 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Theory for Emergence of Complex Skills in Language Models
Jul 29, 2023A major driver of AI products today is the fact that new skills emerge in language models when their parameter set and training corpora are scaled up. This phenomenon is poorly understood, and a mechanistic explanation via mathematical analysis of gradient-based training seems difficult. The current paper takes a different approach, analysing emergence using the famous (and empirical) Scaling Laws of LLMs and a simple statistical framework. Contributions include: (a) A statistical framework that relates cross-entropy loss of LLMs to competence on the basic skills that underlie language tasks. (b) Mathematical analysis showing that the Scaling Laws imply a strong form of inductive bias that allows the pre-trained model to learn very efficiently. We informally call this {\em slingshot generalization} since naively viewed it appears to give competence levels at skills that violate usual generalization theory. (c) A key example of slingshot generalization, that competence at executing tasks involving $k$-tuples of skills emerges essentially at the same scaling and same rate as competence on the elementary skills themselves.
Trainable Transformer in Transformer
Jul 03, 2023



Recent works attribute the capability of in-context learning (ICL) in large pre-trained language models to implicitly simulating and fine-tuning an internal model (e.g., linear or 2-layer MLP) during inference. However, such constructions require large memory overhead, which makes simulation of more sophisticated internal models intractable. In this work, we propose an efficient construction, Transformer in Transformer (in short, TinT), that allows a transformer to simulate and fine-tune complex models internally during inference (e.g., pre-trained language models). In particular, we introduce innovative approximation techniques that allow a TinT model with less than 2 billion parameters to simulate and fine-tune a 125 million parameter transformer model within a single forward pass. TinT accommodates many common transformer variants and its design ideas also improve the efficiency of past instantiations of simple models inside transformers. We conduct end-to-end experiments to validate the internal fine-tuning procedure of TinT on various language modeling and downstream tasks. For example, even with a limited one-step budget, we observe TinT for a OPT-125M model improves performance by 4-16% absolute on average compared to OPT-125M. These findings suggest that large pre-trained language models are capable of performing intricate subroutines. To facilitate further work, a modular and extensible codebase for TinT is included.
Fine-Tuning Language Models with Just Forward Passes
May 27, 2023



Fine-tuning language models (LMs) has yielded success on diverse downstream tasks, but as LMs grow in size, backpropagation requires a prohibitively large amount of memory. Zeroth-order (ZO) methods can in principle estimate gradients using only two forward passes but are theorized to be catastrophically slow for optimizing large models. In this work, we propose a memory-efficient zerothorder optimizer (MeZO), adapting the classical ZO-SGD method to operate in-place, thereby fine-tuning LMs with the same memory footprint as inference. For example, with a single A100 80GB GPU, MeZO can train a 30-billion parameter model, whereas fine-tuning with backpropagation can train only a 2.7B LM with the same budget. We conduct comprehensive experiments across model types (masked and autoregressive LMs), model scales (up to 66B), and downstream tasks (classification, multiple-choice, and generation). Our results demonstrate that (1) MeZO significantly outperforms in-context learning and linear probing; (2) MeZO achieves comparable performance to fine-tuning with backpropagation across multiple tasks, with up to 12x memory reduction; (3) MeZO is compatible with both full-parameter and parameter-efficient tuning techniques such as LoRA and prefix tuning; (4) MeZO can effectively optimize non-differentiable objectives (e.g., maximizing accuracy or F1). We support our empirical findings with theoretical insights, highlighting how adequate pre-training and task prompts enable MeZO to fine-tune huge models, despite classical ZO analyses suggesting otherwise.
Do Transformers Parse while Predicting the Masked Word?
Mar 14, 2023



