 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Independently-Obtainable Reward Functions
Jan 31, 2019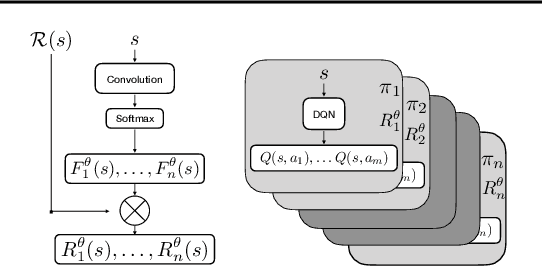
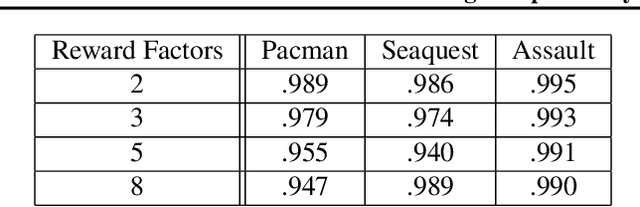
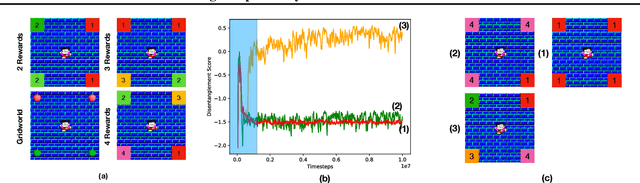
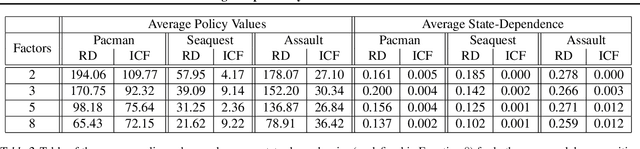
We present a novel method for learning a set of disentangled reward functions that sum to the original environment reward and are constrained to be independently obtainable. We define independent obtainability in terms of value functions with respect to obtaining one learned reward while pursuing another learned reward. Empirically, we illustrate that our method can learn meaningful reward decompositions in a variety of domains and that these decompositions exhibit some form of generalization performance when the environment's reward is modified. Theoretically, we derive results about the effect of maximizing our method's objective on the resulting reward functions and their corresponding optimal policies.
Generative Adversarial Self-Imitation Learning
Dec 03, 2018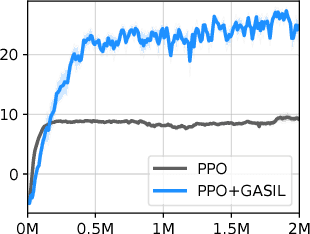
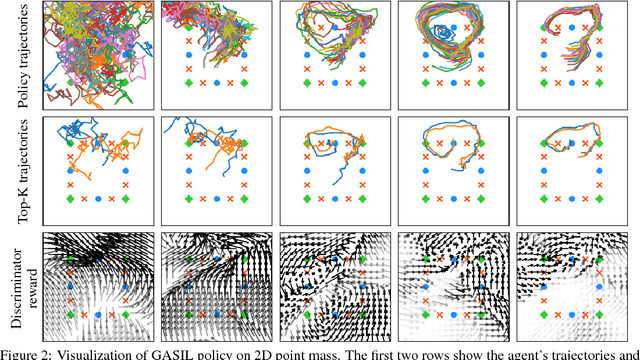
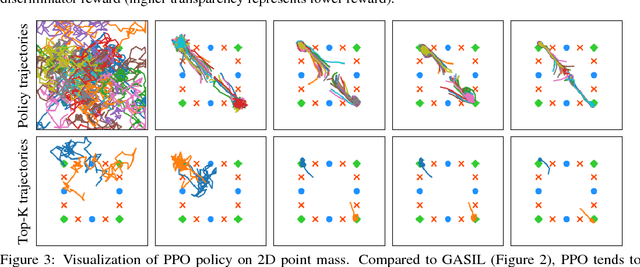
This paper explores a simple regularizer for reinforcement learning by proposing Generative Adversarial Self-Imitation Learning (GASIL), which encourages the agent to imitate past good trajectories via generative adversarial imitation learning framework. Instead of directly maximizing rewards, GASIL focuses on reproducing past good trajectories, which can potentially make long-term credit assignment easier when rewards are sparse and delayed. GASIL can be easily combined with any policy gradient objective by using GASIL as a learned shaped reward function. Our experimental results show that GASIL improves the performance of proximal policy optimization on 2D Point Mass and MuJoCo environments with delayed reward and stochastic dynamics.
