 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Person Re-Identification
Jul 22, 2019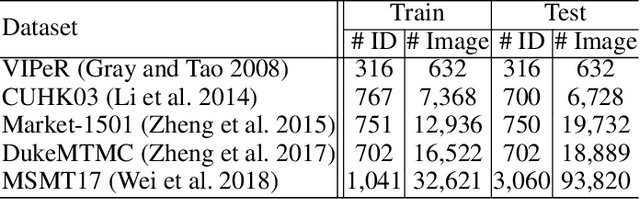

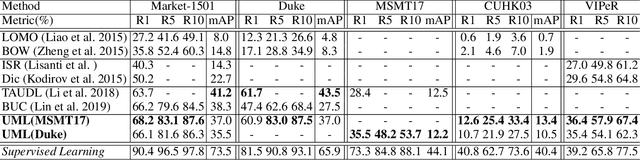
Most state-of-the-art person re-identification (re-id) methods depend on supervised model learning with a large set of cross-view identity labelled training data. Even worse, such trained models are limited to only the same-domain deployment with significantly degraded cross-domain generalization capability, i.e. "domain specific". To solve this limitation, there are a number of recent unsupervised domain adaptation and unsupervised learning methods that leverage unlabelled target domain training data. However, these methods need to train a separate model for each target domain as supervised learning methods. This conventional "{\em train once, run once}" pattern is unscalable to a large number of target domains typically encountered in real-world deployments. We address this problem by presenting a "train once, run everywhere" pattern industry-scale systems are desperate for. We formulate a "universal model learning' approach enabling domain-generic person re-id using only limited training data of a "{\em single}" seed domain. Specifically, we train a universal re-id deep model to discriminate between a set of transformed person identity classes. Each of such classes is formed by applying a variety of random appearance transformations to the images of that class, where the transformations simulate the camera viewing conditions of any domains for making the model training domain generic. Extensive evaluations show the superiority of our method for universal person re-id over a wide variety of state-of-the-art unsupervised domain adaptation and unsupervised learning re-id methods on five standard benchmarks: Market-1501, DukeMTMC, CUHK03, MSMT17, and VIPeR.
Unsupervised Deep Learning by Neighbourhood Discovery
May 30, 2019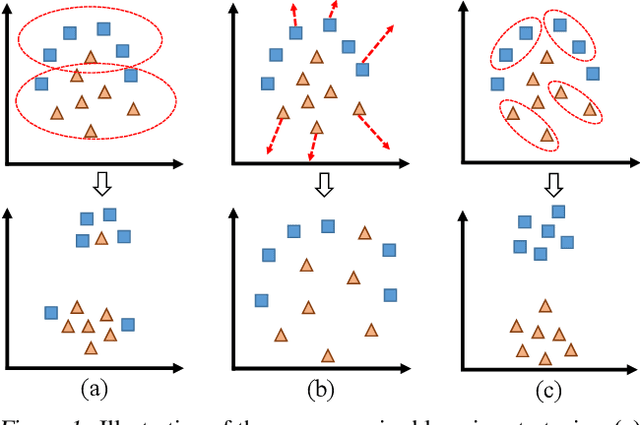
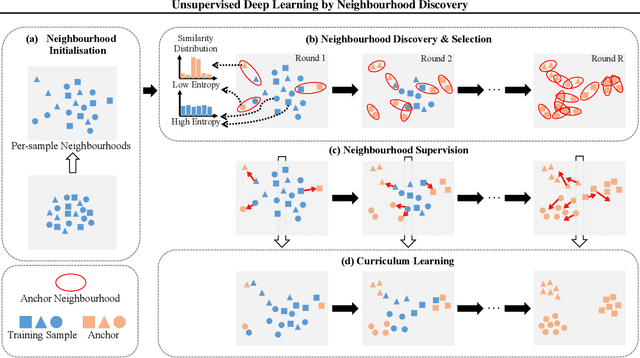
Deep convolutional neural networks (CNNs) have demonstrated remarkable success in computer vision by supervisedly learning strong visual feature representations. However, training CNNs relies heavily on the availability of exhaustive training data annotations, limiting significantly their deployment and scalability in many application scenarios. In this work, we introduce a generic unsupervised deep learning approach to training deep models without the need for any manual label supervision. Specifically, we progressively discover sample anchored/centred neighbourhoods to reason and learn the underlying class decision boundaries iteratively and accumulatively. Every single neighbourhood is specially formulated so that all the member samples can share the same unseen class labels at high probability for facilitating the extraction of class discriminative feature representations during training. Experiments on image classification show the performance advantages of the proposed method over the state-of-the-art unsupervised learning models on six benchmarks including both coarse-grained and fine-grained object image categorisation.
