 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling trainability and generalization in deep learning
Dec 30, 2019
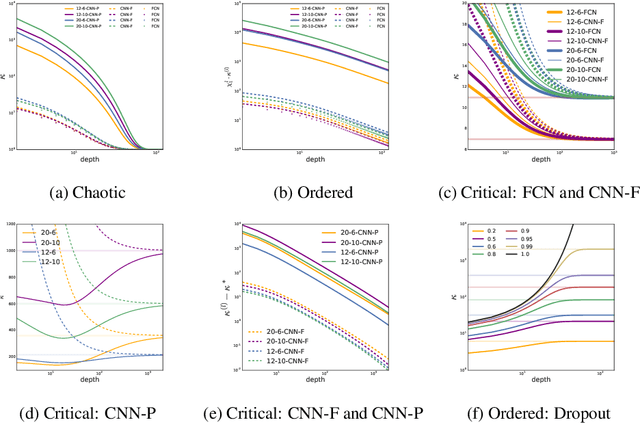
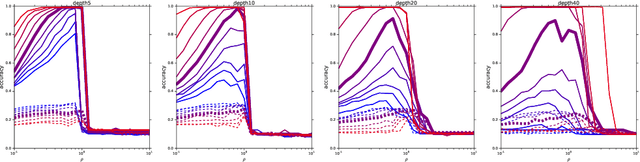
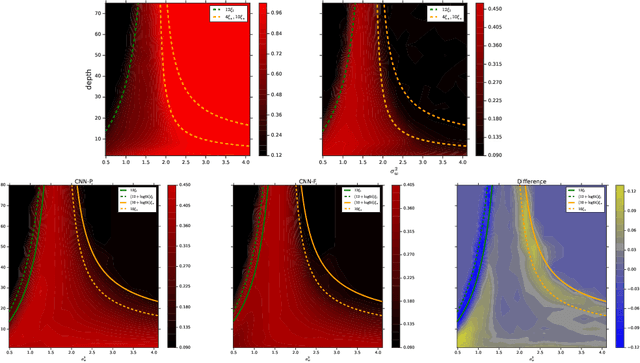
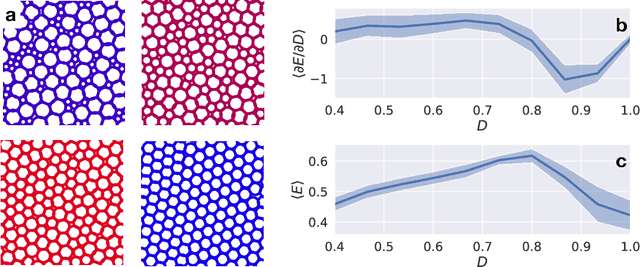
A fundamental goal in deep learning is the characterization of trainability and generalization of neural networks as a function of their architecture and hyperparameters. In this paper, we discuss these challenging issues in the context of wide neural networks at large depths where we will see that the situation simplifies considerably. To do this, we leverage recent advances that have separately shown: (1) that in the wide network limit, random networks before training are Gaussian Processes governed by a kernel known as the Neural Network Gaussian Process (NNGP) kernel, (2) that at large depths the spectrum of the NNGP kernel simplifies considerably and becomes "weakly data-dependent" and (3) that gradient descent training of wide neural networks is described by a kernel called the Neural Tangent Kernel (NTK) that is related to the NNGP. Here we show that in the large depth limit the spectrum of the NTK simplifies in much the same way as that of the NNGP kernel. By analyzing this spectrum, we arrive at a precise characterization of trainability and a necessary condition for generalization across a range of architectures including Fully Connected Networks (FCNs) and Convolutional Neural Networks (CNNs). In particular, we find that there are large regions of hyperparameter space where networks can only memorize the training set in the sense they reach perfect training accuracy but completely fail to generalize outside the training set, in contrast with several recent results. By comparing CNNs with- and without-global average pooling, we show that CNNs without average pooling have very nearly identical learning dynamics to FCNs while CNNs with pooling contain a correction that alters its generalization performance. We perform a thorough empirical investigation of these theoretical results and finding excellent agreement on real datasets.