Learning End-to-End Goal-Oriented Dialog with Multiple Answers
Aug 24, 2018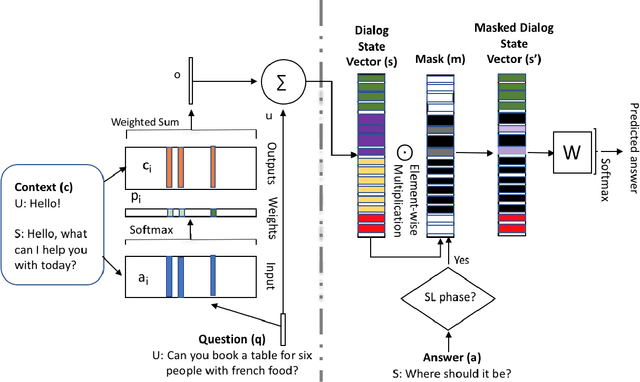
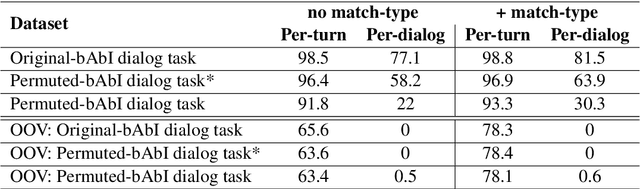
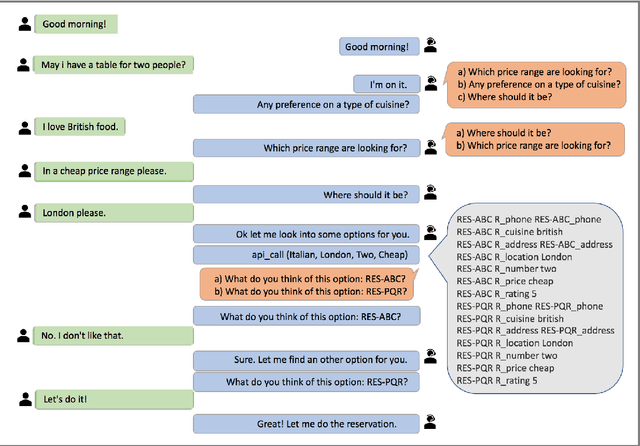
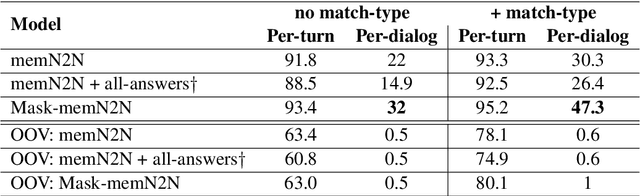
In a dialog, there can be multiple valid next utterances at any point. The present end-to-end neural methods for dialog do not take this into account. They learn with the assumption that at any time there is only one correct next utterance. In this work, we focus on this problem in the goal-oriented dialog setting where there are different paths to reach a goal. We propose a new method, that uses a combination of supervised learning and reinforcement learning approaches to address this issue. We also propose a new and more effective testbed, permuted-bAbI dialog tasks, by introducing multiple valid next utterances to the original-bAbI dialog tasks, which allows evaluation of goal-oriented dialog systems in a more realistic setting. We show that there is a significant drop in performance of existing end-to-end neural methods from 81.5% per-dialog accuracy on original-bAbI dialog tasks to 30.3% on permuted-bAbI dialog tasks. We also show that our proposed method improves the performance and achieves 47.3% per-dialog accuracy on permuted-bAbI dialog tasks.
