 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Attention is all you need: Real-Time Streaming Transformers for Personalised Speech Enhancement
Nov 08, 2022

Personalised speech enhancement (PSE), which extracts only the speech of a target user and removes everything else from a recorded audio clip, can potentially improve users' experiences of audio AI modules deployed in the wild. To support a large variety of downstream audio tasks, such as real-time ASR and audio-call enhancement, a PSE solution should operate in a streaming mode, i.e., input audio cleaning should happen in real-time with a small latency and real-time factor. Personalisation is typically achieved by extracting a target speaker's voice profile from an enrolment audio, in the form of a static embedding vector, and then using it to condition the output of a PSE model. However, a fixed target speaker embedding may not be optimal under all conditions. In this work, we present a streaming Transformer-based PSE model and propose a novel cross-attention approach that gives adaptive target speaker representations. We present extensive experiments and show that our proposed cross-attention approach outperforms competitive baselines consistently, even when our model is only approximately half the size.
The Benefit of the Doubt: Uncertainty Aware Sensing for Edge Computing Platforms
Feb 11, 2021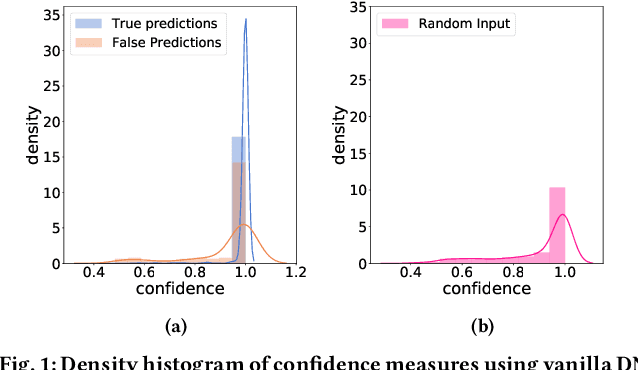

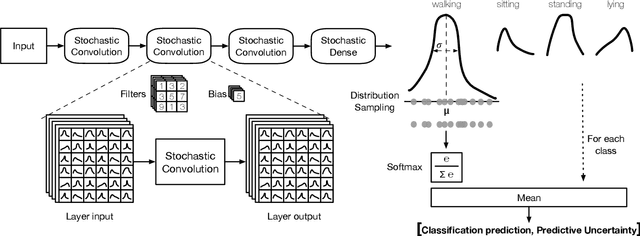
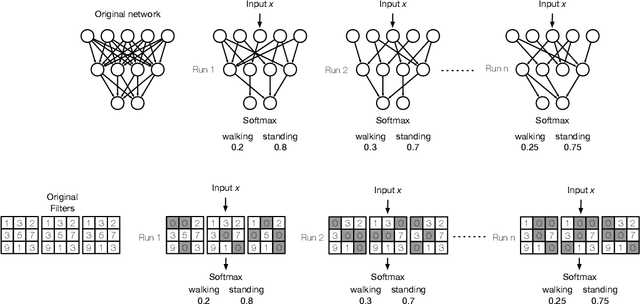
Neural networks (NNs) lack measures of "reliability" estimation that would enable reasoning over their predictions. Despite the vital importance, especially in areas of human well-being and health, state-of-the-art uncertainty estimation techniques are computationally expensive when applied to resource-constrained devices. We propose an efficient framework for predictive uncertainty estimation in NNs deployed on embedded edge systems with no need for fine-tuning or re-training strategies. To meet the energy and latency requirements of these embedded platforms the framework is built from the ground up to provide predictive uncertainty based only on one forward pass and a negligible amount of additional matrix multiplications with theoretically proven correctness. Our aim is to enable already trained deep learning models to generate uncertainty estimates on resource-limited devices at inference time focusing on classification tasks. This framework is founded on theoretical developments casting dropout training as approximate inference in Bayesian NNs. Our layerwise distribution approximation to the convolution layer cascades through the network, providing uncertainty estimates in one single run which ensures minimal overhead, especially compared with uncertainty techniques that require multiple forwards passes and an equal linear rise in energy and latency requirements making them unsuitable in practice. We demonstrate that it yields better performance and flexibility over previous work based on multilayer perceptrons to obtain uncertainty estimates. Our evaluation with mobile applications datasets shows that our approach not only obtains robust and accurate uncertainty estimations but also outperforms state-of-the-art methods in terms of systems performance, reducing energy consumption (up to 28x), keeping the memory overhead at a minimum while still improving accuracy (up to 16%).
