 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSabato Marco Siniscalchi
Inference and Denoise: Causal Inference-based Neural Speech Enhancement
Nov 02, 2022
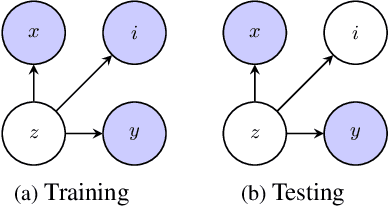
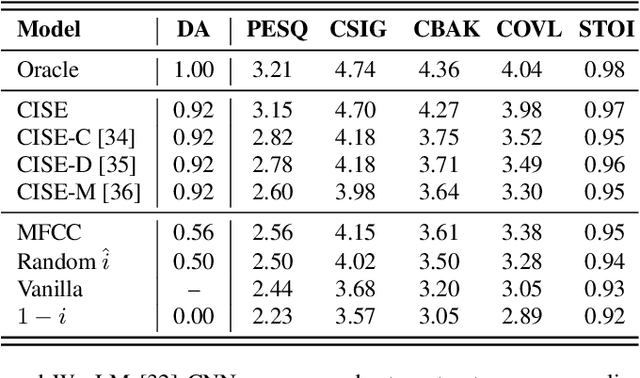
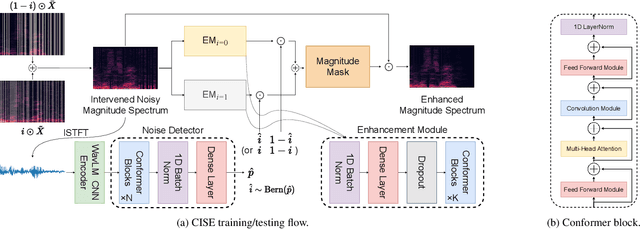
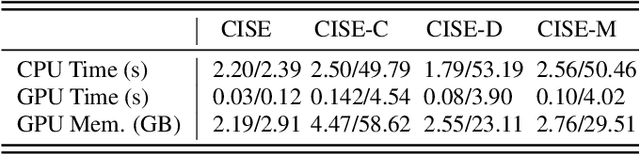
This study addresses the speech enhancement (SE) task within the causal inference paradigm by modeling the noise presence as an intervention. Based on the potential outcome framework, the proposed causal inference-based speech enhancement (CISE) separates clean and noisy frames in an intervened noisy speech using a noise detector and assigns both sets of frames to two mask-based enhancement modules (EMs) to perform noise-conditional SE. Specifically, we use the presence of noise as guidance for EM selection during training, and the noise detector selects the enhancement module according to the prediction of the presence of noise for each frame. Moreover, we derived a SE-specific average treatment effect to quantify the causal effect adequately. Experimental evidence demonstrates that CISE outperforms a non-causal mask-based SE approach in the studied settings and has better performance and efficiency than more complex SE models.
An Experimental Study on Private Aggregation of Teacher Ensemble Learning for End-to-End Speech Recognition
Oct 13, 2022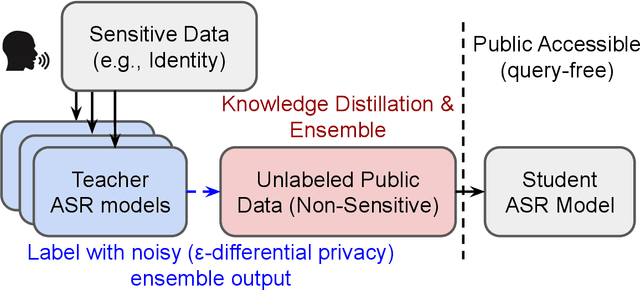
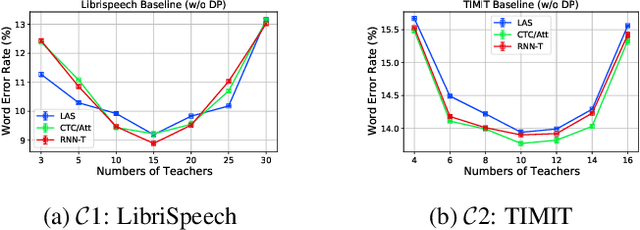
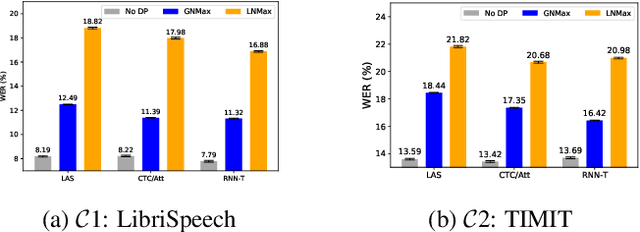
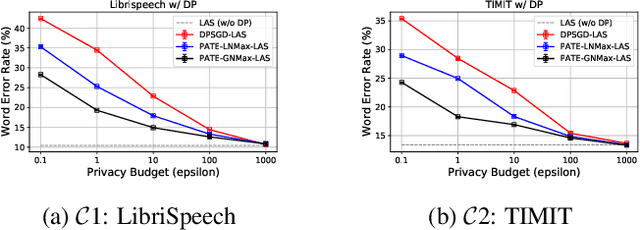
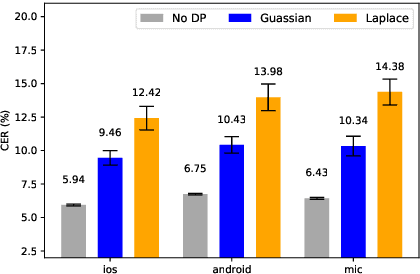
Differential privacy (DP) is one data protection avenue to safeguard user information used for training deep models by imposing noisy distortion on privacy data. Such a noise perturbation often results in a severe performance degradation in automatic speech recognition (ASR) in order to meet a privacy budget $\varepsilon$. Private aggregation of teacher ensemble (PATE) utilizes ensemble probabilities to improve ASR accuracy when dealing with the noise effects