 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Linear Speedup Analysis of Communication Efficient Momentum SGD for Distributed Non-Convex Optimization
May 09, 2019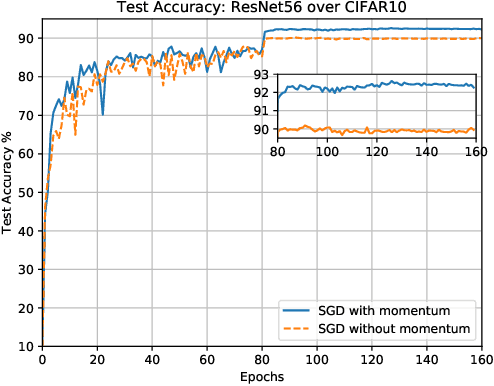

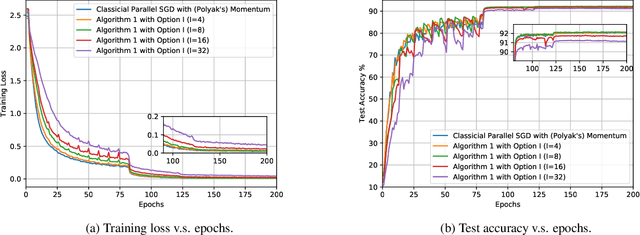
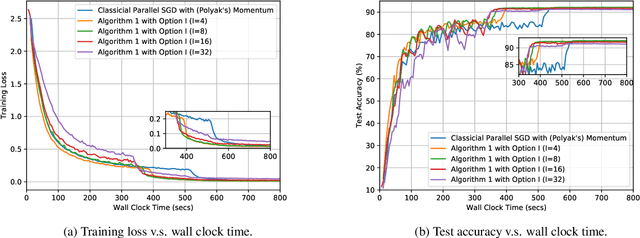
Recent developments on large-scale distributed machine learning applications, e.g., deep neural networks, benefit enormously from the advances in distributed non-convex optimization techniques, e.g., distributed Stochastic Gradient Descent (SGD). A series of recent works study the linear speedup property of distributed SGD variants with reduced communication. The linear speedup property enable us to scale out the computing capability by adding more computing nodes into our system. The reduced communication complexity is desirable since communication overhead is often the performance bottleneck in distributed systems. Recently, momentum methods are more and more widely adopted in training machine learning models and can often converge faster and generalize better. For example, many practitioners use distributed SGD with momentum to train deep neural networks with big data. However, it remains unclear whether any distributed momentum SGD possesses the same linear speedup property as distributed SGD and has reduced communication complexity. This paper fills the gap by considering a distributed communication efficient momentum SGD method and proving its linear speedup property.
Conservative Exploration for Semi-Bandits with Linear Generalization: A Product Selection Problem for Urban Warehouses
Mar 19, 2019
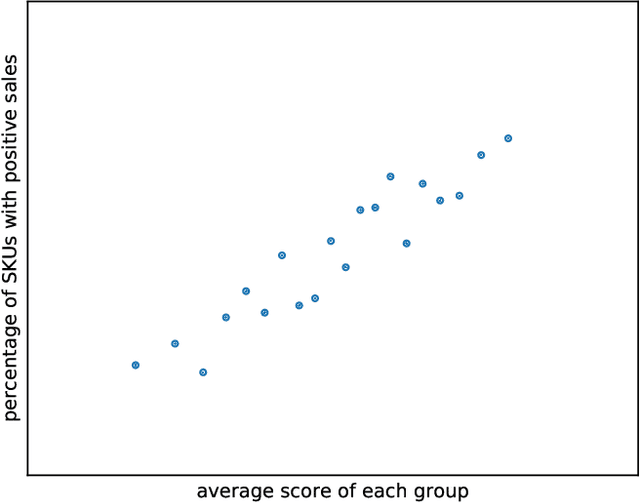
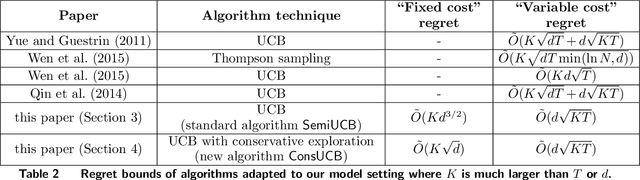
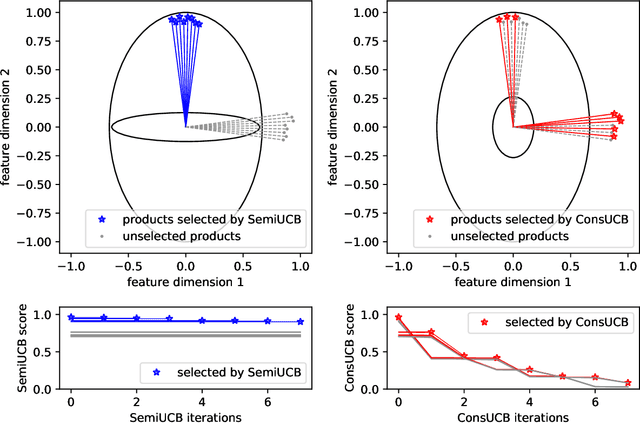