Bunched LPCNet : Vocoder for Low-cost Neural Text-To-Speech Systems
Aug 11, 2020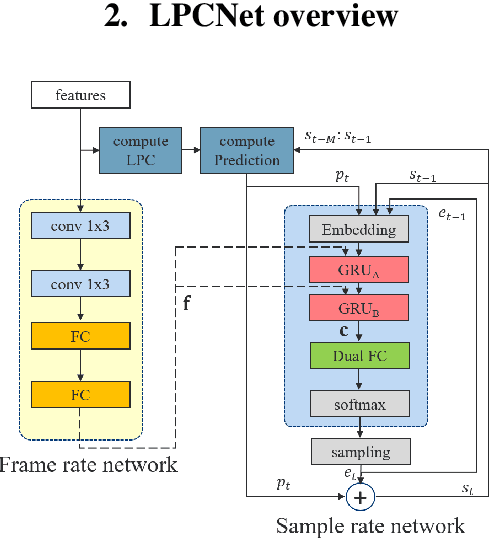
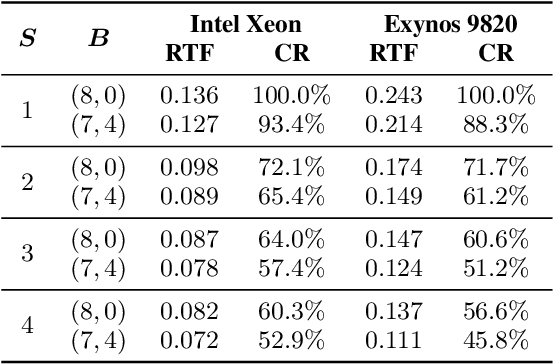
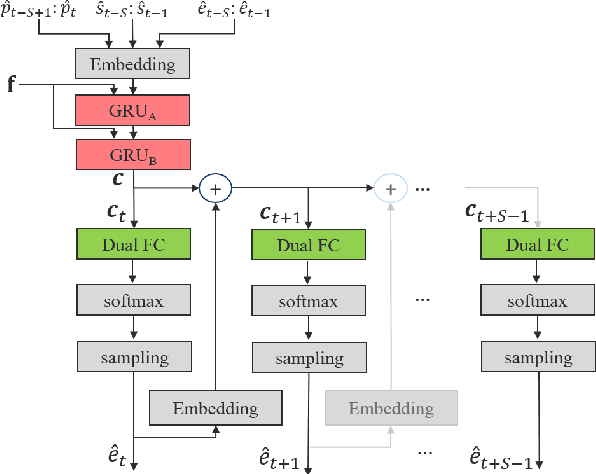
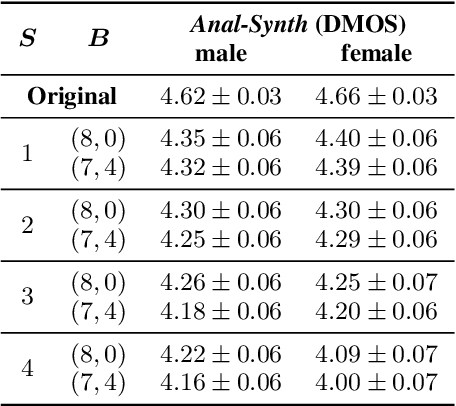
LPCNet is an efficient vocoder that combines linear prediction and deep neural network modules to keep the computational complexity low. In this work, we present two techniques to further reduce it's complexity, aiming for a low-cost LPCNet vocoder-based neural Text-to-Speech (TTS) System. These techniques are: 1) Sample-bunching, which allows LPCNet to generate more than one audio sample per inference; and 2) Bit-bunching, which reduces the computations in the final layer of LPCNet. With the proposed bunching techniques, LPCNet, in conjunction with a Deep Convolutional TTS (DCTTS) acoustic model, shows a 2.19x improvement over the baseline run-time when running on a mobile device, with a less than 0.1 decrease in TTS mean opinion score (MOS).
