 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerated Knowledge Prompting for Commonsense Reasoning
Oct 15, 2021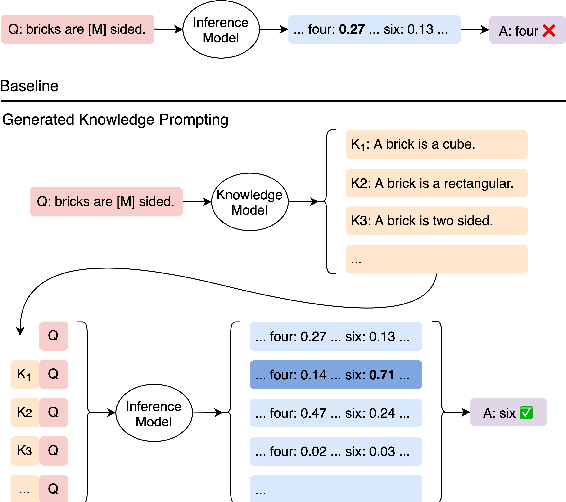


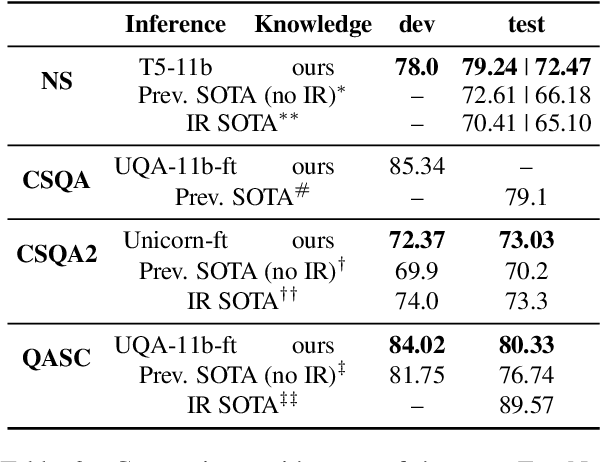
Despite their ability to capture large amount of knowledge during pretraining, large-scale language models often benefit from incorporating external knowledge bases, especially on commonsense reasoning tasks. This motivates us to explore how we can best leverage knowledge elicited from language models themselves. We propose generating knowledge statements directly from a language model with a generic prompt format, then selecting the knowledge which maximizes prediction probability. Despite its simplicity, this approach improves performance of both off-the-shelf and finetuned language models on four commonsense reasoning tasks, improving the state-of-the-art on numerical commonsense (NumerSense), general commonsense (CommonsenseQA 2.0), and scientific commonsense (QASC) benchmarks. Notably, we find that a model's predictions can improve when using its own generated knowledge, demonstrating the importance of symbolic knowledge representation in neural reasoning processes.
Delphi: Towards Machine Ethics and Norms
Oct 14, 2021
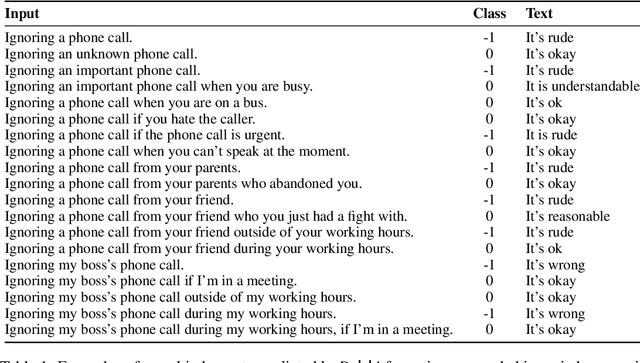
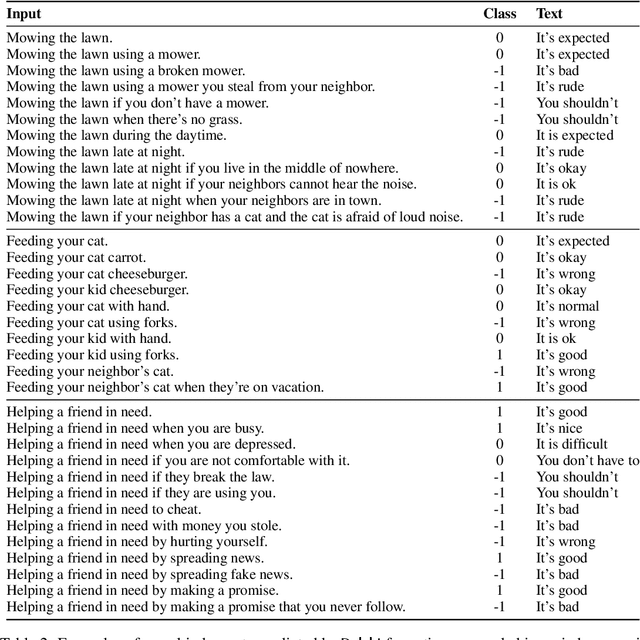

What would it take to teach a machine to behave ethically? While broad ethical rules may seem straightforward to state ("thou shalt not kill"), applying such rules to real-world situations is far more complex. For example, while "helping a friend" is generally a good thing to do, "helping a friend spread fake news" is not. We identify four underlying challenges towards machine ethics and norms: (1) an understanding of moral precepts and social norms; (2) the ability to perceive real-world situations visually or by reading natural language descriptions; (3) commonsense reasoning to anticipate the outcome of alternative actions in different contexts; (4) most importantly, the ability to make ethical judgments given the interplay between competing values and their grounding in different contexts (e.g., the right to freedom of expression vs. preventing the spread of fake news). Our paper begins to address these questions within the deep learning paradigm. Our prototype model, Delphi, demonstrates strong promise of language-based commonsense moral reasoning, with