The recent rising popularity of ultra-fast delivery services on retail platforms fuels the increasing use of urban warehouses, whose proximity to customers makes fast deliveries viable. The space limit in urban warehouses poses a problem for the online retailers: the number of products (SKUs) they carry is no longer "the more, the better", yet it can still be significantly large, reaching hundreds or thousands in a product category. In this paper, we study algorithms for dynamically identifying a large number of products (i.e., SKUs) with top customer purchase probabilities on the fly, from an ocean of potential products to offer on retailers' ultra-fast delivery platforms. We distill the product selection problem into a semi-bandit model with linear generalization. There are in total $N$ different arms, each with a feature vector of dimension $d$. The player pulls $K$ arms in each period and observes the bandit feedback from each of the pulled arms. We focus on the setting where $K$ is much greater than the number of total time periods $T$ or the dimension of product features $d$. We first analyze a standard UCB algorithm and show its regret bound can be expressed as the sum of a $T$-independent part $\tilde O(K d^{3/2})$ and a $T$-dependent part $\tilde O(d\sqrt{KT})$, which we refer to as "fixed cost" and "variable cost" respectively. To reduce the fixed cost for large $K$ values, we propose a novel online learning algorithm, with more conservative exploration steps, and show its fixed cost is reduced by a factor of $d$ to $\tilde O(K \sqrt{d})$. Moreover, we test the algorithms on an industrial dataset from Alibaba Group. Experimental results show that our new algorithm reduces the total regret of the standard UCB algorithm by at least 10%.
