 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIPPI2021: An Approach to Automated Diagnosis and Texture Analysis of the Fetal Liver & Placenta in Fetal Growth Restriction
Nov 01, 2022



Fetal growth restriction (FGR) is a prevalent pregnancy condition characterised by failure of the fetus to reach its genetically predetermined growth potential. We explore the application of model fitting techniques, linear regression machine learning models, deep learning regression, and Haralick textured features from multi-contrast MRI for multi-fetal organ analysis of FGR. We employed T2 relaxometry and diffusion-weighted MRI datasets (using a combined T2-diffusion scan) for 12 normally grown and 12 FGR gestational age (GA) matched pregnancies. We applied the Intravoxel Incoherent Motion Model and novel multi-compartment models for MRI fetal analysis, which exhibit potential to provide a multi-organ FGR assessment, overcoming the limitations of empirical indicators - such as abnormal artery Doppler findings - to evaluate placental dysfunction. The placenta and fetal liver presented key differentiators between FGR and normal controls (decreased perfusion, abnormal fetal blood motion and reduced fetal blood oxygenation. This may be associated with the preferential shunting of the fetal blood towards the fetal brain. These features were further explored to determine their role in assessing FGR severity, by employing simple machine learning models to predict FGR diagnosis (100\% accuracy in test data, n=5), GA at delivery, time from MRI scan to delivery, and baby weight. Moreover, we explored the use of deep learning to regress the latter three variables. Image texture analysis of the fetal organs demonstrated prominent textural variations in the placental perfusion fractions maps between the groups (p$<$0.0009), and spatial differences in the incoherent fetal capillary blood motion in the liver (p$<$0.009). This research serves as a proof-of-concept, investigating the effect of FGR on fetal organs.
Rapid and robust endoscopic content area estimation: A lean GPU-based pipeline and curated benchmark dataset
Oct 26, 2022Endoscopic content area refers to the informative area enclosed by the dark, non-informative, border regions present in most endoscopic footage. The estimation of the content area is a common task in endoscopic image processing and computer vision pipelines. Despite the apparent simplicity of the problem, several factors make reliable real-time estimation surprisingly challenging. The lack of rigorous investigation into the topic combined with the lack of a common benchmark dataset for this task has been a long-lasting issue in the field. In this paper, we propose