 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTackling benign nonconvexity with smoothing and stochastic gradients
Feb 18, 2022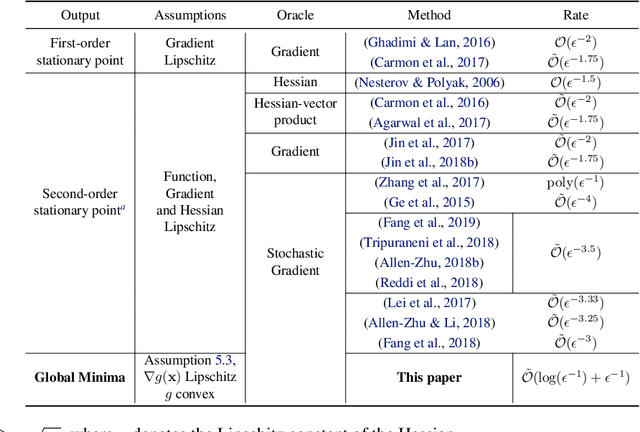
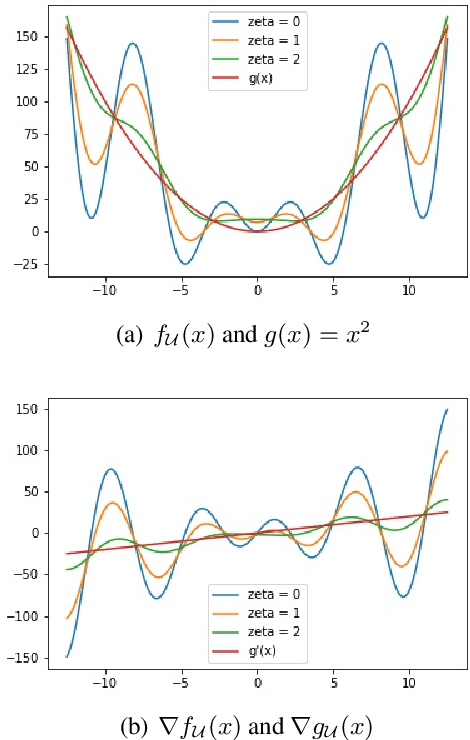
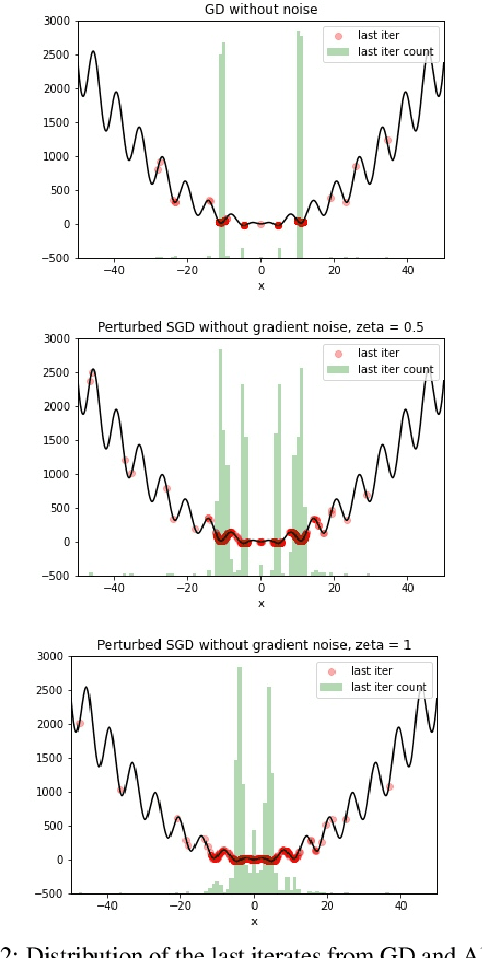
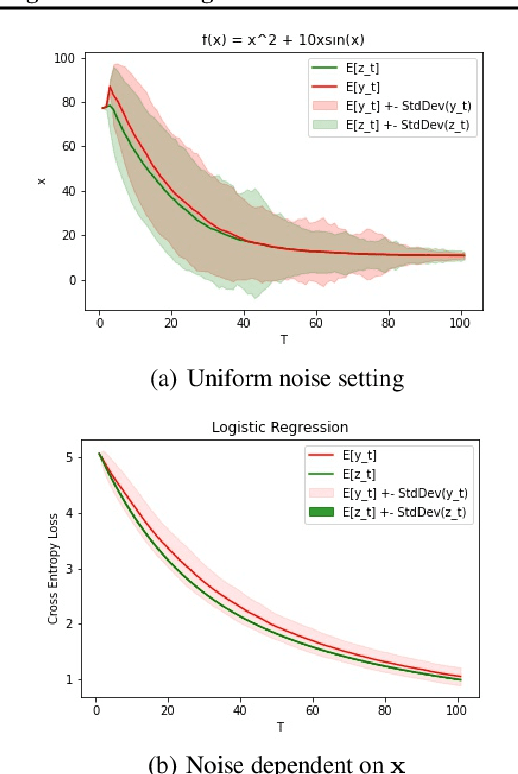
Non-convex optimization problems are ubiquitous in machine learning, especially in Deep Learning. While such complex problems can often be successfully optimized in practice by using stochastic gradient descent (SGD), theoretical analysis cannot adequately explain this success. In particular, the standard analyses do not show global convergence of SGD on non-convex functions, and instead show convergence to stationary points (which can also be local minima or saddle points). We identify a broad class of nonconvex functions for which we can show that perturbed SGD (gradient descent perturbed by stochastic noise -- covering SGD as a special case) converges to a global minimum (or a neighborhood thereof), in contrast to gradient descent without noise that can get stuck in local minima far from a global solution. For example, on non-convex functions that are relatively close to a convex-like (strongly convex or PL) function we show that SGD can converge linearly to a global optimum.
