 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultinomial Logit Bandit with Linear Utility Functions
May 08, 2018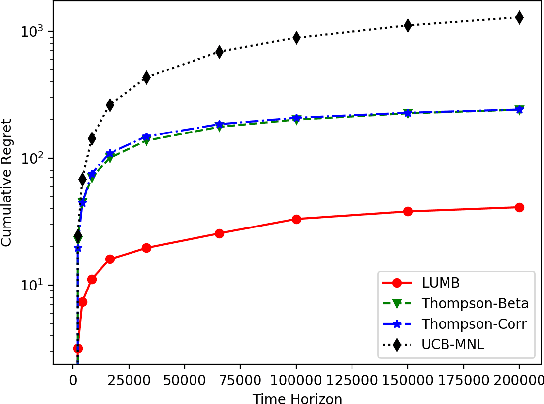
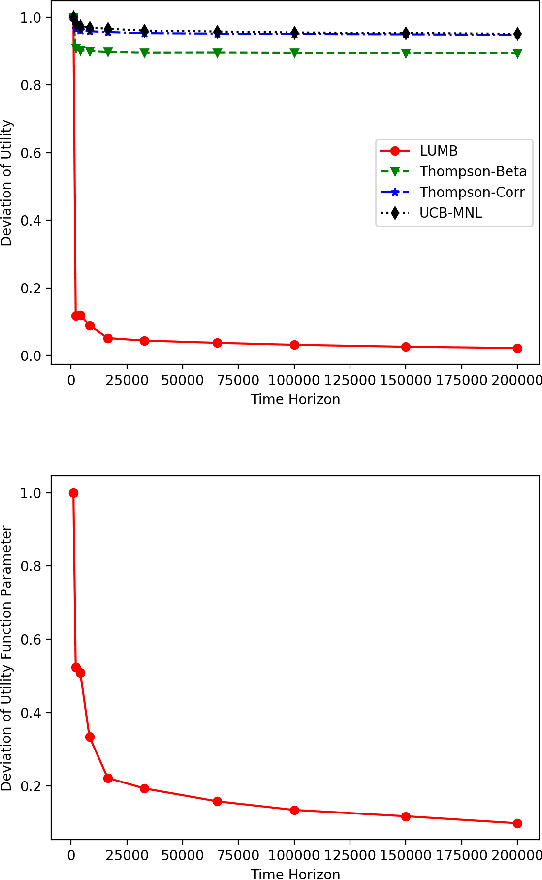
Multinomial logit bandit is a sequential subset selection problem which arises in many applications. In each round, the player selects a $K$-cardinality subset from $N$ candidate items, and receives a reward which is governed by a {\it multinomial logit} (MNL) choice model considering both item utility and substitution property among items. The player's objective is to dynamically learn the parameters of MNL model and maximize cumulative reward over a finite horizon $T$. This problem faces the exploration-exploitation dilemma, and the involved combinatorial nature makes it non-trivial. In recent years, there have developed some algorithms by exploiting specific characteristics of the MNL model, but all of them estimate the parameters of MNL model separately and incur a regret no better than $\tilde{O}\big(\sqrt{NT}\big)$ which is not preferred for large candidate set size $N$. In this paper, we consider the {\it linear utility} MNL choice model whose item utilities are represented as linear functions of $d$-dimension item features, and propose an algorithm, titled {\bf LUMB}, to exploit the underlying structure. It is proven that the proposed algorithm achieves $\tilde{O}\big(dK\sqrt{T}\big)$ regret which is free of candidate set size. Experiments show the superiority of the proposed algorithm.