Unsupervised Person Re-identification by Soft Multilabel Learning
Apr 08, 2019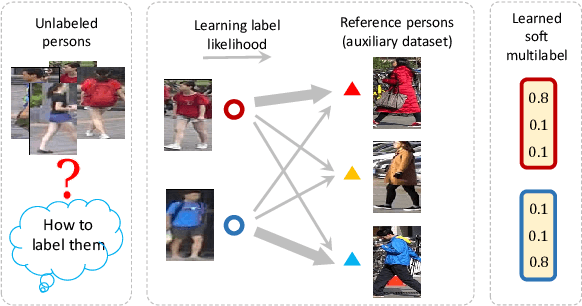
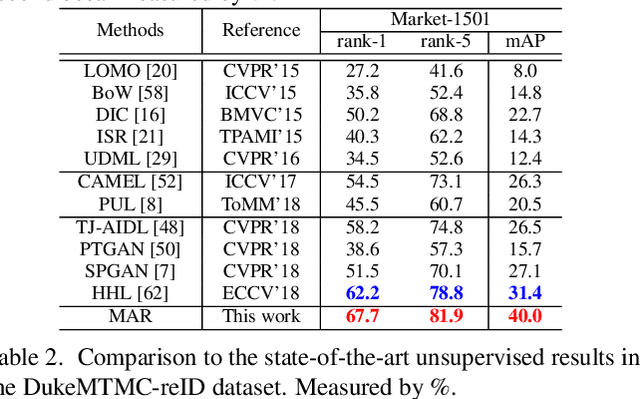
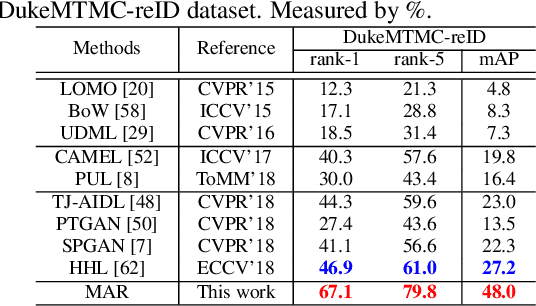
Although unsupervised person re-identification (RE-ID) has drawn increasing research attentions due to its potential to address the scalability problem of supervised RE-ID models, it is very challenging to learn discriminative information in the absence of pairwise labels across disjoint camera views. To overcome this problem, we propose a deep model for the soft multilabel learning for unsupervised RE-ID. The idea is to learn a soft multilabel (real-valued label likelihood vector) for each unlabeled person by comparing (and representing) the unlabeled person with a set of known reference persons from an auxiliary domain. We propose the soft multilabel-guided hard negative mining to learn a discriminative embedding for the unlabeled target domain by exploring the similarity consistency of the visual features and the soft multilabels of unlabeled target pairs. Since most target pairs are cross-view pairs, we develop the cross-view consistent soft multilabel learning to achieve the learning goal that the soft multilabels are consistently good across different camera views. To enable effecient soft multilabel learning, we introduce the reference agent learning to represent each reference person by a reference agent in a joint embedding. We evaluate our unified deep model on Market-1501 and DukeMTMC-reID. Our model outperforms the state-of-the-art unsupervised RE-ID methods by clear margins. Code is available at https://github.com/KovenYu/MAR.