An Improved Analysis of Gradient Tracking for Decentralized Machine Learning
Feb 08, 2022
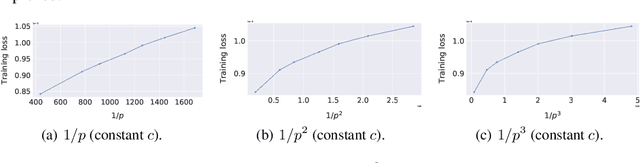

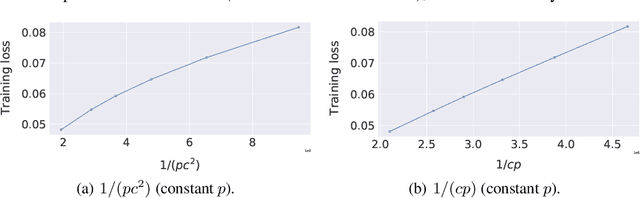
We consider decentralized machine learning over a network where the training data is distributed across $n$ agents, each of which can compute stochastic model updates on their local data. The agent's common goal is to find a model that minimizes the average of all local loss functions. While gradient tracking (GT) algorithms can overcome a key challenge, namely accounting for differences between workers' local data distributions, the known convergence rates for GT algorithms are not optimal with respect to their dependence on the mixing parameter $p$ (related to the spectral gap of the connectivity matrix). We provide a tighter analysis of the GT method in the stochastic strongly convex, convex and non-convex settings. We improve the dependency on $p$ from $\mathcal{O}(p^{-2})$ to $\mathcal{O}(p^{-1}c^{-1})$ in the noiseless case and from $\mathcal{O}(p^{-3/2})$ to $\mathcal{O}(p^{-1/2}c^{-1})$ in the general stochastic case, where $c \geq p$ is related to the negative eigenvalues of the connectivity matrix (and is a constant in most practical applications). This improvement was possible due to a new proof technique which could be of independent interest.
