 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocation Is All You Need: Continuous Spatiotemporal Neural Representations of Earth Observation Data
Apr 09, 2026In this work, we present LIANet (Location Is All You Need Network), a coordinate-based neural representation that models multi-temporal spaceborne Earth observation (EO) data for a given region of interest as a continuous spatiotemporal neural field. Given only spatial and temporal coordinates, LIANet reconstructs the corresponding satellite imagery. Once pretrained, this neural representation can be adapted to various EO downstream tasks, such as semantic segmentation or pixel-wise regression, importantly, without requiring access to the original satellite data. LIANet intends to serve as a user-friendly alternative to Geospatial Foundation Models (GFMs) by eliminating the overhead of data access and preprocessing for end-users and enabling fine-tuning solely based on labels. We demonstrate the pretraining of LIANet across target areas of varying sizes and show that fine-tuning it for downstream tasks achieves competitive performance compared to training from scratch or using established GFMs. The source code and datasets are publicly available at https://github.com/mojganmadadi/LIANet/tree/v1.0.1.
SARFormer -- An Acquisition Parameter Aware Vision Transformer for Synthetic Aperture Radar Data
Apr 11, 2025This manuscript introduces SARFormer, a modified Vision Transformer (ViT) architecture designed for processing one or multiple synthetic aperture radar (SAR) images. Given the complex image geometry of SAR data, we propose an acquisition parameter encoding module that significantly guides the learning process, especially in the case of multiple images, leading to improved performance on downstream tasks. We further explore self-supervised pre-training, conduct experiments with limited labeled data, and benchmark our contribution and adaptations thoroughly in ablation experiments against a baseline, where the model is tested on tasks such as height reconstruction and segmentation. Our approach achieves up to 17% improvement in terms of RMSE over baseline models
SenPa-MAE: Sensor Parameter Aware Masked Autoencoder for Multi-Satellite Self-Supervised Pretraining
Aug 20, 2024This paper introduces SenPa-MAE, a transformer architecture that encodes the sensor parameters of an observed multispectral signal into the image embeddings. SenPa-MAE can be pre-trained on imagery of different satellites with non-matching spectral or geometrical sensor characteristics. To incorporate sensor parameters, we propose a versatile sensor parameter encoding module as well as a data augmentation strategy for the diversification of the pre-training dataset. This enables the model to effectively differentiate between various sensors and gain an understanding of sensor parameters and the correlation to the observed signal. Given the rising number of Earth observation satellite missions and the diversity in their sensor specifications, our approach paves the way towards a sensor-independent Earth observation foundation model. This opens up possibilities such as cross-sensor training and sensor-independent inference.
Global OpenBuildingMap -- Unveiling the Mystery of Global Buildings
Apr 22, 2024Understanding how buildings are distributed globally is crucial to revealing the human footprint on our home planet. This built environment affects local climate, land surface albedo, resource distribution, and many other key factors that influence well-being and human health. Despite this, quantitative and comprehensive data on the distribution and properties of buildings worldwide is lacking. To this end, by using a big data analytics approach and nearly 800,000 satellite images, we generated the highest resolution and highest accuracy building map ever created: the Global OpenBuildingMap (Global OBM). A joint analysis of building maps and solar potentials indicates that rooftop solar energy can supply the global energy consumption need at a reasonable cost. Specifically, if solar panels were placed on the roofs of all buildings, they could supply 1.1-3.3 times -- depending on the efficiency of the solar device -- the global energy consumption in 2020, which is the year with the highest consumption on record. We also identified a clear geospatial correlation between building areas and key socioeconomic variables, which indicates our global building map can serve as an important input to modeling global socioeconomic needs and drivers.
Data-Centric Machine Learning for Geospatial Remote Sensing Data
Dec 08, 2023



Recent developments and research in modern machine learning have led to substantial improvements in the geospatial field. Although numerous deep learning models have been proposed, the majority of them have been developed on benchmark datasets that lack strong real-world relevance. Furthermore, the performance of many methods has already saturated on these datasets. We argue that shifting the focus towards a complementary data-centric perspective is necessary to achieve further improvements in accuracy, generalization ability, and real impact in end-user applications. This work presents a definition and precise categorization of automated data-centric learning approaches for geospatial data. It highlights the complementary role of data-centric learning with respect to model-centric in the larger machine learning deployment cycle. We review papers across the entire geospatial field and categorize them into different groups. A set of representative experiments shows concrete implementation examples. These examples provide concrete steps to act on geospatial data with data-centric machine learning approaches.
