 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Computing for Large-scale Network Optimization: Opportunities and Challenges
Sep 09, 2025The complexity of large-scale 6G-and-beyond networks demands innovative approaches for multi-objective optimization over vast search spaces, a task often intractable. Quantum computing (QC) emerges as a promising technology for efficient large-scale optimization. We present our vision of leveraging QC to tackle key classes of problems in future mobile networks. By analyzing and identifying common features, particularly their graph-centric representation, we propose a unified strategy involving QC algorithms. Specifically, we outline a methodology for optimization using quantum annealing as well as quantum reinforcement learning. Additionally, we discuss the main challenges that QC algorithms and hardware must overcome to effectively optimize future networks.
Mind the XAI Gap: A Human-Centered LLM Framework for Democratizing Explainable AI
Jun 13, 2025Artificial Intelligence (AI) is rapidly embedded in critical decision-making systems, however their foundational ``black-box'' models require eXplainable AI (XAI) solutions to enhance transparency, which are mostly oriented to experts, making no sense to non-experts. Alarming evidence about AI's unprecedented human values risks brings forward the imperative need for transparent human-centered XAI solutions. In this work, we introduce a domain-, model-, explanation-agnostic, generalizable and reproducible framework that ensures both transparency and human-centered explanations tailored to the needs of both experts and non-experts. The framework leverages Large Language Models (LLMs) and employs in-context learning to convey domain- and explainability-relevant contextual knowledge into LLMs. Through its structured prompt and system setting, our framework encapsulates in one response explanations understandable by non-experts and technical information to experts, all grounded in domain and explainability principles. To demonstrate the effectiveness of our framework, we establish a ground-truth contextual ``thesaurus'' through a rigorous benchmarking with over 40 data, model, and XAI combinations for an explainable clustering analysis of a well-being scenario. Through a comprehensive quality and human-friendliness evaluation of our framework's explanations, we prove high content quality through strong correlations with ground-truth explanations (Spearman rank correlation=0.92) and improved interpretability and human-friendliness to non-experts through a user study (N=56). Our overall evaluation confirms trust in LLMs as HCXAI enablers, as our framework bridges the above Gaps by delivering (i) high-quality technical explanations aligned with foundational XAI methods and (ii) clear, efficient, and interpretable human-centered explanations for non-experts.
Variational Pseudo Marginal Methods for Jet Reconstruction in Particle Physics
Jun 05, 2024



Reconstructing jets, which provide vital insights into the properties and histories of subatomic particles produced in high-energy collisions, is a main problem in data analyses in collider physics. This intricate task deals with estimating the latent structure of a jet (binary tree) and involves parameters such as particle energy, momentum, and types. While Bayesian methods offer a natural approach for handling uncertainty and leveraging prior knowledge, they face significant challenges due to the super-exponential growth of potential jet topologies as the number of observed particles increases. To address this, we introduce a Combinatorial Sequential Monte Carlo approach for inferring jet latent structures. As a second contribution, we leverage the resulting estimator to develop a variational inference algorithm for parameter learning. Building on this, we introduce a variational family using a pseudo-marginal framework for a fully Bayesian treatment of all variables, unifying the generative model with the inference process. We illustrate our method's effectiveness through experiments using data generated with a collider physics generative model, highlighting superior speed and accuracy across a range of tasks.
