 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Models Can Be Efficiently Specialized via Few-Shot Task-Aware Compression
Mar 25, 2023Recent vision architectures and self-supervised training methods enable vision models that are extremely accurate and general, but come with massive parameter and computational costs. In practical settings, such as camera traps, users have limited resources, and may fine-tune a pretrained model on (often limited) data from a small set of specific categories of interest. These users may wish to make use of modern, highly-accurate models, but are often computationally constrained. To address this, we ask: can we quickly compress large generalist models into accurate and efficient specialists? For this, we propose a simple and versatile technique called Few-Shot Task-Aware Compression (TACO). Given a large vision model that is pretrained to be accurate on a broad task, such as classification over ImageNet-22K, TACO produces a smaller model that is accurate on specialized tasks, such as classification across vehicle types or animal species. Crucially, TACO works in few-shot fashion, i.e. only a few task-specific samples are used, and the procedure has low computational overheads. We validate TACO on highly-accurate ResNet, ViT/DeiT, and ConvNeXt models, originally trained on ImageNet, LAION, or iNaturalist, which we specialize and compress to a diverse set of "downstream" subtasks. TACO can reduce the number of non-zero parameters in existing models by up to 20x relative to the original models, leading to inference speedups of up to 3$\times$, while remaining accuracy-competitive with the uncompressed models on the specialized tasks.
Teaching Computer Vision for Ecology
Jan 05, 2023


Computer vision can accelerate ecology research by automating the analysis of raw imagery from sensors like camera traps, drones, and satellites. However, computer vision is an emerging discipline that is rarely taught to ecologists. This work discusses our experience teaching a diverse group of ecologists to prototype and evaluate computer vision systems in the context of an intensive hands-on summer workshop. We explain the workshop structure, discuss common challenges, and propose best practices. This document is intended for computer scientists who teach computer vision across disciplines, but it may also be useful to ecologists or other domain experts who are learning to use computer vision themselves.
The Caltech Fish Counting Dataset: A Benchmark for Multiple-Object Tracking and Counting
Jul 19, 2022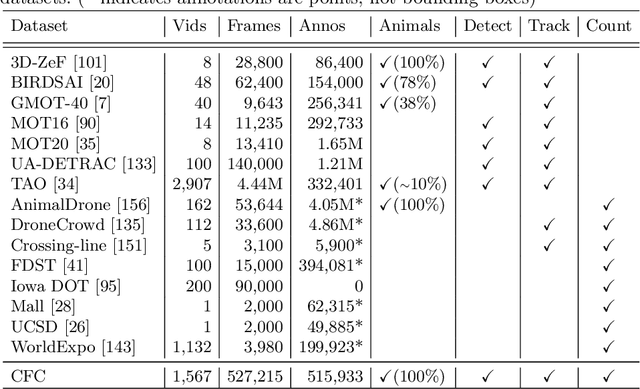
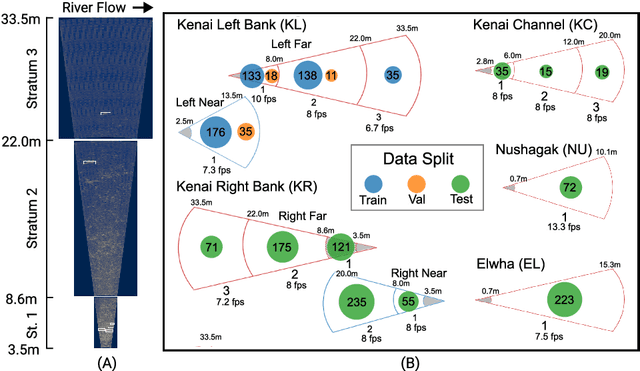
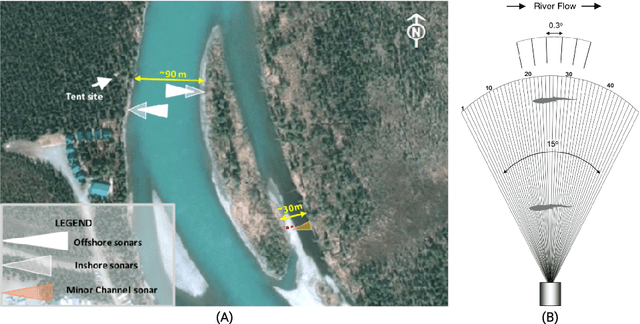

We present the Caltech Fish Counting Dataset (CFC), a large-scale dataset for detecting, tracking, and counting fish in sonar videos. We identify sonar videos as a rich source of data for advancing low signal-to-noise computer vision applications and tackling domain generalization in multiple-object tracking (MOT) and counting. In comparison to existing MOT and counting datasets, which are largely restricted to videos of people and vehicles in cities, CFC is sourced from a natural-world domain where targets are not easily resolvable and appearance features cannot be easily leveraged for target re-identification. With over half a million annotations in over 1,500 videos sourced from seven different sonar cameras, CFC allows researchers to train MOT and counting algorithms and evaluate generalization performance at unseen test locations. We perform extensive baseline experiments and identify key challenges and opportunities for advancing the state of the art in generalization in MOT and counting.