* published at NeurIPS 2021
The Peril of Popular Deep Learning Uncertainty Estimation Methods
Dec 09, 2021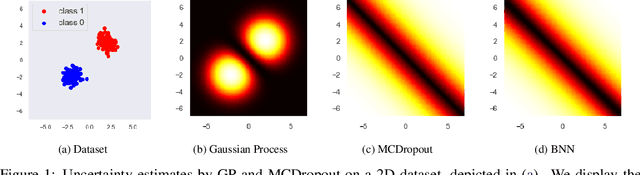

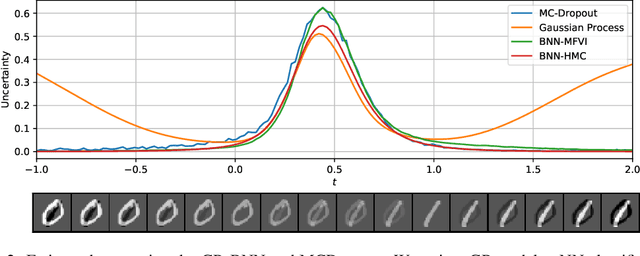

Uncertainty estimation (UE) techniques -- such as the Gaussian process (GP), Bayesian neural networks (BNN), Monte Carlo dropout (MCDropout) -- aim to improve the interpretability of machine learning models by assigning an estimated uncertainty value to each of their prediction outputs. However, since too high uncertainty estimates can have fatal consequences in practice, this paper analyzes the above techniques. Firstly, we show that GP methods always yield high uncertainty estimates on out of distribution (OOD) data. Secondly, we show on a 2D toy example that both BNNs and MCDropout do not give high uncertainty estimates on OOD samples. Finally, we show empirically that this pitfall of BNNs and MCDropout holds on real world datasets as well. Our insights (i) raise awareness for the more cautious use of currently popular UE methods in Deep Learning, (ii) encourage the development of UE methods that approximate GP-based methods -- instead of BNNs and MCDropout, and (iii) our empirical setups can be used for verifying the OOD performances of any other UE method. The source code is available at https://github.com/epfml/uncertainity-estimation.
Linear Speedup in Personalized Collaborative Learning
Nov 10, 2021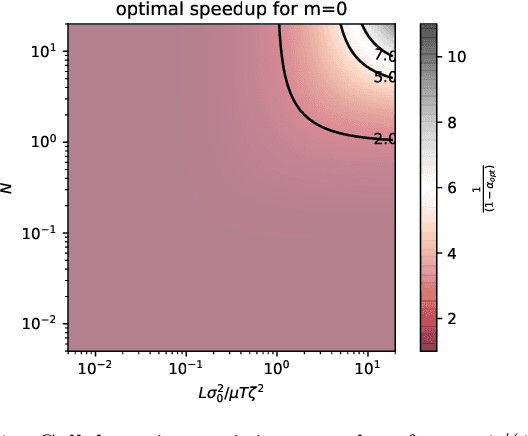
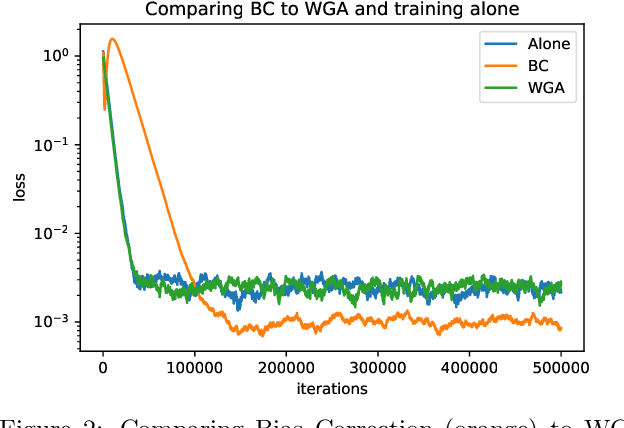
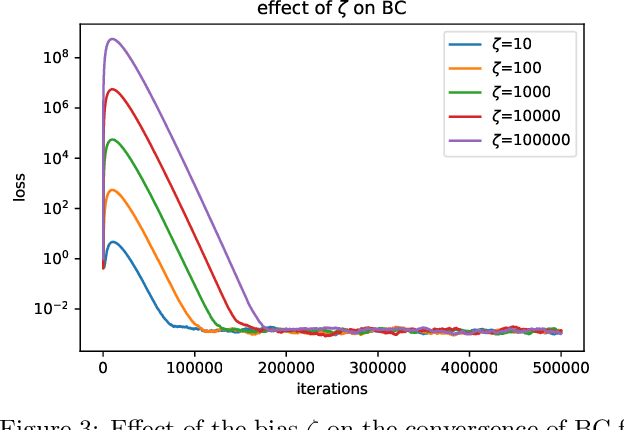
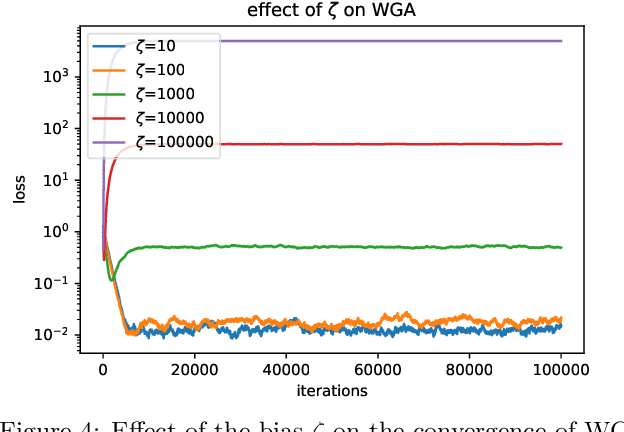
Personalization in federated learning can improve the accuracy of a model for a user by trading off the model's bias (introduced by using data from other users who are potentially different) against its variance (due to the limited amount of data on any single user). In order to develop training algorithms that optimally balance this trade-off, it is necessary to extend our theoretical foundations. In this work, we formalize the personalized collaborative learning problem as stochastic optimization of a user's