controlled by small values of $\varepsilon$. We extend PATE learning to work with dynamic patterns, namely speech utterances, and perform a first experimental demonstration that it prevents acoustic data leakage in ASR training. We evaluate three end-to-end deep models, including LAS, hybrid CTC/attention, and RNN transducer, on the open-source LibriSpeech and TIMIT corpora. PATE learning-enhanced ASR models outperform the benchmark DP-SGD mechanisms, especially under strict DP budgets, giving relative word error rate reductions between 26.2% and 27.5% for an RNN transducer model evaluated with LibriSpeech. We also introduce a DP-preserving ASR solution for pretraining on public speech corpora.
An Ensemble Teacher-Student Learning Approach with Poisson Sub-sampling to Differential Privacy Preserving Speech Recognition
Oct 12, 2022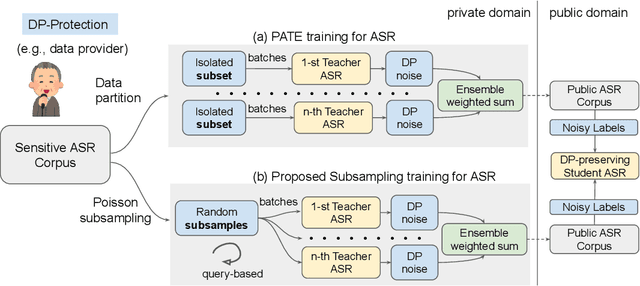


We propose an ensemble learning framework with Poisson sub-sampling to effectively train a collection of teacher models to issue some differential privacy (DP) guarantee for training data. Through boosting under DP, a student model derived from the training data suffers little model degradation from the models trained with no privacy protection. Our proposed solution leverages upon two mechanisms, namely: (i) a privacy budget amplification via Poisson sub-sampling to train a target prediction model that requires less noise to achieve a same level of privacy budget, and (ii) a combination of the sub-sampling technique and an ensemble teacher-student learning framework that introduces DP-preserving noise at the output of the teacher models and transfers DP-preserving properties via noisy labels. Privacy-preserving student models are then trained with the noisy labels to learn the knowledge with DP-protection from the teacher model ensemble. Experimental evidences on spoken command recognition and continuous speech recognition of Mandarin speech show that our proposed framework greatly outperforms existing DP-preserving algorithms in both speech processing tasks.