NEON+: Accelerated Gradient Methods for Extracting Negative Curvature for Non-Convex Optimization
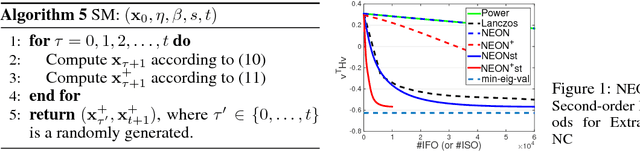
Mar 01, 2018Accelerated gradient (AG) methods are breakthroughs in convex optimization, improving the convergence rate of the gradient descent method for optimization with smooth functions. However, the analysis of AG methods for non-convex optimization is still limited. It remains an open question whether AG methods from convex optimization can accelerate the convergence of the gradient descent method for finding local minimum of non-convex optimization problems. This paper provides an affirmative answer to this question. In particular, we analyze two renowned variants of AG methods (namely Polyak's Heavy Ball method and Nesterov's Accelerated Gradient method) for extracting the negative curvature from random noise, which is central to escaping from saddle points. By leveraging the proposed AG methods for extracting the negative curvature, we present a new AG algorithm with double loops for non-convex optimization~\footnote{this is in contrast to a single-loop AG algorithm proposed in a recent manuscript~\citep{AGNON}, which directly analyzed the Nesterov's AG method for non-convex optimization and appeared online on November 29, 2017. However, we emphasize that our work is an independent work, which is inspired by our earlier work~\citep{NEON17} and is based on a different novel analysis.}, which converges to second-order stationary point $\x$ such that $\|\nabla f(\x)\|\leq \epsilon$ and $\nabla^2 f(\x)\geq -\sqrt{\epsilon} I$ with $\widetilde O(1/\epsilon^{1.75})$ iteration complexity, improving that of gradient descent method by a factor of $\epsilon^{-0.25}$ and matching the best iteration complexity of second-order Hessian-free methods for non-convex optimization.
First-order Stochastic Algorithms for Escaping From Saddle Points in Almost Linear Time
Mar 01, 2018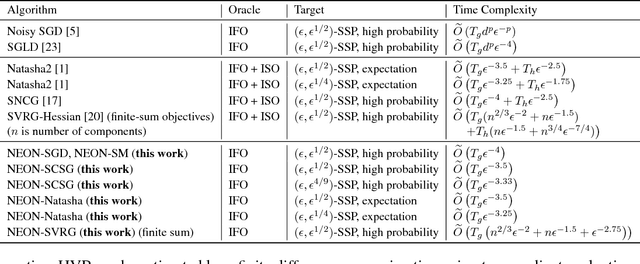
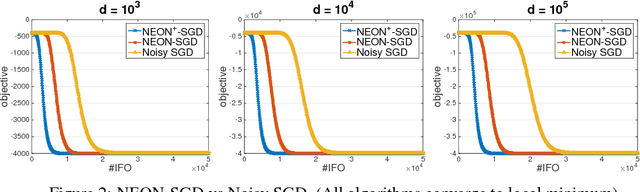
Two classes of methods have been proposed for escaping from saddle points with one using the second-order information carried by the Hessian and the other adding the noise into the first-order information. The existing analysis for algorithms using noise in the first-order information is quite involved and hides the essence of added noise, which hinder further improvements of these algorithms. In this paper, we present a novel perspective of noise-adding technique, i.e., adding the noise into the first-order information can help extract the negative curvature from the Hessian matrix, and provide a formal reasoning of this perspective by analyzing a simple first-order procedure. More importantly, the proposed procedure enables one to design purely first-order stochastic algorithms for escaping from non-degenerate saddle points with a much better time complexity (almost linear time in terms of the problem's dimensionality). In particular, we develop a {\bf first-order stochastic algorithm} based on our new technique and an existing algorithm that only converges to a first-order stationary point to enjoy a time complexity of {$\widetilde O(d/\epsilon^{3.5})$ for finding a nearly second-order stationary point $\bf{x}$ such that $\|\nabla F(bf{x})\|\leq \epsilon$ and $\nabla^2 F(bf{x})\geq -\sqrt{\epsilon}I$ (in high probability), where $F(\cdot)$ denotes the objective function and $d$ is the dimensionality of the problem. To the best of our knowledge, this is the best theoretical result of first-order algorithms for stochastic non-convex optimization, which is even competitive with if not better than existing stochastic algorithms hinging on the second-order information.
Improved Dynamic Regret for Non-degenerate Functions
Nov 02, 2017Recently, there has been a growing research interest in the analysis of dynamic regret, which measures the performance of an online learner against a sequence of local minimizers. By exploiting the strong convexity, previous studies have shown that the dynamic regret can be upper bounded by the path-length of the comparator sequence. In this paper, we illustrate that the dynamic regret can be further improved by allowing the learner to query the gradient of the function multiple times, and meanwhile the strong convexity can be weakened to other non-degenerate conditions. Specifically, we introduce the squared path-length, which could be much smaller than the path-length, as a new regularity of the comparator sequence. When multiple gradients are accessible to the learner, we first demonstrate that the dynamic regret of strongly convex functions can be upper bounded by the minimum of the path-length and the squared path-length. We then extend our theoretical guarantee to functions that are semi-strongly convex or self-concordant. To the best of our knowledge, this is the first time that semi-strong convexity and self-concordance are utilized to tighten the dynamic regret.
