 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflective Decoding Network for Image Captioning
Aug 30, 2019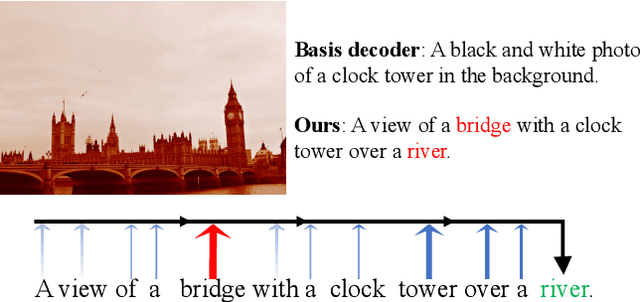

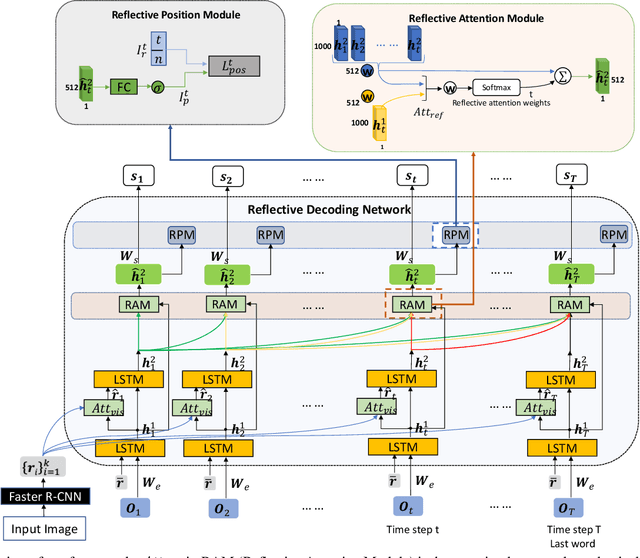
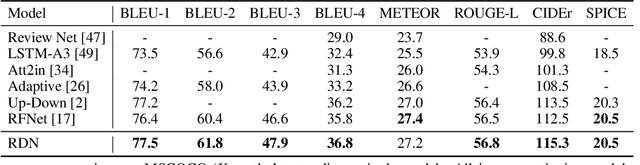
State-of-the-art image captioning methods mostly focus on improving visual features, less attention has been paid to utilizing the inherent properties of language to boost captioning performance. In this paper, we show that vocabulary coherence between words and syntactic paradigm of sentences are also important to generate high-quality image caption. Following the conventional encoder-decoder framework, we propose the Reflective Decoding Network (RDN) for image captioning, which enhances both the long-sequence dependency and position perception of words in a caption decoder. Our model learns to collaboratively attend on both visual and textual features and meanwhile perceive each word's relative position in the sentence to maximize the information delivered in the generated caption. We evaluate the effectiveness of our RDN on the COCO image captioning datasets and achieve superior performance over the previous methods. Further experiments reveal that our approach is particularly advantageous for hard cases with complex scenes to describe by captions.
