 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedDistill: A Geometric Knowledge Distillation for Information Retrieval
Jan 27, 2023



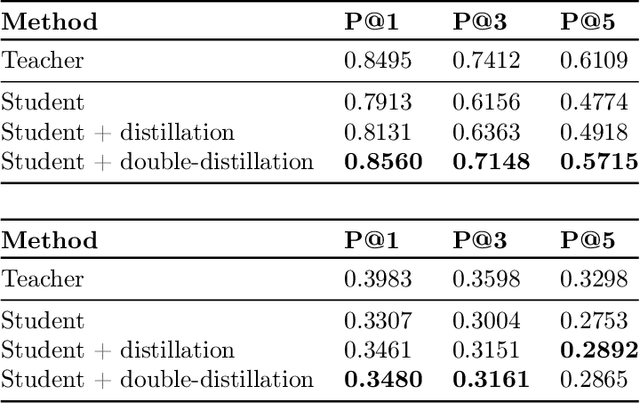
Large neural models (such as Transformers) achieve state-of-the-art performance for information retrieval (IR). In this paper, we aim to improve distillation methods that pave the way for the deployment of such models in practice. The proposed distillation approach supports both retrieval and re-ranking stages and crucially leverages the relative geometry among queries and documents learned by the large teacher model. It goes beyond existing distillation methods in the IR literature, which simply rely on the teacher's scalar scores over the training data, on two fronts: providing stronger signals about local geometry via embedding matching and attaining better coverage of data manifold globally via query generation. Embedding matching provides a stronger signal to align the representations of the teacher and student models. At the same time, query generation explores the data manifold to reduce the discrepancies between the student and teacher where training data is sparse. Our distillation approach is theoretically justified and applies to both dual encoder (DE) and cross-encoder (CE) models. Furthermore, for distilling a CE model to a DE model via embedding matching, we propose a novel dual pooling-based scorer for the CE model that facilitates a distillation-friendly embedding geometry, especially for DE student models.
Teacher Guided Training: An Efficient Framework for Knowledge Transfer
Aug 14, 2022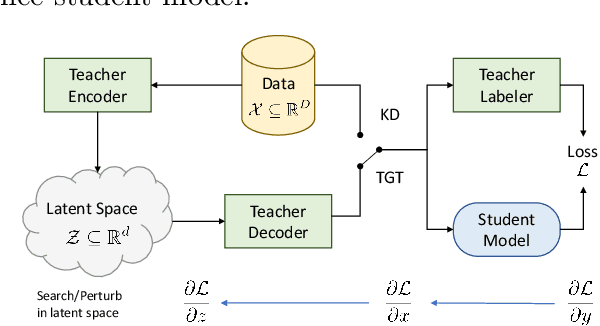
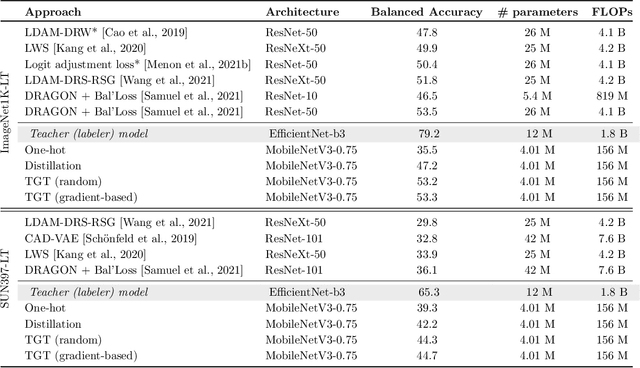
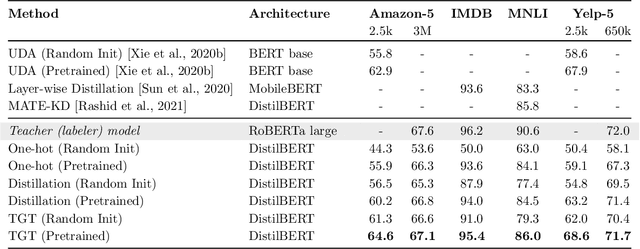
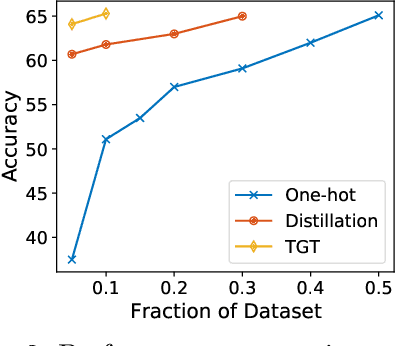
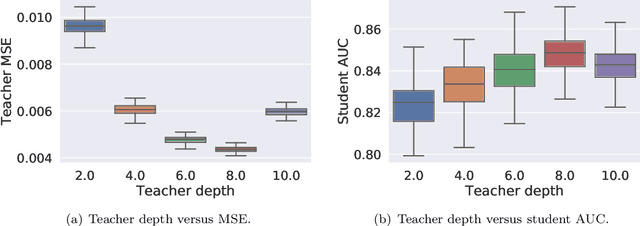