Hierarchical Residual Learning Based Vector Quantized Variational Autoencoder for Image Reconstruction and Generation
Aug 09, 2022

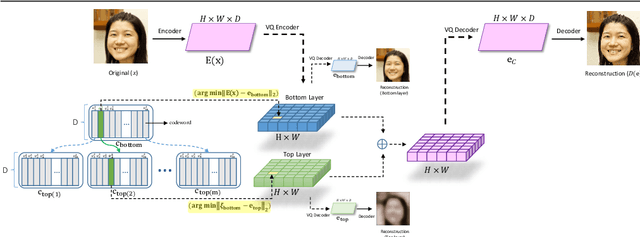
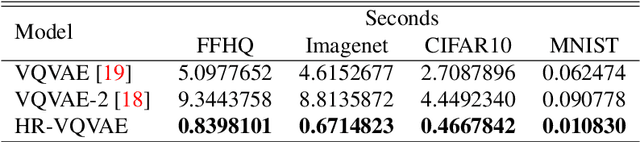
We propose a multi-layer variational autoencoder method, we call HR-VQVAE, that learns hierarchical discrete representations of the data. By utilizing a novel objective function, each layer in HR-VQVAE learns a discrete representation of the residual from previous layers through a vector quantized encoder. Furthermore, the representations at each layer are hierarchically linked to those at previous layers. We evaluate our method on the tasks of image reconstruction and generation. Experimental results demonstrate that the discrete representations learned by HR-VQVAE enable the decoder to reconstruct high-quality images with less distortion than the baseline methods, namely VQVAE and VQVAE-2. HR-VQVAE can also generate high-quality and diverse images that outperform state-of-the-art generative models, providing further verification of the efficiency of the learned representations. The hierarchical nature of HR-VQVAE i) reduces the decoding search time, making the method particularly suitable for high-load tasks and ii) allows to increase the codebook size without incurring the codebook collapse problem.
A study on joint modeling and data augmentation of multi-modalities for audio-visual scene classification
Mar 31, 2022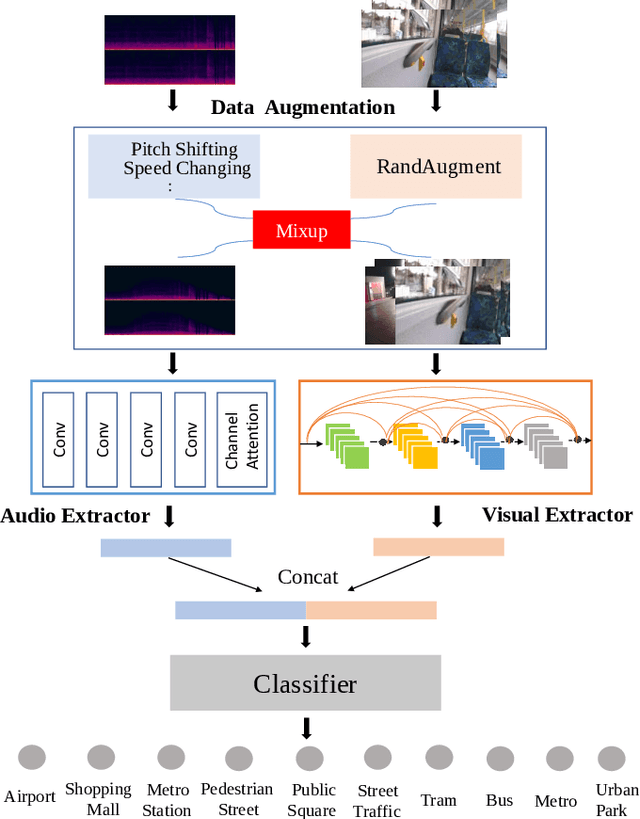
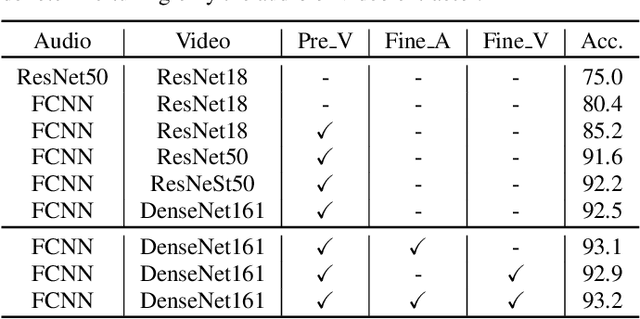
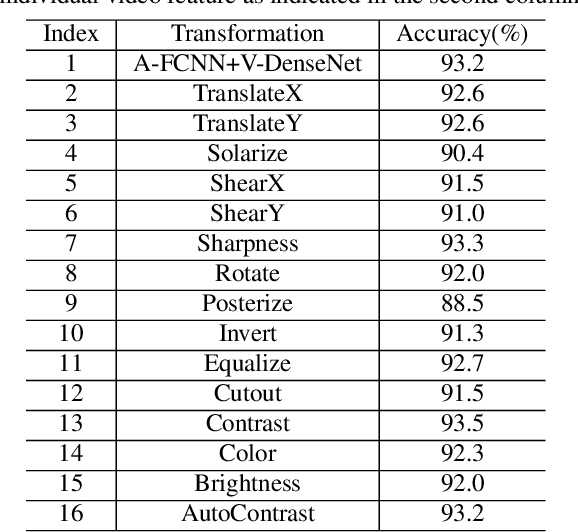
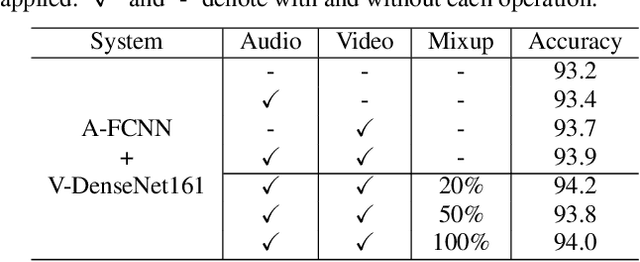