Region Refinement Network for Salient Object Detection
Jun 27, 2019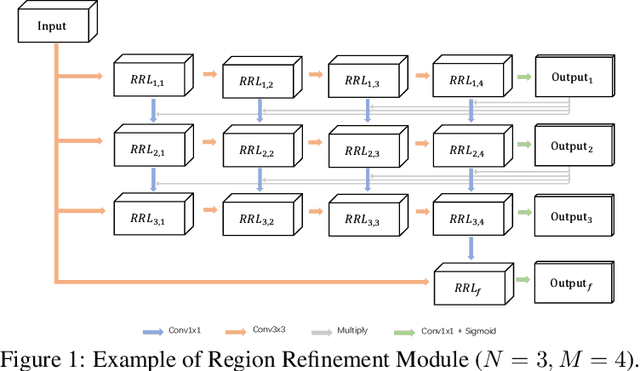
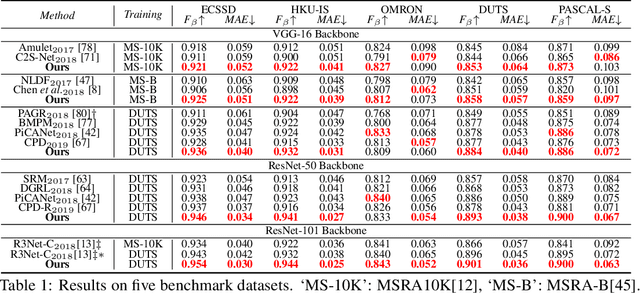


Albeit intensively studied, false prediction and unclear boundaries are still major issues of salient object detection. In this paper, we propose a Region Refinement Network (RRN), which recurrently filters redundant information and explicitly models boundary information for saliency detection. Different from existing refinement methods, we propose a Region Refinement Module (RRM) that optimizes salient region prediction by incorporating supervised attention masks in the intermediate refinement stages. The module only brings a minor increase in model size and yet significantly reduces false predictions from the background. To further refine boundary areas, we propose a Boundary Refinement Loss (BRL) that adds extra supervision for better distinguishing foreground from background. BRL is parameter free and easy to train. We further observe that BRL helps retain the integrity in prediction by refining the boundary. Extensive experiments on saliency detection datasets show that our refinement module and loss bring significant improvement to the baseline and can be easily applied to different frameworks. We also demonstrate that our proposed model generalizes well to portrait segmentation and shadow detection tasks.
2D Attentional Irregular Scene Text Recognizer
Jun 13, 2019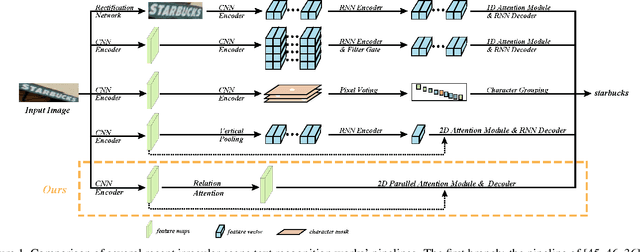
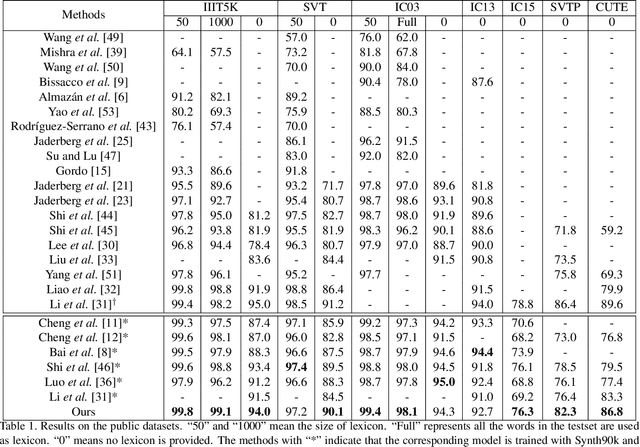
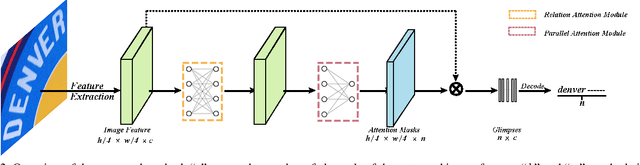
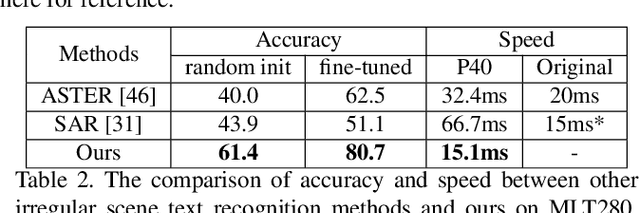
Irregular scene text, which has complex layout in 2D space, is challenging to most previous scene text recognizers. Recently, some irregular scene text recognizers either rectify the irregular text to regular text image with approximate 1D layout or transform the 2D image feature map to 1D feature sequence. Though these methods have achieved good performance, the robustness and accuracy are still limited due to the loss of spatial information in the process of 2D to 1D transformation. Different from all of previous, we in this paper propose a framework which transforms the irregular text with 2D layout to character sequence directly via 2D attentional scheme. We utilize a relation attention module to capture the dependencies of feature maps and a parallel attention module to decode all characters in parallel, which make our method more effective and efficient. Extensive experiments on several public benchmarks as well as our collected multi-line text dataset show that our approach is effective to recognize regular and irregular scene text and outperforms previous methods both in accuracy and speed.
