 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLineRides: Line-Guided Reinforcement Learning for Bicycle Robot Stunts
May 06, 2026Designing reward functions for agile robotic maneuvers in reinforcement learning remains difficult, and demonstration-based approaches often require reference motions that are unavailable for novel platforms or extreme stunts. We present LineRides, a line-guided learning framework that enables a custom bicycle robot to acquire diverse, commandable stunt behaviors from a user-provided spatial guideline and sparse key-orientations, without demonstrations or explicit timing. LineRides handles physically infeasible guidelines using a tracking margin that permits controlled deviation, resolves temporal ambiguity by measuring progress via traveled distance along the guideline, and disambiguates motion details through position- and sequence-based key-orientations. We evaluate LineRides on the Ultra Mobility Vehicle (UMV) and show that the policy trained with our methods supports seamless transitions between normal driving and stunt execution, enabling five distinct stunts on command: MiniHop, LargeHop, ThreePointTurn, Backflip, and DriftTurn.
Flip Stunts on Bicycle Robots using Iterative Motion Imitation
Mar 30, 2026This work demonstrates a front-flip on bicycle robots via reinforcement learning, particularly by imitating reference motions that are infeasible and imperfect. To address this, we propose Iterative Motion Imitation(IMI), a method that iteratively imitates trajectories generated by prior policy rollouts. Starting from an initial reference that is kinematically or dynamically infeasible, IMI helps train policies that lead to feasible and agile behaviors. We demonstrate our method on Ultra-Mobility Vehicle (UMV), a bicycle robot that is designed to enable agile behaviors. From a self-colliding table-to-ground flip reference generated by a model-based controller, we are able to train policies that enable ground-to-ground and ground-to-table front-flips. We show that compared to a single-shot motion imitation, IMI results in policies with higher success rates and can transfer robustly to the real world. To our knowledge, this is the first unassisted acrobatic flip behavior on such a platform.
Angular Center of Mass for Humanoid Robots
Oct 14, 2022
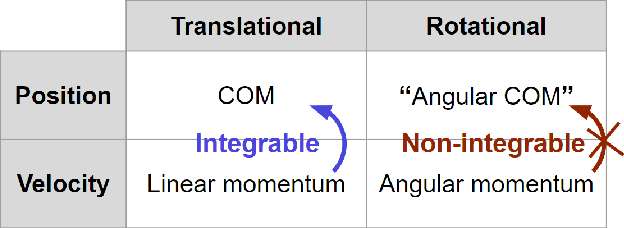
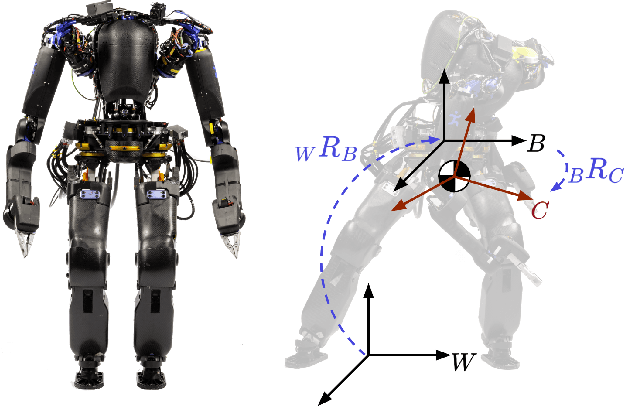
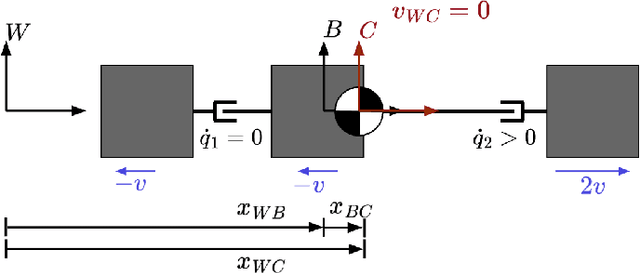
The center of mass (CoM) has been widely used in planning and control for humanoid locomotion, because it carries key information about the position of a robot. In contrast, an ''angular center of mass'' (ACoM), which provides an ''average'' orientation of a robot, is less well-known in the community, although the concept has been in the literature for about a decade. In this paper, we introduce the ACoM from a CoM perspective. We optimize for an ACoM on the humanoid robot Nadia, and demonstrate its application in walking with natural upper body motion on hardware.