 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining cascaded networks for speeded decisions using a temporal-difference loss
Feb 19, 2021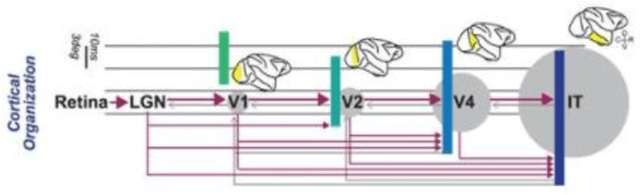
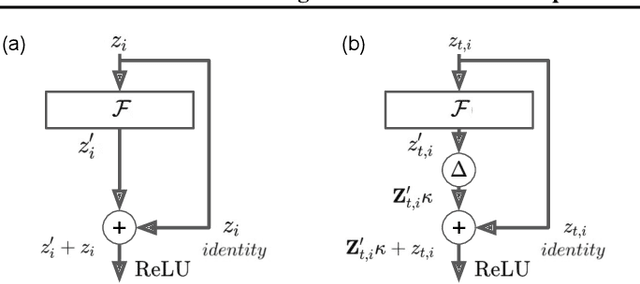

Although deep feedforward neural networks share some characteristics with the primate visual system, a key distinction is their dynamics. Deep nets typically operate in sequential stages wherein each layer fully completes its computation before processing begins in subsequent layers. In contrast, biological systems have cascaded dynamics: information propagates from neurons at all layers in parallel but transmission is gradual over time. In our work, we construct a cascaded ResNet by introducing a propagation delay into each residual block and updating all layers in parallel in a stateful manner. Because information transmitted through skip connections avoids delays, the functional depth of the architecture increases over time and yields a trade off between processing speed and accuracy. We introduce a temporal-difference (TD) training loss that achieves a strictly superior speed accuracy profile over standard losses. The CascadedTD model has intriguing properties, including: typical instances are classified more rapidly than atypical instances; CascadedTD is more robust to both persistent and transient noise than is a conventional ResNet; and the time-varying output trace of CascadedTD provides a signal that can be used by `meta-cognitive' models for OOD detection and to determine when to terminate processing.
NeurIPS 2020 Competition: Predicting Generalization in Deep Learning
Dec 14, 2020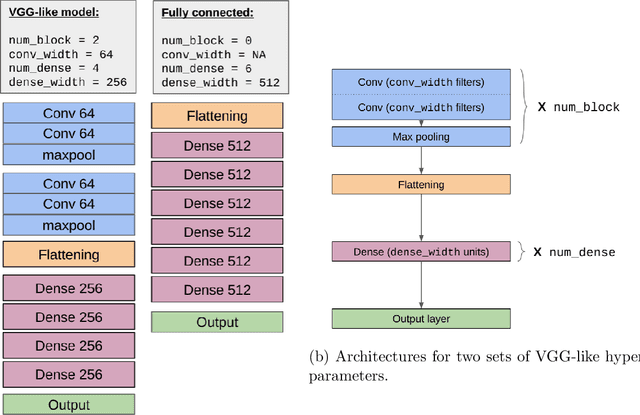
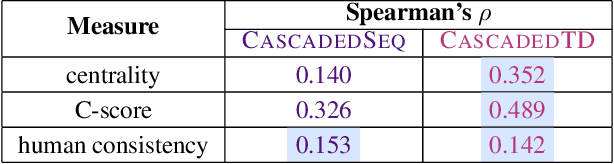
Understanding generalization in deep learning is arguably one of the most important questions in deep learning. Deep learning has been successfully adopted to a large number of problems ranging from pattern recognition to complex decision making, but many recent researchers have raised many concerns about deep learning, among which the most important is generalization. Despite numerous attempts, conventional statistical learning approaches have yet been able to provide a satisfactory explanation on why deep learning works. A recent line of works aims to address the problem by trying to predict the generalization performance through complexity measures. In this competition, we invite the community to propose complexity measures that can accurately predict generalization of models. A robust and general complexity measure would potentially lead to a better understanding of deep learning's underlying mechanism and behavior of deep models on unseen data, or shed light on better generalization bounds. All these outcomes will be important for making deep learning more robust and reliable.
