 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Transpile AMR into SPARQL
Dec 15, 2021

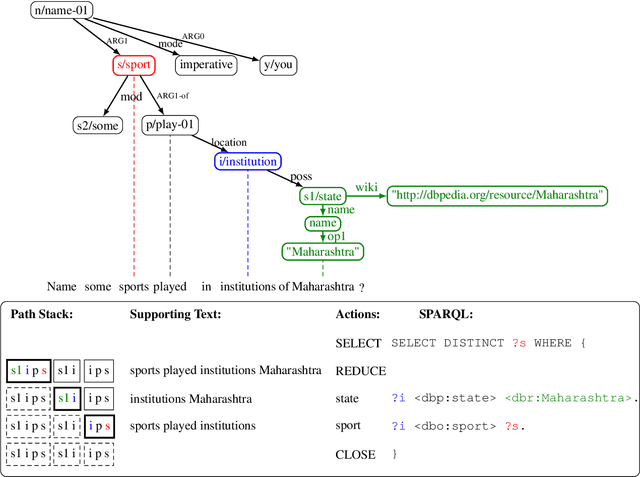
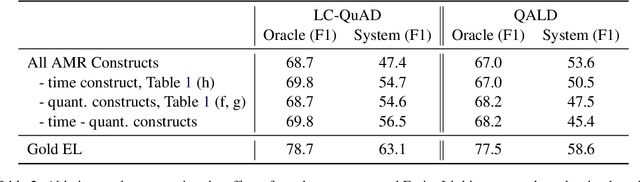
We propose a transition-based system to transpile Abstract Meaning Representation (AMR) into SPARQL for Knowledge Base Question Answering (KBQA). This allows to delegate part of the abstraction problem to a strongly pre-trained semantic parser, while learning transpiling with small amount of paired data. We departure from recent work relating AMR and SPARQL constructs, but rather than applying a set of rules, we teach the BART model to selectively use these relations. Further, we avoid explicitly encoding AMR but rather encode the parser state in the attention mechanism of BART, following recent semantic parsing works. The resulting model is simple, provides supporting text for its decisions, and outperforms recent progress in AMR-based KBQA in LC-QuAD (F1 53.4), matching it in QALD (F1 30.8), while exploiting the same inductive biases.
Maximum Bayes Smatch Ensemble Distillation for AMR Parsing
Dec 14, 2021
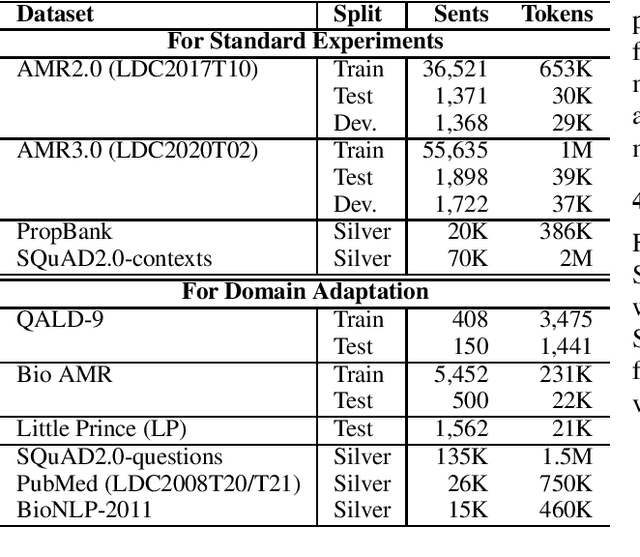
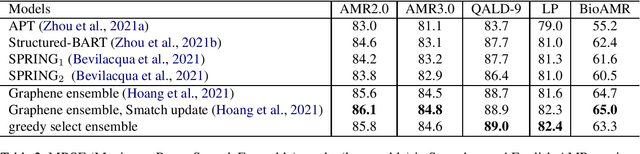
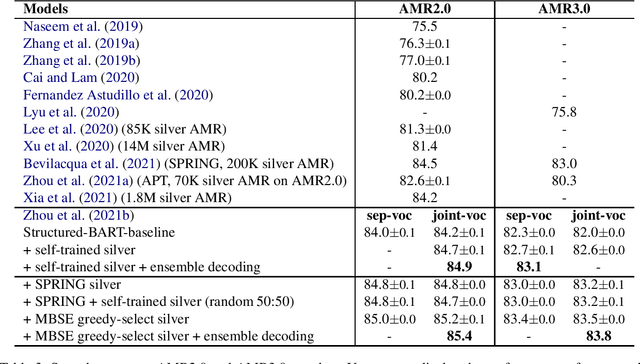
AMR parsing has experienced an unprecendented increase in performance in the last three years, due to a mixture of effects including architecture improvements and transfer learning. Self-learning techniques have also played a role in pushing performance forward. However, for most recent high performant parsers, the effect of self-learning and silver data generation seems to be fading. In this paper we show that it is possible to overcome this diminishing returns of silver data by combining Smatch-based ensembling techniques with ensemble distillation. In an extensive experimental setup, we push