 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidance and Teaching Network for Video Salient Object Detection
Jun 06, 2021
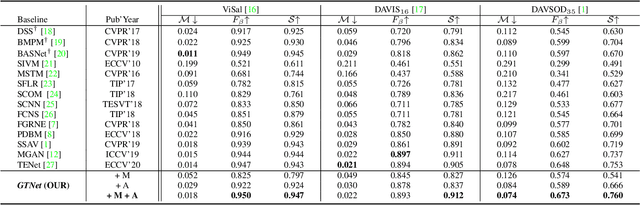
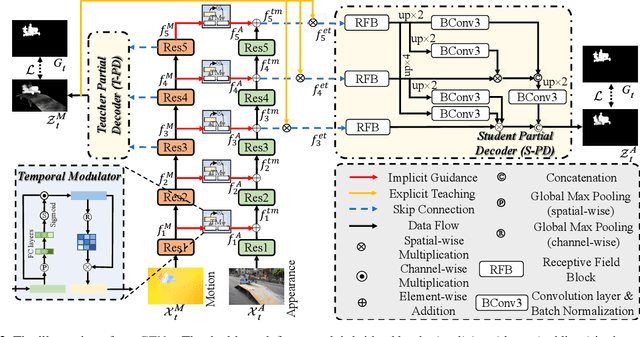
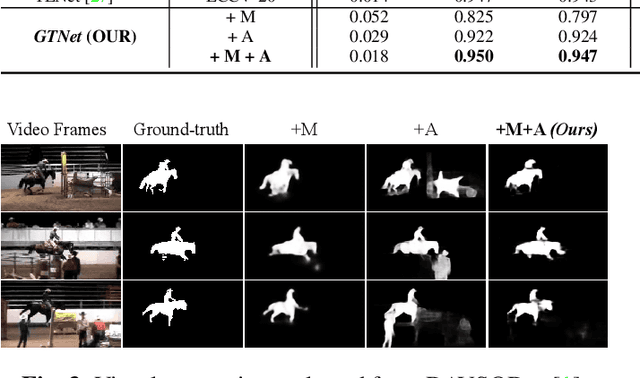
Owing to the difficulties of mining spatial-temporal cues, the existing approaches for video salient object detection (VSOD) are limited in understanding complex and noisy scenarios, and often fail in inferring prominent objects. To alleviate such shortcomings, we propose a simple yet efficient architecture, termed Guidance and Teaching Network (GTNet), to independently distil effective spatial and temporal cues with implicit guidance and explicit teaching at feature- and decision-level, respectively. To be specific, we (a) introduce a temporal modulator to implicitly bridge features from motion into the appearance branch, which is capable of fusing cross-modal features collaboratively, and (b) utilise motion-guided mask to propagate the explicit cues during the feature aggregation. This novel learning strategy achieves satisfactory results via decoupling the complex spatial-temporal cues and mapping informative cues across different modalities. Extensive experiments on three challenging benchmarks show that the proposed method can run at ~28 fps on a single TITAN Xp GPU and perform competitively against 14 cutting-edge baselines.