Unsupervised Tracklet Person Re-Identification
Mar 01, 2019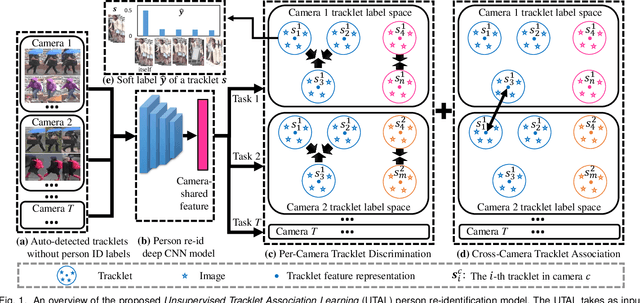
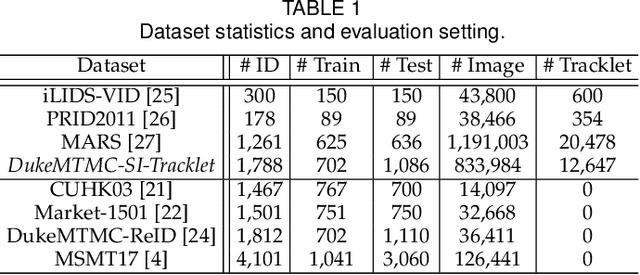
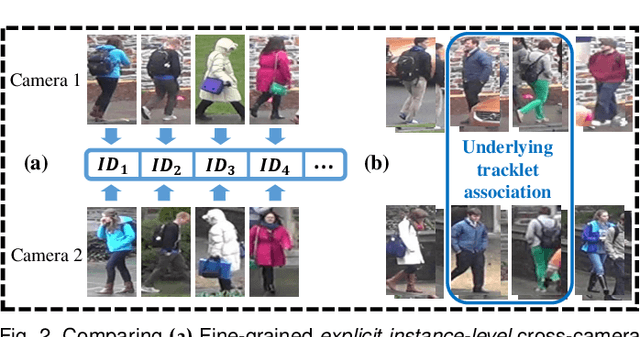
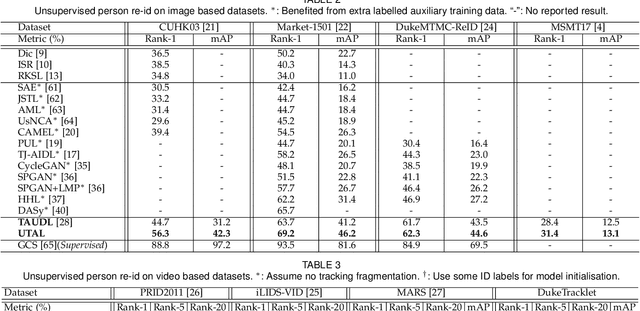
Most existing person re-identification (re-id) methods rely on supervised model learning on per-camera-pair manually labelled pairwise training data. This leads to poor scalability in a practical re-id deployment, due to the lack of exhaustive identity labelling of positive and negative image pairs for every camera-pair. In this work, we present an unsupervised re-id deep learning approach. It is capable of incrementally discovering and exploiting the underlying re-id discriminative information from automatically generated person tracklet data end-to-end. We formulate an Unsupervised Tracklet Association Learning (UTAL) framework. This is by jointly learning within-camera tracklet discrimination and cross-camera tracklet association in order to maximise the discovery of tracklet identity matching both within and across camera views. Extensive experiments demonstrate the superiority of the proposed model over the state-of-the-art unsupervised learning and domain adaptation person re-id methods on eight benchmarking datasets.