single model English parser performance above 85 Smatch for the first time and return to substantial gains. We also attain a new state-of-the-art for cross-lingual AMR parsing for Chinese, German, Italian and Spanish. Finally we explore the impact of the proposed distillation technique on domain adaptation, and show that it can produce gains rivaling those of human annotated data for QALD-9 and achieve a new state-of-the-art for BioAMR.
Structure-aware Fine-tuning of Sequence-to-sequence Transformers for Transition-based AMR Parsing
Oct 29, 2021
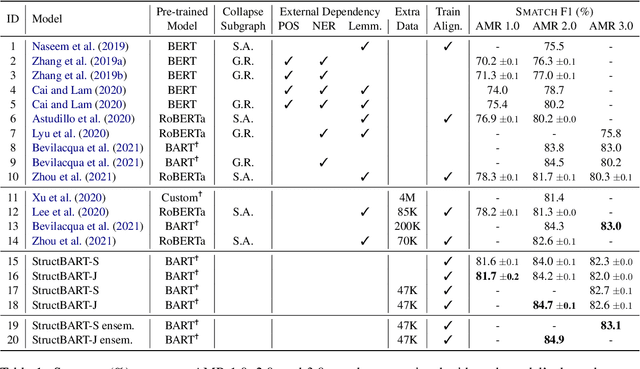
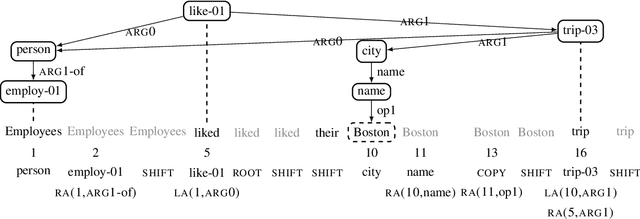
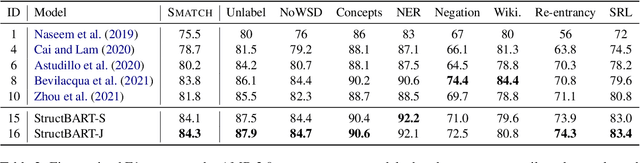
Predicting linearized Abstract Meaning Representation (AMR) graphs using pre-trained sequence-to-sequence Transformer models has recently led to large improvements on AMR parsing benchmarks. These parsers are simple and avoid explicit modeling of structure but lack desirable properties such as graph well-formedness guarantees or built-in graph-sentence alignments. In this work we explore the integration of general pre-trained sequence-to-sequence language models and a structure-aware transition-based approach. We depart from a pointer-based transition system and propose a simplified transition set, designed to better exploit pre-trained language models for structured fine-tuning. We also explore modeling the parser state within the pre-trained encoder-decoder architecture and different vocabulary strategies for the same purpose. We provide a detailed comparison with recent progress in AMR parsing and show that the proposed parser retains the desirable properties of previous transition-based approaches, while being simpler and reaching the new parsing state of the art for AMR 2.0, without the need for graph re-categorization.