two variants of a lean GPU-based computational pipeline combining edge detection and circle fitting. The two variants differ by relying on handcrafted features, and learned features respectively to extract content area edge point candidates. We also present a first-of-its-kind dataset of manually annotated and pseudo-labelled content areas across a range of surgical indications. To encourage further developments, the curated dataset, and an implementation of both algorithms, has been made public (https://doi.org/10.7303/syn32148000, https://github.com/charliebudd/torch-content-area). We compare our proposed algorithm with a state-of-the-art U-Net-based approach and demonstrate significant improvement in terms of both accuracy (Hausdorff distance: 6.3 px versus 118.1 px) and computational time (Average runtime per frame: 0.13 ms versus 11.2 ms).
Brain Imaging Generation with Latent Diffusion Models
Sep 15, 2022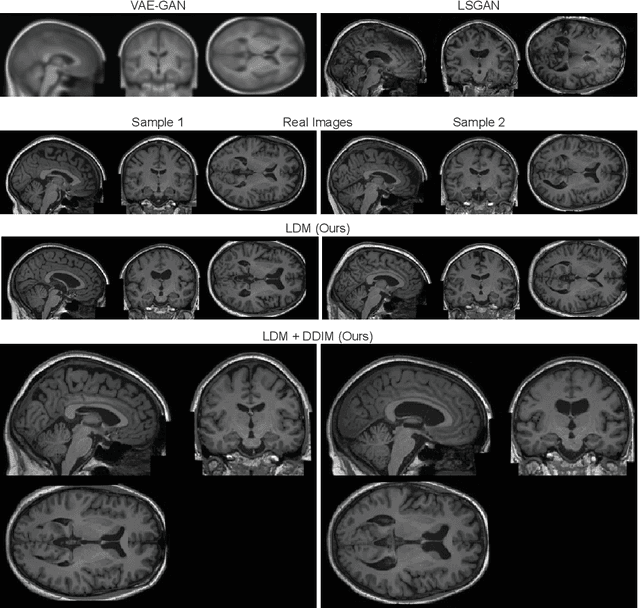
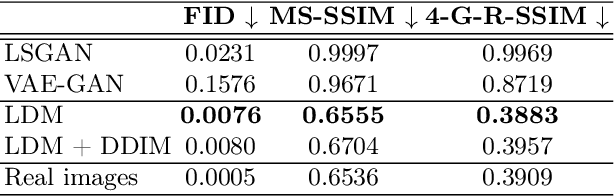
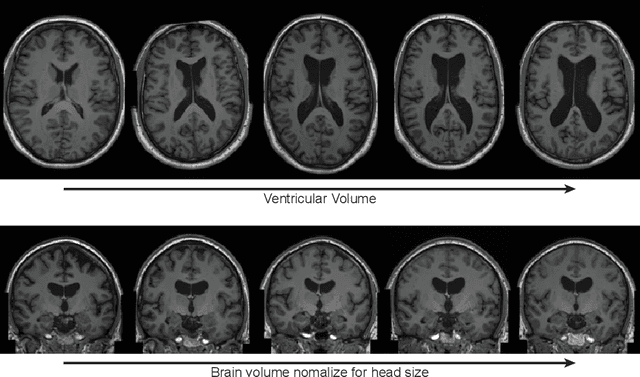
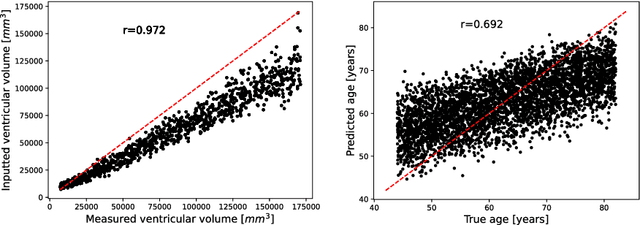
Deep neural networks have brought remarkable breakthroughs in medical image analysis. However, due to their data-hungry nature, the modest dataset sizes in medical imaging projects might be hindering their full potential. Generating synthetic data provides a promising alternative, allowing to complement training datasets and conducting medical image research at a larger scale. Diffusion models recently have caught the attention of the computer vision community by producing photorealistic synthetic images. In this study, we explore using Latent Diffusion Models to generate synthetic images from high-resolution 3D brain images. We used T1w MRI images from the UK Biobank dataset (N=31,740) to train our models to learn about the probabilistic distribution of brain images, conditioned on covariables, such as age, sex, and brain structure volumes. We found that our models created realistic data, and we could use the conditioning variables to control the data generation effectively. Besides that, we created a synthetic dataset with 100,000 brain images and made it openly available to the scientific community.
Morphology-preserving Autoregressive 3D Generative Modelling of the Brain
Sep 07, 2022
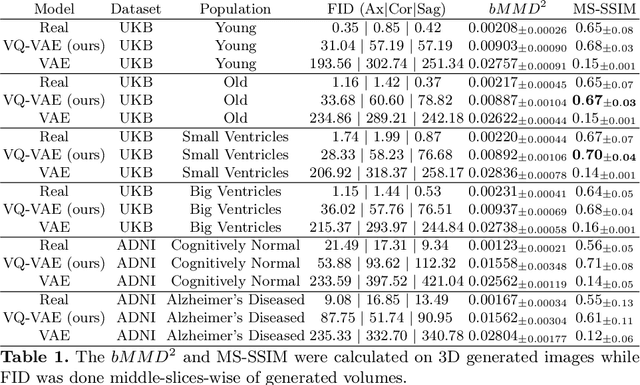
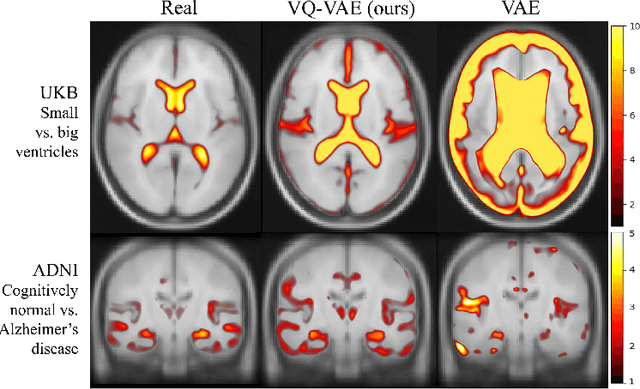
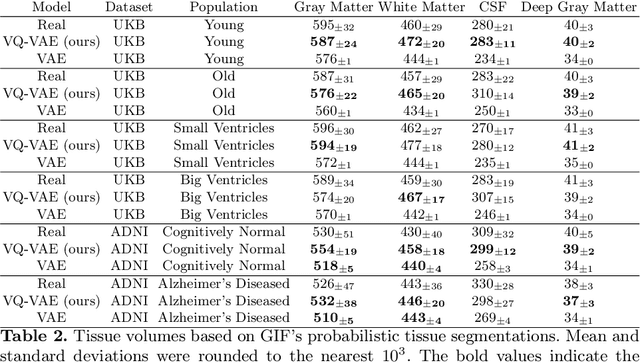