Instance-level Sketch-based Retrieval by Deep Triplet Classification Siamese Network
Nov 28, 2018
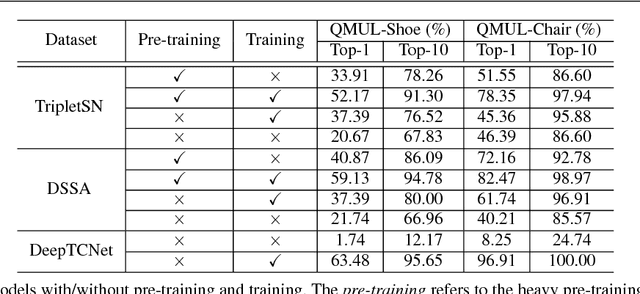


Sketch has been employed as an effective communicative tool to express the abstract and intuitive meanings of object. Recognizing the free-hand sketch drawing is extremely useful in many real-world applications. While content-based sketch recognition has been studied for several decades, the instance-level Sketch-Based Image Retrieval (SBIR) tasks have attracted significant research attention recently. The existing datasets such as QMUL-Chair and QMUL-Shoe, focus on the retrieval tasks of chairs and shoes. However, there are several key limitations in previous instance-level SBIR works. The state-of-the-art works have to heavily rely on the pre-training process, quality of edge maps, multi-cropping testing strategy, and augmenting sketch images. To efficiently solve the instance-level SBIR, we propose a new Deep Triplet Classification Siamese Network (DeepTCNet) which employs DenseNet-169 as the basic feature extractor and is optimized by the triplet loss and classification loss. Critically, our proposed DeepTCNet can break the limitations existed in previous works. The extensive experiments on five benchmark sketch datasets validate the effectiveness of the proposed model. Additionally, to study the tasks of sketch-based hairstyle retrieval, this paper contributes a new instance-level photo-sketch dataset - Hairstyle Photo-Sketch dataset, which is composed of 3600 sketches and photos, and 2400 sketch-photo pairs.
Low-Resolution Face Recognition
Nov 21, 2018
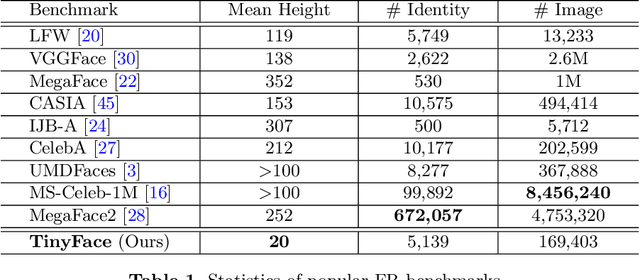
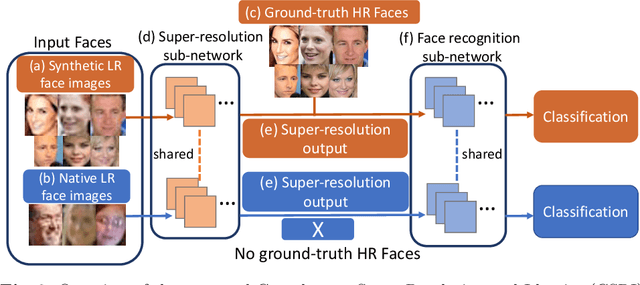

Whilst recent face-recognition (FR) techniques have made significant progress on recognising constrained high-resolution web images, the same cannot be said on natively unconstrained low-resolution images at large scales. In this work, we examine systematically this under-studied FR problem, and introduce a novel Complement Super-Resolution and Identity (CSRI) joint deep learning method with a unified end-to-end network architecture. We further construct a new large-scale dataset TinyFace of native unconstrained low-resolution face images from selected public datasets, because none benchmark of this nature exists in the literature. With extensive experiments we show there is a significant gap between the reported FR performances on popular benchmarks and the results on TinyFace, and the advantages of the proposed CSRI over a variety of state-of-the-art FR and super-resolution deep models on solving this largely ignored FR scenario. The TinyFace dataset is released publicly at: https://qmul-tinyface.github.io/.
