 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Causal Effects from Natural Language Queries using Structured Representations
May 28, 2026Randomized controlled trials are a cornerstone of medicine and the social sciences as they enable reliable estimates of causal effects. However, they are costly and time-consuming to conduct, motivating interest in predicting causal effects from existing experimental evidence. Recent advances in large language models (LLMs) have demonstrated strong performance on knowledge-intensive tasks, raising the question of whether these models can be used for forecasting causal effect sizes. To investigate this, we introduce Query2Effect, a new large-scale benchmark consisting of more than 72,000 natural language questions aligned with experiment descriptions, created to simulate realistic information-seeking scenarios by varying query specificity along dimensions of implicitness, abstraction, and ambiguity. We then propose a two-step framework that first generates a synthetic structured representation of a query before predicting effect size using a supervised encoder model. Experiments show that finetuning plays a crucial role in improving prediction performance, with absolute error reducing by -27% up to -71% compared to prompted out-of-the-box LLMs, and that our two-step framework is beneficial for out-of-domain generalization, highlighting the benefits of separating semantic interpretation from numerical effect estimation.
Cultural Fidelity in Large-Language Models: An Evaluation of Online Language Resources as a Driver of Model Performance in Value Representation
Oct 14, 2024
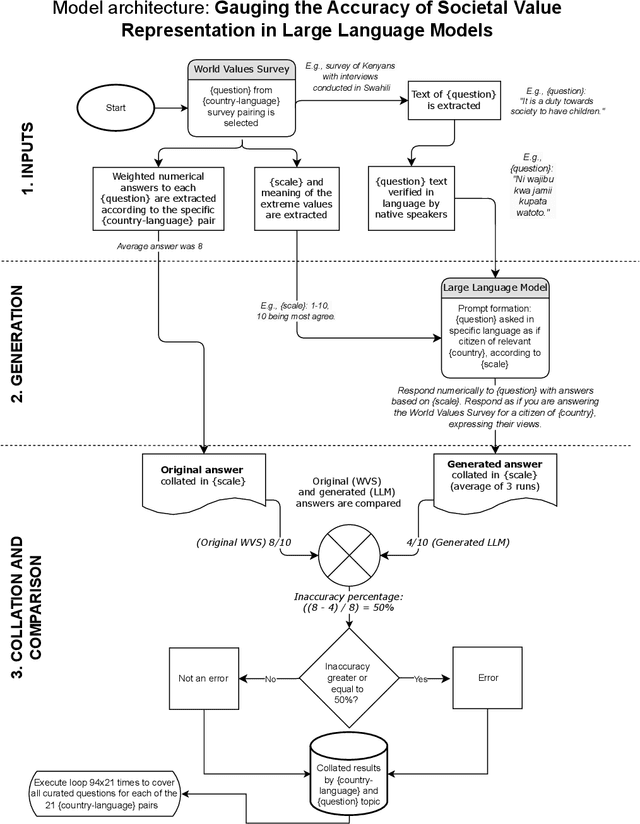
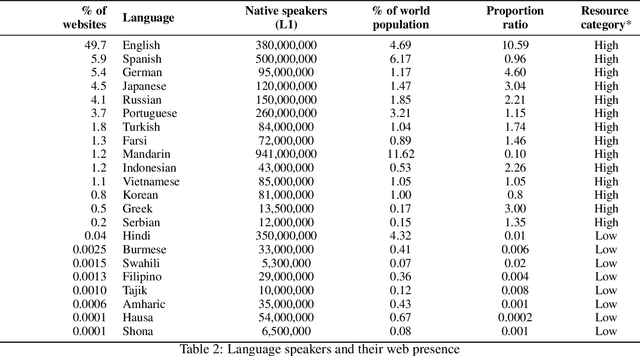
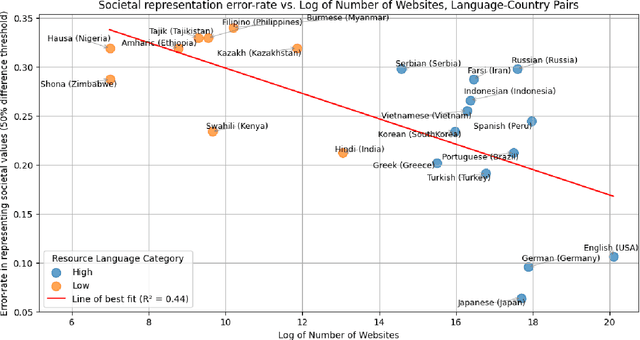
The training data for LLMs embeds societal values, increasing their familiarity with the language's culture. Our analysis found that 44% of the variance in the ability of GPT-4o to reflect the societal values of a country, as measured by the World Values Survey, correlates with the availability of digital resources in that language. Notably, the error rate was more than five times higher for the languages of the lowest resource compared to the languages of the highest resource. For GPT-4-turbo, this correlation rose to 72%, suggesting efforts to improve the familiarity with the non-English language beyond the web-scraped data. Our study developed one of the largest and most robust datasets in this topic area with 21 country-language pairs, each of which contain 94 survey questions verified by native speakers. Our results highlight the link between LLM performance and digital data availability in target languages. Weaker performance in low-resource languages, especially prominent in the Global South, may worsen digital divides. We discuss strategies proposed to address this, including developing multilingual LLMs from the ground up and enhancing fine-tuning on diverse linguistic datasets, as seen in African language initiatives.