Human anatomy, morphology, and associated diseases can be studied using medical imaging data. However, access to medical imaging data is restricted by governance and privacy concerns, data ownership, and the cost of acquisition, thus limiting our ability to understand the human body. A possible solution to this issue is the creation of a model able to learn and then generate synthetic images of the human body conditioned on specific characteristics of relevance (e.g., age, sex, and disease status). Deep generative models, in the form of neural networks, have been recently used to create synthetic 2D images of natural scenes. Still, the ability to produce high-resolution 3D volumetric imaging data with correct anatomical morphology has been hampered by data scarcity and algorithmic and computational limitations. This work proposes a generative model that can be scaled to produce anatomically correct, high-resolution, and realistic images of the human brain, with the necessary quality to allow further downstream analyses. The ability to generate a potentially unlimited amount of data not only enables large-scale studies of human anatomy and pathology without jeopardizing patient privacy, but also significantly advances research in the field of anomaly detection, modality synthesis, learning under limited data, and fair and ethical AI. Code and trained models are available at: https://github.com/AmigoLab/SynthAnatomy.
Driving Points Prediction For Abdominal Probabilistic Registration
Aug 05, 2022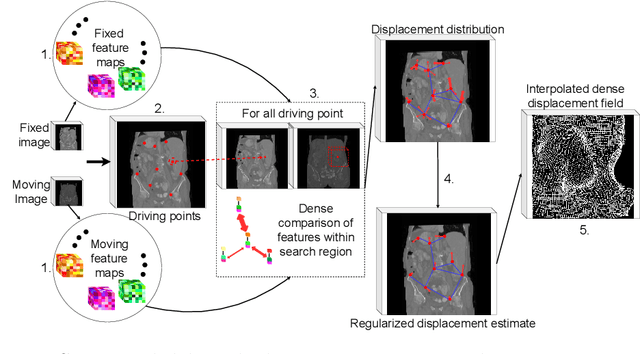
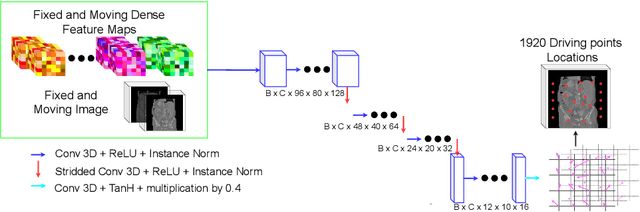
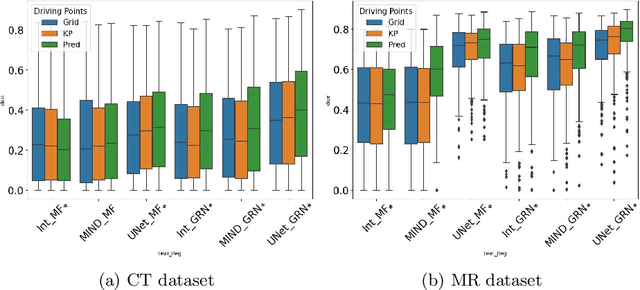
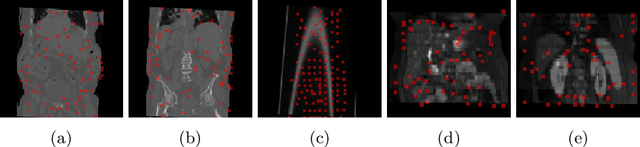
Inter-patient abdominal registration has various applications, from pharmakinematic studies to anatomy modeling. Yet, it remains a challenging application due to the morphological heterogeneity and variability of the human abdomen. Among the various registration methods proposed for this task, probabilistic displacement registration models estimate displacement distribution for a subset of points by comparing feature vectors of points from the two images. These probabilistic models are informative and robust while allowing large displacements by design. As the displacement distributions are typically estimated on a subset of points (which we refer to as driving points), due to computational requirements, we propose in this work to learn a driving points predictor. Compared to previously proposed methods, the driving points predictor is optimized in an end-to-end fashion to infer driving points tailored for a specific registration pipeline. We evaluate the impact of our contribution on two different datasets corresponding to different modalities. Specifically, we compared the performances of 6 different probabilistic displacement registration models when using a driving points predictor or one of 2 other standard driving points selection methods. The proposed method improved performances in 11 out of 12 experiments.