JAX, M.D.: End-to-End Differentiable, Hardware Accelerated, Molecular Dynamics in Pure Python
Dec 09, 2019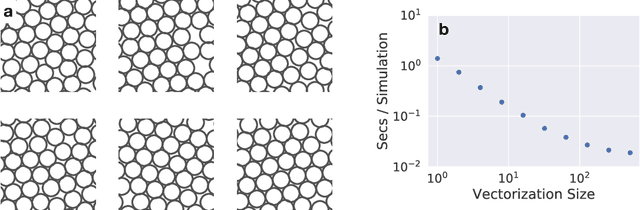
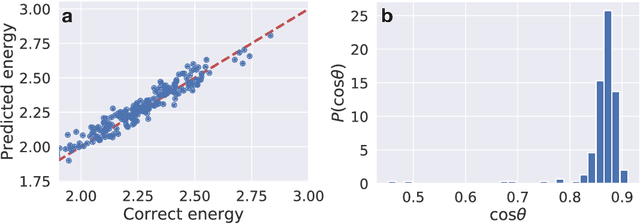

A large fraction of computational science involves simulating the dynamics of particles that interact via pairwise or many-body interactions. These simulations, called Molecular Dynamics (MD), span a vast range of subjects from physics and materials science to biochemistry and drug discovery. Most MD software involves significant use of handwritten derivatives and code reuse across C++, FORTRAN, and CUDA. This is reminiscent of the state of machine learning before automatic differentiation became popular. In this work we bring the substantial advances in software that have taken place in machine learning to MD with JAX, M.D. (JAX MD). JAX MD is an end-to-end differentiable MD package written entirely in Python that can be just-in-time compiled to CPU, GPU, or TPU. JAX MD allows researchers to iterate extremely quickly and lets researchers easily incorporate machine learning models into their workflows. Finally, since all of the simulation code is written in Python, researchers can have unprecedented flexibility in setting up experiments without having to edit any low-level C++ or CUDA code. In addition to making existing workloads easier, JAX MD allows researchers to take derivatives through whole-simulations as well as seamlessly incorporate neural networks into simulations. This paper explores the architecture of JAX MD and its capabilities through several vignettes. Code is available at www.github.com/google/jax-md. We also provide an interactive Colab notebook that goes through all of the experiments discussed in the paper.
Neural Tangents: Fast and Easy Infinite Neural Networks in Python
Dec 05, 2019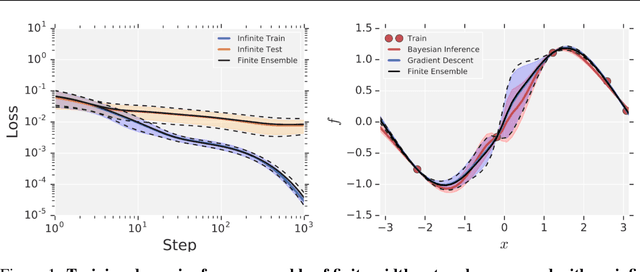
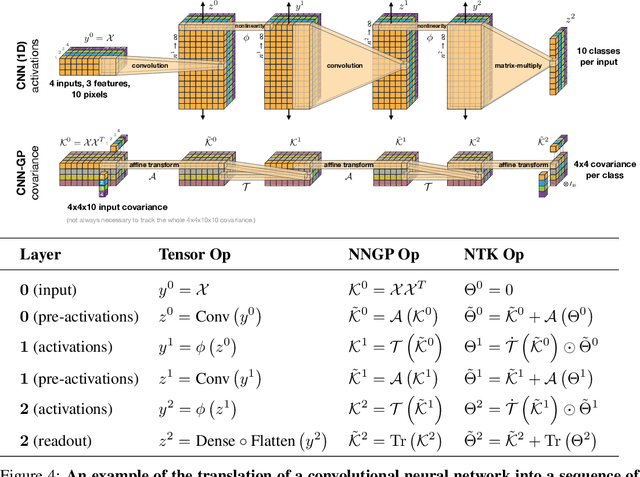
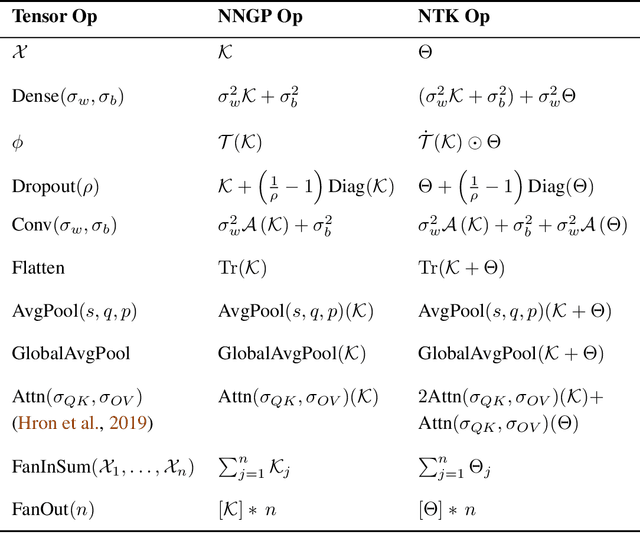
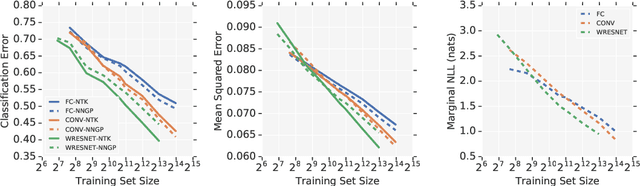