SYGMA: System for Generalizable Modular Question Answering OverKnowledge Bases
Sep 28, 2021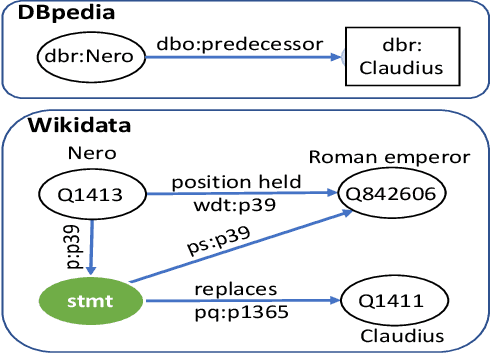

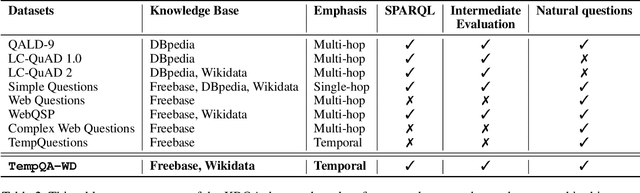

Knowledge Base Question Answering (KBQA) tasks that in-volve complex reasoning are emerging as an important re-search direction. However, most KBQA systems struggle withgeneralizability, particularly on two dimensions: (a) acrossmultiple reasoning types where both datasets and systems haveprimarily focused on multi-hop reasoning, and (b) across mul-tiple knowledge bases, where KBQA approaches are specif-ically tuned to a single knowledge base. In this paper, wepresent SYGMA, a modular approach facilitating general-izability across multiple knowledge bases and multiple rea-soning types. Specifically, SYGMA contains three high levelmodules: 1) KB-agnostic question understanding module thatis common across KBs 2) Rules to support additional reason-ing types and 3) KB-specific question mapping and answeringmodule to address the KB-specific aspects of the answer ex-traction. We demonstrate effectiveness of our system by evalu-ating on datasets belonging to two distinct knowledge bases,DBpedia and Wikidata. In addition, to demonstrate extensi-bility to additional reasoning types we evaluate on multi-hopreasoning datasets and a new Temporal KBQA benchmarkdataset on Wikidata, namedTempQA-WD1, introduced in thispaper. We show that our generalizable approach has bettercompetetive performance on multiple datasets on DBpediaand Wikidata that requires both multi-hop and temporal rea-soning
Combining Rules and Embeddings via Neuro-Symbolic AI for Knowledge Base Completion
Sep 16, 2021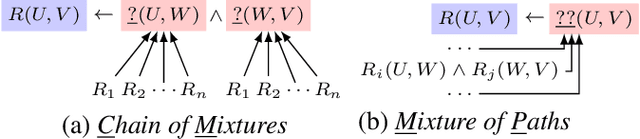
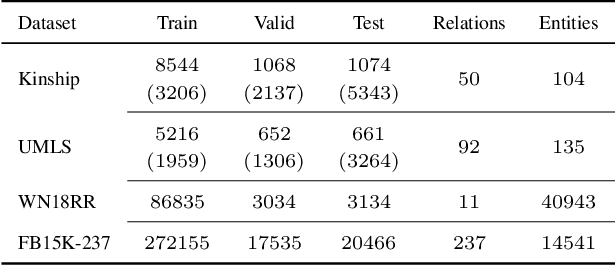
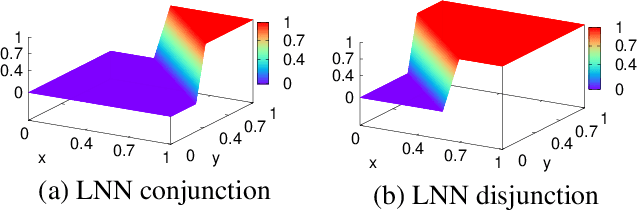
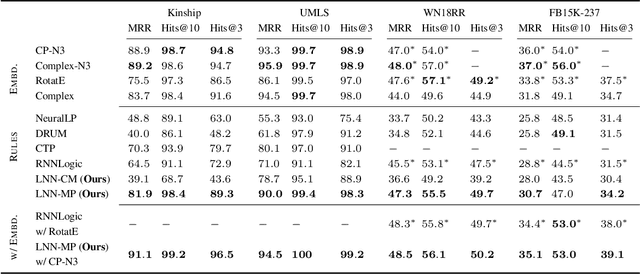