Brain Lesion Synthesis via Progressive Adversarial Variational Auto-Encoder
Aug 05, 2022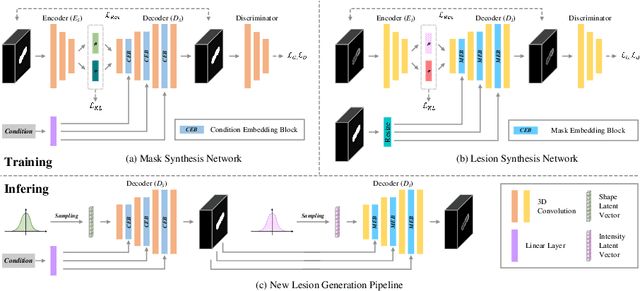
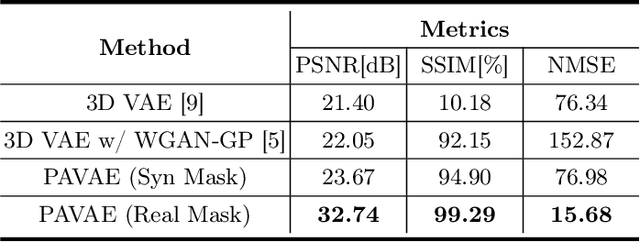
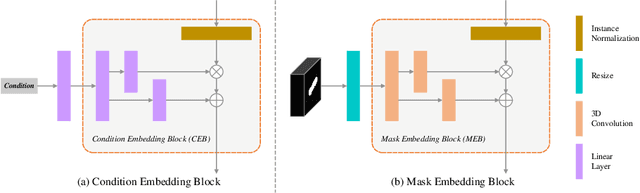
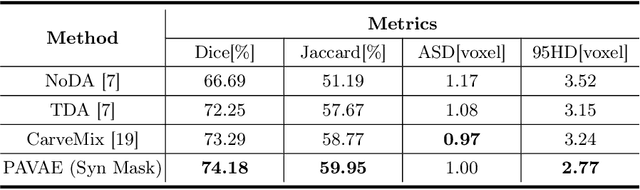
Laser interstitial thermal therapy (LITT) is a novel minimally invasive treatment that is used to ablate intracranial structures to treat mesial temporal lobe epilepsy (MTLE). Region of interest (ROI) segmentation before and after LITT would enable automated lesion quantification to objectively assess treatment efficacy. Deep learning techniques, such as convolutional neural networks (CNNs) are state-of-the-art solutions for ROI segmentation, but require large amounts of annotated data during the training. However, collecting large datasets from emerging treatments such as LITT is impractical. In this paper, we propose a progressive brain lesion synthesis framework (PAVAE) to expand both the quantity and diversity of the training dataset. Concretely, our framework consists of two sequential networks: a mask synthesis network and a mask-guided lesion synthesis network. To better employ extrinsic information to provide additional supervision during network training, we design a condition embedding block (CEB) and a mask embedding block (MEB) to encode inherent conditions of masks to the feature space. Finally, a segmentation network is trained using raw and synthetic lesion images to evaluate the effectiveness of the proposed framework. Experimental results show that our method can achieve realistic synthetic results and boost the performance of down-stream segmentation tasks above traditional data augmentation techniques.