Neural Tangents is a library designed to enable research into infinite-width neural networks. It provides a high-level API for specifying complex and hierarchical neural network architectures. These networks can then be trained and evaluated either at finite-width as usual or in their infinite-width limit. Infinite-width networks can be trained analytically using exact Bayesian inference or using gradient descent via the Neural Tangent Kernel. Additionally, Neural Tangents provides tools to study gradient descent training dynamics of wide but finite networks in either function space or weight space. The entire library runs out-of-the-box on CPU, GPU, or TPU. All computations can be automatically distributed over multiple accelerators with near-linear scaling in the number of devices. Neural Tangents is available at www.github.com/google/neural-tangents. We also provide an accompanying interactive Colab notebook.
A Mean Field Theory of Batch Normalization
Mar 05, 2019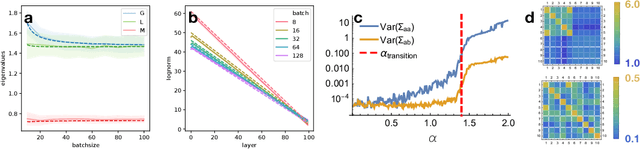
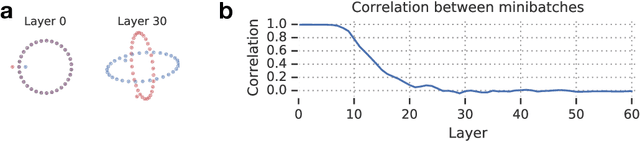
We develop a mean field theory for batch normalization in fully-connected feedforward neural networks. In so doing, we provide a precise characterization of signal propagation and gradient backpropagation in wide batch-normalized networks at initialization. Our theory shows that gradient signals grow exponentially in depth and that these exploding gradients cannot be eliminated by tuning the initial weight variances or by adjusting the nonlinear activation function. Indeed, batch normalization itself is the cause of gradient explosion. As a result, vanilla batch-normalized networks without skip connections are not trainable at large depths for common initialization schemes, a prediction that we verify with a variety of empirical simulations. While gradient explosion cannot be eliminated, it can be reduced by tuning the network close to the linear regime, which improves the trainability of deep batch-normalized networks without residual connections. Finally, we investigate the learning dynamics of batch-normalized networks and observe that after a single step of optimization the networks achieve a relatively stable equilibrium in which gradients have dramatically smaller dynamic range. Our theory leverages Laplace, Fourier, and Gegenbauer transforms and we derive new identities that may be of independent interest.