The remarkable performance gains realized by large pretrained models, e.g., GPT-3, hinge on the massive amounts of data they are exposed to during training. Analogously, distilling such large models to compact models for efficient deployment also necessitates a large amount of (labeled or unlabeled) training data. In this paper, we propose the teacher-guided training (TGT) framework for training a high-quality compact model that leverages the knowledge acquired by pretrained generative models, while obviating the need to go through a large volume of data. TGT exploits the fact that the teacher has acquired a good representation of the underlying data domain, which typically corresponds to a much lower dimensional manifold than the input space. Furthermore, we can use the teacher to explore input space more efficiently through sampling or gradient-based methods; thus, making TGT especially attractive for limited data or long-tail settings. We formally capture this benefit of proposed data-domain exploration in our generalization bounds. We find that TGT can improve accuracy on several image classification benchmarks as well as a range of text classification and retrieval tasks.
Balancing Robustness and Sensitivity using Feature Contrastive Learning
May 19, 2021
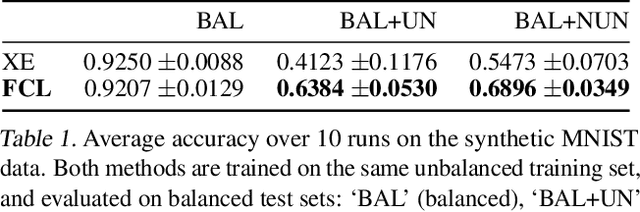
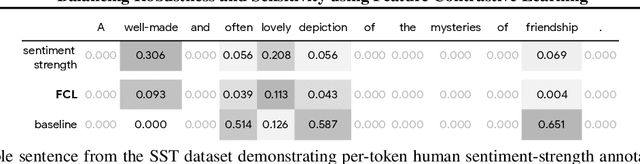
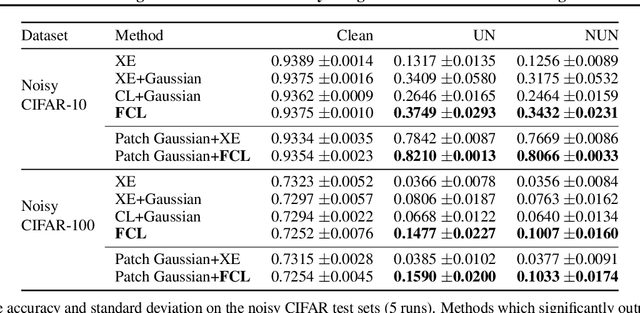
It is generally believed that robust training of extremely large networks is critical to their success in real-world applications. However, when taken to the extreme, methods that promote robustness can hurt the model's sensitivity to rare or underrepresented patterns. In this paper, we discuss this trade-off between sensitivity and robustness to natural (non-adversarial) perturbations by introducing two notions: contextual feature utility and contextual feature sensitivity. We propose Feature Contrastive Learning (FCL) that encourages a model to be more sensitive to the features that have higher contextual utility. Empirical results demonstrate that models trained with FCL achieve a better balance of robustness and sensitivity, leading to improved generalization in the presence of noise on both vision and NLP datasets.