Extending the WILDS Benchmark for Unsupervised Adaptation
Dec 09, 2021

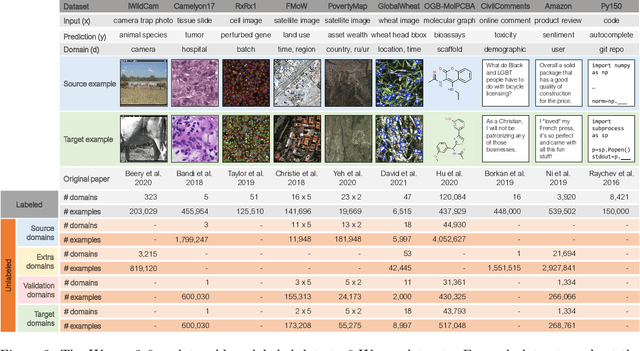
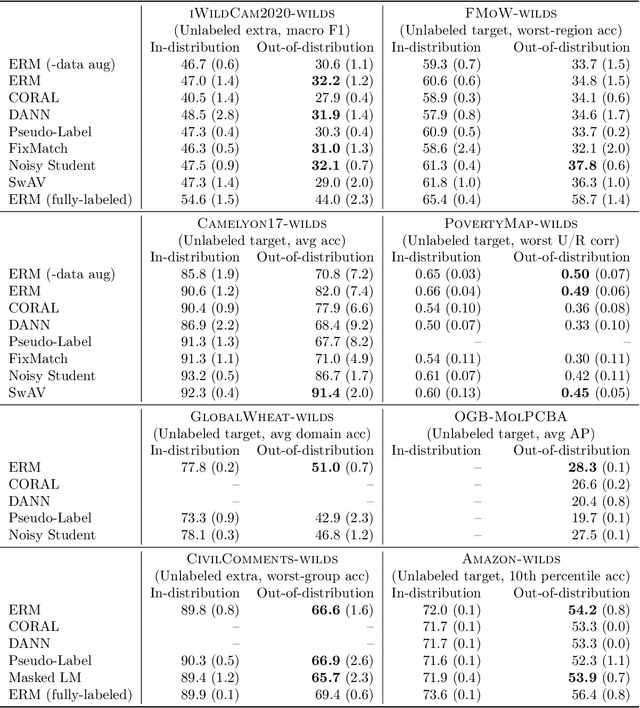
Machine learning systems deployed in the wild are often trained on a source distribution but deployed on a different target distribution. Unlabeled data can be a powerful point of leverage for mitigating these distribution shifts, as it is frequently much more available than labeled data. However, existing distribution shift benchmarks for unlabeled data do not reflect the breadth of scenarios that arise in real-world applications. In this work, we present the WILDS 2.0 update, which extends 8 of the 10 datasets in the WILDS benchmark of distribution shifts to include curated unlabeled data that would be realistically obtainable in deployment. To maintain consistency, the labeled training, validation, and test sets, as well as the evaluation metrics, are exactly the same as in the original WILDS benchmark. These datasets span a wide range of applications (from histology to wildlife conservation), tasks (classification, regression, and detection), and modalities (photos, satellite images, microscope slides, text, molecular graphs). We systematically benchmark state-of-the-art methods that leverage unlabeled data, including domain-invariant, self-training, and self-supervised methods, and show that their success on WILDS 2.0 is limited. To facilitate method development and evaluation, we provide an open-source package that automates data loading and contains all of the model architectures and methods used in this paper. Code and leaderboards are available at https://wilds.stanford.edu.