Data Augmentation via Structured Adversarial Perturbations
Nov 05, 2020
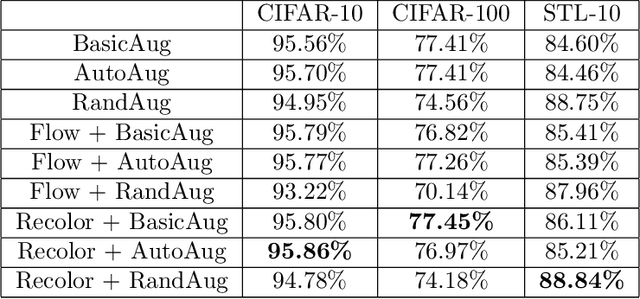

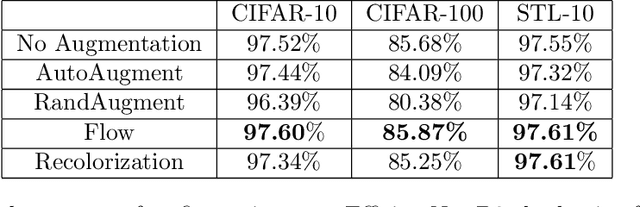
Data augmentation is a major component of many machine learning methods with state-of-the-art performance. Common augmentation strategies work by drawing random samples from a space of transformations. Unfortunately, such sampling approaches are limited in expressivity, as they are unable to scale to rich transformations that depend on numerous parameters due to the curse of dimensionality. Adversarial examples can be considered as an alternative scheme for data augmentation. By being trained on the most difficult modifications of the inputs, the resulting models are then hopefully able to handle other, presumably easier, modifications as well. The advantage of adversarial augmentation is that it replaces sampling with the use of a single, calculated perturbation that maximally increases the loss. The downside, however, is that these raw adversarial perturbations appear rather unstructured; applying them often does not produce a natural transformation, contrary to a desirable data augmentation technique. To address this, we propose a method to generate adversarial examples that maintain some desired natural structure. We first construct a subspace that only contains perturbations with the desired structure. We then project the raw adversarial gradient onto this space to select a structured transformation that would maximally increase the loss when applied. We demonstrate this approach through two types of image transformations: photometric and geometric. Furthermore, we show that training on such structured adversarial images improves generalization.
Characterising Bias in Compressed Models
Oct 06, 2020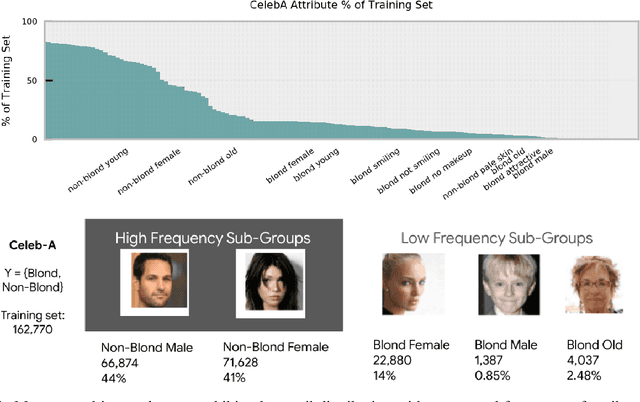
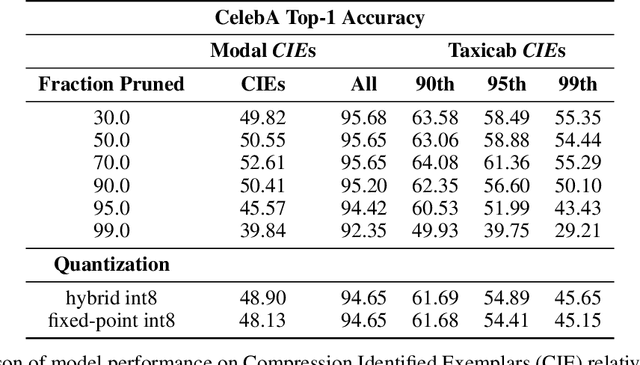
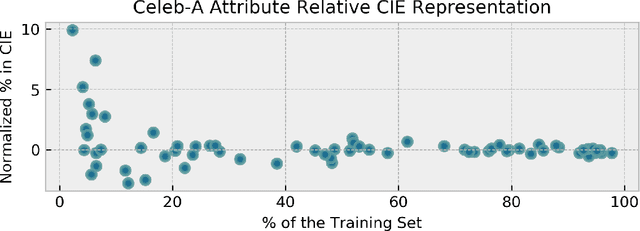
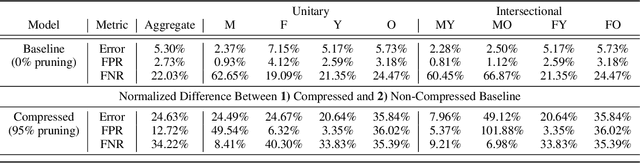
The popularity and widespread use of pruning and quantization is driven by the severe resource constraints of deploying deep neural networks to environments with strict latency, memory and energy requirements. These techniques achieve high levels of compression with negligible impact on top-line metrics (top-1 and top-5 accuracy). However, overall accuracy hides disproportionately high errors on a small subset of examples; we call this subset Compression Identified Exemplars (CIE). We further establish that for CIE examples, compression amplifies existing algorithmic bias. Pruning disproportionately impacts performance on underrepresented features, which often coincides with considerations of fairness. Given that CIE is a relatively small subset but a great contributor of error in the model, we propose its use as a human-in-the-loop auditing tool to surface a tractable subset of the dataset for further inspection or annotation by a domain expert. We provide qualitative and quantitative support that CIE surfaces the most challenging examples in the data distribution for human-in-the-loop auditing.