Fitting Segmentation Networks on Varying Image Resolutions using Splatting
Jun 15, 2022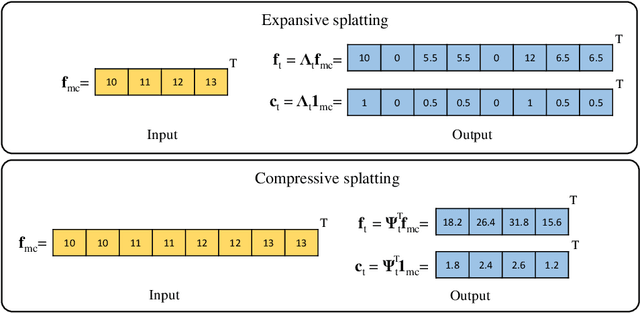
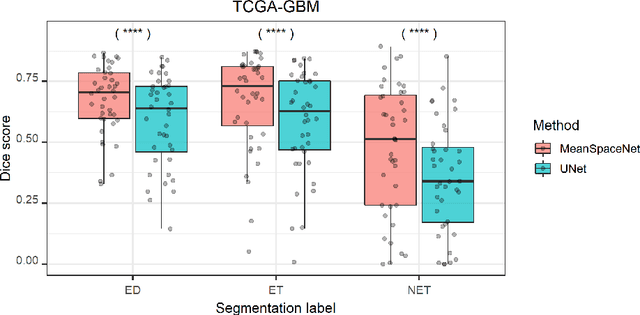
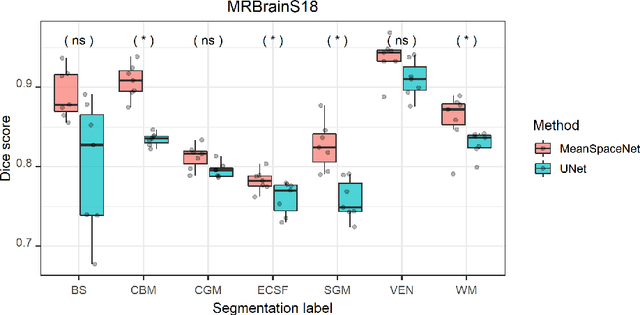
Data used in image segmentation are not always defined on the same grid. This is particularly true for medical images, where the resolution, field-of-view and orientation can differ across channels and subjects. Images and labels are therefore commonly resampled onto the same grid, as a pre-processing step. However, the resampling operation introduces partial volume effects and blurring, thereby changing the effective resolution and reducing the contrast between structures. In this paper we propose a splat layer, which automatically handles resolution mismatches in the input data. This layer pushes each image onto a mean space where the forward pass is performed. As the splat operator is the adjoint to the resampling operator, the mean-space prediction can be pulled back to the native label space, where the loss function is computed. Thus, the need for explicit resolution adjustment using interpolation is removed. We show on two publicly available datasets, with simulated and real multi-modal magnetic resonance images, that this model improves segmentation results compared to resampling as a pre-processing step.
Fast Unsupervised Brain Anomaly Detection and Segmentation with Diffusion Models
Jun 07, 2022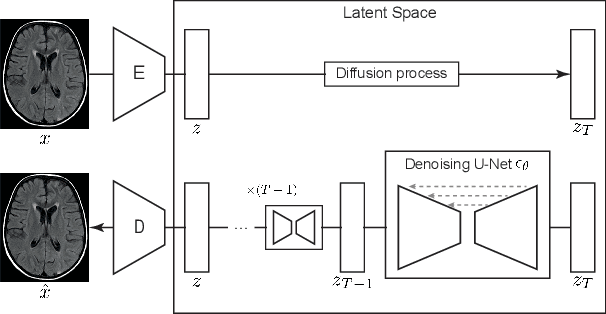
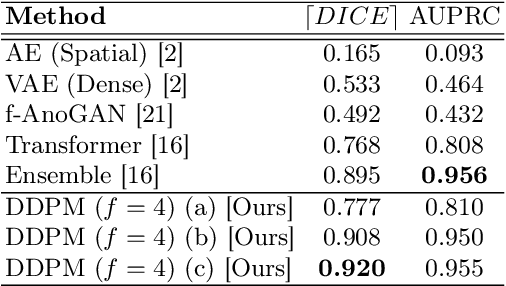
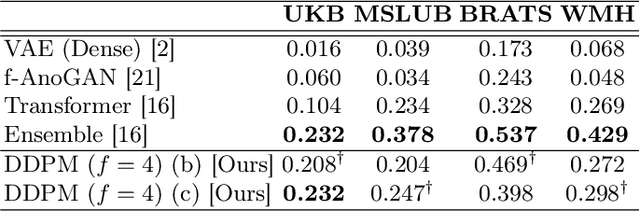
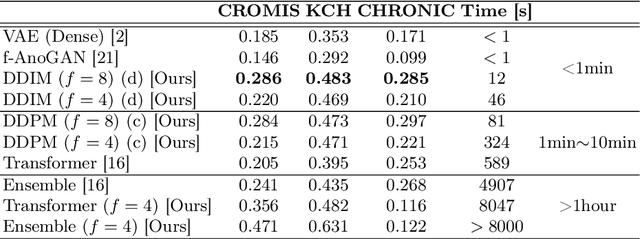