Recent interest in Knowledge Base Completion (KBC) has led to a plethora of approaches based on reinforcement learning, inductive logic programming and graph embeddings. In particular, rule-based KBC has led to interpretable rules while being comparable in performance with graph embeddings. Even within rule-based KBC, there exist different approaches that lead to rules of varying quality and previous work has not always been precise in highlighting these differences. Another issue that plagues most rule-based KBC is the non-uniformity of relation paths: some relation sequences occur in very few paths while others appear very frequently. In this paper, we show that not all rule-based KBC models are the same and propose two distinct approaches that learn in one case: 1) a mixture of relations and the other 2) a mixture of paths. When implemented on top of neuro-symbolic AI, which learns rules by extending Boolean logic to real-valued logic, the latter model leads to superior KBC accuracy outperforming state-of-the-art rule-based KBC by 2-10% in terms of mean reciprocal rank. Furthermore, to address the non-uniformity of relation paths, we combine rule-based KBC with graph embeddings thus improving our results even further and achieving the best of both worlds.
Bootstrapping Multilingual AMR with Contextual Word Alignments
Feb 03, 2021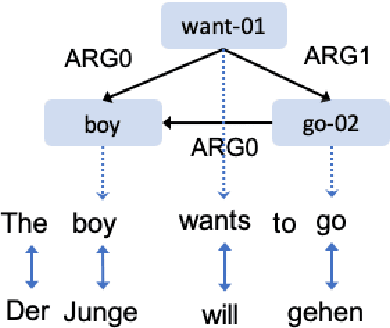
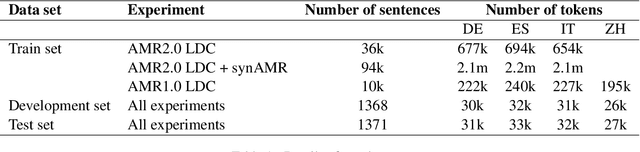
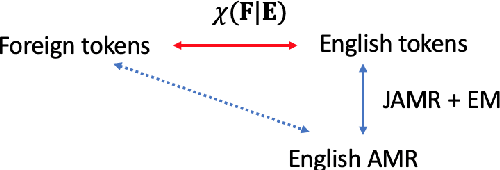
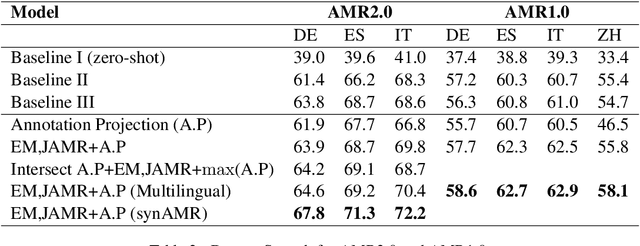
We develop high performance multilingualAbstract Meaning Representation (AMR) sys-tems by projecting English AMR annotationsto other languages with weak supervision. Weachieve this goal by bootstrapping transformer-based multilingual word embeddings, in partic-ular those from cross-lingual RoBERTa (XLM-R large). We develop a novel technique forforeign-text-to-English AMR alignment, usingthe contextual word alignment between En-glish and foreign language tokens. This wordalignment is weakly supervised and relies onthe contextualized XLM-R word embeddings.We achieve a highly competitive performancethat surpasses the best published results forGerman, Italian, Spanish and Chinese.