Deep Bandits Show-Off: Simple and Efficient Exploration with Deep Networks
May 10, 2021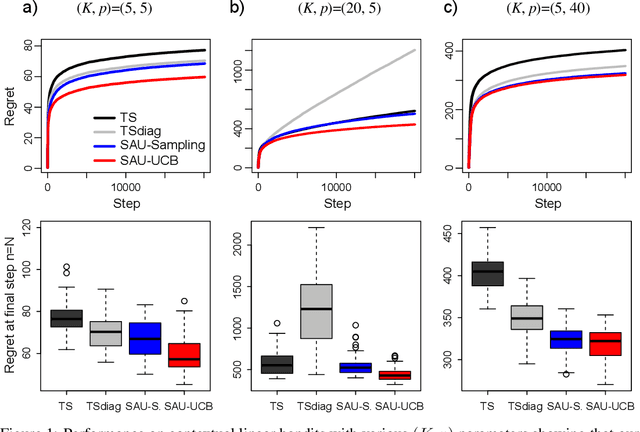
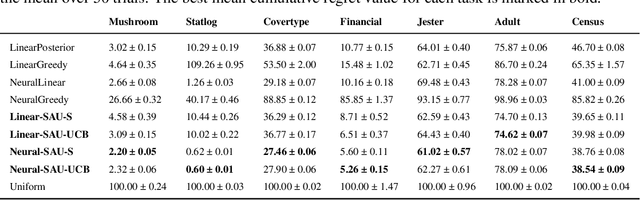
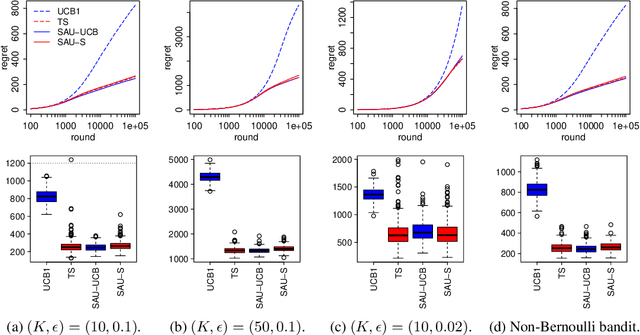
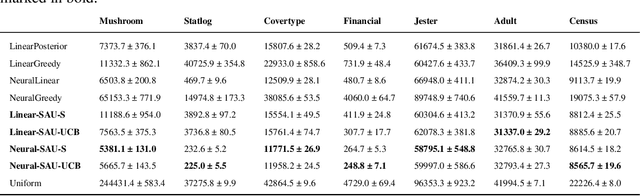
Designing efficient exploration is central to Reinforcement Learning due to the fundamental problem posed by the exploration-exploitation dilemma. Bayesian exploration strategies like Thompson Sampling resolve this trade-off in a principled way by modeling and updating the distribution of the parameters of the the action-value function, the outcome model of the environment. However, this technique becomes infeasible for complex environments due to the difficulty of representing and updating probability distributions over parameters of outcome models of corresponding complexity. Moreover, the approximation techniques introduced to mitigate this issue typically result in poor exploration-exploitation trade-offs, as observed in the case of deep neural network models with approximate posterior methods that have been shown to underperform in the deep bandit scenario. In this paper we introduce Sample Average Uncertainty (SAU), a simple and efficient uncertainty measure for contextual bandits. While Bayesian approaches like Thompson Sampling estimate outcomes uncertainty indirectly by first quantifying the variability over the parameters of the outcome model, SAU is a frequentist approach that directly estimates the uncertainty of the outcomes based on the value predictions. Importantly, we show theoretically that the uncertainty measure estimated by SAU asymptotically matches the uncertainty provided by Thompson Sampling, as well as its regret bounds. Because of its simplicity SAU can be seamlessly applied to deep contextual bandits as a very scalable drop-in replacement for epsilon-greedy exploration. Finally, we empirically confirm our theory by showing that SAU-based exploration outperforms current state-of-the-art deep Bayesian bandit methods on several real-world datasets at modest computation cost.