Iterative Compression of End-to-End ASR Model using AutoML
Aug 06, 2020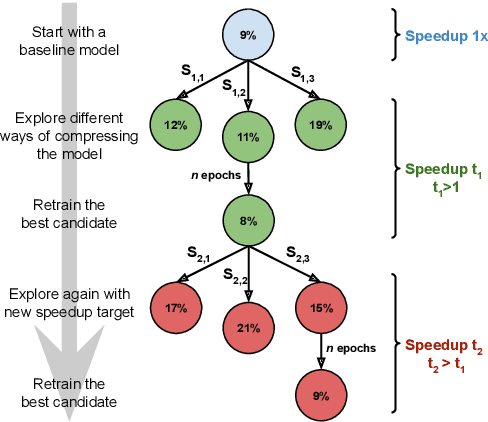
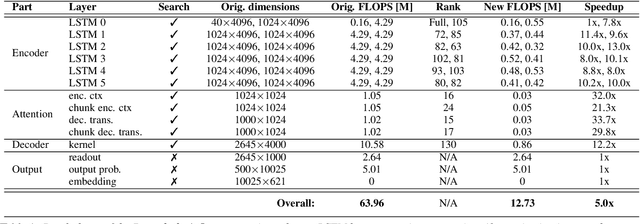
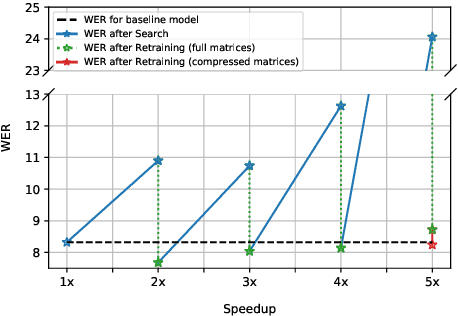
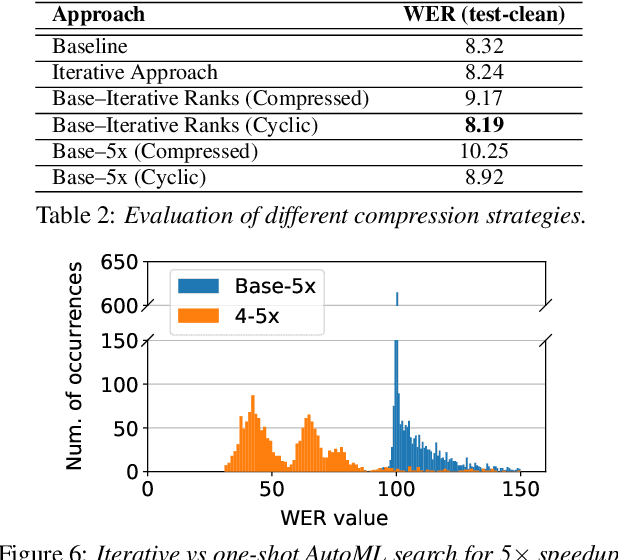
Increasing demand for on-device Automatic Speech Recognition (ASR) systems has resulted in renewed interests in developing automatic model compression techniques. Past research have shown that AutoML-based Low Rank Factorization (LRF) technique, when applied to an end-to-end Encoder-Attention-Decoder style ASR model, can achieve a speedup of up to 3.7x, outperforming laborious manual rank-selection approaches. However, we show that current AutoML-based search techniques only work up to a certain compression level, beyond which they fail to produce compressed models with acceptable word error rates (WER). In this work, we propose an iterative AutoML-based LRF approach that achieves over 5x compression without degrading the WER, thereby advancing the state-of-the-art in ASR compression.