Single-Label Multi-Class Image Classification by Deep Logistic Regression
Nov 20, 2018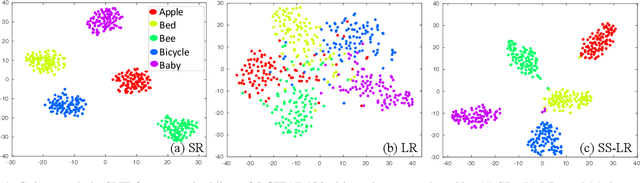
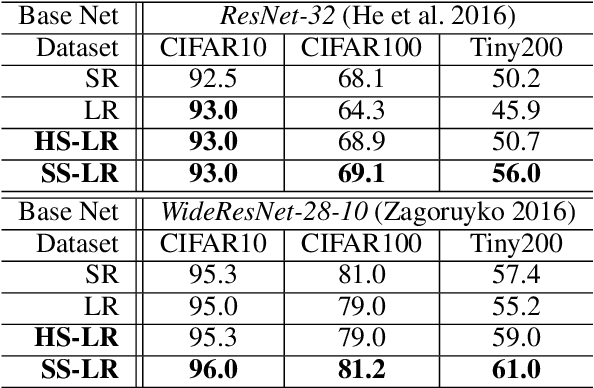
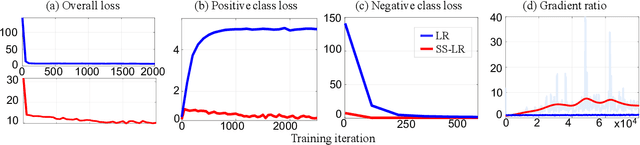
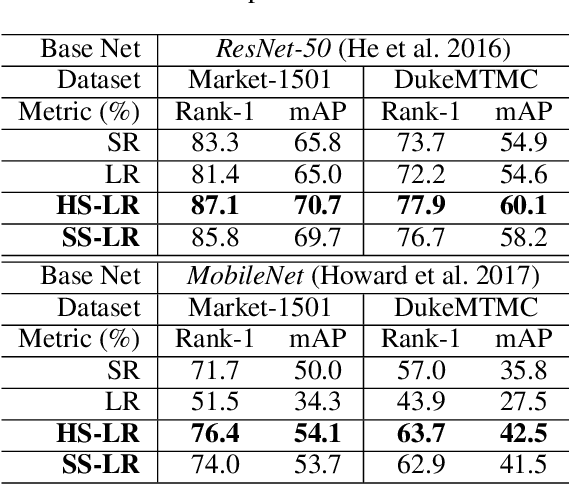
The objective learning formulation is essential for the success of convolutional neural networks. In this work, we analyse thoroughly the standard learning objective functions for multi-class classification CNNs: softmax regression (SR) for single-label scenario and logistic regression (LR) for multi-label scenario. Our analyses lead to an inspiration of exploiting LR for single-label classification learning, and then the disclosing of the negative class distraction problem in LR. To address this problem, we develop two novel LR based objective functions that not only generalise the conventional LR but importantly turn out to be competitive alternatives to SR in single label classification. Extensive comparative evaluations demonstrate the model learning advantages of the proposed LR functions over the commonly adopted SR in single-label coarse-grained object categorisation and cross-class fine-grained person instance identification tasks. We also show the performance superiority of our method on clothing attribute classification in comparison to the vanilla LR function.
Self-Referenced Deep Learning
Nov 19, 2018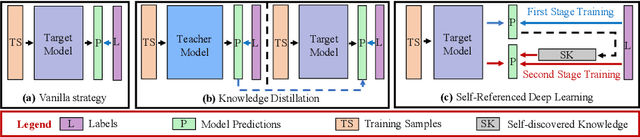
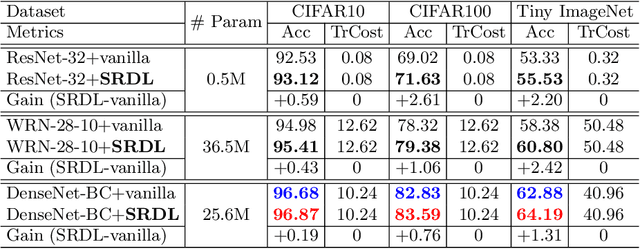
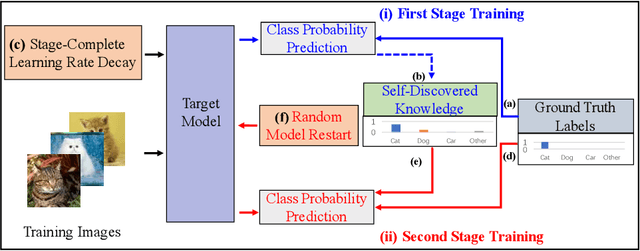
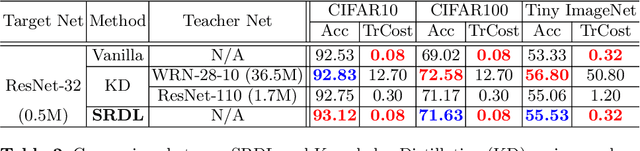
Knowledge distillation is an effective approach to transferring knowledge from a teacher neural network to a student target network for satisfying the low-memory and fast running requirements in practice use. Whilst being able to create stronger target networks compared to the vanilla non-teacher based learning strategy, this scheme needs to train additionally a large teacher model with expensive computational cost. In this work, we present a Self-Referenced Deep Learning (SRDL) strategy. Unlike both vanilla optimisation and existing knowledge distillation, SRDL distils the knowledge discovered by the in-training target model back to itself to regularise the subsequent learning procedure therefore eliminating the need for training a large teacher model. SRDL improves the model generalisation performance compared to vanilla learning and conventional knowledge distillation approaches with negligible extra computational cost. Extensive evaluations show that a variety of deep networks benefit from SRDL resulting in enhanced deployment performance on both coarse-grained object categorisation tasks (CIFAR10, CIFAR100, Tiny ImageNet, and ImageNet) and fine-grained person instance identification tasks (Market-1501).
Open Logo Detection Challenge