Question Answering over Knowledge Bases by Leveraging Semantic Parsing and Neuro-Symbolic Reasoning
Dec 03, 2020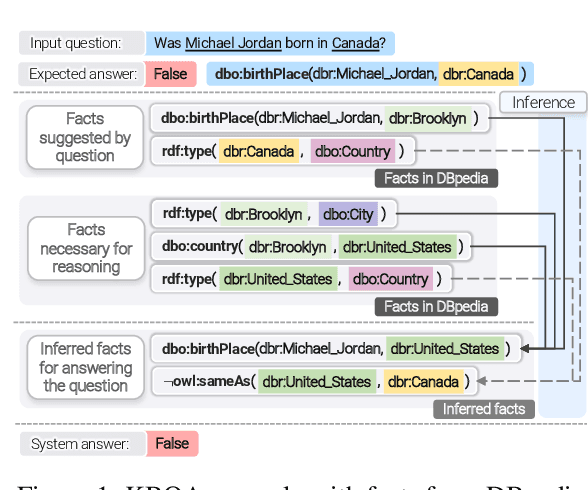
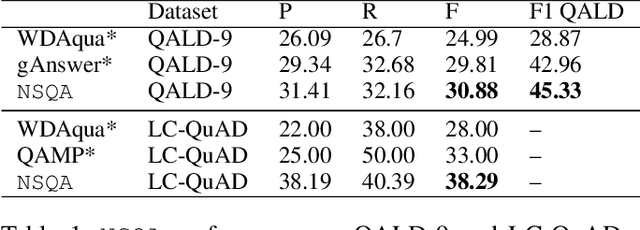
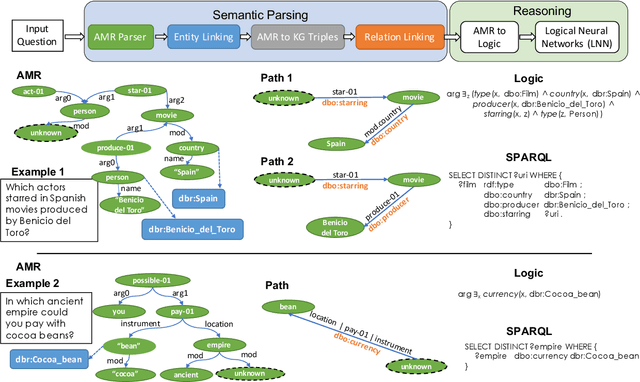

Knowledge base question answering (KBQA) is an important task in Natural Language Processing. Existing approaches face significant challenges including complex question understanding, necessity for reasoning, and lack of large training datasets. In this work, we propose a semantic parsing and reasoning-based Neuro-Symbolic Question Answering(NSQA) system, that leverages (1) Abstract Meaning Representation (AMR) parses for task-independent question under-standing; (2) a novel path-based approach to transform AMR parses into candidate logical queries that are aligned to the KB; (3) a neuro-symbolic reasoner called Logical Neural Net-work (LNN) that executes logical queries and reasons over KB facts to provide an answer; (4) system of systems approach,which integrates multiple, reusable modules that are trained specifically for their individual tasks (e.g. semantic parsing,entity linking, and relationship linking) and do not require end-to-end training data. NSQA achieves state-of-the-art performance on QALD-9 and LC-QuAD 1.0. NSQA's novelty lies in its modular neuro-symbolic architecture and its task-general approach to interpreting natural language questions.
End-to-End QA on COVID-19: Domain Adaptation with Synthetic Training
Dec 02, 2020
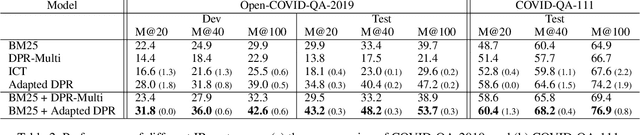


End-to-end question answering (QA) requires both information retrieval (IR) over a large document collection and machine reading comprehension (MRC) on the retrieved passages. Recent work has successfully trained neural IR systems using only supervised question answering (QA) examples from open-domain datasets. However, despite impressive performance on Wikipedia, neural IR lags behind traditional term matching approaches such as BM25 in more specific and specialized target domains such as COVID-19. Furthermore, given little or no labeled data, effective adaptation of QA systems can also be challenging in such target domains. In this work, we explore the application of synthetically generated QA examples to improve performance on closed-domain retrieval and MRC. We combine our neural IR and MRC systems and show significant improvements in end-to-end QA on the CORD-19 collection over a state-of-the-art open-domain QA baseline.