Which Factorization Machine Modeling is Better: A Theoretical Answer with Optimal Guarantee
Jan 30, 2019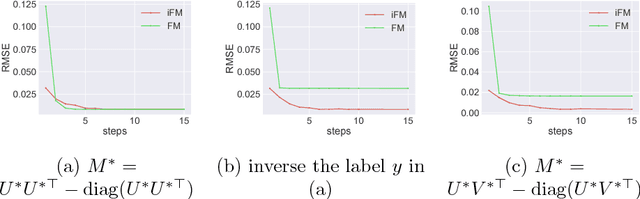
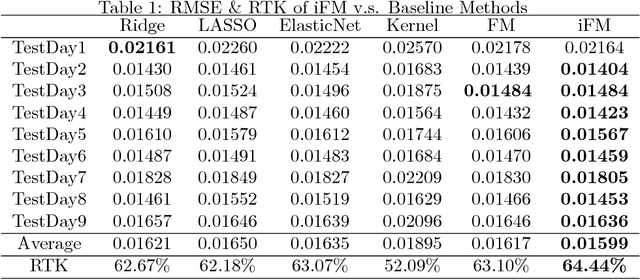
Factorization machine (FM) is a popular machine learning model to capture the second order feature interactions. The optimal learning guarantee of FM and its generalized version is not yet developed. For a rank $k$ generalized FM of $d$ dimensional input, the previous best known sampling complexity is $\mathcal{O}[k^{3}d\cdot\mathrm{polylog}(kd)]$ under Gaussian distribution. This bound is sub-optimal comparing to the information theoretical lower bound $\mathcal{O}(kd)$. In this work, we aim to tighten this bound towards optimal and generalize the analysis to sub-gaussian distribution. We prove that when the input data satisfies the so-called $\tau$-Moment Invertible Property, the sampling complexity of generalized FM can be improved to $\mathcal{O}[k^{2}d\cdot\mathrm{polylog}(kd)/\tau^{2}]$. When the second order self-interaction terms are excluded in the generalized FM, the bound can be improved to the optimal $\mathcal{O}[kd\cdot\mathrm{polylog}(kd)]$ up to the logarithmic factors. Our analysis also suggests that the positive semi-definite constraint in the conventional FM is redundant as it does not improve the sampling complexity while making the model difficult to optimize. We evaluate our improved FM model in real-time high precision GPS signal calibration task to validate its superiority.
Why Does Stagewise Training Accelerate Convergence of Testing Error Over SGD?
Dec 11, 2018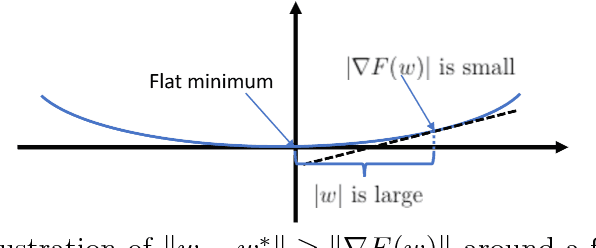
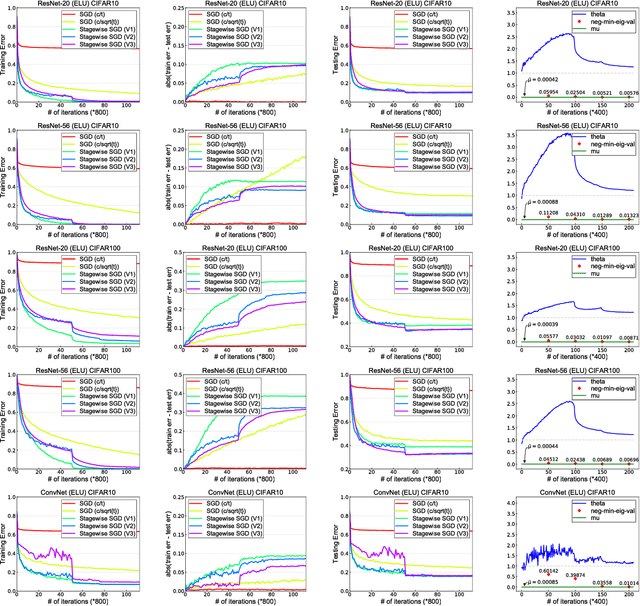
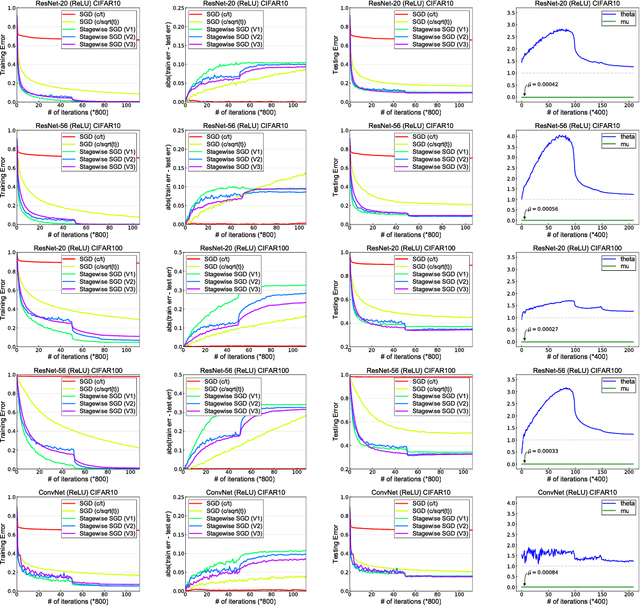
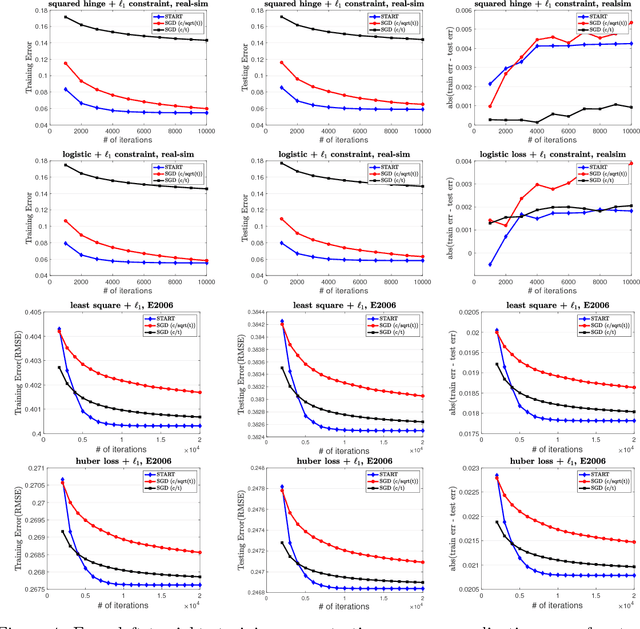