Seeing biodiversity: perspectives in machine learning for wildlife conservation
Oct 25, 2021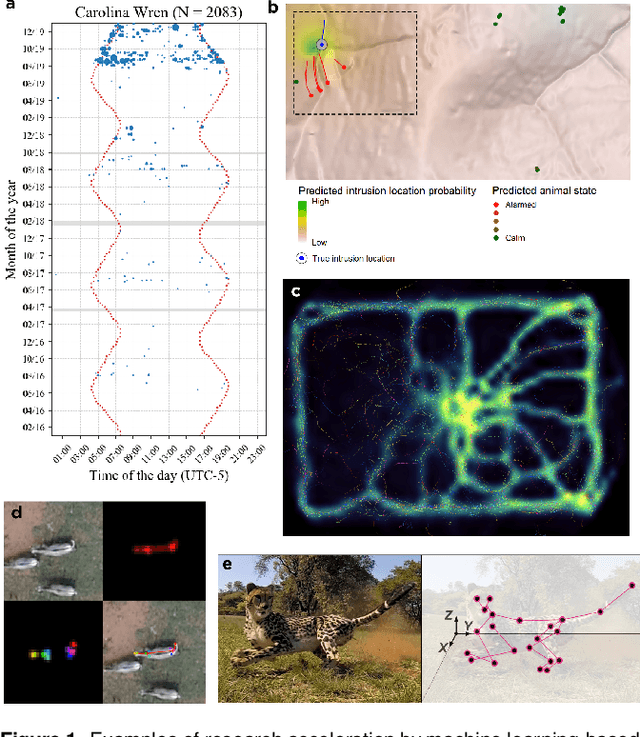
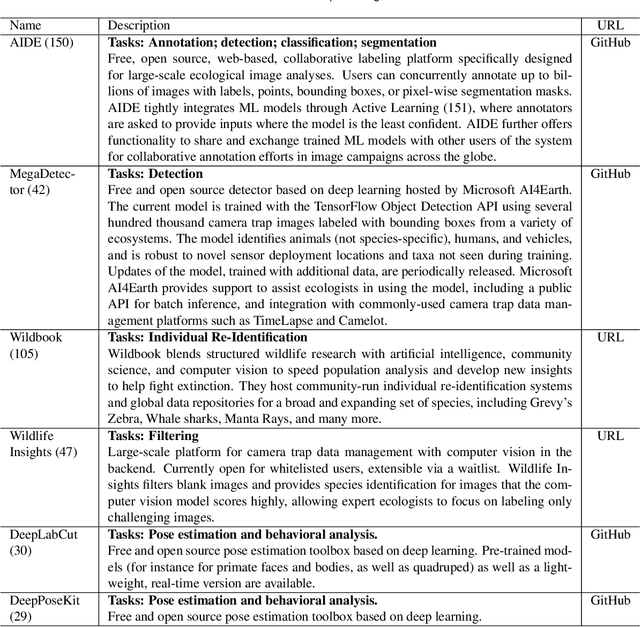

Data acquisition in animal ecology is rapidly accelerating due to inexpensive and accessible sensors such as smartphones, drones, satellites, audio recorders and bio-logging devices. These new technologies and the data they generate hold great potential for large-scale environmental monitoring and understanding, but are limited by current data processing approaches which are inefficient in how they ingest, digest, and distill data into relevant information. We argue that machine learning, and especially deep learning approaches, can meet this analytic challenge to enhance our understanding, monitoring capacity, and conservation of wildlife species. Incorporating machine learning into ecological workflows could improve inputs for population and behavior models and eventually lead to integrated hybrid modeling tools, with ecological models acting as constraints for machine learning models and the latter providing data-supported insights. In essence, by combining new machine learning approaches with ecological domain knowledge, animal ecologists can capitalize on the abundance of data generated by modern sensor technologies in order to reliably estimate population abundances, study animal behavior and mitigate human/wildlife conflicts. To succeed, this approach will require close collaboration and cross-disciplinary education between the computer science and animal ecology communities in order to ensure the quality of machine learning approaches and train a new generation of data scientists in ecology and conservation.