Using Machine Learning to predict extreme events in the Hénon map
Feb 20, 2020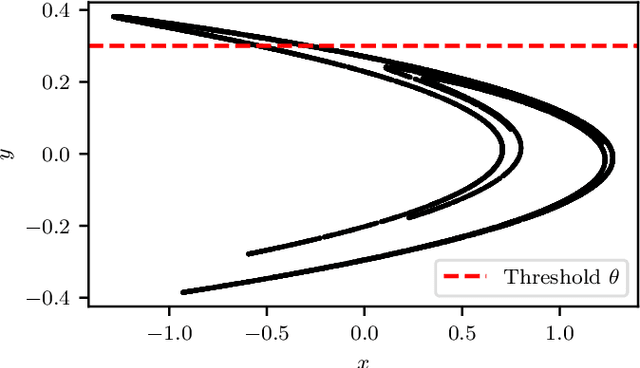
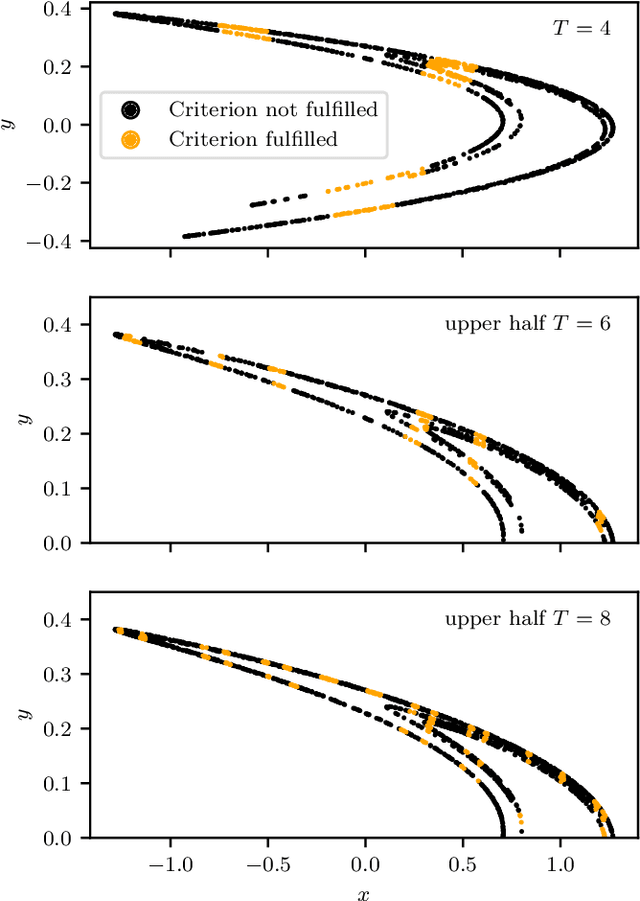
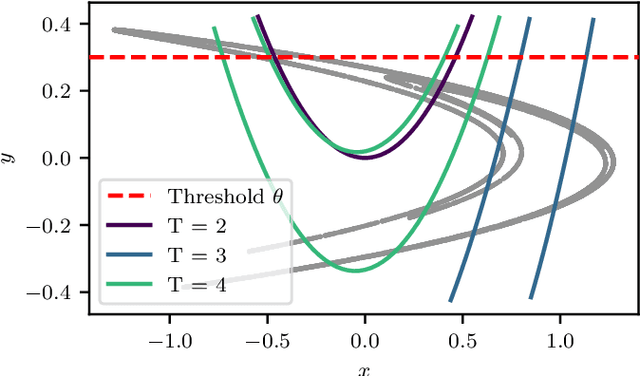
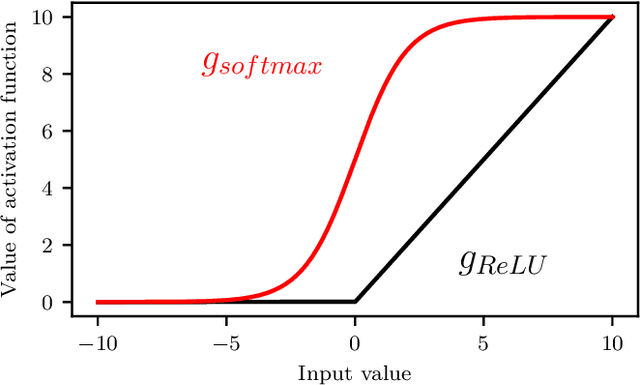
Machine Learning (ML) inspired algorithms provide a flexible set of tools for analyzing and forecasting chaotic dynamical systems. We here analyze the performance of one algorithm for the prediction of extreme events in the two-dimensional H\'enon map at the classical parameters. The task is to determine whether a trajectory will exceed a threshold after a set number of time steps into the future. This task has a geometric interpretation within the dynamics of the H\'enon map, which we use to gauge the performance of the neural networks that are used in this work. We analyze the dependence of the success rate of the ML models on the prediction time $T$ , the number of training samples $N_T$ and the size of the network $N_p$. We observe that in order to maintain a certain accuracy, $N_T \propto exp(2 h T)$ and $N_p \propto exp(hT)$, where $h$ is the topological entropy. Similar relations between the intrinsic chaotic properties of the dynamics and ML parameters might be observable in other systems as well.
