 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Reaction Time to Comprehend Scenes with Foveated Scene Understanding Maps
May 19, 2025



Although models exist that predict human response times (RTs) in tasks such as target search and visual discrimination, the development of image-computable predictors for scene understanding time remains an open challenge. Recent advances in vision-language models (VLMs), which can generate scene descriptions for arbitrary images, combined with the availability of quantitative metrics for comparing linguistic descriptions, offer a new opportunity to model human scene understanding. We hypothesize that the primary bottleneck in human scene understanding and the driving source of variability in response times across scenes is the interaction between the foveated nature of the human visual system and the spatial distribution of task-relevant visual information within an image. Based on this assumption, we propose a novel image-computable model that integrates foveated vision with VLMs to produce a spatially resolved map of scene understanding as a function of fixation location (Foveated Scene Understanding Map, or F-SUM), along with an aggregate F-SUM score. This metric correlates with average (N=17) human RTs (r=0.47) and number of saccades (r=0.51) required to comprehend a scene (across 277 scenes). The F-SUM score also correlates with average (N=16) human description accuracy (r=-0.56) in time-limited presentations. These correlations significantly exceed those of standard image-based metrics such as clutter, visual complexity, and scene ambiguity based on language entropy. Together, our work introduces a new image-computable metric for predicting human response times in scene understanding and demonstrates the importance of foveated visual processing in shaping comprehension difficulty.
The Advantage of Doubling: A Deep Reinforcement Learning Approach to Studying the Double Team in the NBA
Mar 08, 2018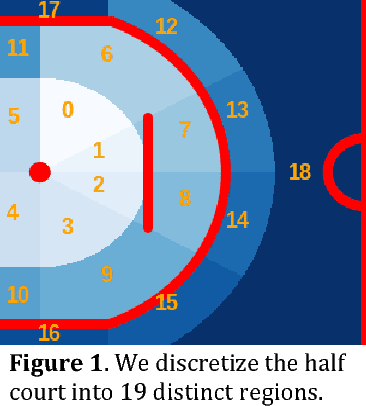
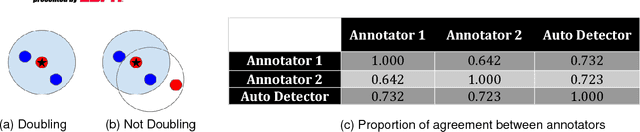

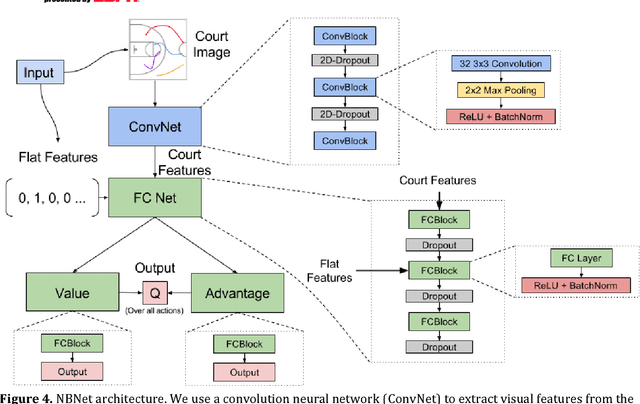
During the 2017 NBA playoffs, Celtics coach Brad Stevens was faced with a difficult decision when defending against the Cavaliers: "Do you double and risk giving up easy shots, or stay at home and do the best you can?" It's a tough call, but finding a good defensive strategy that effectively incorporates doubling can make all the difference in the NBA. In this paper, we analyze double teaming in the NBA, quantifying the trade-off between risk and reward. Using player trajectory data pertaining to over 643,000 possessions, we identified when the ball handler was double teamed. Given these data and the corresponding outcome (i.e., was the defense successful), we used deep reinforcement learning to estimate the quality of the defensive actions. We present qualitative and quantitative results summarizing our learned defensive strategy for defending. We show that our policy value estimates are predictive of points per possession and win percentage. Overall, the proposed framework represents a step toward a more comprehensive understanding of defensive strategies in the NBA.