Deep generative models have emerged as promising tools for detecting arbitrary anomalies in data, dispensing with the necessity for manual labelling. Recently, autoregressive transformers have achieved state-of-the-art performance for anomaly detection in medical imaging. Nonetheless, these models still have some intrinsic weaknesses, such as requiring images to be modelled as 1D sequences, the accumulation of errors during the sampling process, and the significant inference times associated with transformers. Denoising diffusion probabilistic models are a class of non-autoregressive generative models recently shown to produce excellent samples in computer vision (surpassing Generative Adversarial Networks), and to achieve log-likelihoods that are competitive with transformers while having fast inference times. Diffusion models can be applied to the latent representations learnt by autoencoders, making them easily scalable and great candidates for application to high dimensional data, such as medical images. Here, we propose a method based on diffusion models to detect and segment anomalies in brain imaging. By training the models on healthy data and then exploring its diffusion and reverse steps across its Markov chain, we can identify anomalous areas in the latent space and hence identify anomalies in the pixel space. Our diffusion models achieve competitive performance compared with autoregressive approaches across a series of experiments with 2D CT and MRI data involving synthetic and real pathological lesions with much reduced inference times, making their usage clinically viable.
Transformer-based out-of-distribution detection for clinically safe segmentation
May 21, 2022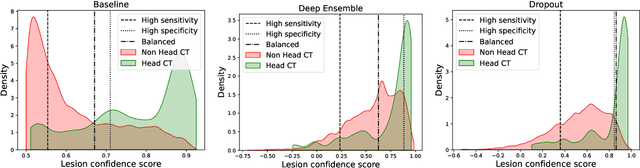