Sep 27, 2018



Existing logo detection benchmarks consider artificial deployment scenarios by assuming that large training data with fine-grained bounding box annotations for each class are available for model training. Such assumptions are often invalid in realistic logo detection scenarios where new logo classes come progressively and require to be detected with little or none budget for exhaustively labelling fine-grained training data for every new class. Existing benchmarks are thus unable to evaluate the true performance of a logo detection method in realistic and open deployments. In this work, we introduce a more realistic and challenging logo detection setting, called Open Logo Detection. Specifically, this new setting assumes fine-grained labelling only on a small proportion of logo classes whilst the remaining classes have no labelled training data to simulate the open deployment. We further create an open logo detection benchmark, called OpenLogo,to promote the investigation of this new challenge. OpenLogo contains 27,083 images from 352 logo classes, built by aggregating/refining 7 existing datasets and establishing an open logo detection evaluation protocol. To address this challenge, we propose a Context Adversarial Learning (CAL) approach to synthesising training data with coherent logo instance appearance against diverse background context for enabling more effective optimisation of contemporary deep learning detection models. Experiments show the performance advantage of CAL over existing state-of-the-art alternative methods on the more realistic and challenging OpenLogo benchmark.
Vehicle Re-Identification in Context
Sep 26, 2018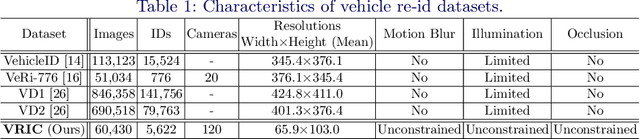



Existing vehicle re-identification (re-id) evaluation benchmarks consider strongly artificial test scenarios by assuming the availability of high quality images and fine-grained appearance at an almost constant image scale, reminiscent to images required for Automatic Number Plate Recognition, e.g. VeRi-776. Such assumptions are often invalid in realistic vehicle re-id scenarios where arbitrarily changing image resolutions (scales) are the norm. This makes the existing vehicle re-id benchmarks limited for testing the true performance of a re-id method. In this work, we introduce a more realistic and challenging vehicle re-id benchmark, called Vehicle Re-Identification in Context (VRIC). In contrast to existing datasets, VRIC is uniquely characterised by vehicle images subject to more realistic and unconstrained variations in resolution (scale), motion blur, illumination, occlusion, and viewpoint. It contains 60,430 images of 5,622 vehicle identities captured by 60 different cameras at heterogeneous road traffic scenes in both day-time and night-time.