On the Reproducibility of Neural Network Predictions
Feb 05, 2021

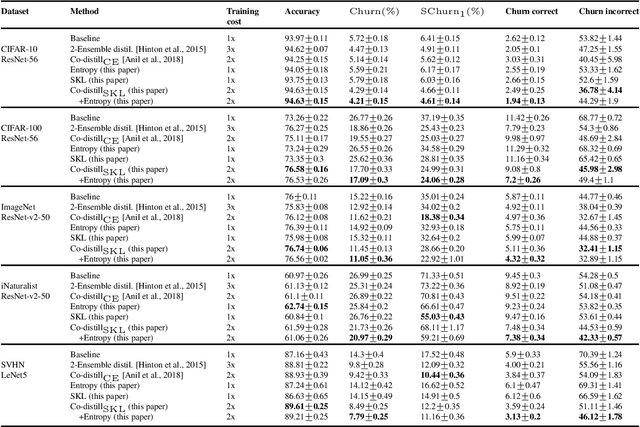
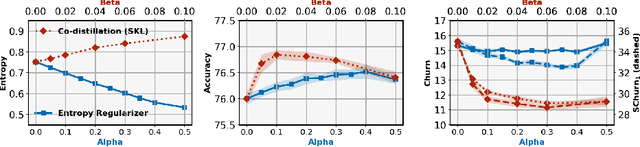
Standard training techniques for neural networks involve multiple sources of randomness, e.g., initialization, mini-batch ordering and in some cases data augmentation. Given that neural networks are heavily over-parameterized in practice, such randomness can cause {\em churn} -- for the same input, disagreements between predictions of the two models independently trained by the same algorithm, contributing to the `reproducibility challenges' in modern machine learning. In this paper, we study this problem of churn, identify factors that cause it, and propose two simple means of mitigating it. We first demonstrate that churn is indeed an issue, even for standard image classification tasks (CIFAR and ImageNet), and study the role of the different sources of training randomness that cause churn. By analyzing the relationship between churn and prediction confidences, we pursue an approach with two components for churn reduction. First, we propose using \emph{minimum entropy regularizers} to increase prediction confidences. Second, \changes{we present a novel variant of co-distillation approach~\citep{anil2018large} to increase model agreement and reduce churn}. We present empirical results showing the effectiveness of both techniques in reducing churn while improving the accuracy of the underlying model.
Semantic Label Smoothing for Sequence to Sequence Problems
Oct 15, 2020
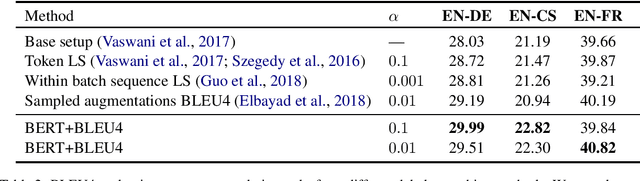

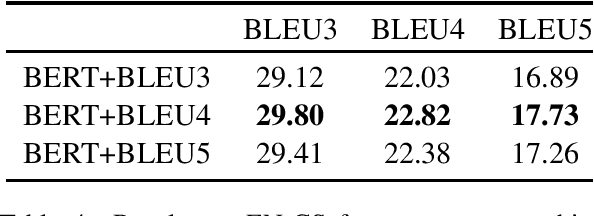
Label smoothing has been shown to be an effective regularization strategy in classification, that prevents overfitting and helps in label de-noising. However, extending such methods directly to seq2seq settings, such as Machine Translation, is challenging: the large target output space of such problems makes it intractable to apply label smoothing over all possible outputs. Most existing approaches for seq2seq settings either do token level smoothing, or smooth over sequences generated by randomly substituting tokens in the target sequence. Unlike these works, in this paper, we propose a technique that smooths over \emph{well formed} relevant sequences that not only have sufficient n-gram overlap with the target sequence, but are also \emph{semantically similar}. Our method shows a consistent and significant improvement over the state-of-the-art techniques on different datasets.
Evaluations and Methods for Explanation through Robustness Analysis
May 31, 2020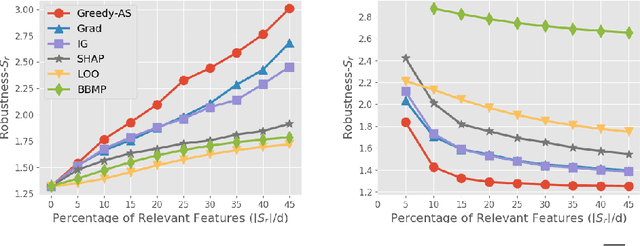


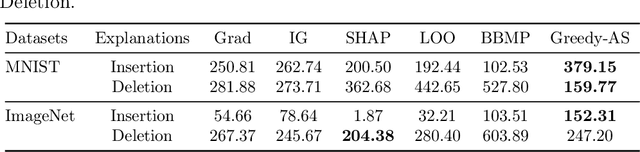
Among multiple ways of interpreting a machine learning model, measuring the importance of a set of features tied to a prediction is probably one of the most intuitive ways to explain a model. In this paper, we establish the link between a set of features to a prediction with a new evaluation criterion, robustness analysis, which measures the minimum distortion distance of adversarial perturbation. By measuring the tolerance level for an adversarial attack, we can extract a set of features that provides the most robust support for a prediction, and also can extract a set of features that contrasts the current prediction to a target class by setting a targeted adversarial attack. By applying this methodology to various prediction tasks across multiple domains, we observe the derived explanations are indeed capturing the significant feature set qualitatively and quantitatively.