Many-Goals Reinforcement Learning
Jun 22, 2018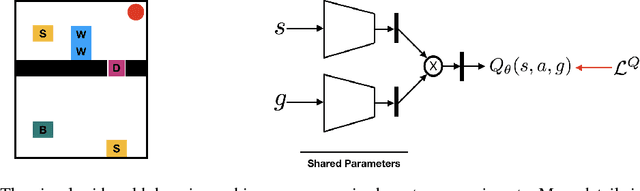
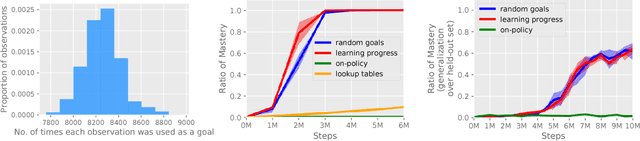
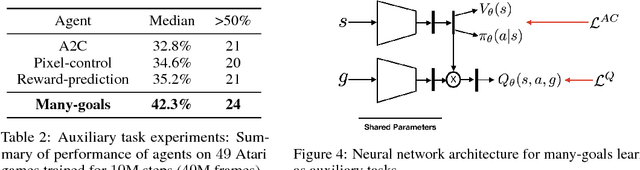
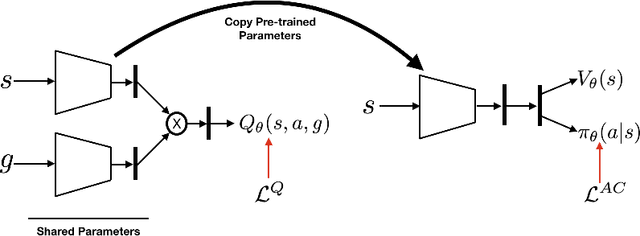
All-goals updating exploits the off-policy nature of Q-learning to update all possible goals an agent could have from each transition in the world, and was introduced into Reinforcement Learning (RL) by Kaelbling (1993). In prior work this was mostly explored in small-state RL problems that allowed tabular representations and where all possible goals could be explicitly enumerated and learned separately. In this paper we empirically explore 3 different extensions of the idea of updating many (instead of all) goals in the context of RL with deep neural networks (or DeepRL for short). First, in a direct adaptation of Kaelbling's approach we explore if many-goals updating can be used to achieve mastery in non-tabular visual-observation domains. Second, we explore whether many-goals updating can be used to pre-train a network to subsequently learn faster and better on a single main task of interest. Third, we explore whether many-goals updating can be used to provide auxiliary task updates in training a network to learn faster and better on a single main task of interest. We provide comparisons to baselines for each of the 3 extensions.
On Learning Intrinsic Rewards for Policy Gradient Methods
Jun 22, 2018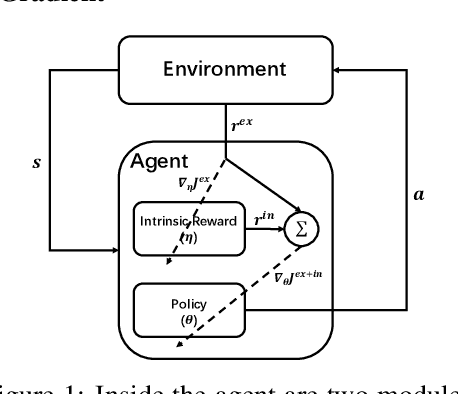
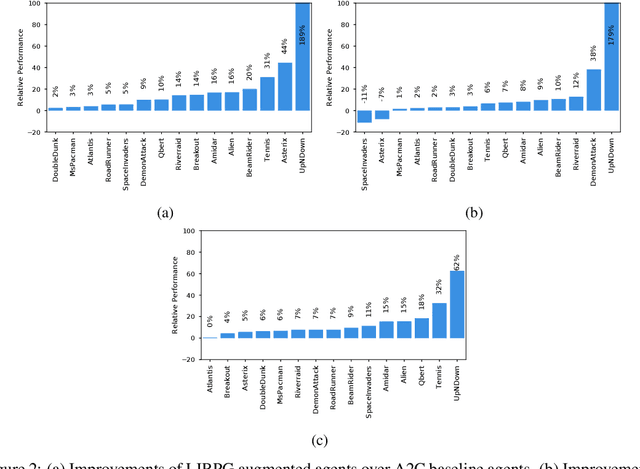
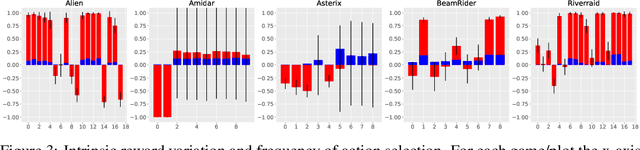
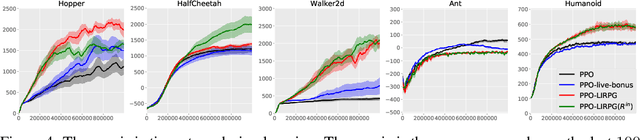
In many sequential decision making tasks, it is challenging to design reward functions that help an RL agent efficiently learn behavior that is considered good by the agent designer. A number of different formulations of the reward-design problem, or close variants thereof, have been proposed in the literature. In this paper we build on the Optimal Rewards Framework of Singh et.al. that defines the optimal intrinsic reward function as one that when used by an RL agent achieves behavior that optimizes the task-specifying or extrinsic reward function. Previous work in this framework has shown how good intrinsic reward functions can be learned for lookahead search based planning agents. Whether it is possible to learn intrinsic reward functions for learning agents remains an open problem. In this paper we derive a novel algorithm for learning intrinsic rewards for policy-gradient based learning agents. We compare the performance of an augmented agent that uses our algorithm to provide additive intrinsic rewards to an A2C-based policy learner (for Atari games) and a PPO-based policy learner (for Mujoco domains) with a baseline agent that uses the same policy learners but with only extrinsic rewards. Our results show improved performance on most but not all of the domains.