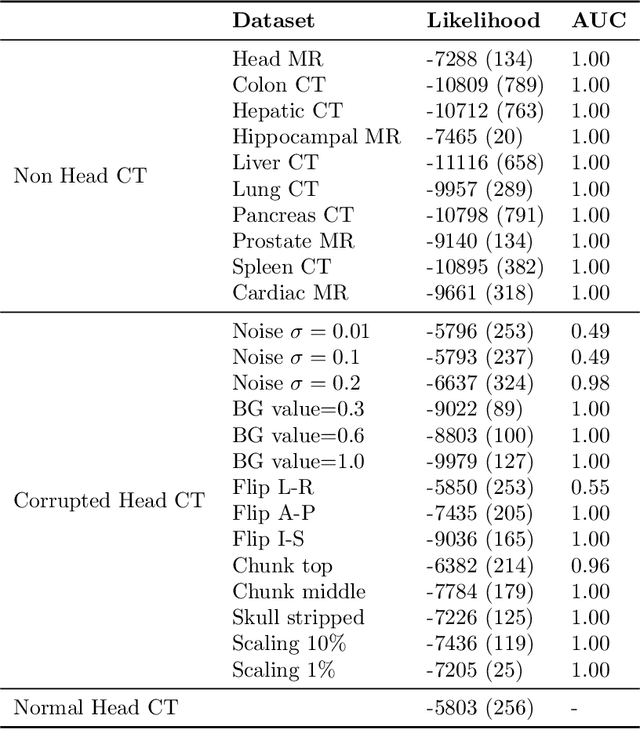
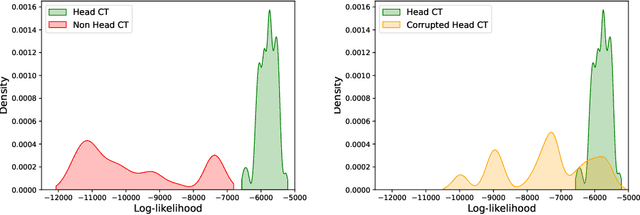
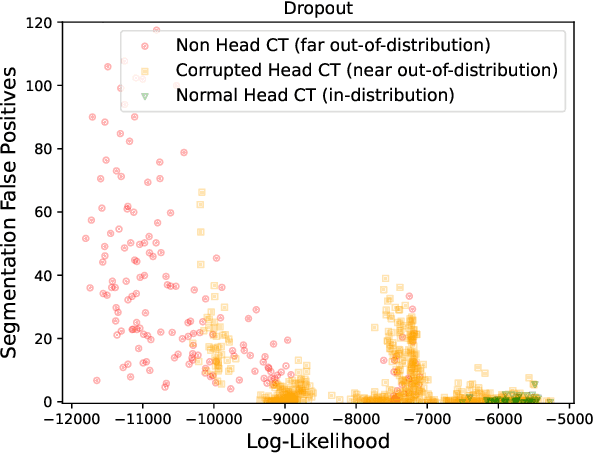
In a clinical setting it is essential that deployed image processing systems are robust to the full range of inputs they might encounter and, in particular, do not make confidently wrong predictions. The most popular approach to safe processing is to train networks that can provide a measure of their uncertainty, but these tend to fail for inputs that are far outside the training data distribution. Recently, generative modelling approaches have been proposed as an alternative; these can quantify the likelihood of a data sample explicitly, filtering out any out-of-distribution (OOD) samples before further processing is performed. In this work, we focus on image segmentation and evaluate several approaches to network uncertainty in the far-OOD and near-OOD cases for the task of segmenting haemorrhages in head CTs. We find all of these approaches are unsuitable for safe segmentation as they provide confidently wrong predictions when operating OOD. We propose performing full 3D OOD detection using a VQ-GAN to provide a compressed latent representation of the image and a transformer to estimate the data likelihood. Our approach successfully identifies images in both the far- and near-OOD cases. We find a strong relationship between image likelihood and the quality of a model's segmentation, making this approach viable for filtering images unsuitable for segmentation. To our knowledge, this is the first time transformers have been applied to perform OOD detection on 3D image data.
Ultrathin, high-speed, all-optical photoacoustic endomicroscopy probe for guiding minimally invasive surgery