Why distillation helps: a statistical perspective
May 21, 2020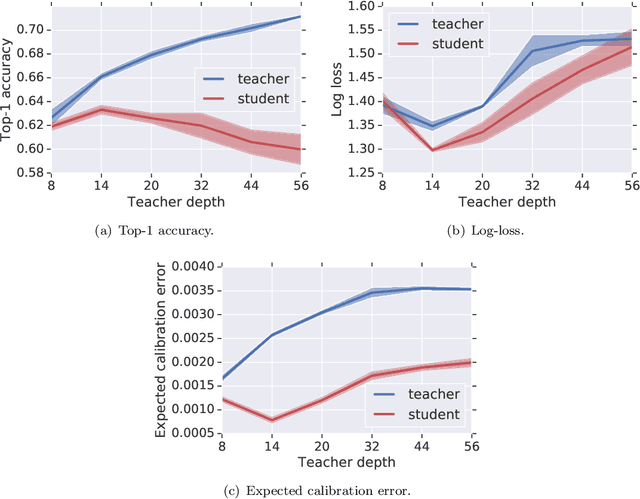
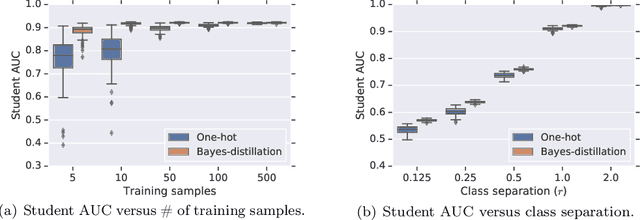
Knowledge distillation is a technique for improving the performance of a simple "student" model by replacing its one-hot training labels with a distribution over labels obtained from a complex "teacher" model. While this simple approach has proven widely effective, a basic question remains unresolved: why does distillation help? In this paper, we present a statistical perspective on distillation which addresses this question, and provides a novel connection to extreme multiclass retrieval techniques. Our core observation is that the teacher seeks to estimate the underlying (Bayes) class-probability function. Building on this, we establish a fundamental bias-variance tradeoff in the student's objective: this quantifies how approximate knowledge of these class-probabilities can significantly aid learning. Finally, we show how distillation complements existing negative mining techniques for extreme multiclass retrieval, and propose a unified objective which combines these ideas.
Why ADAM Beats SGD for Attention Models
Dec 06, 2019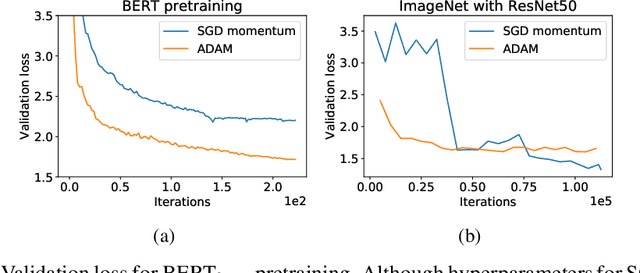

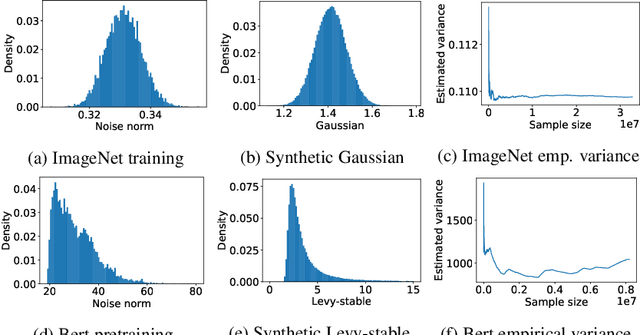

While stochastic gradient descent (SGD) is still the de facto algorithm in deep learning, adaptive methods like Adam have been observed to outperform SGD across important tasks, such as attention models. The settings under which SGD performs poorly in comparison to Adam are not well understood yet. In this paper, we provide empirical and theoretical evidence that a heavy-tailed distribution of the noise in stochastic gradients is a root cause of SGD's poor performance. Based on this observation, we study clipped variants of SGD that circumvent this issue; we then analyze their convergence under heavy-tailed noise. Furthermore, we develop a new adaptive coordinate-wise clipping algorithm (ACClip) tailored to such settings. Subsequently, we show how adaptive methods like Adam can be viewed through the lens of clipping, which helps us explain Adam's strong performance under heavy-tail noise settings. Finally, we show that the proposed ACClip outperforms Adam for both BERT pretraining and finetuning tasks.