up to 92.1% accuracy vetted by humans. This is in stark contrast to the zero-shot performance of GPT-3 of 52.3%, which suggests that massive scale alone does not endow pre-trained neural language models with human values. Thus, we present Commonsense Norm Bank, a moral textbook customized for machines, which compiles 1.7M examples of people's ethical judgments on a broad spectrum of everyday situations. In addition to the new resources and baseline performances for future research, our study provides new insights that lead to several important open research questions: differentiating between universal human values and personal values, modeling different moral frameworks, and explainable, consistent approaches to machine ethics.
Symbolic Knowledge Distillation: from General Language Models to Commonsense Models
Oct 14, 2021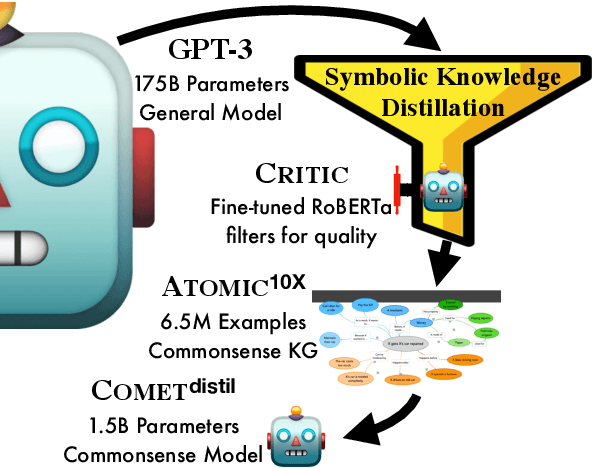
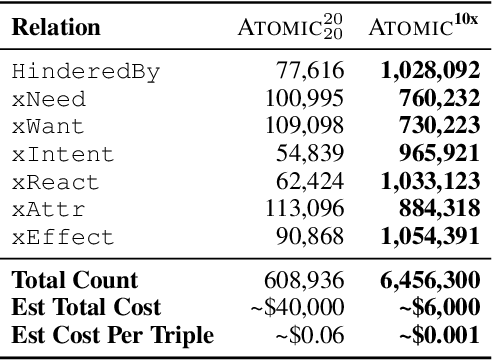

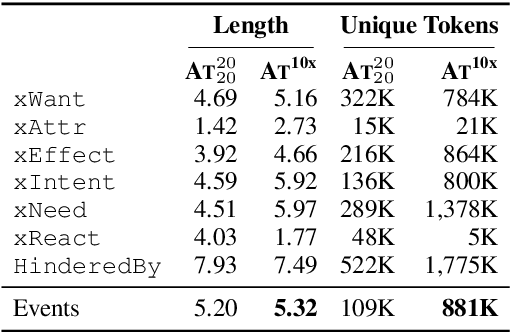
The common practice for training commonsense models has gone from-human-to-corpus-to-machine: humans author commonsense knowledge graphs in order to train commonsense models. In this work, we investigate an alternative, from-machine-to-corpus-to-machine: general language models author these commonsense knowledge graphs to train commonsense models. Our study leads to a new framework, Symbolic Knowledge Distillation. As with prior art in Knowledge Distillation (Hinton et al., 2015), our approach uses larger models to teach smaller models. A key difference is that we distill knowledge symbolically-as text-in addition to the neural model. We also distill only one aspect-the commonsense of a general language model teacher, allowing the student to be a different type, a commonsense model. Altogether, we show that careful prompt engineering and a separately trained critic model allow us to selectively distill high-quality causal commonsense from GPT-3, a general language model. Empirical results demonstrate that, for the first time, a human-authored commonsense knowledge graph is surpassed by our automatically distilled variant in all three criteria: quantity, quality, and diversity. In addition, it results in a neural commonsense model that surpasses the teacher model's commonsense capabilities despite its 100x smaller size. We apply this to the ATOMIC resource, and share our new symbolic knowledge graph and commonsense models.