May 06, 2022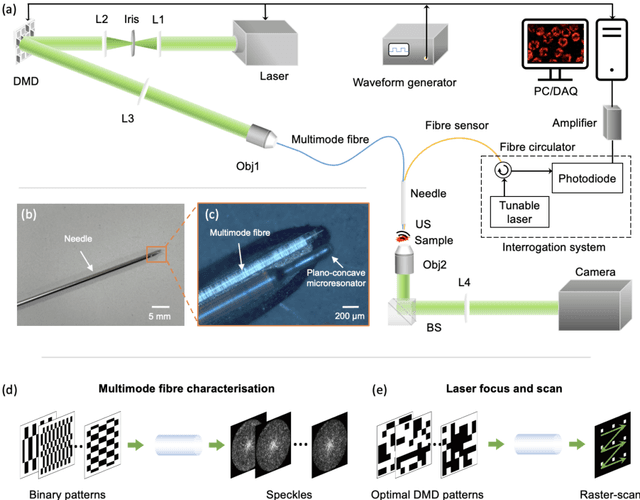
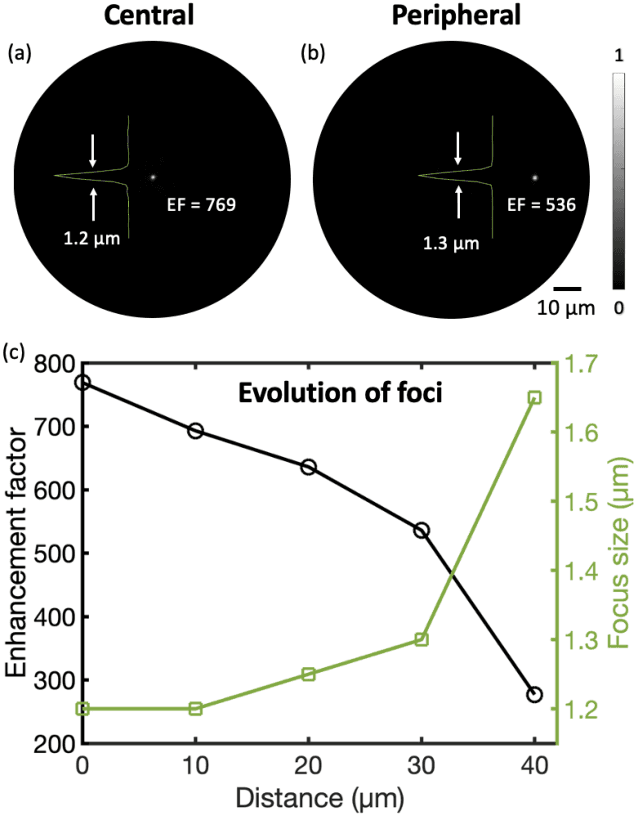
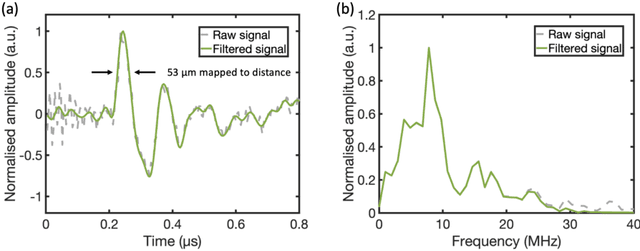
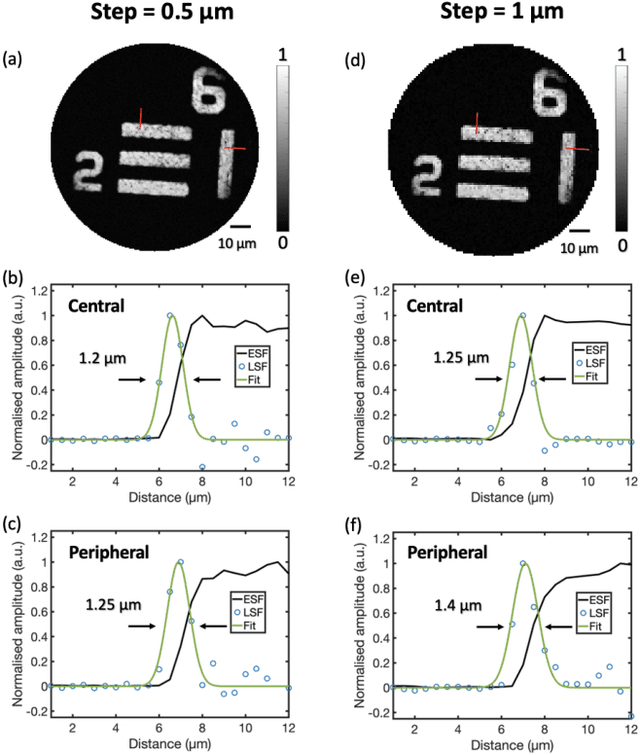
Photoacoustic (PA) endoscopy has shown significant potential for clinical diagnosis and surgical guidance. Multimode fibres (MMFs) are becoming increasing attractive for the development of miniature endoscopy probes owing to ultrathin size, low cost and diffraction-limited spatial resolution enabled by wavefront shaping. However, current MMF-based PA endomicroscopy probes are either limited by a bulky ultrasound detector or a low imaging speed which hindered their usability. In this work, we report the development of a highly miniaturised and high-speed PA endomicroscopy probe that is integrated within the cannula of a 20 gauge medical needle. This probe comprises a MMF for delivering the PA excitation light and a single-mode optical fibre with a plano-concave microresonator for ultrasound detection. Wavefront shaping with a digital micromirror device enabled rapid raster-scanning of a focused light spot at the distal end of the MMF for tissue interrogation. High-resolution PA imaging of mouse red blood cells covering an area 100 microns in diameter was achieved with the needle probe at ~3 frames per second. Mosaicing imaging was performed after fibre characterisation by translating the needle probe to enlarge the field-of-view in real-time. The developed ultrathin PA endomicroscopy probe is promising for guiding minimally invasive surgery by providing functional, molecular and microstructural information of tissue in real-time.