In this paper, we propose two techniques, namely joint modeling and data augmentation, to improve system performances for audio-visual scene classification (AVSC). We employ pre-trained networks trained only on image data sets to extract video embedding; whereas for audio embedding models, we decide to train them from scratch. We explore different neural network architectures for joint modeling to effectively combine the video and audio modalities. Moreover, data augmentation strategies are investigated to increase audio-visual training set size. For the video modality the effectiveness of several operations in RandAugment is verified. An audio-video joint mixup scheme is proposed to further improve AVSC performances. Evaluated on the development set of TAU Urban Audio Visual Scenes 2021, our final system can achieve the best accuracy of 94.2% among all single AVSC systems submitted to DCASE 2021 Task 1b.
A Variational Bayesian Approach to Learning Latent Variables for Acoustic Knowledge Transfer
Oct 16, 2021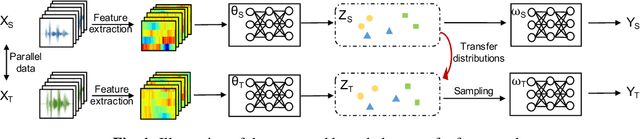
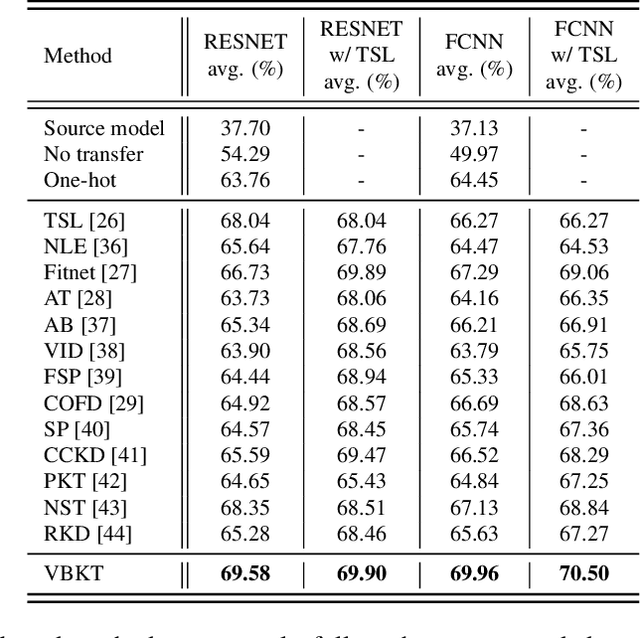
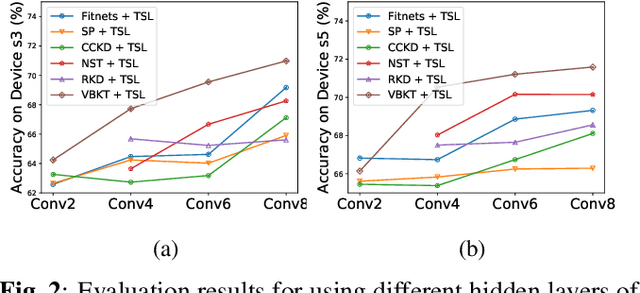
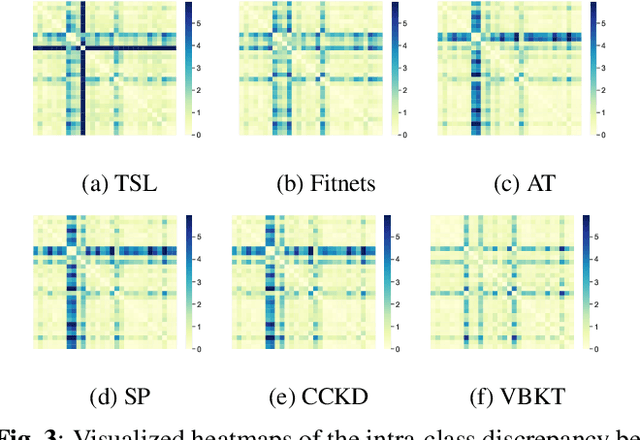
We propose a variational Bayesian (VB) approach to learning distributions of latent variables in deep neural network (DNN) models for cross-domain knowledge transfer, to address acoustic mismatches between training and testing conditions. Instead of carrying out point estimation in conventional maximum a posteriori estimation with a risk of having a curse of dimensionality in estimating a huge number of model parameters, we focus our attention on estimating a manageable number of latent variables of DNNs