Wide Neural Networks of Any Depth Evolve as Linear Models Under Gradient Descent
Feb 18, 2019
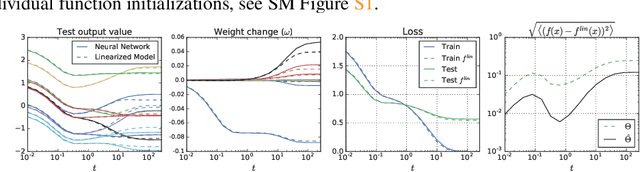
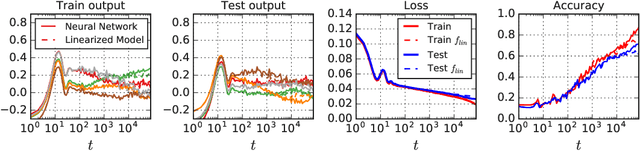
A longstanding goal in deep learning research has been to precisely characterize training and generalization. However, the often complex loss landscapes of neural networks have made a theory of learning dynamics elusive. In this work, we show that for wide neural networks the learning dynamics simplify considerably and that, in the infinite width limit, they are governed by a linear model obtained from the first-order Taylor expansion of the network around its initial parameters. Furthermore, mirroring the correspondence between wide Bayesian neural networks and Gaussian processes, gradient-based training of wide neural networks with a squared loss produces test set predictions drawn from a Gaussian process with a particular compositional kernel. While these theoretical results are only exact in the infinite width limit, we nevertheless find excellent empirical agreement between the predictions of the original network and those of the linearized version even for finite practically-sized networks. This agreement is robust across different architectures, optimization methods, and loss functions.
Dynamical Isometry and a Mean Field Theory of LSTMs and GRUs
Jan 25, 2019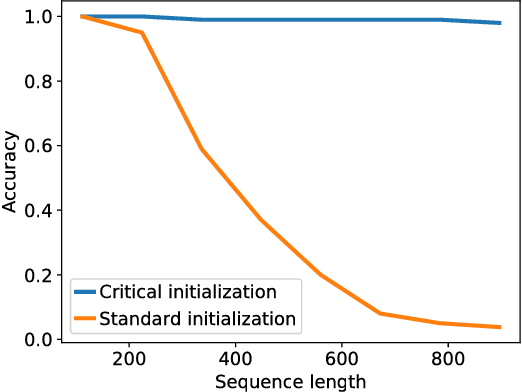

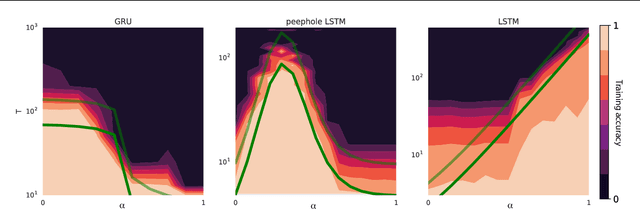

Training recurrent neural networks (RNNs) on long sequence tasks is plagued with difficulties arising from the exponential explosion or vanishing of signals as they propagate forward or backward through the network. Many techniques have been proposed to ameliorate these issues, including various algorithmic and architectural modifications. Two of the most successful RNN architectures, the LSTM and the GRU, do exhibit modest improvements over vanilla RNN cells, but they still suffer from instabilities when trained on very long sequences. In this work, we develop a mean field theory of signal propagation in LSTMs and GRUs that enables us to calculate the time scales for signal propagation as well as the spectral properties of the state-to-state Jacobians. By optimizing these quantities in terms of the initialization hyperparameters, we derive a novel initialization scheme that eliminates or reduces training instabilities. We demonstrate the efficacy of our initialization scheme on multiple sequence tasks, on which it enables successful training while a standard initialization either fails completely or is orders of magnitude slower. We also observe a beneficial effect on generalization performance using this new initialization.