Exact and Approximate Hierarchical Clustering Using A*
Apr 14, 2021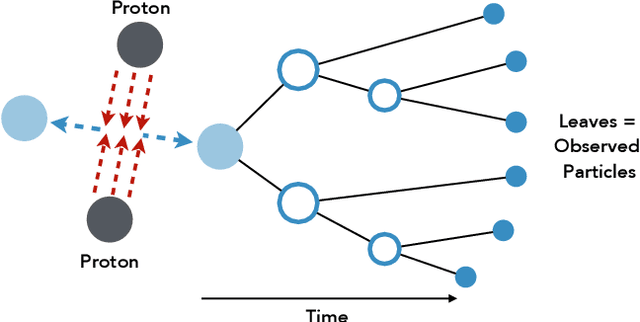
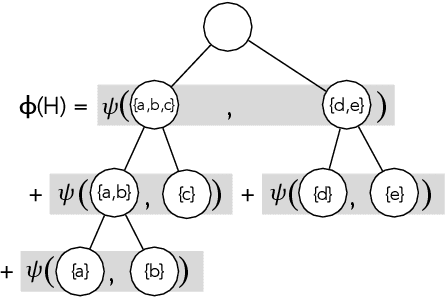
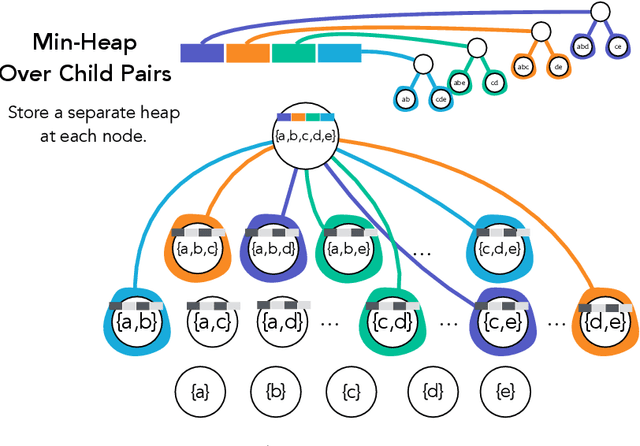
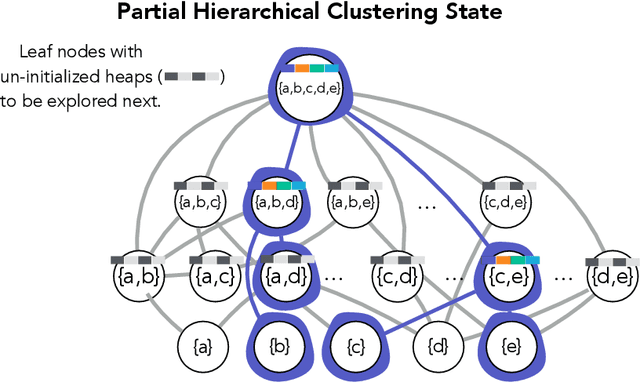
Hierarchical clustering is a critical task in numerous domains. Many approaches are based on heuristics and the properties of the resulting clusterings are studied post hoc. However, in several applications, there is a natural cost function that can be used to characterize the quality of the clustering. In those cases, hierarchical clustering can be seen as a combinatorial optimization problem. To that end, we introduce a new approach based on A* search. We overcome the prohibitively large search space by combining A* with a novel \emph{trellis} data structure. This combination results in an exact algorithm that scales beyond previous state of the art, from a search space with $10^{12}$ trees to $10^{15}$ trees, and an approximate algorithm that improves over baselines, even in enormous search spaces that contain more than $10^{1000}$ trees. We empirically demonstrate that our method achieves substantially higher quality results than baselines for a particle physics use case and other clustering benchmarks. We describe how our method provides significantly improved theoretical bounds on the time and space complexity of A* for clustering.
Hierarchical clustering in particle physics through reinforcement learning
Nov 16, 2020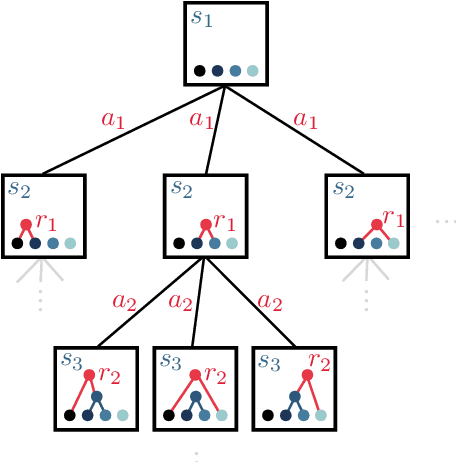
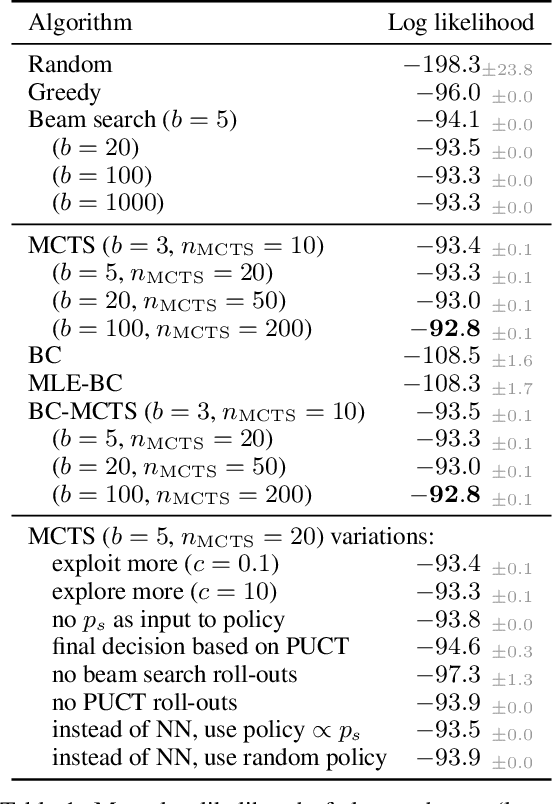
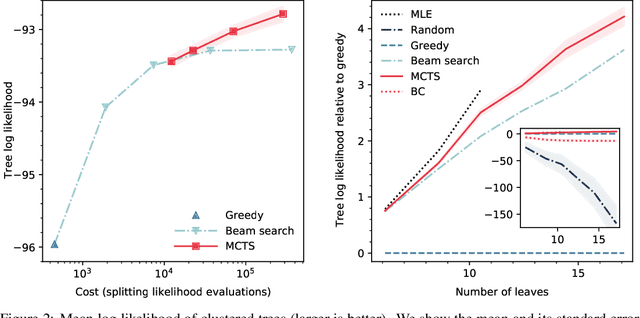