via a VB inference framework. To accomplish model transfer, knowledge learnt from a source domain is encoded in prior distributions of latent variables and optimally combined, in a Bayesian sense, with a small set of adaptation data from a target domain to approximate the corresponding posterior distributions. Experimental results on device adaptation in acoustic scene classification show that our proposed VB approach can obtain good improvements on target devices, and consistently outperforms 13 state-of-the-art knowledge transfer algorithms.
A Study of Low-Resource Speech Commands Recognition based on Adversarial Reprogramming
Oct 08, 2021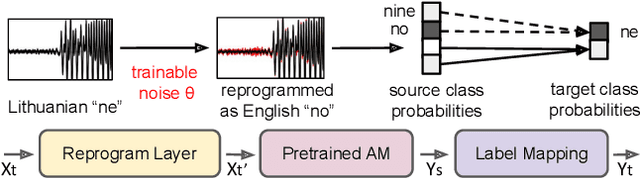
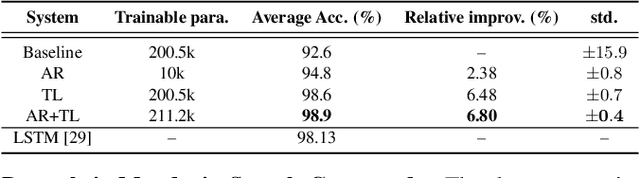
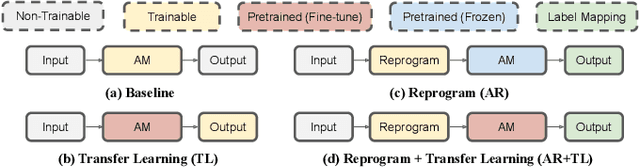
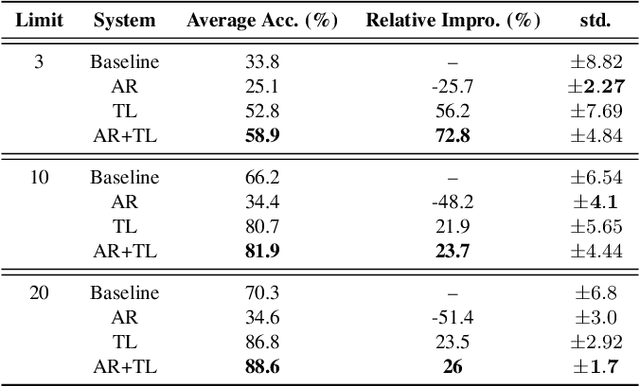
In this study, we propose a novel adversarial reprogramming (AR) approach for low-resource spoken command recognition (SCR), and build an AR-SCR system. The AR procedure aims to modify the acoustic signals (from the target domain) to repurpose a pretrained SCR model (from the source domain). To solve the label mismatches between source and target domains, and further improve the stability of AR, we propose a novel similarity-based label mapping technique to align classes. In addition, the transfer learning (TL) technique is combined with the original AR process to improve the model adaptation capability. We evaluate the proposed AR-SCR system on three low-resource SCR datasets, including Arabic, Lithuanian, and dysarthric Mandarin speech. Experimental results show that with a pretrained AM trained on a large-scale English dataset, the proposed AR-SCR system outperforms the current state-of-the-art results on Arabic and Lithuanian speech commands datasets, with only a limited amount of training data.