Domain Adaptation for Rare Classes Augmented with Synthetic Samples
Oct 23, 2021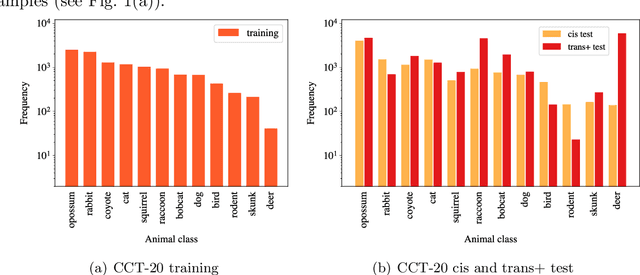

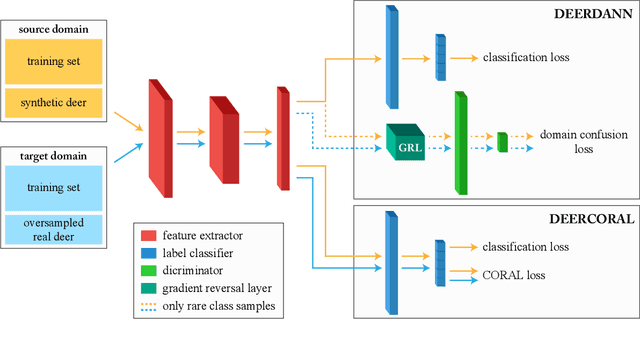
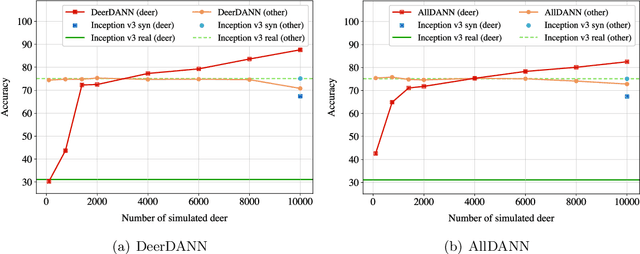
To alleviate lower classification performance on rare classes in imbalanced datasets, a possible solution is to augment the underrepresented classes with synthetic samples. Domain adaptation can be incorporated in a classifier to decrease the domain discrepancy between real and synthetic samples. While domain adaptation is generally applied on completely synthetic source domains and real target domains, we explore how domain adaptation can be applied when only a single rare class is augmented with simulated samples. As a testbed, we use a camera trap animal dataset with a rare deer class, which is augmented with synthetic deer samples. We adapt existing domain adaptation methods to two new methods for the single rare class setting: DeerDANN, based on the Domain-Adversarial Neural Network (DANN), and DeerCORAL, based on deep correlation alignment (Deep CORAL) architectures. Experiments show that DeerDANN has the highest improvement in deer classification accuracy of 24.0% versus 22.4% improvement of DeerCORAL when compared to the baseline. Further, both methods require fewer than 10k synthetic samples, as used by the baseline, to achieve these higher accuracies. DeerCORAL requires the least number of synthetic samples (2k deer), followed by DeerDANN (8k deer).
Species Distribution Modeling for Machine Learning Practitioners: A Review
Jul 03, 2021
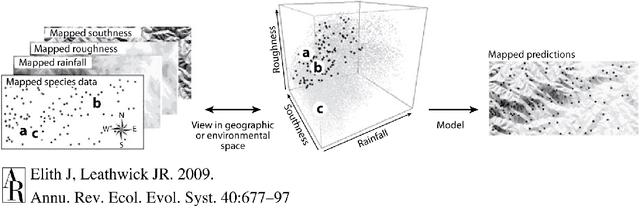

Conservation science depends on an accurate understanding of what's happening in a given ecosystem. How many species live there? What is the makeup of the population? How is that changing over time? Species Distribution Modeling (SDM) seeks to predict the spatial (and sometimes temporal) patterns of species occurrence, i.e. where a species is likely to be found. The last few years have seen a surge of interest in applying powerful machine learning tools to challenging problems in ecology. Despite its considerable importance, SDM has received relatively little attention from the computer science community. Our goal in this work is to provide computer scientists with the necessary background to read the SDM literature and develop ecologically useful ML-based SDM algorithms. In particular, we introduce key SDM concepts and terminology, review standard models, discuss data availability, and highlight technical challenges and pitfalls.