A Unified Transferable Model for ML-Enhanced DBMS
May 06, 2021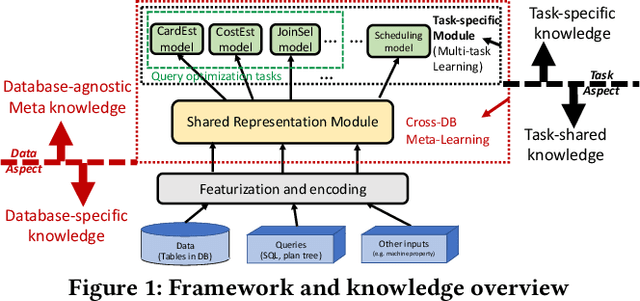
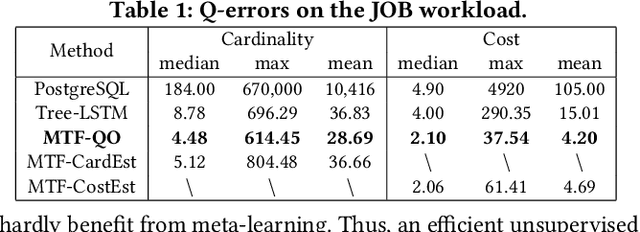
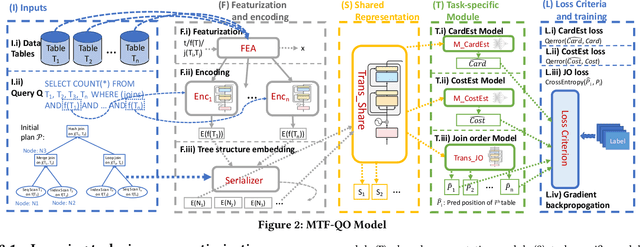
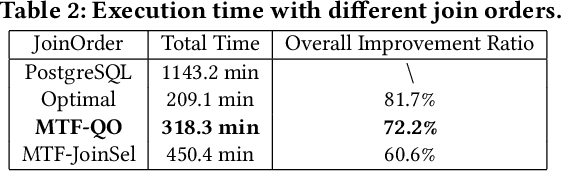
Recently, the database management system (DBMS) community has witnessed the power of machine learning (ML) solutions for DBMS tasks. Despite their promising performance, these existing solutions can hardly be considered satisfactory. First, these ML-based methods in DBMS are not effective enough because they are optimized on each specific task, and cannot explore or understand the intrinsic connections between tasks. Second, the training process has serious limitations that hinder their practicality, because they need to retrain the entire model from scratch for a new DB. Moreover, for each retraining, they require an excessive amount of training data, which is very expensive to acquire and unavailable for a new DB. We propose to explore the transferabilities of the ML methods both across tasks and across DBs to tackle these fundamental drawbacks. In this paper, we propose a unified model MTMLF that uses a multi-task training procedure to capture the transferable knowledge across tasks and a pretrain finetune procedure to distill the transferable meta knowledge across DBs. We believe this paradigm is more suitable for cloud DB service, and has the potential to revolutionize the way how ML is used in DBMS. Furthermore, to demonstrate the predicting power and viability of MTMLF, we provide a concrete and very promising case study on query optimization tasks. Last but not least, we discuss several concrete research opportunities along this line of work.
BayesCard: Revitilizing Bayesian Frameworks for Cardinality Estimation
Feb 02, 2021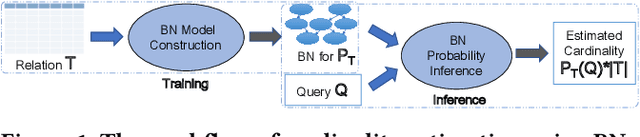
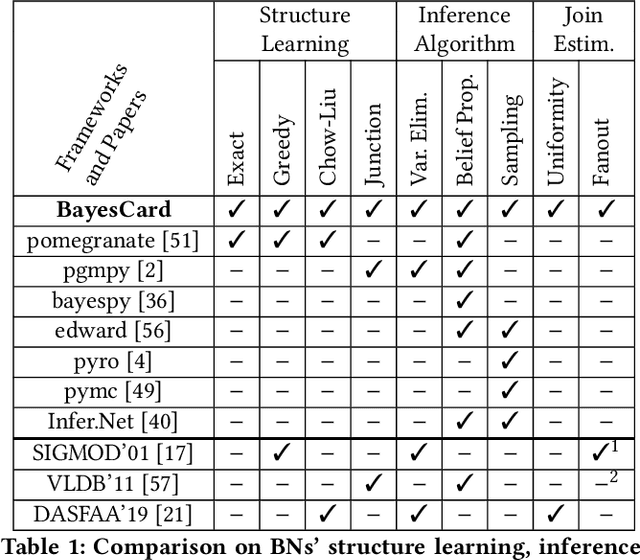
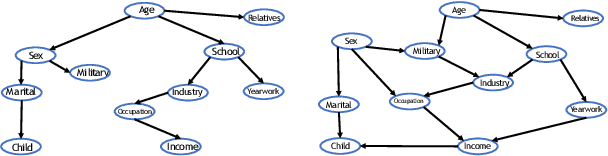
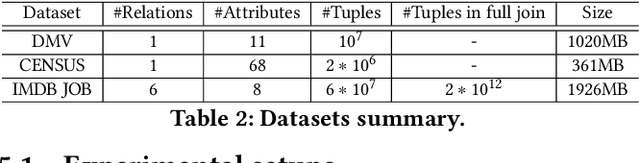
Cardinality estimation (CardEst) is an essential component in query optimizers and a fundamental problem in DBMS. A desired CardEst method should attain good algorithm performance, be stable to varied data settings, and be friendly to system deployment. However, no existing CardEst method can fulfill the three criteria at the same time. Traditional methods often have significant algorithm drawbacks such as large estimation errors. Recently proposed deep learning based methods largely improve the estimation accuracy but their performance can be greatly affected by data and often difficult for system deployment. In this paper, we revitalize the Bayesian networks (BN) for CardEst by incorporating the techniques of probabilistic programming languages. We present BayesCard, the first framework