Stagewise training strategy is commonly used for learning neural networks, which uses a stochastic algorithm (e.g., SGD) starting with a relatively large step size (aka learning rate) and geometrically decreasing the step size after a number of iterations. It has been observed that the stagewise SGD has much faster convergence than the vanilla SGD with a polynomial decaying step size in terms of both training error and testing error. {\it But how to explain this phenomenon has been largely ignored by existing studies.} This paper provides some theoretical evidence for explaining this faster convergence. In particular, we consider the stagewise training strategy for minimizing empirical risk that satisfies the Polyak-\L ojasiewicz condition, which has been observed/proved for neural networks and also holds for a broad family of convex functions. For convex loss functions and "nice-behaviored" non-convex loss functions that are close to a convex function (namely weakly convex functions), we establish faster convergence of stagewise training than the vanilla SGD under the same condition on both training error and testing error. Indeed, the proposed algorithm has additional favorable features that come with theoretical guarantee for the considered non-convex optimization problems, including using explicit algorithmic regularization at each stage, using stagewise averaged solution for restarting, and returning the last stagewise averaged solution as the final solution. To differentiate from commonly used stagewise SGD, we refer to our algorithm as stagewise regularized training algorithm. Of independent interest, the proved testing error bounds for a family of non-convex loss functions are dimensionality and norm independent.
