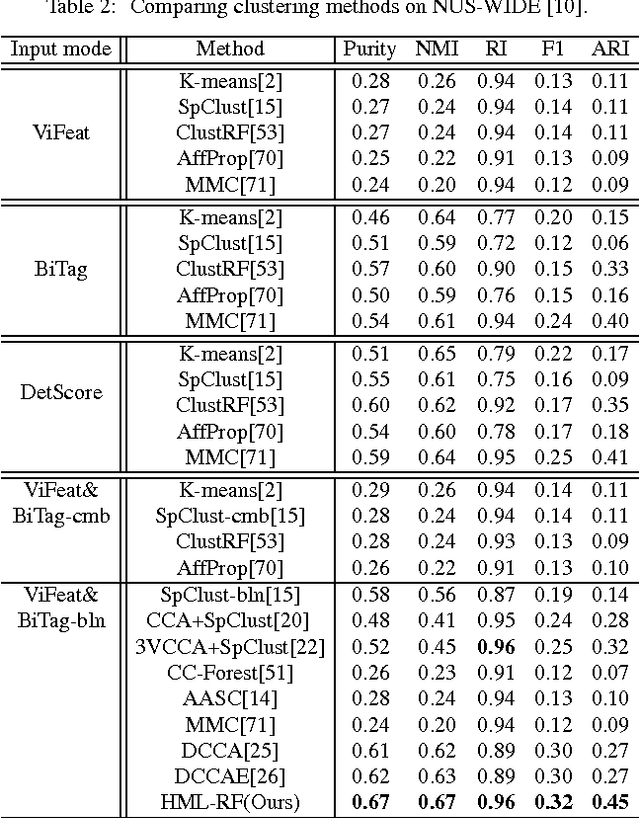
Discovering automatically the semantic structure of tagged visual data (e.g. web videos and images) is important for visual data analysis and interpretation, enabling the machine intelligence for effectively processing the fast-growing amount of multi-media data. However, this is non-trivial due to the need for jointly learning underlying correlations between heterogeneous visual and tag data. The task is made more challenging by inherently sparse and incomplete tags. In this work, we develop a method for modelling the inherent visual data concept structures based on a novel Hierarchical-Multi-Label Random Forest model capable of correlating structured visual and tag information so as to more accurately interpret the visual semantics, e.g. disclosing meaningful visual groups with similar high-level concepts, and recovering missing tags for individual visual data samples. Specifically, our model exploits hierarchically structured tags of different semantic abstractness and multiple tag statistical correlations in addition to modelling visual and tag interactions. As a result, our model is able to discover more accurate semantic correlation between textual tags and visual features, and finally providing favourable visual semantics interpretation even with highly sparse and incomplete tags. We demonstrate the advantages of our proposed approach in two fundamental applications, visual data clustering and missing tag completion, on benchmarking video (i.e. TRECVID MED 2011) and image (i.e. NUS-WIDE) datasets.
Person Re-Identification by Deep Joint Learning of Multi-Loss Classification
May 23, 2017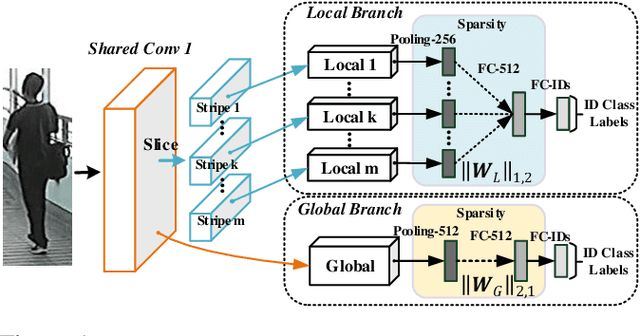
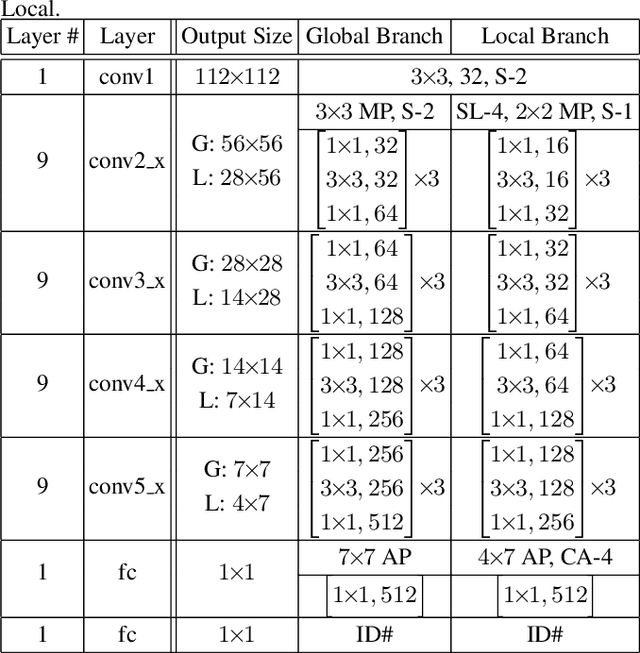
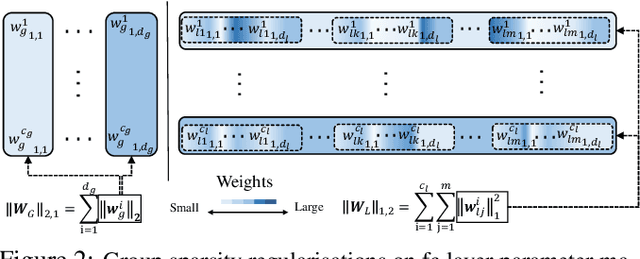
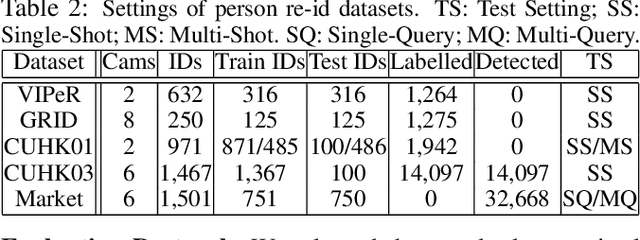
Existing person re-identification (re-id) methods rely mostly on either localised or global feature representation alone. This ignores their joint benefit and mutual complementary effects. In this work, we show the advantages of jointly learning local and global features in a Convolutional Neural Network (CNN) by aiming to discover correlated local and global features in different context. Specifically, we formulate a method for joint learning of local and global feature selection losses designed to optimise person re-id when using only generic matching metrics such as the L2 distance. We design a novel CNN architecture for Jointly Learning Multi-Loss (JLML) of local and global discriminative feature optimisation subject concurrently to the same re-id labelled information. Extensive comparative evaluations demonstrate the advantages of this new JLML model for person re-id over a wide range of state-of-the-art re-id methods on five benchmarks (VIPeR, GRID, CUHK01, CUHK03, Market-1501).