that inherits the advantages of BNs, i.e., high estimation accuracy and interpretability, while overcomes their drawbacks, i.e. low structure learning and inference efficiency. This makes BayesCard a perfect candidate for commercial DBMS deployment. Our experimental results on several single-table and multi-table benchmarks indicate BayesCard's superiority over existing state-of-the-art CardEst methods: BayesCard achieves comparable or better accuracy, 1-2 orders of magnitude faster inference time, 1-3 orders faster training time, 1-3 orders smaller model size, and 1-2 orders faster updates. Meanwhile, BayesCard keeps stable performance when varying data with different settings. We also deploy BayesCard into PostgreSQL. On the IMDB benchmark workload, it improves the end-to-end query time by 13.3%, which is very close to the optimal result of 14.2% using an oracle of true cardinality.
Efficient and Scalable Structure Learning for Bayesian Networks: Algorithms and Applications
Dec 07, 2020


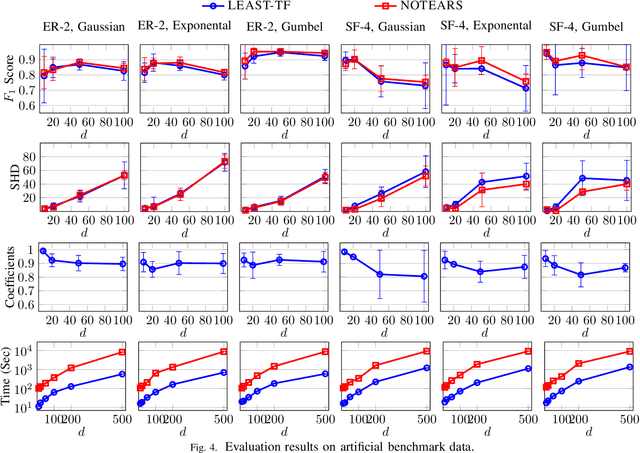
Structure Learning for Bayesian network (BN) is an important problem with extensive research. It plays central roles in a wide variety of applications in Alibaba Group. However, existing structure learning algorithms suffer from considerable limitations in real world applications due to their low efficiency and poor scalability. To resolve this, we propose a new structure learning algorithm LEAST, which comprehensively fulfills our business requirements as it attains high accuracy, efficiency and scalability at the same time. The core idea of LEAST is to formulate the structure learning into a continuous constrained optimization problem, with a novel differentiable constraint function measuring the acyclicity of the resulting graph. Unlike with existing work, our constraint function is built on the spectral radius of the graph and could be evaluated in near linear time w.r.t. the graph node size. Based on it, LEAST can be efficiently implemented with low storage overhead. According to our benchmark evaluation, LEAST runs 1 to 2 orders of magnitude faster than state of the art method with comparable accuracy, and it is able to scale on BNs with up to hundreds of thousands of variables. In our production environment, LEAST is deployed and serves for more than 20 applications with thousands of executions per day. We describe a concrete scenario in a ticket booking service in Alibaba, where LEAST is applied to build a near real-time automatic anomaly detection and root error cause analysis system. We also show that LEAST unlocks the possibility of applying BN structure learning in new areas, such as large-scale gene expression data analysis and explainable recommendation system.