objective $f_0(x)$ while given access to $N$ related but different objectives of other users $\{f_1(x), \dots, f_N(x)\}$. We give convergence guarantees for two algorithms in this setting -- a popular personalization method known as \emph{weighted gradient averaging}, and a novel \emph{bias correction} method -- and explore conditions under which we can optimally trade-off their bias for a reduction in variance and achieve linear speedup w.r.t.\ the number of users $N$. Further, we also empirically study their performance confirming our theoretical insights.
ProgFed: Effective, Communication, and Computation Efficient Federated Learning by Progressive Training
Oct 11, 2021
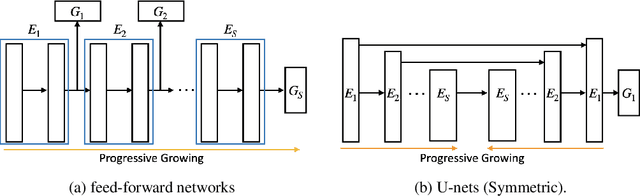
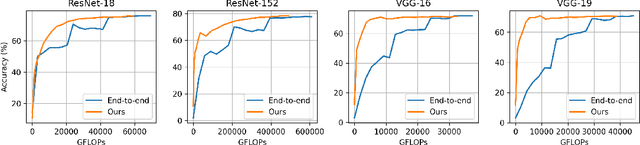
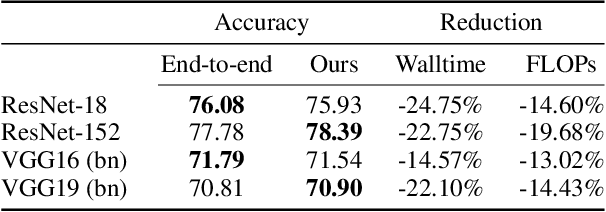
Federated learning is a powerful distributed learning scheme that allows numerous edge devices to collaboratively train a model without sharing their data. However, training is resource-intensive for edge devices, and limited network bandwidth is often the main bottleneck. Prior work often overcomes the constraints by condensing the models or messages into compact formats, e.g., by gradient compression or distillation. In contrast, we propose ProgFed, the first progressive training framework for efficient and effective federated learning. It inherently reduces computation and two-way communication costs while maintaining the strong performance of the final models. We theoretically prove that ProgFed converges at the same asymptotic rate as standard training on full models. Extensive results on a broad range of architectures, including CNNs (VGG, ResNet, ConvNets) and U-nets, and diverse tasks from simple classification to medical image segmentation show that our highly effective training approach saves up to $20\%$ computation and up to $63\%$ communication costs for converged models. As our approach is also complimentary to prior work on compression, we can achieve a wide range of trade-offs, showing reduced communication of up to $50\times$ at only $0.1\%$ loss in utility.