Auto Completion of User Interface Layout Design Using Transformer-Based Tree Decoders
Jan 14, 2020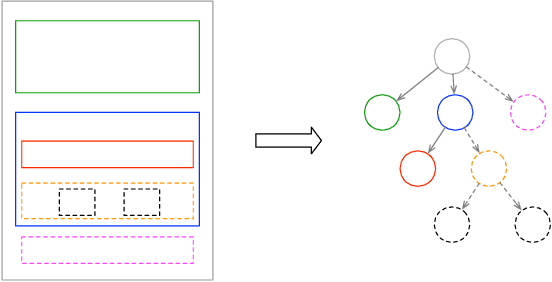

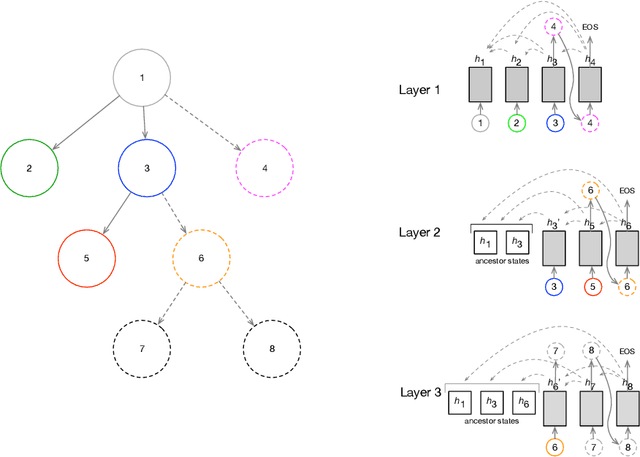
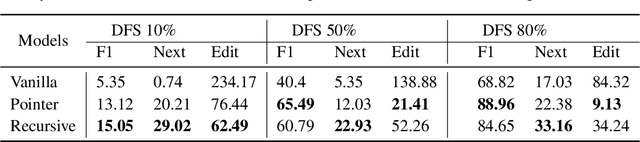
It has been of increasing interest in the field to develop automatic machineries to facilitate the design process. In this paper, we focus on assisting graphical user interface (UI) layout design, a crucial task in app development. Given a partial layout, which a designer has entered, our model learns to complete the layout by predicting the remaining UI elements with a correct position and dimension as well as the hierarchical structures. Such automation will significantly ease the effort of UI designers and developers. While we focus on interface layout prediction, our model can be generally applicable for other layout prediction problems that involve tree structures and 2-dimensional placements. Particularly, we design two versions of Transformer-based tree decoders: Pointer and Recursive Transformer, and experiment with these models on a public dataset. We also propose several metrics for measuring the accuracy of tree prediction and ground these metrics in the domain of user experience. These contribute a new task and methods to deep learning research.