Exploring Retraining-Free Speech Recognition for Intra-sentential Code-Switching
Aug 27, 2021
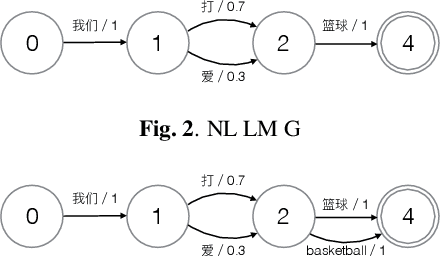
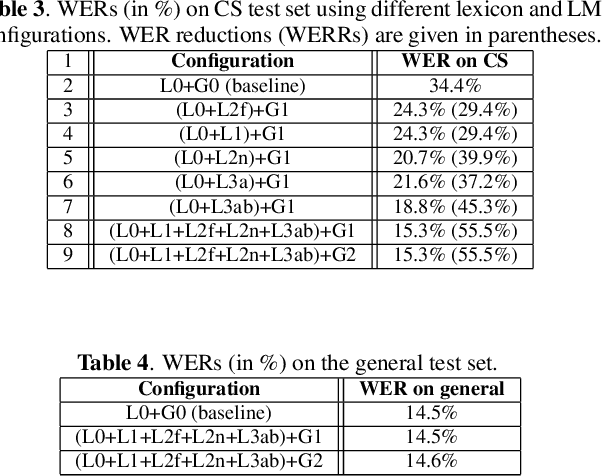
In this paper, we present our initial efforts for building a code-switching (CS) speech recognition system leveraging existing acoustic models (AMs) and language models (LMs), i.e., no training required, and specifically targeting intra-sentential switching. To achieve such an ambitious goal, new mechanisms for foreign pronunciation generation and language model (LM) enrichment have been devised. Specifically, we have designed an automatic approach to obtain high quality pronunciation of foreign language (FL) words in the native language (NL) phoneme set using existing acoustic phone decoders and an LSTM-based grapheme-to-phoneme (G2P) model. Improved accented pronunciations have thus been obtained by learning foreign pronunciations directly from data. Furthermore, a code-switching LM was deployed by converting the original NL LM into a CS LM using translated word pairs and borrowing statistics for the NL LM. Experimental evidence clearly demonstrates that our approach better deals with accented foreign pronunciations than techniques based on human labeling. Moreover, our best system achieves a 55.5% relative word error rate reduction from 34.4%, obtained with a conventional monolingual ASR system, to 15.3% on an intra-sentential CS task without harming the monolingual recognition accuracy.