Self-correcting Q-Learning
Dec 02, 2020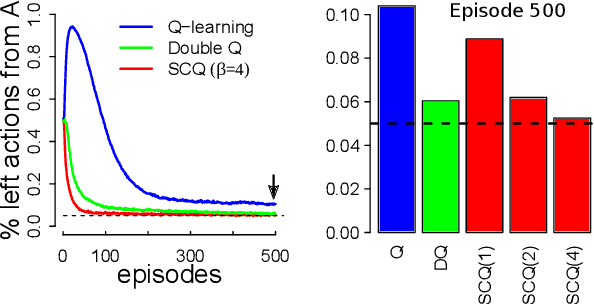
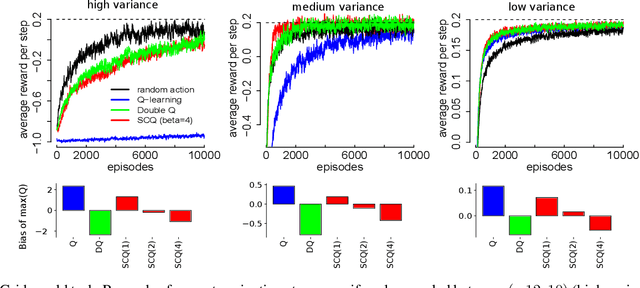
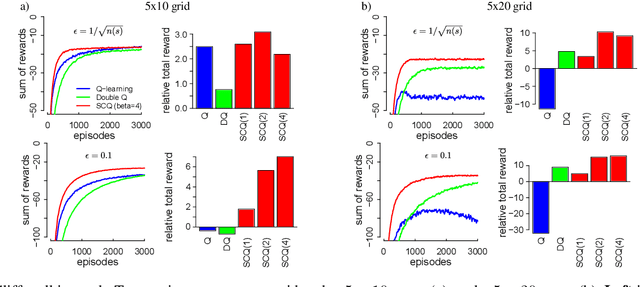
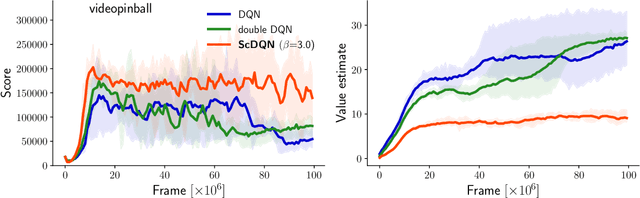
The Q-learning algorithm is known to be affected by the maximization bias, i.e. the systematic overestimation of action values, an important issue that has recently received renewed attention. Double Q-learning has been proposed as an efficient algorithm to mitigate this bias. However, this comes at the price of an underestimation of action values, in addition to increased memory requirements and a slower convergence. In this paper, we introduce a new way to address the maximization bias in the form of a "self-correcting algorithm" for approximating the maximum of an expected value. Our method balances the overestimation of the single estimator used in conventional Q-learning and the underestimation of the double estimator used in Double Q-learning. Applying this strategy to Q-learning results in Self-correcting Q-learning. We show theoretically that this new algorithm enjoys the same convergence guarantees as Q-learning while being more accurate. Empirically, it performs better than Double Q-learning in domains with rewards of high variance, and it even attains faster convergence than Q-learning in domains with rewards of zero or low variance. These advantages transfer to a Deep Q Network implementation that we call Self-correcting DQN and which outperforms regular DQN and Double DQN on several tasks in the Atari 2600 domain.