Pre-trained language models have been shown to encode linguistic structures, e.g. dependency and constituency parse trees, in their embeddings while being trained on unsupervised loss functions like masked language modeling. Some doubts have been raised whether the models actually are doing parsing or only some computation weakly correlated with it. We study questions: (a) Is it possible to explicitly describe transformers with realistic embedding dimension, number of heads, etc. that are capable of doing parsing -- or even approximate parsing? (b) Why do pre-trained models capture parsing structure? This paper takes a step toward answering these questions in the context of generative modeling with PCFGs. We show that masked language models like BERT or RoBERTa of moderate sizes can approximately execute the Inside-Outside algorithm for the English PCFG [Marcus et al, 1993]. We also show that the Inside-Outside algorithm is optimal for masked language modeling loss on the PCFG-generated data. We also give a construction of transformers with $50$ layers, $15$ attention heads, and $1275$ dimensional embeddings in average such that using its embeddings it is possible to do constituency parsing with $>70\%$ F1 score on PTB dataset. We conduct probing experiments on models pre-trained on PCFG-generated data to show that this not only allows recovery of approximate parse tree, but also recovers marginal span probabilities computed by the Inside-Outside algorithm, which suggests an implicit bias of masked language modeling towards this algorithm.
Why does Local SGD Generalize Better than SGD?
Mar 09, 2023



Local SGD is a communication-efficient variant of SGD for large-scale training, where multiple GPUs perform SGD independently and average the model parameters periodically. It has been recently observed that Local SGD can not only achieve the design goal of reducing the communication overhead but also lead to higher test accuracy than the corresponding SGD baseline (Lin et al., 2020b), though the training regimes for this to happen are still in debate (Ortiz et al., 2021). This paper aims to understand why (and when) Local SGD generalizes better based on Stochastic Differential Equation (SDE) approximation. The main contributions of this paper include (i) the derivation of an SDE that captures the long-term behavior of Local SGD in the small learning rate regime, showing how noise drives the iterate to drift and diffuse after it has reached close to the manifold of local minima, (ii) a comparison between the SDEs of Local SGD and SGD, showing that Local SGD induces a stronger drift term that can result in a stronger effect of regularization, e.g., a faster reduction of sharpness, and (iii) empirical evidence validating that having a small learning rate and long enough training time enables the generalization improvement over SGD but removing either of the two conditions leads to no improvement.
Task-Specific Skill Localization in Fine-tuned Language Models
Feb 13, 2023



Pre-trained language models can be fine-tuned to solve diverse NLP tasks, including in few-shot settings. Thus fine-tuning allows the model to quickly pick up task-specific ``skills,'' but there has been limited study of where these newly-learnt skills reside inside the massive model. This paper introduces the term skill localization for this problem and proposes a solution. Given the downstream task and a model fine-tuned on that task, a simple optimization is used to identify a very small subset of parameters ($\sim0.01$% of model parameters) responsible for ($>95$%) of the model's performance, in the sense that grafting the fine-tuned values for just this tiny subset onto the pre-trained model gives performance almost as well as the fine-tuned model. While reminiscent of recent works on parameter-efficient fine-tuning, the novel aspects here are that: (i) No further re-training is needed on the subset (unlike, say, with lottery tickets). (ii) Notable improvements are seen over vanilla fine-tuning with respect to calibration of predictions in-distribution ($40$-$90$% error reduction) as well as the quality of predictions out-of-distribution (OOD). In models trained on multiple tasks, a stronger notion of skill localization is observed, where the sparse regions corresponding to different tasks are almost disjoint, and their overlap (when it happens) is a proxy for task similarity. Experiments suggest that localization via grafting can assist certain forms of continual learning.
New Definitions and Evaluations for Saliency Methods: Staying Intrinsic, Complete and Sound
Nov 05, 2022



