 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Causal Effects from Natural Language Queries using Structured Representations
May 28, 2026Randomized controlled trials are a cornerstone of medicine and the social sciences as they enable reliable estimates of causal effects. However, they are costly and time-consuming to conduct, motivating interest in predicting causal effects from existing experimental evidence. Recent advances in large language models (LLMs) have demonstrated strong performance on knowledge-intensive tasks, raising the question of whether these models can be used for forecasting causal effect sizes. To investigate this, we introduce Query2Effect, a new large-scale benchmark consisting of more than 72,000 natural language questions aligned with experiment descriptions, created to simulate realistic information-seeking scenarios by varying query specificity along dimensions of implicitness, abstraction, and ambiguity. We then propose a two-step framework that first generates a synthetic structured representation of a query before predicting effect size using a supervised encoder model. Experiments show that finetuning plays a crucial role in improving prediction performance, with absolute error reducing by -27% up to -71% compared to prompted out-of-the-box LLMs, and that our two-step framework is beneficial for out-of-domain generalization, highlighting the benefits of separating semantic interpretation from numerical effect estimation.
Towards Loosely-Coupling Knowledge Graph Embeddings and Ontology-based Reasoning
Feb 07, 2022
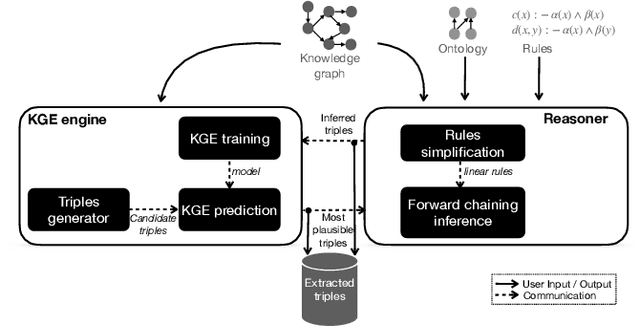

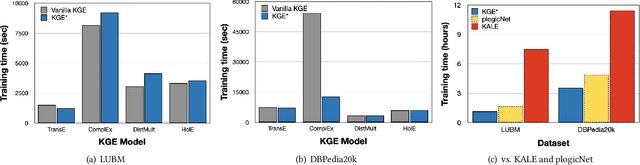
Knowledge graph completion (a.k.a.~link prediction), i.e.,~the task of inferring missing information from knowledge graphs, is a widely used task in many applications, such as product recommendation and question answering. The state-of-the-art approaches of knowledge graph embeddings and/or rule mining and reasoning are data-driven and, thus, solely based on the information the input knowledge graph contains. This leads to unsatisfactory prediction results which make such solutions inapplicable to crucial domains such as healthcare. To further enhance the accuracy of knowledge graph completion we propose to loosely-couple the data-driven power of knowledge graph embeddings with domain-specific reasoning stemming from experts or entailment regimes (e.g., OWL2). In this way, we not only enhance the prediction accuracy with domain knowledge that may not be included in the input knowledge graph but also allow users to plugin their own knowledge graph embedding and reasoning method. Our initial results show that we enhance the MRR accuracy of vanilla knowledge graph embeddings by up to 3x and outperform hybrid solutions that combine knowledge graph embeddings with rule mining and reasoning up to 3.5x MRR.