Stochastic Optimization for DC Functions and Non-smooth Non-convex Regularizers with Non-asymptotic Convergence
Nov 28, 2018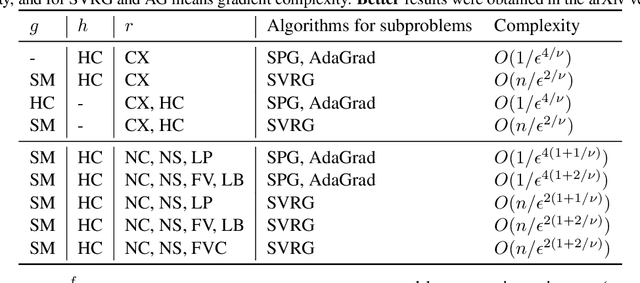
Difference of convex (DC) functions cover a broad family of non-convex and possibly non-smooth and non-differentiable functions, and have wide applications in machine learning and statistics. Although deterministic algorithms for DC functions have been extensively studied, stochastic optimization that is more suitable for learning with big data remains under-explored. In this paper, we propose new stochastic optimization algorithms and study their first-order convergence theories for solving a broad family of DC functions. We improve the existing algorithms and theories of stochastic optimization for DC functions from both practical and theoretical perspectives. On the practical side, our algorithm is more user-friendly without requiring a large mini-batch size and more efficient by saving unnecessary computations. On the theoretical side, our convergence analysis does not necessarily require the involved functions to be smooth with Lipschitz continuous gradient. Instead, the convergence rate of the proposed stochastic algorithm is automatically adaptive to the H\"{o}lder continuity of the gradient of one component function. Moreover, we extend the proposed stochastic algorithms for DC functions to solve problems with a general non-convex non-differentiable regularizer, which does not necessarily have a DC decomposition but enjoys an efficient proximal mapping. To the best of our knowledge, this is the first work that gives the first non-asymptotic convergence for solving non-convex optimization whose objective has a general non-convex non-differentiable regularizer.
Dynamic Regret of Strongly Adaptive Methods
Jun 04, 2018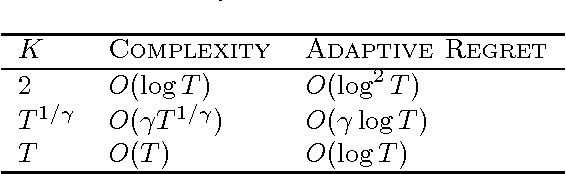
To cope with changing environments, recent developments in online learning have introduced the concepts of adaptive regret and dynamic regret independently. In this paper, we illustrate an intrinsic connection between these two concepts by showing that the dynamic regret can be expressed in terms of the adaptive regret and the functional variation. This observation implies that strongly adaptive algorithms can be directly leveraged to minimize the dynamic regret. As a result, we present a series of strongly adaptive algorithms that have small dynamic regrets for convex functions, exponentially concave functions, and strongly convex functions, respectively. To the best of our knowledge, this is the first time that exponential concavity is utilized to upper bound the dynamic regret. Moreover, all of those adaptive algorithms do not need any prior knowledge of the functional variation, which is a significant advantage over previous specialized methods for minimizing dynamic regret.