ElephantBook: A Semi-Automated Human-in-the-Loop System for Elephant Re-Identification
Jun 30, 2021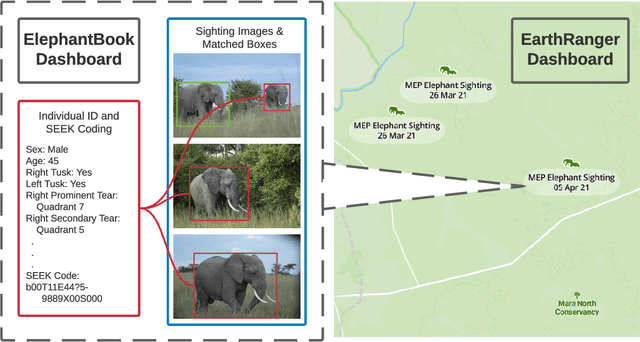
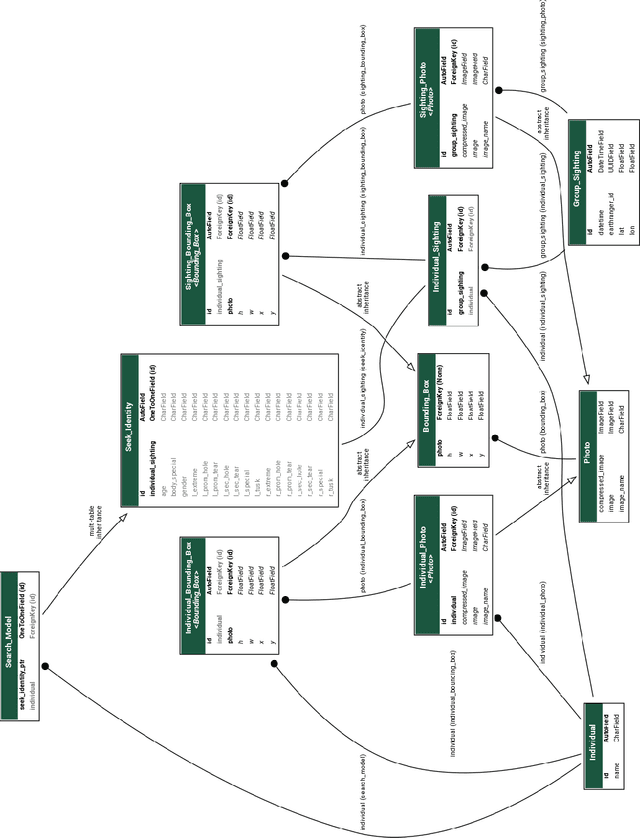
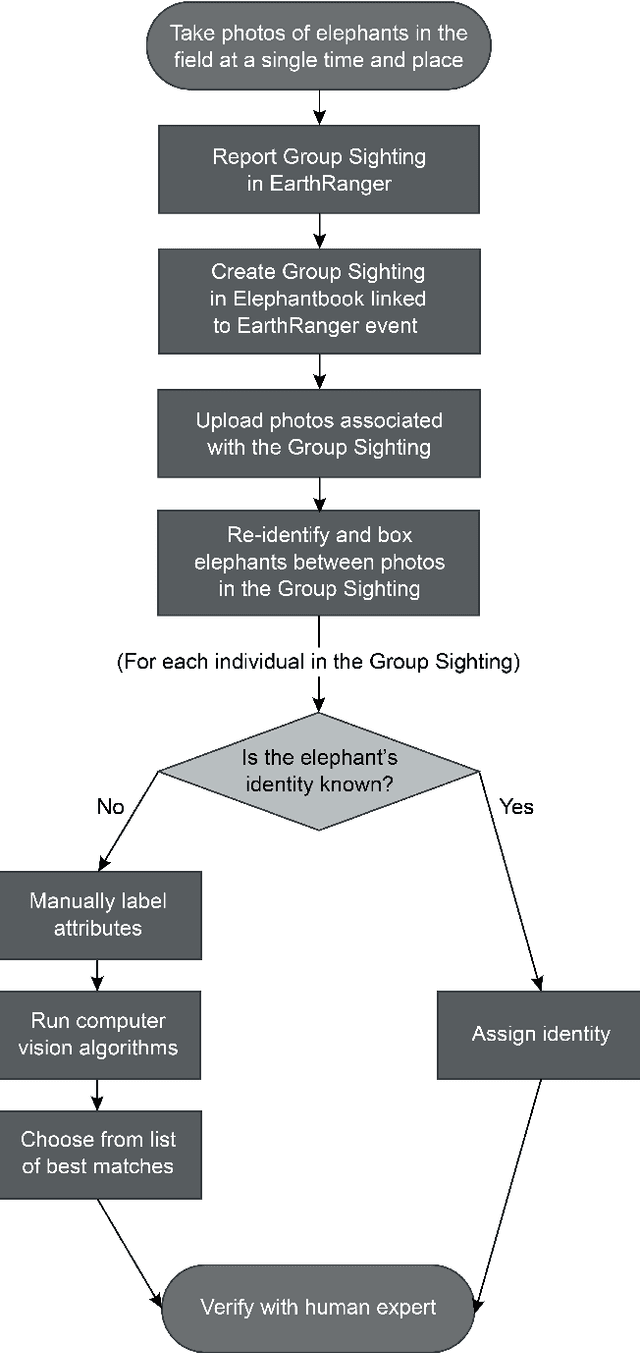

African elephants are vital to their ecosystems, but their populations are threatened by a rise in human-elephant conflict and poaching. Monitoring population dynamics is essential in conservation efforts; however, tracking elephants is a difficult task, usually relying on the invasive and sometimes dangerous placement of GPS collars. Although there have been many recent successes in the use of computer vision techniques for automated identification of other species, identification of elephants is extremely difficult and typically requires expertise as well as familiarity with elephants in the population. We have built and deployed a web-based platform and database for human-in-the-loop re-identification of elephants combining manual attribute labeling and state-of-the-art computer vision algorithms, known as ElephantBook. Our system is currently in use at the Mara Elephant Project, helping monitor the protected and at-risk population of elephants in the Greater Maasai Mara ecosystem. ElephantBook makes elephant re-identification usable by non-experts and scalable for use by multiple conservation NGOs.