Extremely Low Bit Neural Network: Squeeze the Last Bit Out with ADMM
Sep 13, 2017



Although deep learning models are highly effective for various learning tasks, their high computational costs prohibit the deployment to scenarios where either memory or computational resources are limited. In this paper, we focus on compressing and accelerating deep models with network weights represented by very small numbers of bits, referred to as extremely low bit neural network. We model this problem as a discretely constrained optimization problem. Borrowing the idea from Alternating Direction Method of Multipliers (ADMM), we decouple the continuous parameters from the discrete constraints of network, and cast the original hard problem into several subproblems. We propose to solve these subproblems using extragradient and iterative quantization algorithms that lead to considerably faster convergency compared to conventional optimization methods. Extensive experiments on image recognition and object detection verify that the proposed algorithm is more effective than state-of-the-art approaches when coming to extremely low bit neural network.
Empirical Risk Minimization for Stochastic Convex Optimization: $O(1/n)$- and $O(1/n^2)$-type of Risk Bounds
Feb 07, 2017
Although there exist plentiful theories of empirical risk minimization (ERM) for supervised learning, current theoretical understandings of ERM for a related problem---stochastic convex optimization (SCO), are limited. In this work, we strengthen the realm of ERM for SCO by exploiting smoothness and strong convexity conditions to improve the risk bounds. First, we establish an $\widetilde{O}(d/n + \sqrt{F_*/n})$ risk bound when the random function is nonnegative, convex and smooth, and the expected function is Lipschitz continuous, where $d$ is the dimensionality of the problem, $n$ is the number of samples, and $F_*$ is the minimal risk. Thus, when $F_*$ is small we obtain an $\widetilde{O}(d/n)$ risk bound, which is analogous to the $\widetilde{O}(1/n)$ optimistic rate of ERM for supervised learning. Second, if the objective function is also $\lambda$-strongly convex, we prove an $\widetilde{O}(d/n + \kappa F_*/n )$ risk bound where $\kappa$ is the condition number, and improve it to $O(1/[\lambda n^2] + \kappa F_*/n)$ when $n=\widetilde{\Omega}(\kappa d)$. As a result, we obtain an $O(\kappa/n^2)$ risk bound under the condition that $n$ is large and $F_*$ is small, which to the best of our knowledge, is the first $O(1/n^2)$-type of risk bound of ERM. Third, we stress that the above results are established in a unified framework, which allows us to derive new risk bounds under weaker conditions, e.g., without convexity of the random function and Lipschitz continuity of the expected function. Finally, we demonstrate that to achieve an $O(1/[\lambda n^2] + \kappa F_*/n)$ risk bound for supervised learning, the $\widetilde{\Omega}(\kappa d)$ requirement on $n$ can be replaced with $\Omega(\kappa^2)$, which is dimensionality-independent.
Sparse Learning for Large-scale and High-dimensional Data: A Randomized Convex-concave Optimization Approach
Oct 16, 2016In this paper, we develop a randomized algorithm and theory for learning a sparse model from large-scale and high-dimensional data, which is usually formulated as an empirical risk minimization problem with a sparsity-inducing regularizer. Under the assumption that there exists a (approximately) sparse solution with high classification accuracy, we argue that the dual solution is also sparse or approximately sparse. The fact that both primal and dual solutions are sparse motivates us to develop a randomized approach for a general convex-concave optimization problem. Specifically, the proposed approach combines the strength of random projection with that of sparse learning: it utilizes random projection to reduce the dimensionality, and introduces $\ell_1$-norm regularization to alleviate the approximation error caused by random projection. Theoretical analysis shows that under favored conditions, the randomized algorithm can accurately recover the optimal solutions to the convex-concave optimization problem (i.e., recover both the primal and dual solutions).