RelaySum for Decentralized Deep Learning on Heterogeneous Data
Oct 08, 2021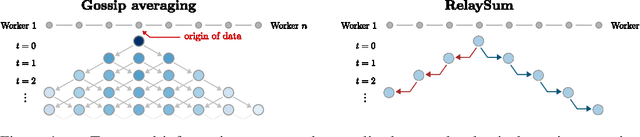
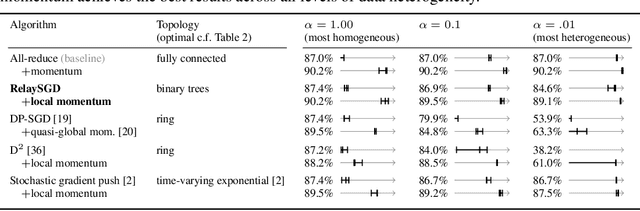
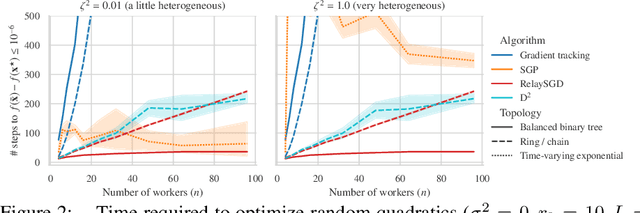

In decentralized machine learning, workers compute model updates on their local data. Because the workers only communicate with few neighbors without central coordination, these updates propagate progressively over the network. This paradigm enables distributed training on networks without all-to-all connectivity, helping to protect data privacy as well as to reduce the communication cost of distributed training in data centers. A key challenge, primarily in decentralized deep learning, remains the handling of differences between the workers' local data distributions. To tackle this challenge, we introduce the RelaySum mechanism for information propagation in decentralized learning. RelaySum uses spanning trees to distribute information exactly uniformly across all workers with finite delays depending on the distance between nodes. In contrast, the typical gossip averaging mechanism only distributes data uniformly asymptotically while using the same communication volume per step as RelaySum. We prove that RelaySGD, based on this mechanism, is independent of data heterogeneity and scales to many workers, enabling highly accurate decentralized deep learning on heterogeneous data. Our code is available at http://github.com/epfml/relaysgd.