Adversarial Spheres
Sep 10, 2018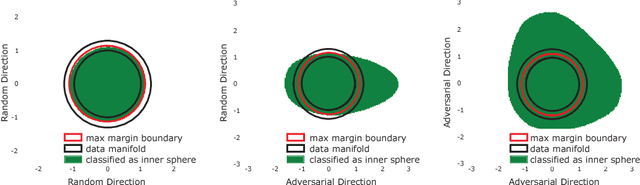
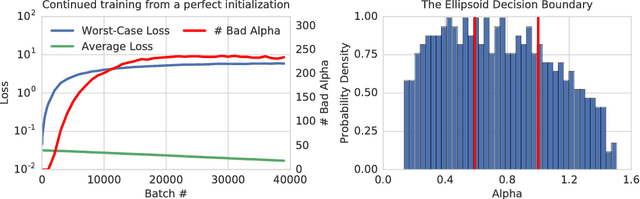
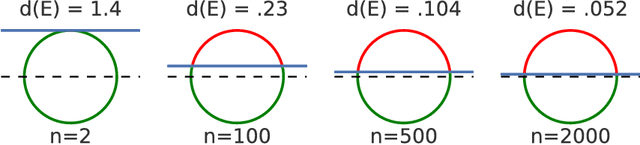
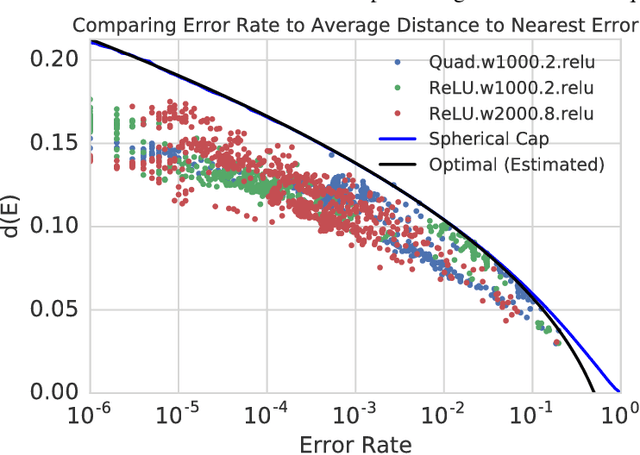
State of the art computer vision models have been shown to be vulnerable to small adversarial perturbations of the input. In other words, most images in the data distribution are both correctly classified by the model and are very close to a visually similar misclassified image. Despite substantial research interest, the cause of the phenomenon is still poorly understood and remains unsolved. We hypothesize that this counter intuitive behavior is a naturally occurring result of the high dimensional geometry of the data manifold. As a first step towards exploring this hypothesis, we study a simple synthetic dataset of classifying between two concentric high dimensional spheres. For this dataset we show a fundamental tradeoff between the amount of test error and the average distance to nearest error. In particular, we prove that any model which misclassifies a small constant fraction of a sphere will be vulnerable to adversarial perturbations of size $O(1/\sqrt{d})$. Surprisingly, when we train several different architectures on this dataset, all of their error sets naturally approach this theoretical bound. As a result of the theory, the vulnerability of neural networks to small adversarial perturbations is a logical consequence of the amount of test error observed. We hope that our theoretical analysis of this very simple case will point the way forward to explore how the geometry of complex real-world data sets leads to adversarial examples.
Peptide-Spectra Matching from Weak Supervision
Aug 22, 2018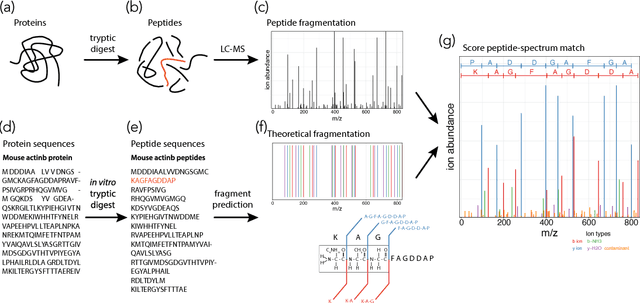

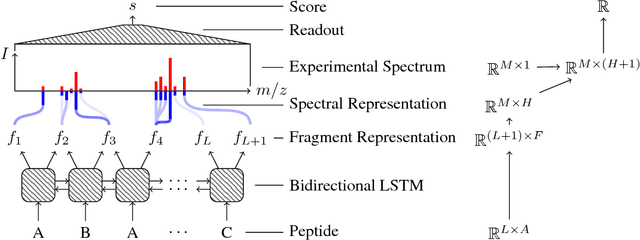

As in many other scientific domains, we face a fundamental problem when using machine learning to identify proteins from mass spectrometry data: large ground truth datasets mapping inputs to correct outputs are extremely difficult to obtain. Instead, we have access to imperfect hand-coded models crafted by domain experts. In this paper, we apply deep neural networks to an important step of the protein identification problem, the pairing of mass spectra with short sequences of amino acids called peptides. We train our model to differentiate between top scoring results from a state-of-the art classical system and hard-negative second and third place results. Our resulting model is much better at identifying peptides with spectra than the model used to generate its training data. In particular, we achieve a 43% improvement over standard matching methods and a 10% improvement over a combination of the matching method and an industry standard cross-spectra reranking tool. Importantly, in a more difficult experimental regime that reflects current challenges facing biologists, our advantage over the previous state-of-the-art grows to 15% even after reranking. We believe this approach will generalize to other challenging scientific problems.