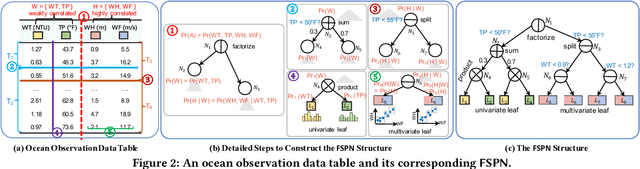
FSPN: A New Class of Probabilistic Graphical Model
Nov 20, 2020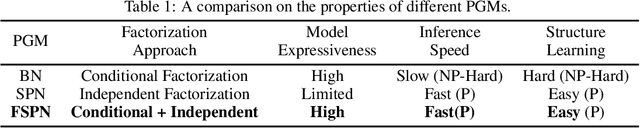
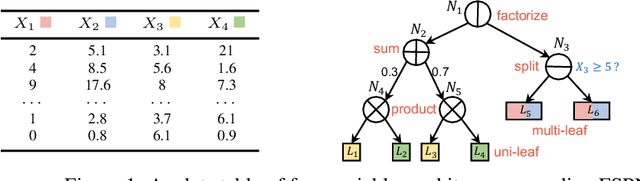
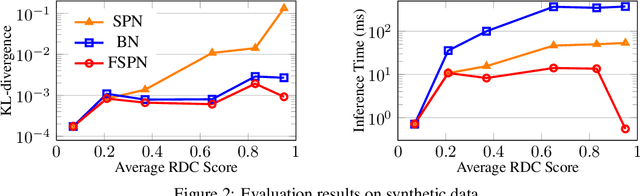
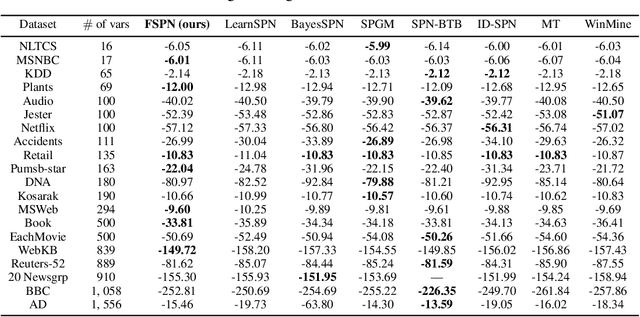
We introduce factorize sum split product networks (FSPNs), a new class of probabilistic graphical models (PGMs). FSPNs are designed to overcome the drawbacks of existing PGMs in terms of estimation accuracy and inference efficiency. Specifically, Bayesian networks (BNs) have low inference speed and performance of tree structured sum product networks(SPNs) significantly degrades in presence of highly correlated variables. FSPNs absorb their advantages by adaptively modeling the joint distribution of variables according to their dependence degree, so that one can simultaneously attain the two desirable goals: high estimation accuracy and fast inference speed. We present efficient probability inference and structure learning algorithms for FSPNs, along with a theoretical analysis and extensive evaluation evidence. Our experimental results on synthetic and benchmark datasets indicate the superiority of FSPN over other PGMs.