Self-Imitation Learning
Jun 14, 2018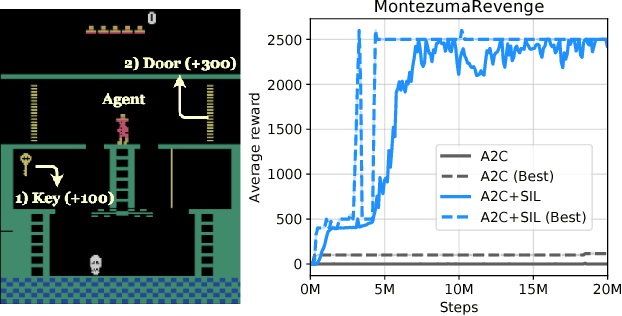
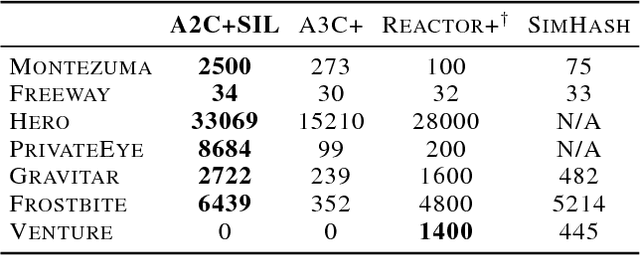
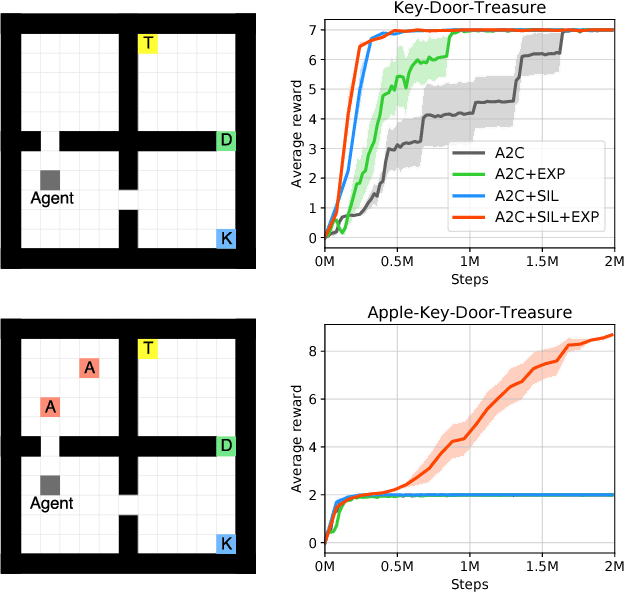

This paper proposes Self-Imitation Learning (SIL), a simple off-policy actor-critic algorithm that learns to reproduce the agent's past good decisions. This algorithm is designed to verify our hypothesis that exploiting past good experiences can indirectly drive deep exploration. Our empirical results show that SIL significantly improves advantage actor-critic (A2C) on several hard exploration Atari games and is competitive to the state-of-the-art count-based exploration methods. We also show that SIL improves proximal policy optimization (PPO) on MuJoCo tasks.