Dynamical Isometry and a Mean Field Theory of RNNs: Gating Enables Signal Propagation in Recurrent Neural Networks
Aug 15, 2018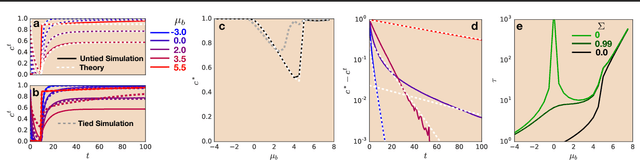
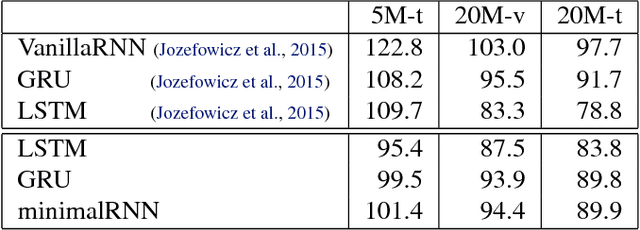
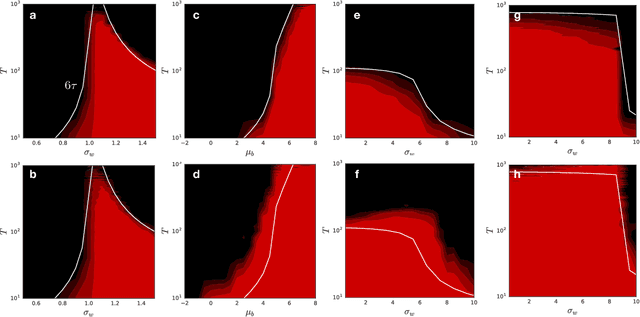
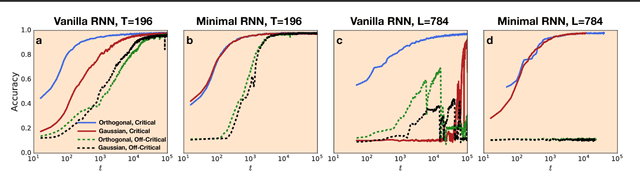
Recurrent neural networks have gained widespread use in modeling sequence data across various domains. While many successful recurrent architectures employ a notion of gating, the exact mechanism that enables such remarkable performance is not well understood. We develop a theory for signal propagation in recurrent networks after random initialization using a combination of mean field theory and random matrix theory. To simplify our discussion, we introduce a new RNN cell with a simple gating mechanism that we call the minimalRNN and compare it with vanilla RNNs. Our theory allows us to define a maximum timescale over which RNNs can remember an input. We show that this theory predicts trainability for both recurrent architectures. We show that gated recurrent networks feature a much broader, more robust, trainable region than vanilla RNNs, which corroborates recent experimental findings. Finally, we develop a closed-form critical initialization scheme that achieves dynamical isometry in both vanilla RNNs and minimalRNNs. We show that this results in significantly improvement in training dynamics. Finally, we demonstrate that the minimalRNN achieves comparable performance to its more complex counterparts, such as LSTMs or GRUs, on a language modeling task.