Saliency methods compute heat maps that highlight portions of an input that were most {\em important} for the label assigned to it by a deep net. Evaluations of saliency methods convert this heat map into a new {\em masked input} by retaining the $k$ highest-ranked pixels of the original input and replacing the rest with \textquotedblleft uninformative\textquotedblright\ pixels, and checking if the net's output is mostly unchanged. This is usually seen as an {\em explanation} of the output, but the current paper highlights reasons why this inference of causality may be suspect. Inspired by logic concepts of {\em completeness \& soundness}, it observes that the above type of evaluation focuses on completeness of the explanation, but ignores soundness. New evaluation metrics are introduced to capture both notions, while staying in an {\em intrinsic} framework -- i.e., using the dataset and the net, but no separately trained nets, human evaluations, etc. A simple saliency method is described that matches or outperforms prior methods in the evaluations. Experiments also suggest new intrinsic justifications, based on soundness, for popular heuristic tricks such as TV regularization and upsampling.
A Kernel-Based View of Language Model Fine-Tuning
Oct 11, 2022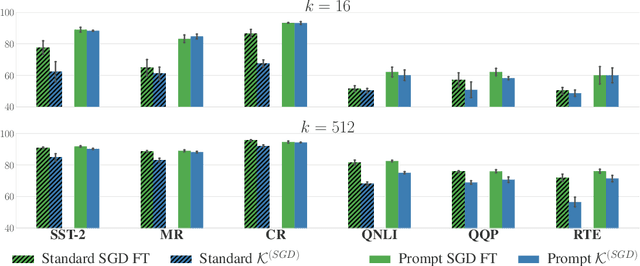
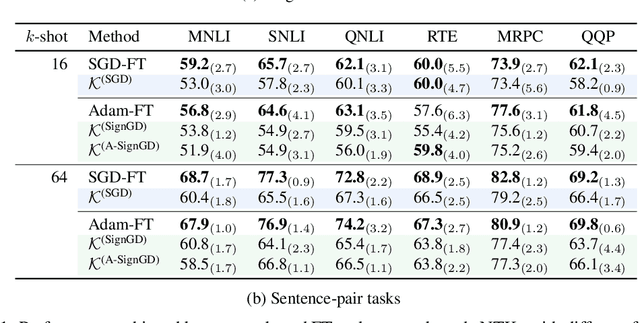
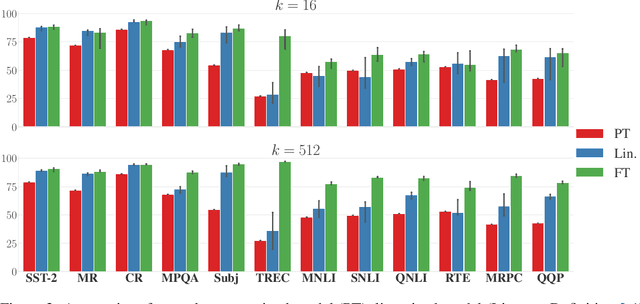