Fantastic Generalization Measures and Where to Find Them
Dec 04, 2019
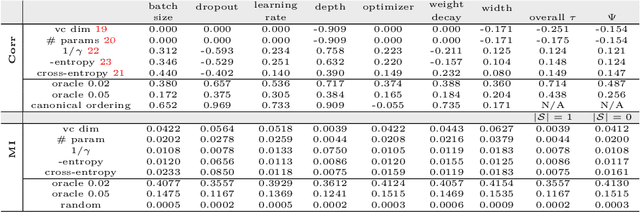
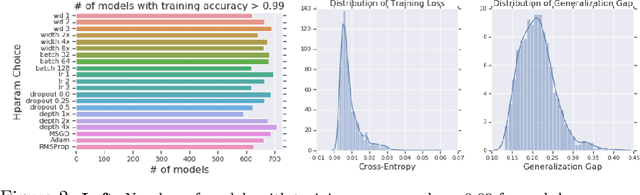
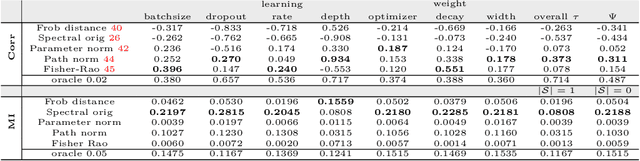
Generalization of deep networks has been of great interest in recent years, resulting in a number of theoretically and empirically motivated complexity measures. However, most papers proposing such measures study only a small set of models, leaving open the question of whether the conclusion drawn from those experiments would remain valid in other settings. We present the first large scale study of generalization in deep networks. We investigate more then 40 complexity measures taken from both theoretical bounds and empirical studies. We train over 10,000 convolutional networks by systematically varying commonly used hyperparameters. Hoping to uncover potentially causal relationships between each measure and generalization, we analyze carefully controlled experiments and show surprising failures of some measures as well as promising measures for further research.
Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML
Sep 19, 2019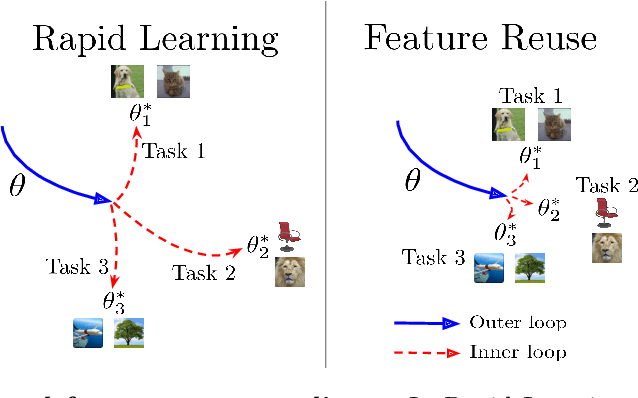

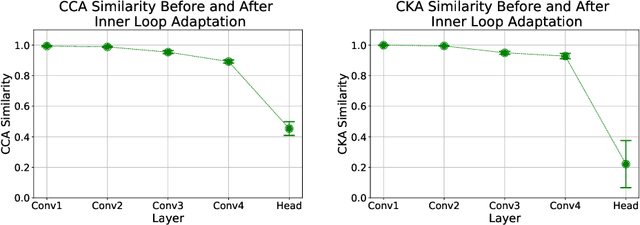

An important research direction in machine learning has centered around developing meta-learning algorithms to tackle few-shot learning. An especially successful algorithm has been Model Agnostic Meta-Learning (MAML), a method that consists of two optimization loops, with the outer loop finding a meta-initialization, from which the inner loop can efficiently learn new tasks. Despite MAML's popularity, a fundamental open question remains -- is the effectiveness of MAML due to the meta-initialization being primed for rapid learning (large, efficient changes in the representations) or due to feature reuse, with the meta initialization already containing high quality features? We investigate this question, via ablation studies and analysis of the latent representations, finding that feature reuse is the dominant factor. This leads to the ANIL (Almost No Inner Loop) algorithm, a simplification of MAML where we remove the inner loop for all but the (task-specific) head of a MAML-trained network. ANIL matches MAML's performance on benchmark few-shot image classification and RL and offers computational improvements over MAML. We further study the precise contributions of the head and body of the network, showing that performance on the test tasks is entirely determined by the quality of the learned features, and we can remove even the head of the network (the NIL algorithm). We conclude with a discussion of the rapid learning vs feature reuse question for meta-learning algorithms more broadly.