Image-to-Image Translation of Synthetic Samples for Rare Classes
Jun 23, 2021
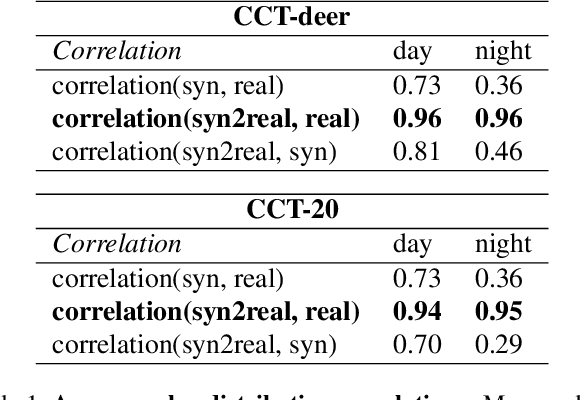
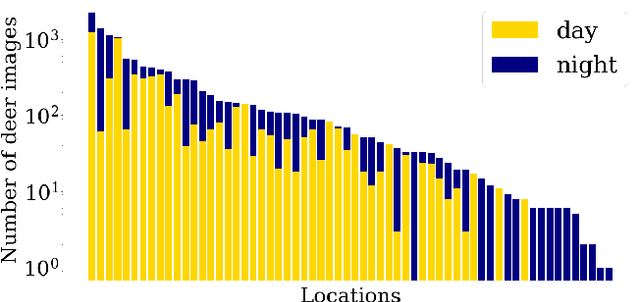
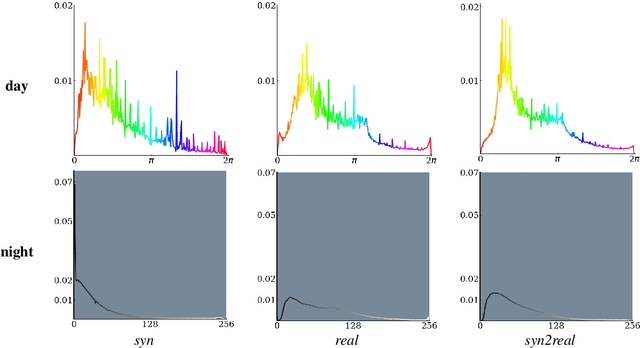
The natural world is long-tailed: rare classes are observed orders of magnitudes less frequently than common ones, leading to highly-imbalanced data where rare classes can have only handfuls of examples. Learning from few examples is a known challenge for deep learning based classification algorithms, and is the focus of the field of low-shot learning. One potential approach to increase the training data for these rare classes is to augment the limited real data with synthetic samples. This has been shown to help, but the domain shift between real and synthetic hinders the approaches' efficacy when tested on real data. We explore the use of image-to-image translation methods to close the domain gap between synthetic and real imagery for animal species classification in data collected from camera traps: motion-activated static cameras used to monitor wildlife. We use low-level feature alignment between source and target domains to make synthetic data for a rare species generated using a graphics engine more "realistic". Compared against a system augmented with unaligned synthetic data, our experiments show a considerable decrease in classification error rates on a rare species.