Named Entities troubling your Neural Methods? Build NE-Table: A neural approach for handling Named Entities
Apr 22, 2018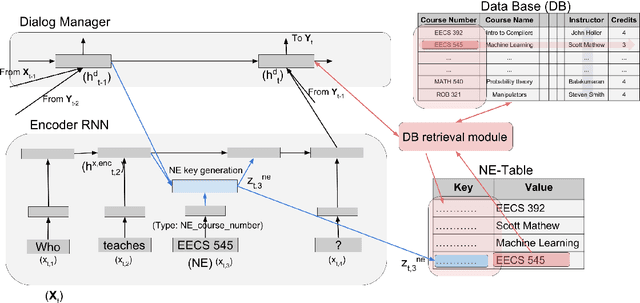
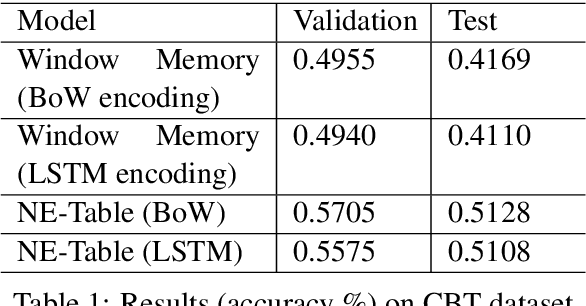
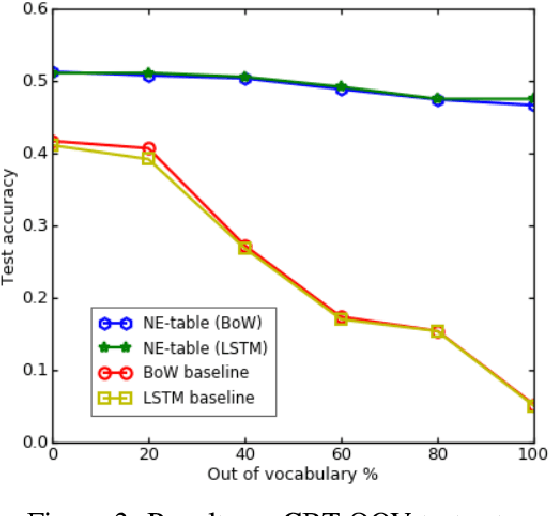
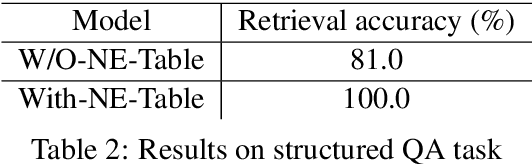
Many natural language processing tasks require dealing with Named Entities (NEs) in the texts themselves and sometimes also in external knowledge sources. While this is often easy for humans, recent neural methods that rely on learned word embeddings for NLP tasks have difficulty with it, especially with out of vocabulary or rare NEs. In this paper, we propose a new neural method for this problem, and present empirical evaluations on a structured Question-Answering task, three related Goal-Oriented dialog tasks and a reading-comprehension-based task. They show that our proposed method can be effective in dealing with both in-vocabulary and out of vocabulary (OOV) NEs. We create extended versions of dialog bAbI tasks 1,2 and 4 and Out-of-vocabulary (OOV) versions of the CBT test set which will be made publicly available online.
The Advantage of Doubling: A Deep Reinforcement Learning Approach to Studying the Double Team in the NBA
Mar 08, 2018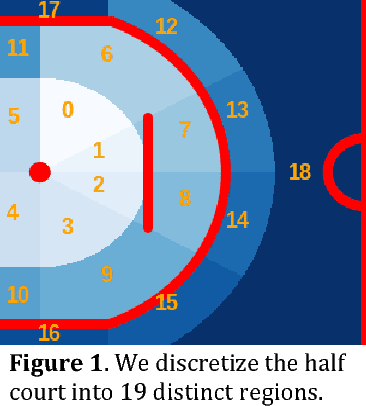
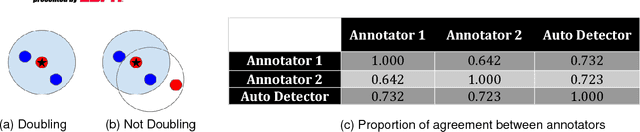

During the 2017 NBA playoffs, Celtics coach Brad Stevens was faced with a difficult decision when defending against the Cavaliers: "Do you double and risk giving up easy shots, or stay at home and do the best you can?" It's a tough call, but finding a good defensive strategy that effectively incorporates doubling can make all the difference in the NBA. In this paper, we analyze double teaming in the NBA, quantifying the trade-off between risk and reward. Using player trajectory data pertaining to over 643,000 possessions, we identified when the ball handler was double teamed. Given these data and the corresponding outcome (i.e., was the defense successful), we used deep reinforcement learning to estimate the quality of the defensive actions. We present qualitative and quantitative results summarizing our learned defensive strategy for defending. We show that our policy value estimates are predictive of points per possession and win percentage. Overall, the proposed framework represents a step toward a more comprehensive understanding of defensive strategies in the NBA.