Pushing the Limits of AMR Parsing with Self-Learning
Oct 20, 2020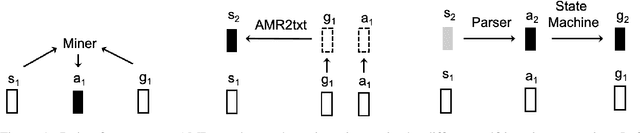

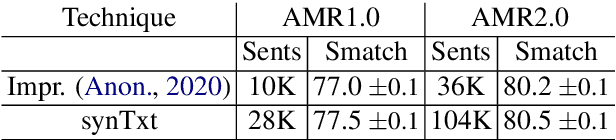
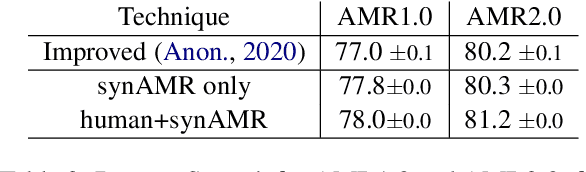
Abstract Meaning Representation (AMR) parsing has experienced a notable growth in performance in the last two years, due both to the impact of transfer learning and the development of novel architectures specific to AMR. At the same time, self-learning techniques have helped push the performance boundaries of other natural language processing applications, such as machine translation or question answering. In this paper, we explore different ways in which trained models can be applied to improve AMR parsing performance, including generation of synthetic text and AMR annotations as well as refinement of actions oracle. We show that, without any additional human annotations, these techniques improve an already performant parser and achieve state-of-the-art results on AMR 1.0 and AMR 2.0.
Multi-Stage Pre-training for Low-Resource Domain Adaptation
Oct 12, 2020
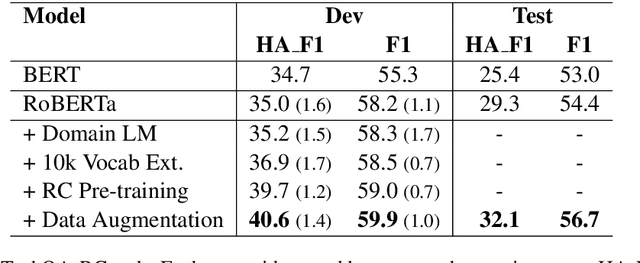
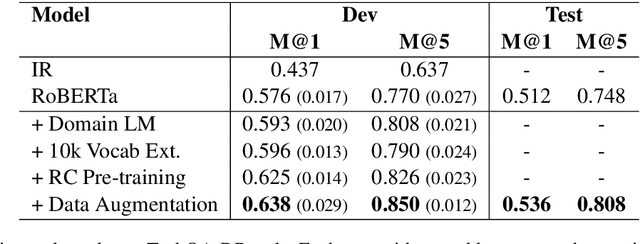
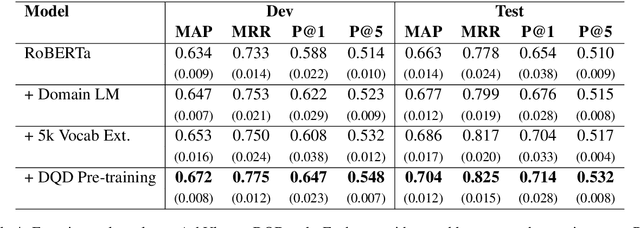
Transfer learning techniques are particularly useful in NLP tasks where a sizable amount of high-quality annotated data is difficult to obtain. Current approaches directly adapt a pre-trained language model (LM) on in-domain text before fine-tuning to downstream tasks. We show that extending the vocabulary of the LM with domain-specific terms leads to further gains. To a bigger effect, we utilize structure in the unlabeled data to create auxiliary synthetic tasks, which helps the LM transfer to downstream tasks. We apply these approaches incrementally on a pre-trained Roberta-large LM and show considerable performance gain on three tasks in the IT domain: Extractive Reading Comprehension, Document Ranking and Duplicate Question Detection.