Facelet-Bank for Fast Portrait Manipulation
Mar 30, 2018
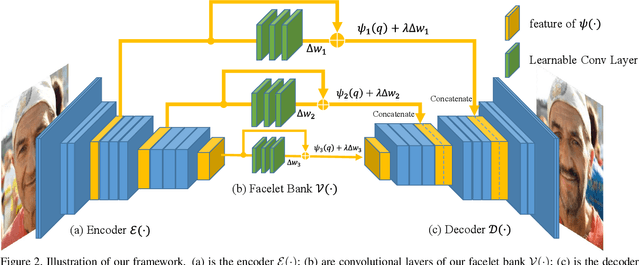


Digital face manipulation has become a popular and fascinating way to touch images with the prevalence of smartphones and social networks. With a wide variety of user preferences, facial expressions, and accessories, a general and flexible model is necessary to accommodate different types of facial editing. In this paper, we propose a model to achieve this goal based on an end-to-end convolutional neural network that supports fast inference, edit-effect control, and quick partial-model update. In addition, this model learns from unpaired image sets with different attributes. Experimental results show that our framework can handle a wide range of expressions, accessories, and makeup effects. It produces high-resolution and high-quality results in fast speed.
Situation Recognition with Graph Neural Networks
Aug 14, 2017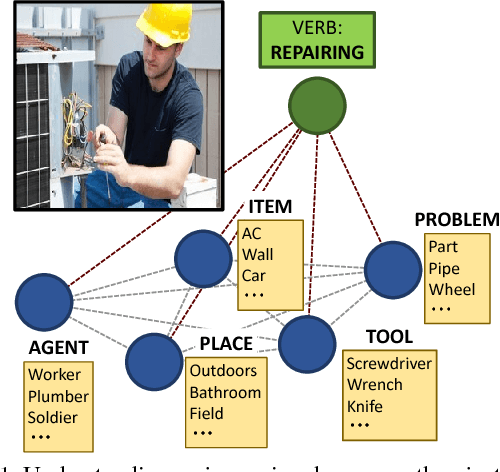
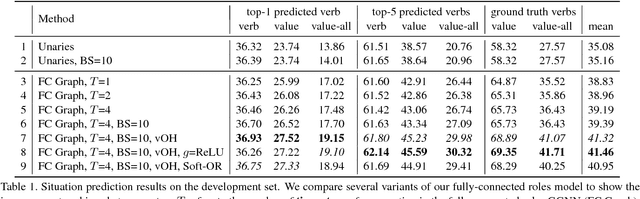

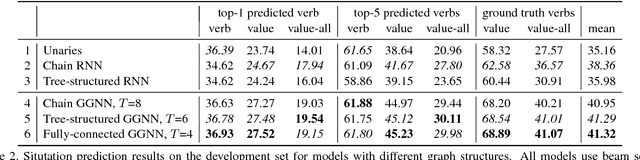
We address the problem of recognizing situations in images. Given an image, the task is to predict the most salient verb (action), and fill its semantic roles such as who is performing the action, what is the source and target of the action, etc. Different verbs have different roles (e.g. attacking has weapon), and each role can take on many possible values (nouns). We propose a model based on Graph Neural Networks that allows us to efficiently capture joint dependencies between roles using neural networks defined on a graph. Experiments with different graph connectivities show that our approach that propagates information between roles significantly outperforms existing work, as well as multiple baselines. We obtain roughly 3-5% improvement over previous work in predicting the full situation. We also provide a thorough qualitative analysis of our model and influence of different roles in the verbs.