FLAT: Fast, Lightweight and Accurate Method for Cardinality Estimation
Nov 18, 2020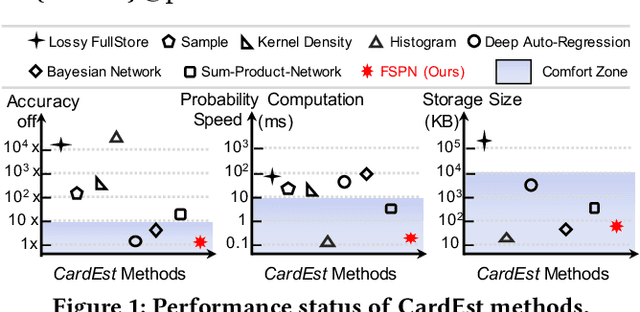
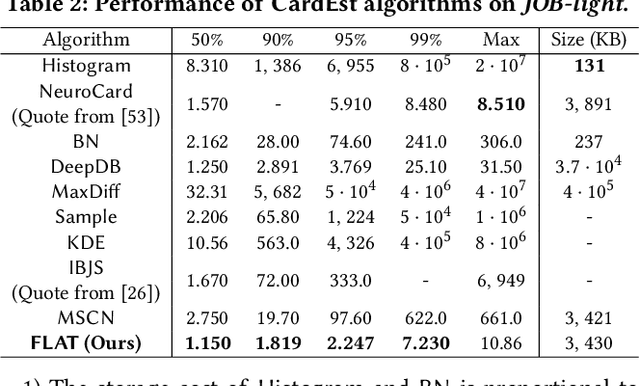

Query optimizers rely on accurate cardinality estimation (CardEst) to produce good execution plans. The core problem of CardEst is how to model the rich joint distribution of attributes in an accurate and compact manner. Despite decades of research, existing methods either over simplify the models only using independent factorization which leads to inaccurate estimates and sub optimal query plans, or over-complicate them by lossless conditional factorization without any independent assumption which results in slow probability computation. In this paper, we propose FLAT, a CardEst method that is simultaneously fast in probability computation, lightweight in model size and accurate in estimation quality. The key idea of FLAT is a novel unsupervised graphical model, called FSPN. It utilizes both independent and conditional factorization to adaptively model different levels of attributes correlations, and thus subsumes all existing CardEst models and dovetails their advantages. FLAT supports efficient online probability computation in near liner time on the underlying FSPN model, and provides effective offline model construction. It can estimate cardinality for both single table queries and multi-table join queries. Extensive experimental study demonstrates the superiority of FLAT over existing CardEst methods on well-known benchmarks: FLAT achieves 1 to 5 orders of magnitude better accuracy, 1 to 3 orders of magnitude faster probability computation speed (around 0.2ms) and 1 to 2 orders of magnitude lower storage cost (only tens of KB).
Penalized matrix decomposition for denoising, compression, and improved demixing of functional imaging data
Jul 17, 2018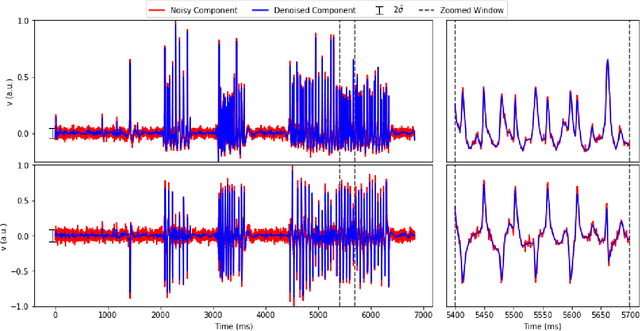
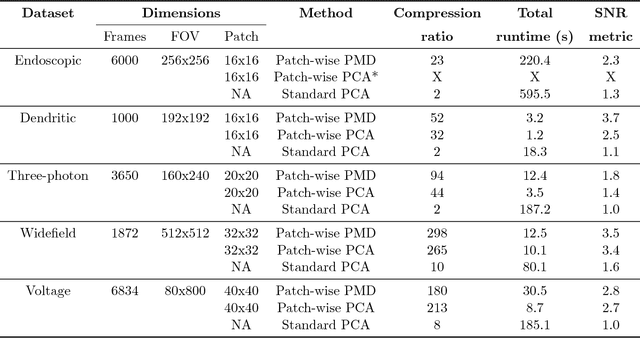

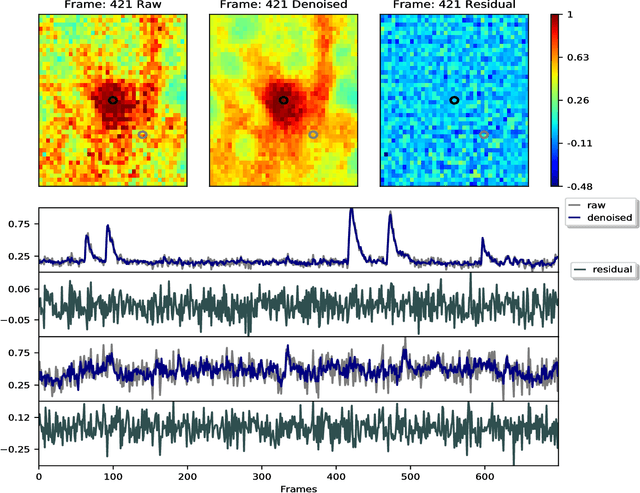
Calcium imaging has revolutionized systems neuroscience, providing the ability to image large neural populations with single-cell resolution. The resulting datasets are quite large, which has presented a barrier to routine open sharing of this data, slowing progress in reproducible research. State of the art methods for analyzing this data are based on non-negative matrix factorization (NMF); these approaches solve a non-convex optimization problem, and are effective when good initializations are available, but can break down in low-SNR settings where common initialization approaches fail. Here we introduce an approach to compressing and denoising functional