Markov Decision Processes with Continuous Side Information
Nov 15, 2017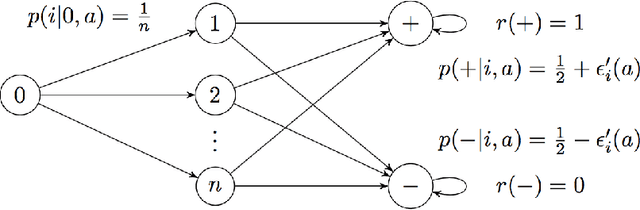
We consider a reinforcement learning (RL) setting in which the agent interacts with a sequence of episodic MDPs. At the start of each episode the agent has access to some side-information or context that determines the dynamics of the MDP for that episode. Our setting is motivated by applications in healthcare where baseline measurements of a patient at the start of a treatment episode form the context that may provide information about how the patient might respond to treatment decisions. We propose algorithms for learning in such Contextual Markov Decision Processes (CMDPs) under an assumption that the unobserved MDP parameters vary smoothly with the observed context. We also give lower and upper PAC bounds under the smoothness assumption. Because our lower bound has an exponential dependence on the dimension, we consider a tractable linear setting where the context is used to create linear combinations of a finite set of MDPs. For the linear setting, we give a PAC learning algorithm based on KWIK learning techniques.
Zero-Shot Task Generalization with Multi-Task Deep Reinforcement Learning
Nov 07, 2017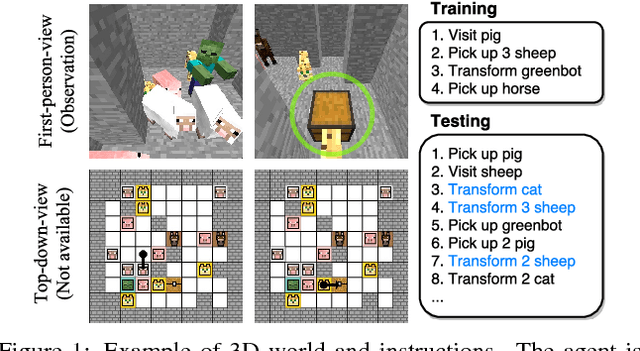
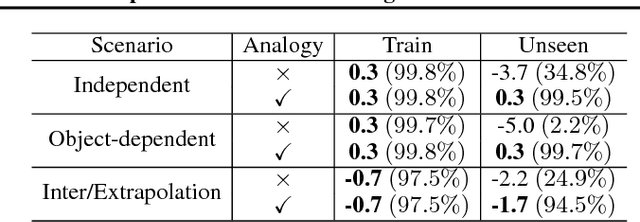
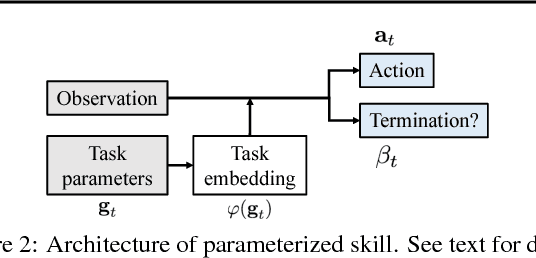
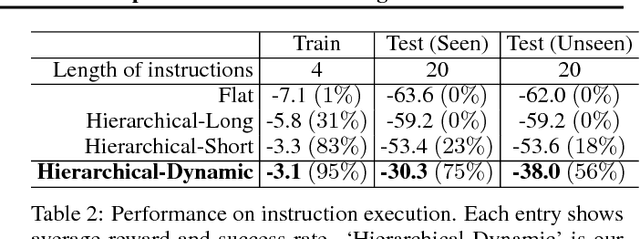
As a step towards developing zero-shot task generalization capabilities in reinforcement learning (RL), we introduce a new RL problem where the agent should learn to execute sequences of instructions after learning useful skills that solve subtasks. In this problem, we consider two types of generalizations: to previously unseen instructions and to longer sequences of instructions. For generalization over unseen instructions, we propose a new objective which encourages learning correspondences between similar subtasks by making analogies. For generalization over sequential instructions, we present a hierarchical architecture where a meta controller learns to use the acquired skills for executing the instructions. To deal with delayed reward, we propose a new neural architecture in the meta controller that learns when to update the subtask, which makes learning more efficient. Experimental results on a stochastic 3D domain show that the proposed ideas are crucial for generalization to longer instructions as well as unseen instructions.