Particle physics experiments often require the reconstruction of decay patterns through a hierarchical clustering of the observed final-state particles. We show that this task can be phrased as a Markov Decision Process and adapt reinforcement learning algorithms to solve it. In particular, we show that Monte-Carlo Tree Search guided by a neural policy can construct high-quality hierarchical clusterings and outperform established greedy and beam search baselines.
Compact Representation of Uncertainty in Hierarchical Clustering
Feb 26, 2020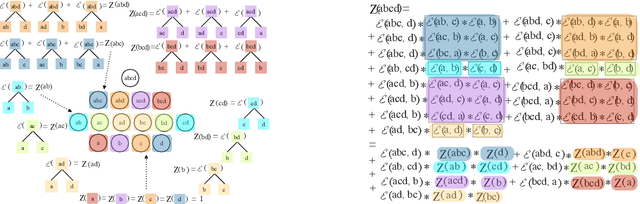
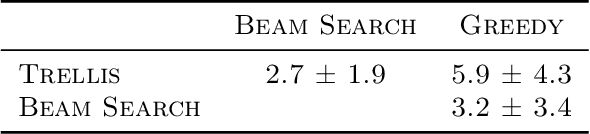
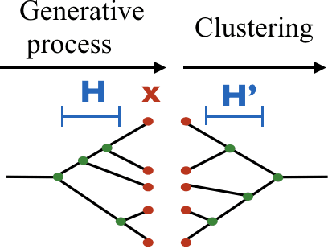
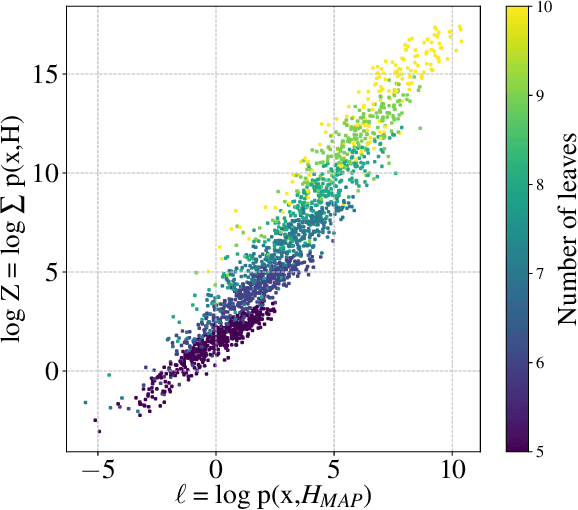
Hierarchical clustering is a fundamental task often used to discover meaningful structures in data, such as phylogenetic trees, taxonomies of concepts, subtypes of cancer, and cascades of particle decays in particle physics. When multiple hierarchical clusterings of the data are possible, it is useful to represent uncertainty in the clustering through various probabilistic quantities. Existing approaches represent uncertainty for a range of models; however, they only provide approximate inference. This paper presents dynamic-programming algorithms and proofs for exact inference in hierarchical clustering. We are able to compute the partition function, MAP hierarchical clustering, and marginal probabilities of sub-hierarchies and clusters. Our method supports a wide range of hierarchical models and only requires a cluster compatibility function. Rather than scaling with the number of hierarchical clusterings of $n$ elements ($\omega(n n! / 2^{n-1})$), our approach runs in time and space proportional to the significantly smaller powerset of $n$. Despite still being large, these algorithms enable exact inference in small-data applications and are also interesting from a theoretical perspective. We demonstrate the utility of our method and compare its performance with respect to existing approximate methods.