imaging data. The method is based on a spatially-localized penalized matrix decomposition (PMD) of the data to separate (low-dimensional) signal from (temporally-uncorrelated) noise. This approach can be applied in parallel on local spatial patches and is therefore highly scalable, does not impose non-negativity constraints or require stringent identifiability assumptions (leading to significantly more robust results compared to NMF), and estimates all parameters directly from the data, so no hand-tuning is required. We have applied the method to a wide range of functional imaging data (including one-photon, two-photon, three-photon, widefield, somatic, axonal, dendritic, calcium, and voltage imaging datasets): in all cases, we observe ~2-4x increases in SNR and compression rates of 20-300x with minimal visible loss of signal, with no adjustment of hyperparameters; this in turn facilitates the process of demixing the observed activity into contributions from individual neurons. We focus on two challenging applications: dendritic calcium imaging data and voltage imaging data in the context of optogenetic stimulation. In both cases, we show that our new approach leads to faster and much more robust extraction of activity from the data.
Subsampled Optimization: Statistical Guarantees, Mean Squared Error Approximation, and Sampling Method
Apr 10, 2018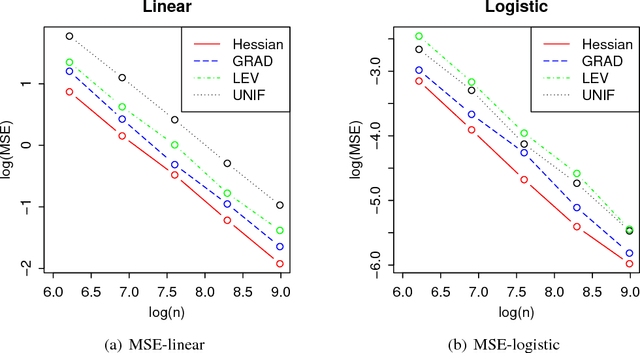


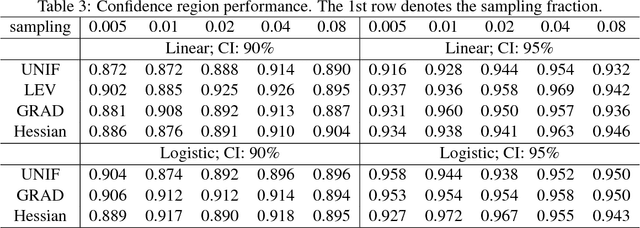
For optimization on large-scale data, exactly calculating its solution may be computationally difficulty because of the large size of the data. In this paper we consider subsampled optimization for fast approximating the exact solution. In this approach, one gets a surrogate dataset by sampling from the full data, and then obtains an approximate solution by solving the subsampled optimization based on the surrogate. One main theoretical contributions are to provide the asymptotic properties of the approximate solution with respect to the exact solution as statistical guarantees, and to rigorously derive an accurate approximation of the mean squared error (MSE) and an approximately unbiased MSE estimator. These results help us better diagnose the subsampled optimization in the context that a confidence region on the exact solution is provided using the approximate solution. The other consequence of our results is to propose an optimal sampling method, Hessian-based sampling, whose probabilities are proportional to the norms of Newton directions. Numerical experiments with least-squares and logistic regression show promising performance, in line with our results.