Efficient Exploration with Self-Imitation Learning via Trajectory-Conditioned Policy
Jul 24, 2019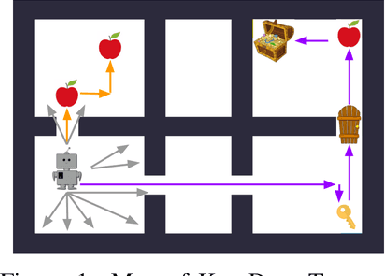
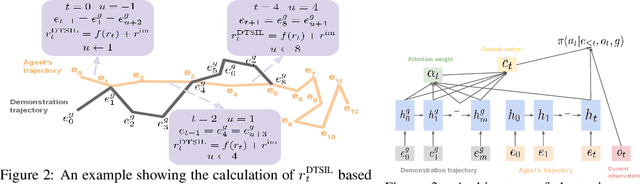
This paper proposes a method for learning a trajectory-conditioned policy to imitate diverse demonstrations from the agent's own past experiences. We demonstrate that such self-imitation drives exploration in diverse directions and increases the chance of finding a globally optimal solution in reinforcement learning problems, especially when the reward is sparse and deceptive. Our method significantly outperforms existing self-imitation learning and count-based exploration methods on various sparse-reward reinforcement learning tasks with local optima. In particular, we report a state-of-the-art score of more than 25,000 points on Montezuma's Revenge without using expert demonstrations or resetting to arbitrary states.
Parallel Scheduled Sampling
Jun 11, 2019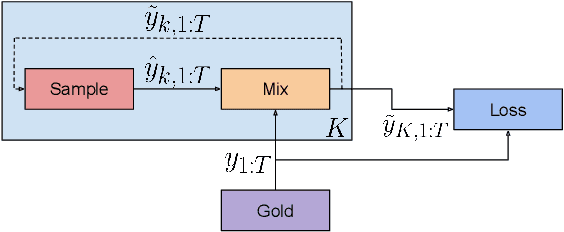
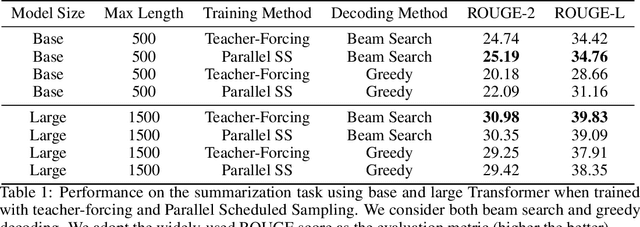
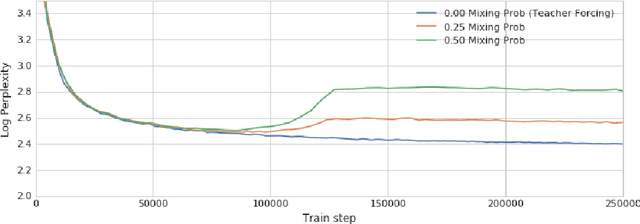
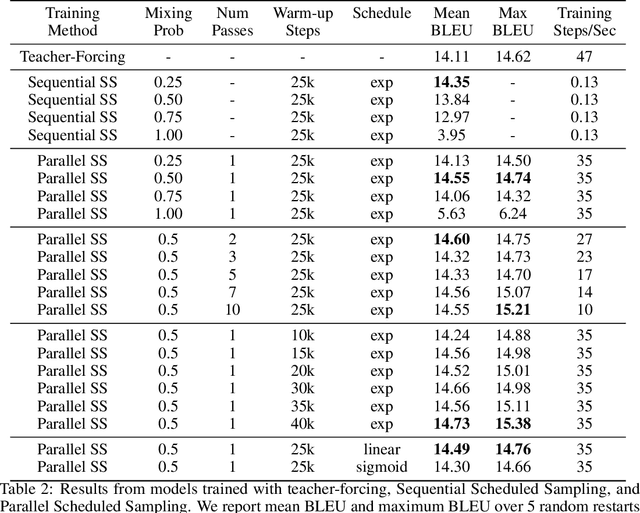
Auto-regressive models are widely used in sequence generation problems. The output sequence is typically generated in a predetermined order, one discrete unit (pixel or word or character) at a time. The models are trained by teacher-forcing where ground-truth history is fed to the model as input, which at test time is replaced by the model prediction. Scheduled Sampling aims to mitigate this discrepancy between train and test time by randomly replacing some discrete units in the history with the model's prediction. While teacher-forced training works well with ML accelerators as the computation can be parallelized across time, Scheduled Sampling involves undesirable sequential processing. In this paper, we introduce a simple technique to parallelize Scheduled Sampling across time. We find that in most cases our technique leads to better empirical performance on summarization and dialog generation tasks compared to teacher-forced training. Further, we discuss the effects of different hyper-parameters associated with Scheduled Sampling on the model performance.