Dynamical Isometry and a Mean Field Theory of CNNs: How to Train 10,000-Layer Vanilla Convolutional Neural Networks
Jul 10, 2018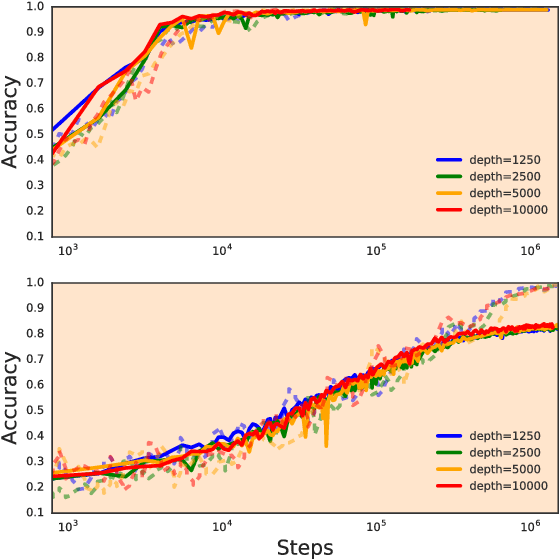
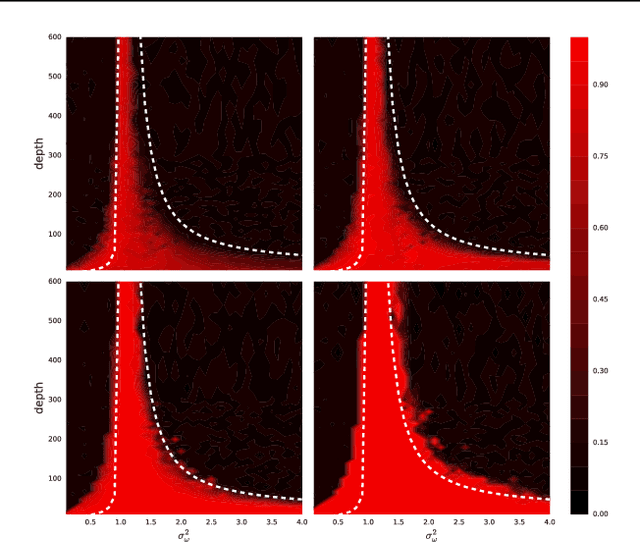
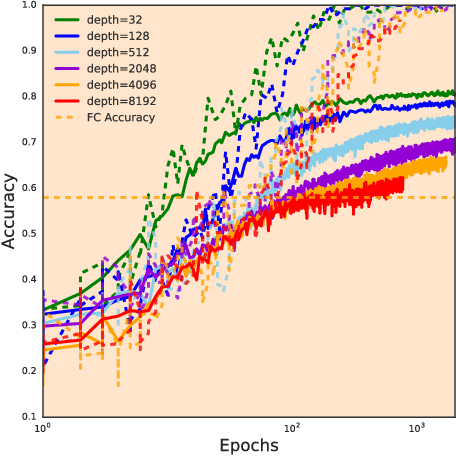
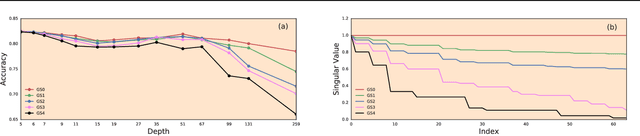
In recent years, state-of-the-art methods in computer vision have utilized increasingly deep convolutional neural network architectures (CNNs), with some of the most successful models employing hundreds or even thousands of layers. A variety of pathologies such as vanishing/exploding gradients make training such deep networks challenging. While residual connections and batch normalization do enable training at these depths, it has remained unclear whether such specialized architecture designs are truly necessary to train deep CNNs. In this work, we demonstrate that it is possible to train vanilla CNNs with ten thousand layers or more simply by using an appropriate initialization scheme. We derive this initialization scheme theoretically by developing a mean field theory for signal propagation and by characterizing the conditions for dynamical isometry, the equilibration of singular values of the input-output Jacobian matrix. These conditions require that the convolution operator be an orthogonal transformation in the sense that it is norm-preserving. We present an algorithm for generating such random initial orthogonal convolution kernels and demonstrate empirically that they enable efficient training of extremely deep architectures.