* 9 pages, 12 figures
Weakly Supervised Semantic Segmentation of Satellite Images for Land Cover Mapping -- Challenges and Opportunities
Feb 19, 2020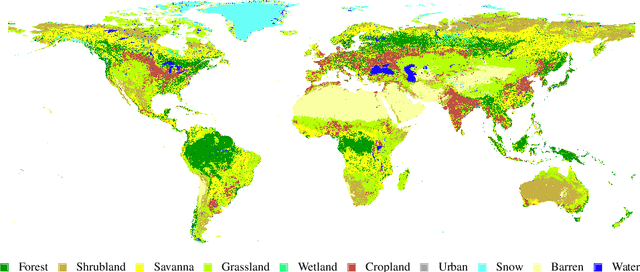
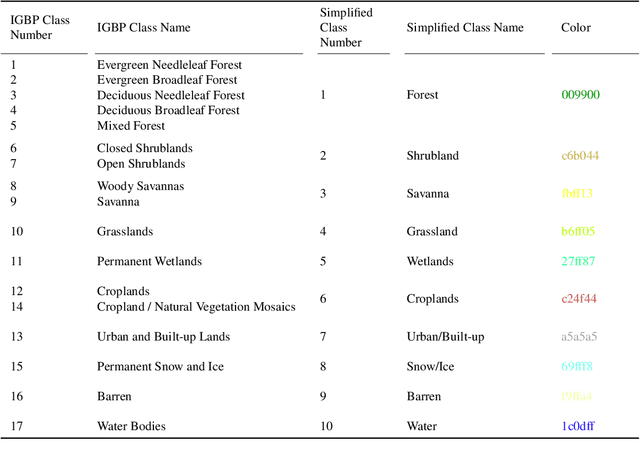
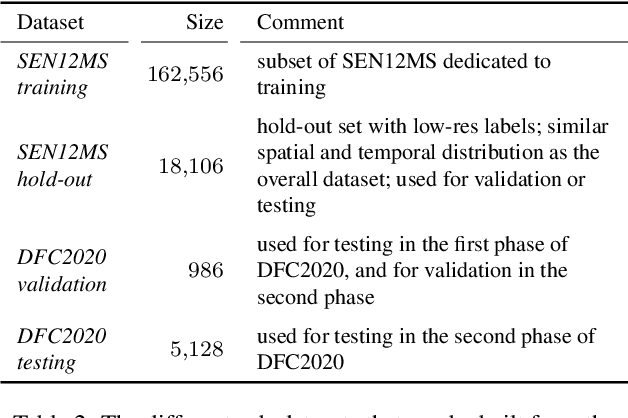
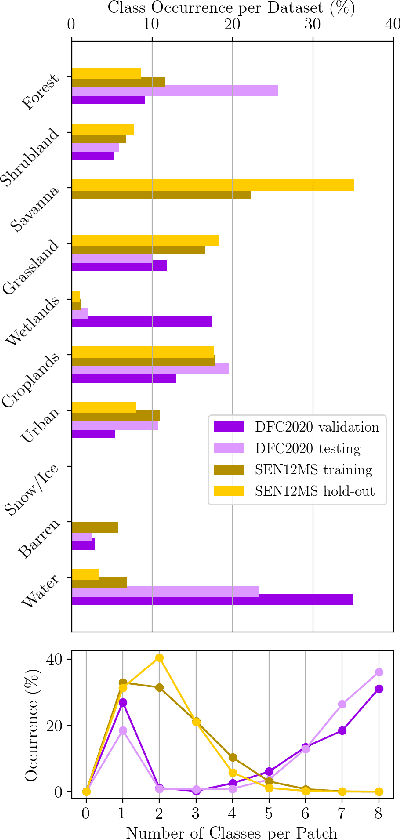
Fully automatic large-scale land cover mapping belongs to the core challenges addressed by the remote sensing community. Usually, the basis of this task is formed by (supervised) machine learning models. However, in spite of recent growth in the availability of satellite observations, accurate training data remains comparably scarce. On the other hand, numerous global land cover products exist and can be accessed often free-of-charge. Unfortunately, these maps are typically of a much lower resolution than modern day satellite imagery. Besides, they always come with a significant amount of noise, as they cannot be considered ground truth, but are products of previous (semi-)automatic prediction tasks. Therefore, this paper seeks to make a case for the application of weakly supervised learning strategies to get the most out of available data sources and achieve progress in high-resolution large-scale land cover mapping. Challenges and opportunities are discussed based on the SEN12MS dataset, for which also some baseline results are shown. These baselines indicate that there is still a lot of potential for dedicated approaches designed to deal with remote sensing-specific forms of weak supervision.