On Second-order Optimization Methods for Federated Learning
Sep 06, 2021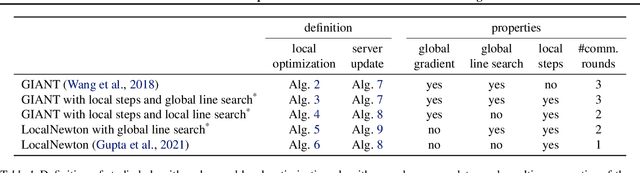
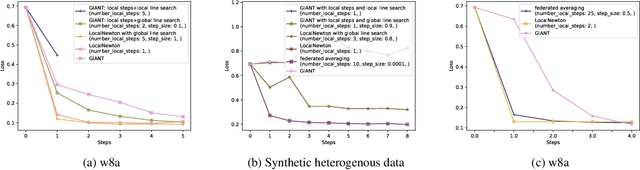
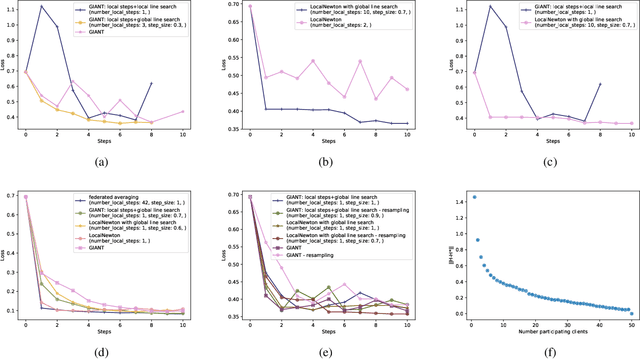
We consider federated learning (FL), where the training data is distributed across a large number of clients. The standard optimization method in this setting is Federated Averaging (FedAvg), which performs multiple local first-order optimization steps between communication rounds. In this work, we evaluate the performance of several second-order distributed methods with local steps in the FL setting which promise to have favorable convergence properties. We (i) show that FedAvg performs surprisingly well against its second-order competitors when evaluated under fair metrics (equal amount of local computations)-in contrast to the results of previous work. Based on our numerical study, we propose (ii) a novel variant that uses second-order local information for updates and a global line search to counteract the resulting local specificity.
Semantic Perturbations with Normalizing Flows for Improved Generalization
Aug 18, 2021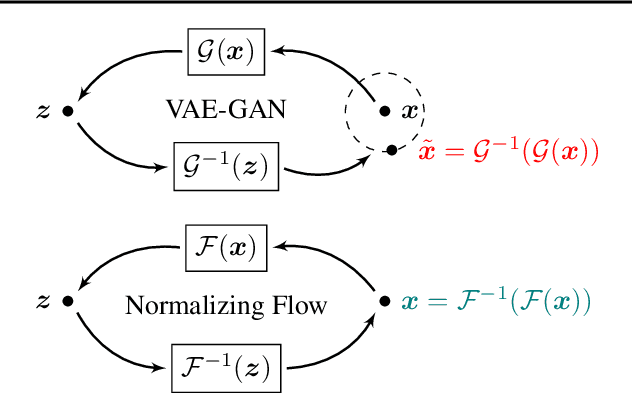
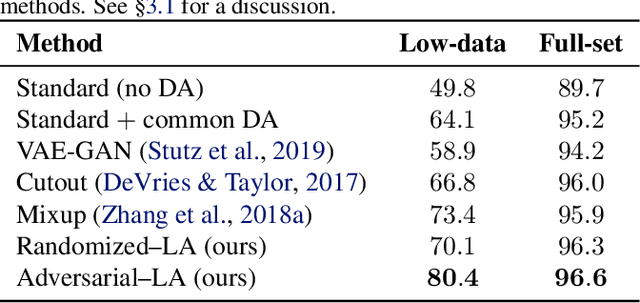

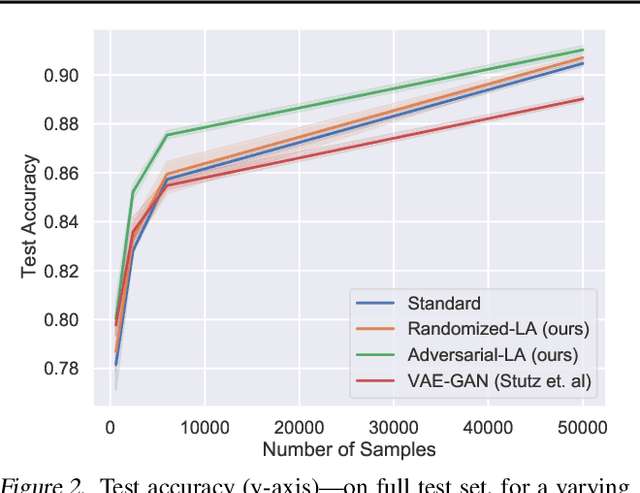
Data augmentation is a widely adopted technique for avoiding overfitting when training deep neural networks. However, this approach requires domain-specific knowledge and is often limited to a fixed set of hard-coded transformations. Recently, several works proposed to use generative models for generating semantically meaningful perturbations to train a classifier. However, because accurate encoding and decoding are critical, these methods, which use architectures that approximate the latent-variable inference, remained limited to pilot studies on small datasets. Exploiting the exactly reversible encoder-decoder structure of normalizing flows, we perform on-manifold perturbations in the latent space to define fully unsupervised data augmentations. We demonstrate that such perturbations match the performance of advanced data augmentation