Tracking Slowly Moving Clairvoyant: Optimal Dynamic Regret of Online Learning with True and Noisy Gradient
May 16, 2016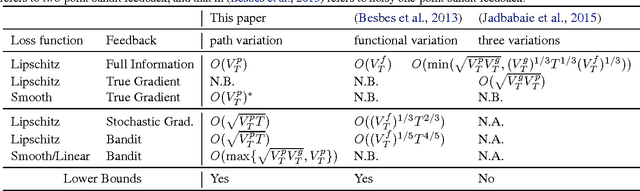
This work focuses on dynamic regret of online convex optimization that compares the performance of online learning to a clairvoyant who knows the sequence of loss functions in advance and hence selects the minimizer of the loss function at each step. By assuming that the clairvoyant moves slowly (i.e., the minimizers change slowly), we present several improved variation-based upper bounds of the dynamic regret under the true and noisy gradient feedback, which are {\it optimal} in light of the presented lower bounds. The key to our analysis is to explore a regularity metric that measures the temporal changes in the clairvoyant's minimizers, to which we refer as {\it path variation}. Firstly, we present a general lower bound in terms of the path variation, and then show that under full information or gradient feedback we are able to achieve an optimal dynamic regret. Secondly, we present a lower bound with noisy gradient feedback and then show that we can achieve optimal dynamic regrets under a stochastic gradient feedback and two-point bandit feedback. Moreover, for a sequence of smooth loss functions that admit a small variation in the gradients, our dynamic regret under the two-point bandit feedback matches what is achieved with full information.
Similarity Learning via Adaptive Regression and Its Application to Image Retrieval
Dec 06, 2015
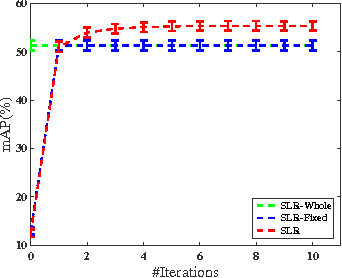
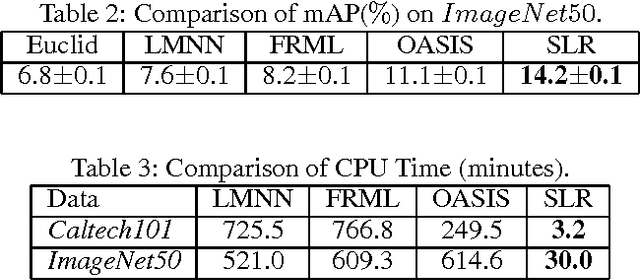
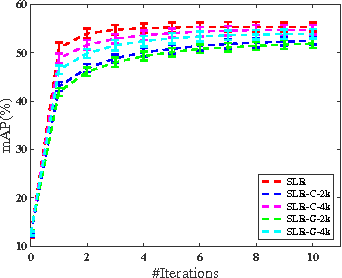
We study the problem of similarity learning and its application to image retrieval with large-scale data. The similarity between pairs of images can be measured by the distances between their high dimensional representations, and the problem of learning the appropriate similarity is often addressed by distance metric learning. However, distance metric learning requires the learned metric to be a PSD matrix, which is computational expensive and not necessary for retrieval ranking problem. On the other hand, the bilinear model is shown to be more flexible for large-scale image retrieval task, hence, we adopt it to learn a matrix for estimating pairwise similarities under the regression framework. By adaptively updating the target matrix in regression, we can mimic the hinge loss, which is more appropriate for similarity learning problem. Although the regression problem can have the closed-form solution, the computational cost can be very expensive. The computational challenges come from two aspects: the number of images can be very large and image features have high dimensionality. We address the first challenge by compressing the data by a randomized algorithm with the theoretical guarantee. For the high dimensional issue, we address it by taking low rank assumption and applying alternating method to obtain the partial matrix, which has a global optimal solution. Empirical studies on real world image datasets (i.e., Caltech and ImageNet) demonstrate the effectiveness and efficiency of the proposed method.
Stochastic Proximal Gradient Descent for Nuclear Norm Regularization
Dec 05, 2015In this paper, we utilize stochastic optimization to reduce the space complexity of convex composite optimization with a nuclear norm regularizer, where the variable is a matrix of size $m \times n$. By constructing a low-rank estimate of the gradient, we propose an iterative algorithm based on stochastic proximal gradient descent (SPGD), and take the last iterate of SPGD as the final solution. The main advantage of the proposed algorithm is that its space complexity is $O(m+n)$, in contrast, most of previous algorithms have a $O(mn)$ space complexity. Theoretical analysis shows that it achieves $O(\log T/\sqrt{T})$ and $O(\log T/T)$ convergence rates for general convex functions and strongly convex functions, respectively.