Local Space-Time Smoothing for Version Controlled Documents
Aug 08, 2013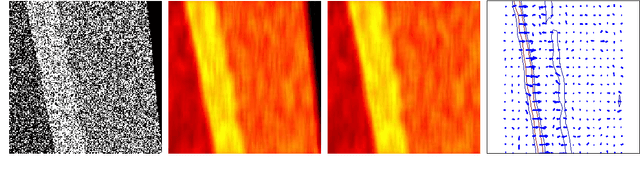
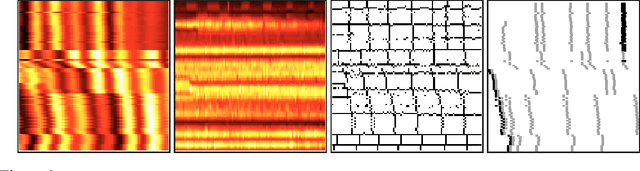
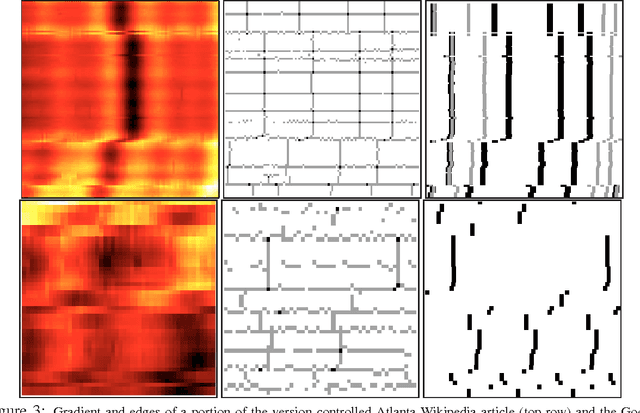

Unlike static documents, version controlled documents are continuously edited by one or more authors. Such collaborative revision process makes traditional modeling and visualization techniques inappropriate. In this paper we propose a new representation based on local space-time smoothing that captures important revision patterns. We demonstrate the applicability of our framework using experiments on synthetic and real-world data.
* 9 pages, 6 figures
Beyond Sentiment: The Manifold of Human Emotions
Aug 08, 2013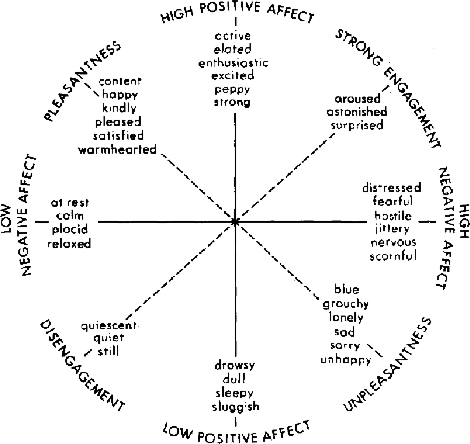
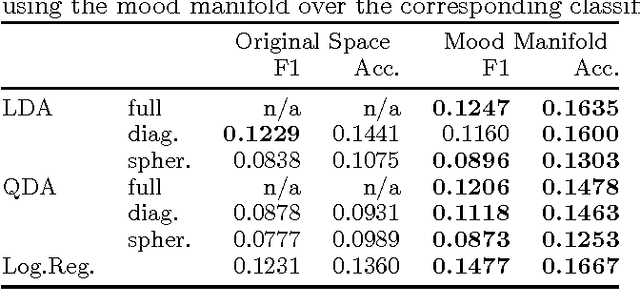

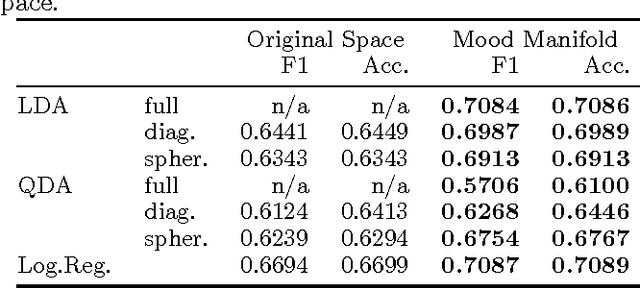
Sentiment analysis predicts the presence of positive or negative emotions in a text document. In this paper we consider higher dimensional extensions of the sentiment concept, which represent a richer set of human emotions. Our approach goes beyond previous work in that our model contains a continuous manifold rather than a finite set of human emotions. We investigate the resulting model, compare it to psychological observations, and explore its predictive capabilities. Besides obtaining significant improvements over a baseline without manifold, we are also able to visualize different notions of positive sentiment in different domains.
* 15 pages, 7 figures