Large-scale Distance Metric Learning with Uncertainty
May 25, 2018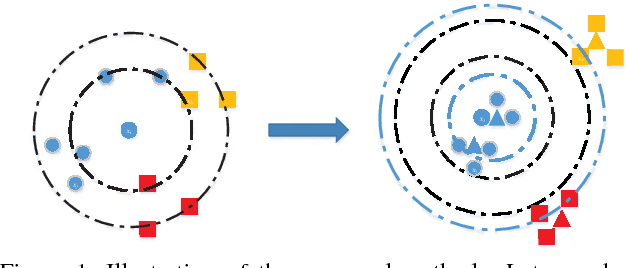
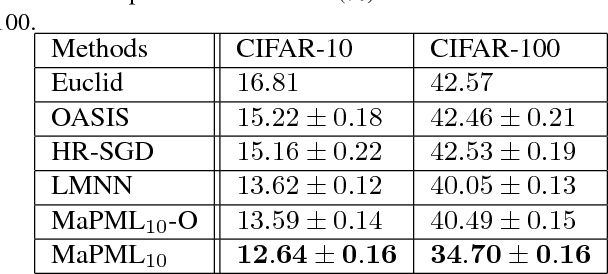
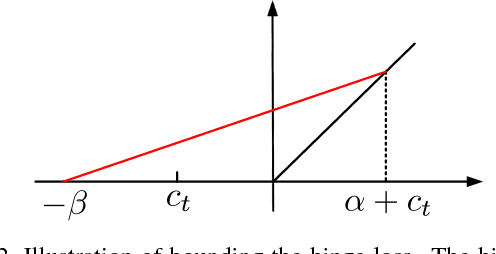
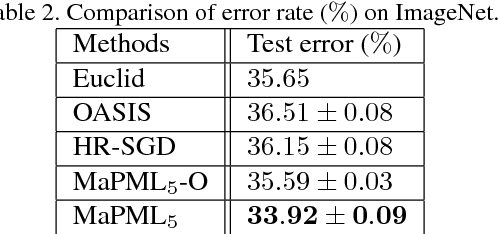
Distance metric learning (DML) has been studied extensively in the past decades for its superior performance with distance-based algorithms. Most of the existing methods propose to learn a distance metric with pairwise or triplet constraints. However, the number of constraints is quadratic or even cubic in the number of the original examples, which makes it challenging for DML to handle the large-scale data set. Besides, the real-world data may contain various uncertainty, especially for the image data. The uncertainty can mislead the learning procedure and cause the performance degradation. By investigating the image data, we find that the original data can be observed from a small set of clean latent examples with different distortions. In this work, we propose the margin preserving metric learning framework to learn the distance metric and latent examples simultaneously. By leveraging the ideal properties of latent examples, the training efficiency can be improved significantly while the learned metric also becomes robust to the uncertainty in the original data. Furthermore, we can show that the metric is learned from latent examples only, but it can preserve the large margin property even for the original data. The empirical study on the benchmark image data sets demonstrates the efficacy and efficiency of the proposed method.
Learning with Non-Convex Truncated Losses by SGD
May 21, 2018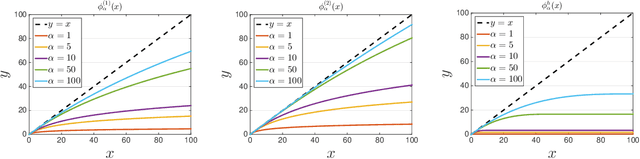
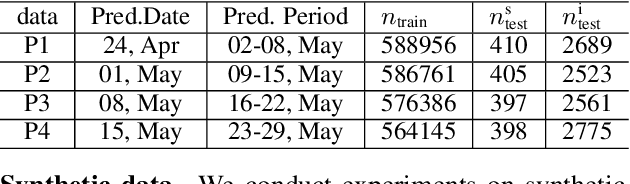
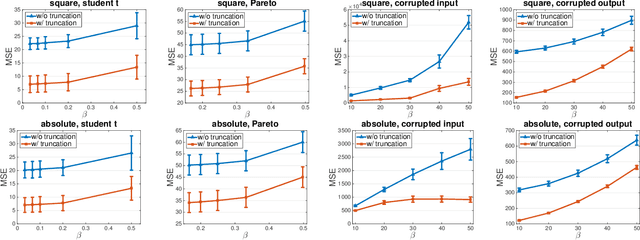
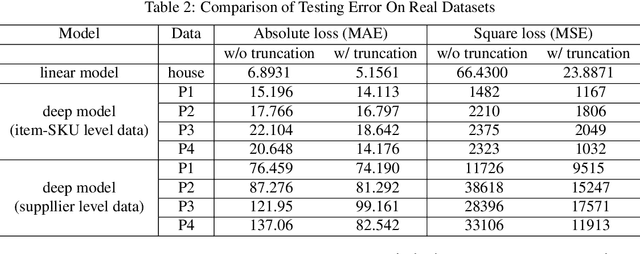
Learning with a {\it convex loss} function has been a dominating paradigm for many years. It remains an interesting question how non-convex loss functions help improve the generalization of learning with broad applicability. In this paper, we study a family of objective functions formed by truncating traditional loss functions, which is applicable to both shallow learning and deep learning. Truncating loss functions has potential to be less vulnerable and more robust to large noise in observations that could be adversarial. More importantly, it is a generic technique without assuming the knowledge of noise distribution. To justify non-convex learning with truncated losses, we establish excess risk bounds of empirical risk minimization based on truncated losses for heavy-tailed output, and statistical error of an approximate stationary point found by stochastic gradient descent (SGD) method. Our experiments for shallow and deep learning for regression with outliers, corrupted data and heavy-tailed noise further justify the proposed method.