A Closed-Form Learned Pooling for Deep Classification Networks
Jun 10, 2019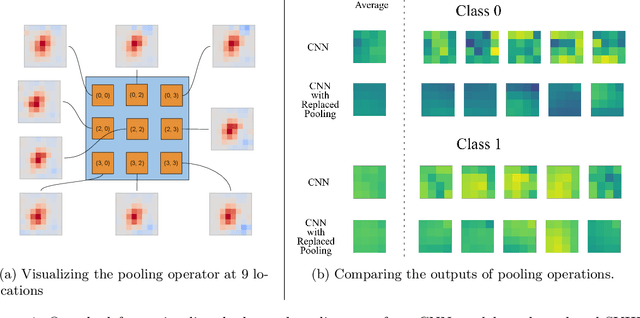
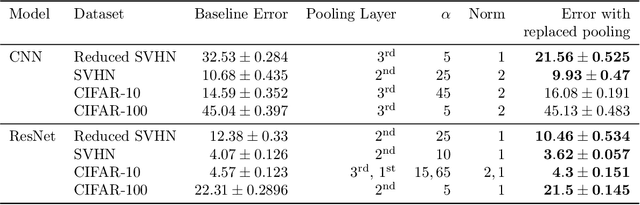
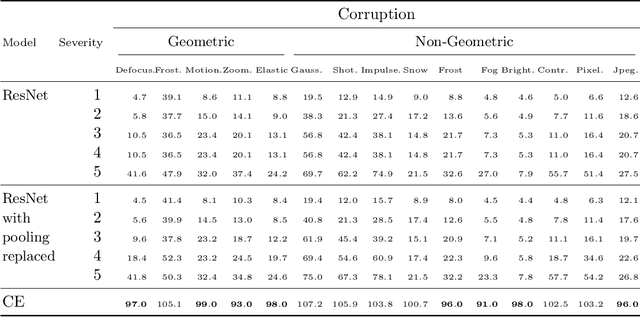
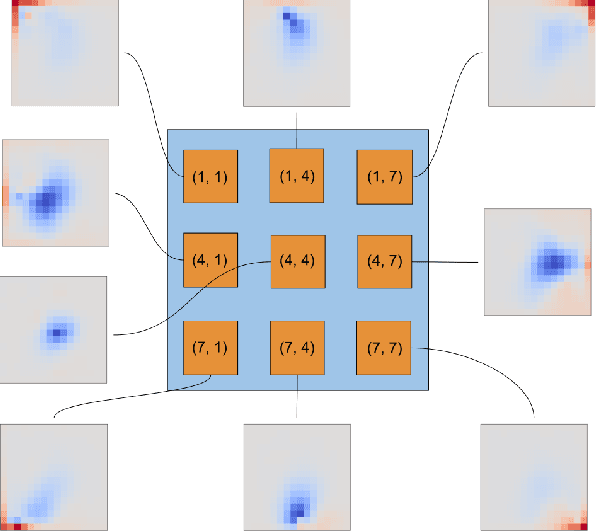
In modern computer vision tasks, convolutional neural networks (CNNs) are indispensable for image classification tasks due to their efficiency and effectiveness. Part of their superiority compared to other architectures, comes from the fact that a single, local filter is shared across the entire image. However, there are scenarios where we may need to treat spatial locations in non-uniform manner. We see this in nature when considering how humans have evolved foveation to process different areas in their field of vision with varying levels of detail. In this paper we propose a way to enable CNNs to learn different pooling weights for each pixel location. We do so by introducing an extended definition of a pooling operator. This operator can learn a strict super-set of what can be learned by average pooling or convolutions. It has the benefit of being shared across feature maps and can be encouraged to be local or diffuse depending on the data. We show that for fixed network weights, our pooling operator can be computed in closed-form by spectral decomposition of matrices associated with class separability. Through experiments, we show that this operator benefits generalization for ResNets and CNNs on the CIFAR-10, CIFAR-100 and SVHN datasets and improves robustness to geometric corruptions and perturbations on the CIFAR-10-C and CIFAR-10-P test sets.