techniques -- reaching 96.6% test accuracy for CIFAR-10 using ResNet-18 and outperform existing methods, particularly in low data regimes -- yielding 10--25% relative improvement of test accuracy from classical training. We find that our latent adversarial perturbations adaptive to the classifier throughout its training are most effective, yielding the first test accuracy improvement results on real-world datasets -- CIFAR-10/100 -- via latent-space perturbations.
A Field Guide to Federated Optimization
Jul 14, 2021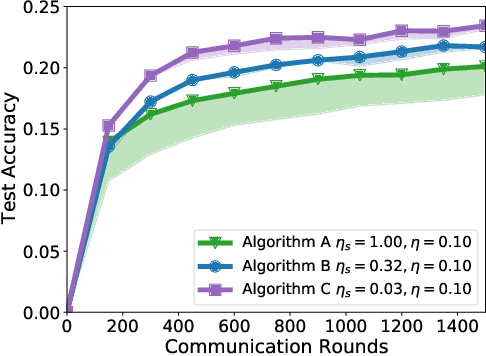


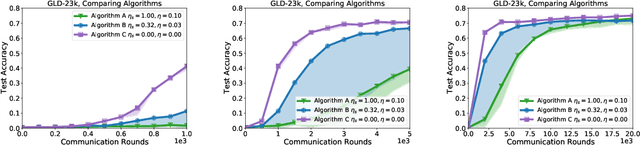
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
Simultaneous Training of Partially Masked Neural Networks
Jun 16, 2021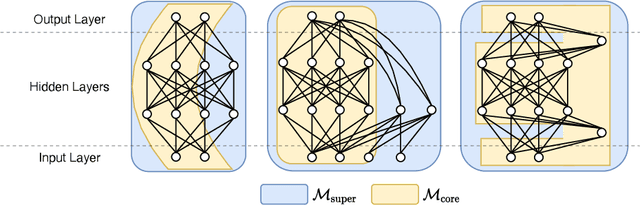


For deploying deep learning models to lower end devices, it is necessary to train less resource-demanding variants of state-of-the-art architectures. This does not eliminate the need for more expensive models as they have a higher performance. In order to avoid training two separate models, we show that it is possible to train neural networks in such a way that a predefined 'core' subnetwork can be split-off from the trained full network with remarkable good performance. We extend on prior methods that focused only on core networks of smaller width, while we focus on supporting arbitrary core network architectures. Our proposed training scheme switches consecutively between optimizing only the core part of the network and the full one. The accuracy of the full model remains comparable, while the core network achieves better performance than when it is trained in isolation. In particular, we show that training a Transformer with a low-rank core gives a low-rank model with superior performance than when training the low-rank model alone. We analyze our training scheme theoretically, and show its convergence under assumptions that are either standard or practically justified. Moreover, we show that the developed theoretical framework allows analyzing many other partial training schemes for neural networks.