Robust Optimization over Multiple Domains
May 19, 2018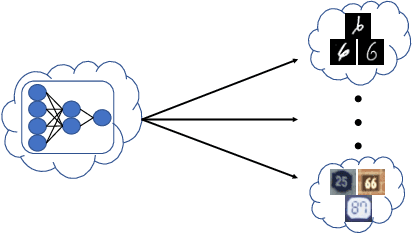
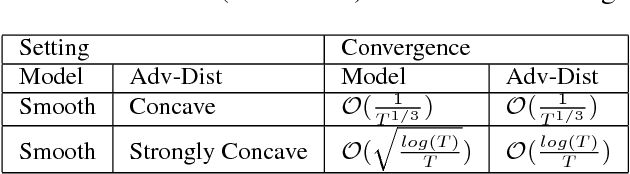
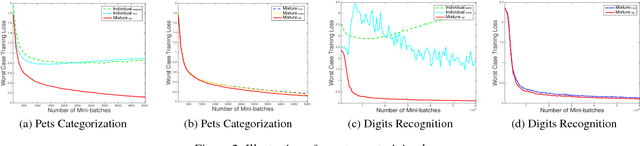

Recently, machine learning becomes important for the cloud computing service. Users of cloud computing can benefit from the sophisticated machine learning models provided by the service. Considering that users can come from different domains with the same problem, an ideal model has to be applicable over multiple domains. In this work, we propose to address this challenge by developing a framework of robust optimization. In lieu of minimizing the empirical risk, we aim to learn a model optimized with an adversarial distribution over multiple domains. Besides the convex model, we analyze the convergence rate of learning a robust non-convex model due to its dominating performance on many real-word applications. Furthermore, we demonstrate that both the robustness of the framework and the convergence rate can be enhanced by introducing appropriate regularizers for the adversarial distribution. The empirical study on real-world fine-grained visual categorization and digits recognition tasks verifies the effectiveness and efficiency of the proposed framework.
Fast Rates of ERM and Stochastic Approximation: Adaptive to Error Bound Conditions
May 11, 2018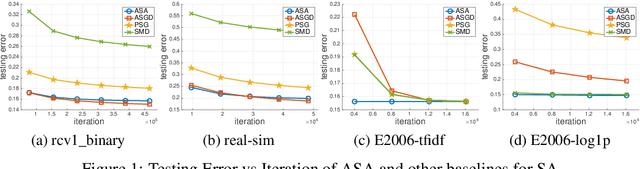
Error bound conditions (EBC) are properties that characterize the growth of an objective function when a point is moved away from the optimal set. They have recently received increasing attention in the field of optimization for developing optimization algorithms with fast convergence. However, the studies of EBC in statistical learning are hitherto still limited. The main contributions of this paper are two-fold. First, we develop fast and intermediate rates of empirical risk minimization (ERM) under EBC for risk minimization with Lipschitz continuous, and smooth convex random functions. Second, we establish fast and intermediate rates of an efficient stochastic approximation (SA) algorithm for risk minimization with Lipschitz continuous random functions, which requires only one pass of $n$ samples and adapts to EBC. For both approaches, the convergence rates span a full spectrum between $\widetilde O(1/\sqrt{n})$ and $\widetilde O(1/n)$ depending on the power constant in EBC, and could be even faster than $O(1/n)$ in special cases for ERM. Moreover, these convergence rates are automatically adaptive without using any knowledge of EBC. Overall, this work not only strengthens the understanding of ERM for statistical learning but also brings new fast stochastic algorithms for solving a broad range of statistical learning problems.