Can poachers find animals from public camera trap images?
Jun 21, 2021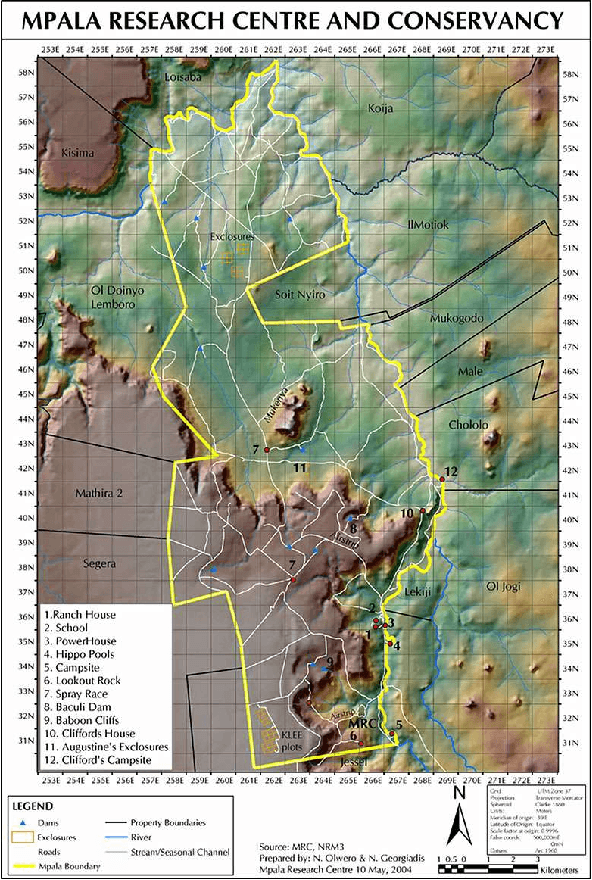

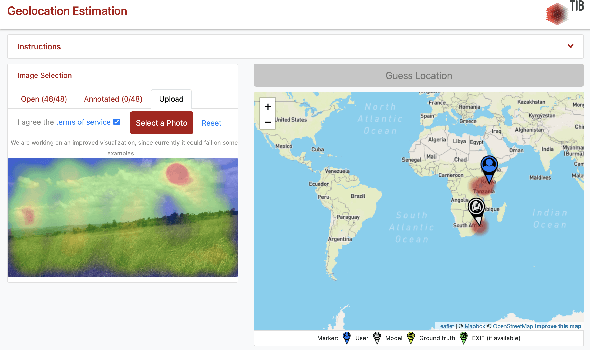
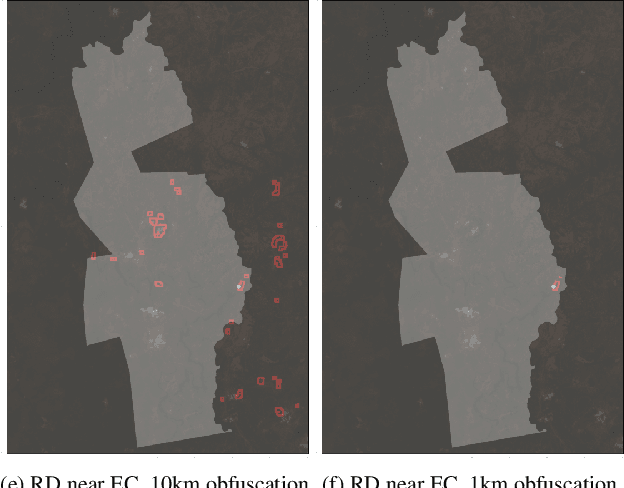
To protect the location of camera trap data containing sensitive, high-target species, many ecologists randomly obfuscate the latitude and longitude of the camera when publishing their data. For example, they may publish a random location within a 1km radius of the true camera location for each camera in their network. In this paper, we investigate the robustness of geo-obfuscation for maintaining camera trap location privacy, and show via a case study that a few simple, intuitive heuristics and publicly available satellite rasters can be used to reduce the area likely to contain the camera by 87% (assuming random obfuscation within 1km), demonstrating that geo-obfuscation may be less effective than previously believed.