It has become standard to solve NLP tasks by fine-tuning pre-trained language models (LMs), especially in low-data settings. There is minimal theoretical understanding of empirical success, e.g., why fine-tuning a model with $10^8$ or more parameters on a couple dozen training points does not result in overfitting. We investigate whether the Neural Tangent Kernel (NTK) - which originated as a model to study the gradient descent dynamics of infinitely wide networks with suitable random initialization - describes fine-tuning of pre-trained LMs. This study was inspired by the decent performance of NTK for computer vision tasks (Wei et al., 2022). We also extend the NTK formalism to fine-tuning with Adam. We present extensive experiments that show that once the downstream task is formulated as a language modeling problem through prompting, the NTK lens can often reasonably describe the model updates during fine-tuning with both SGD and Adam. This kernel view also suggests an explanation for success of parameter-efficient subspace-based fine-tuning methods. Finally, we suggest a path toward a formal explanation for our findings via Tensor Programs (Yang, 2020).
Understanding Influence Functions and Datamodels via Harmonic Analysis
Oct 03, 2022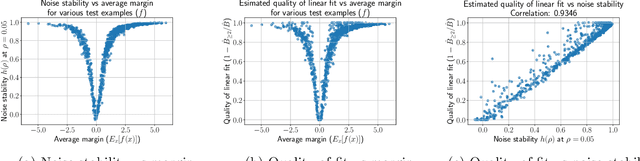
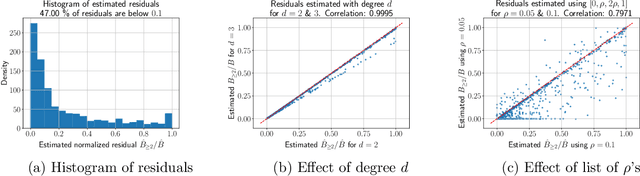
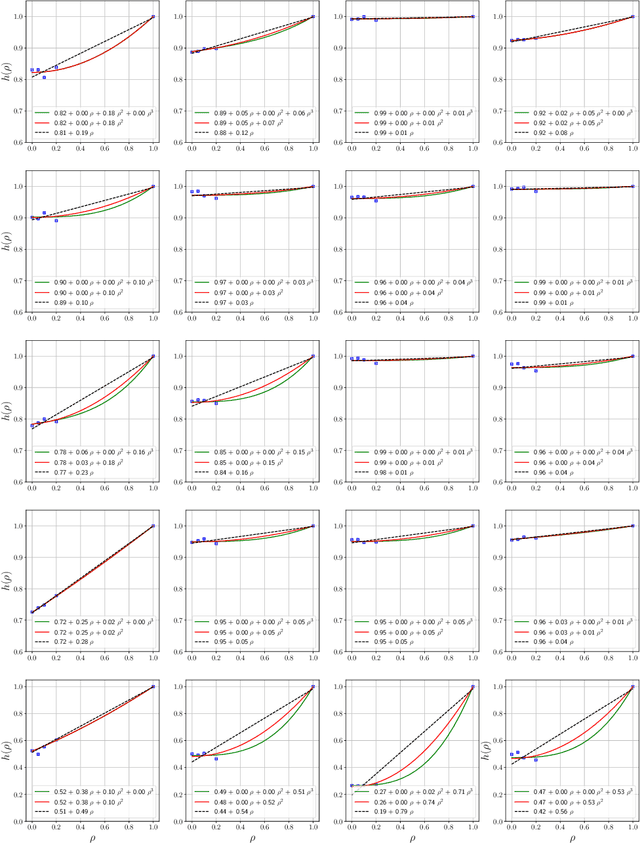
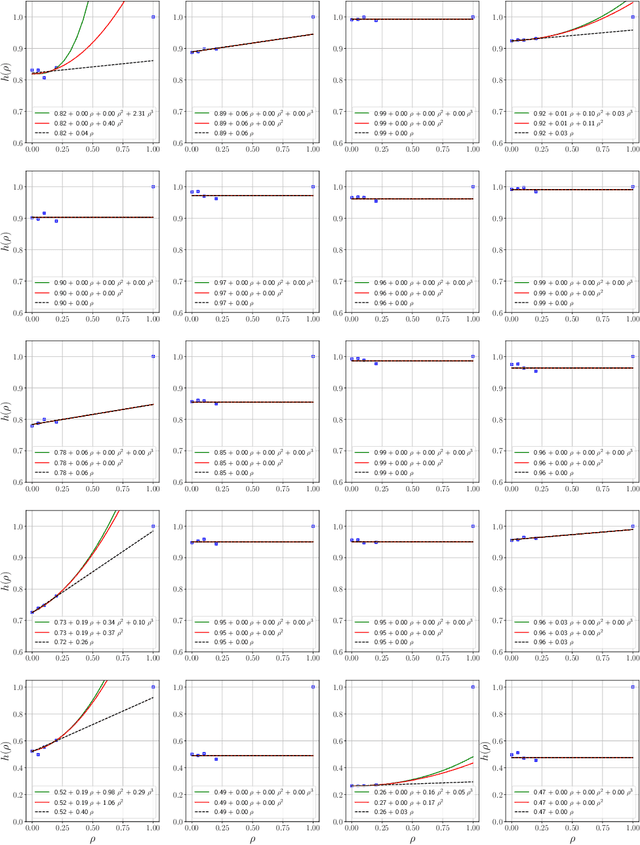
Influence functions estimate effect of individual data points on predictions of the model on test data and were adapted to deep learning in Koh and Liang [2017]. They have been used for detecting data poisoning, detecting helpful and harmful examples, influence of groups of datapoints, etc. Recently, Ilyas et al. [2022] introduced a linear regression method they termed datamodels to predict the effect of training points on outputs on test data. The current paper seeks to provide a better theoretical understanding of such interesting empirical phenomena. The primary tool is harmonic analysis and the idea of noise stability. Contributions include: (a) Exact characterization of the learnt datamodel in terms of Fourier coefficients. (b) An efficient method to estimate the residual error and quality of the optimum linear datamodel without having to train the datamodel. (c) New insights into when influences of groups of datapoints may or may not add up linearly.
Implicit Bias of Gradient Descent on Reparametrized Models: On Equivalence to Mirror Descent
Jul 08, 2022
As part of the effort to understand implicit bias of gradient descent in overparametrized models, several results have shown how the training trajectory on the overparametrized model can be understood as mirror descent on a different objective. The main result here is a characterization of this phenomenon under a notion termed commuting parametrization, which encompasses all the previous results in this setting. It is shown that gradient flow with any commuting parametrization is equivalent to continuous mirror descent with a related Legendre function. Conversely, continuous mirror descent with any Legendre function can be viewed as gradient flow with a related commuting parametrization. The latter result relies upon Nash's embedding theorem.