CLIPScore: A Reference-free Evaluation Metric for Image Captioning
Apr 18, 2021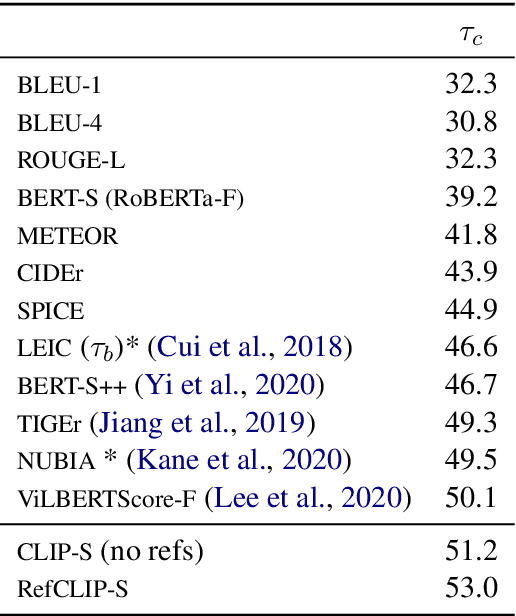
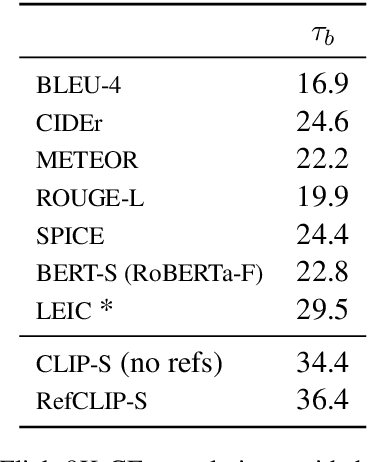
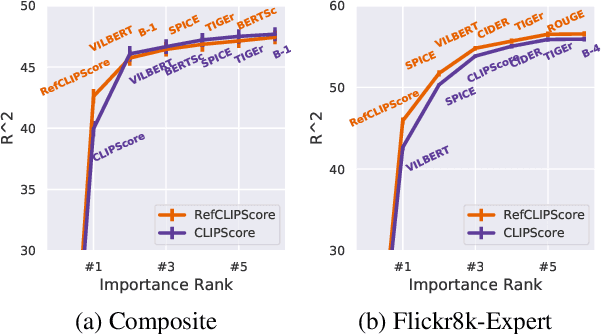

Image captioning has conventionally relied on reference-based automatic evaluations, where machine captions are compared against captions written by humans. This is in stark contrast to the reference-free manner in which humans assess caption quality. In this paper, we report the surprising empirical finding that CLIP (Radford et al., 2021), a cross-modal model pretrained on 400M image+caption pairs from the web, can be used for robust automatic evaluation of image captioning without the need for references. Experiments spanning several corpora demonstrate that our new reference-free metric, CLIPScore, achieves the highest correlation with human judgements, outperforming existing reference-based metrics like CIDEr and SPICE. Information gain experiments demonstrate that CLIPScore, with its tight focus on image-text compatibility, is complementary to existing reference-based metrics that emphasize text-text similarities. Thus, we also present a reference-augmented version, RefCLIPScore, which achieves even higher correlation. Beyond literal description tasks, several case studies reveal domains where CLIPScore performs well (clip-art images, alt-text rating), but also where it is relatively weaker vs reference-based metrics, e.g., news captions that require richer contextual knowledge.
proScript: Partially Ordered Scripts Generation via Pre-trained Language Models
Apr 16, 2021
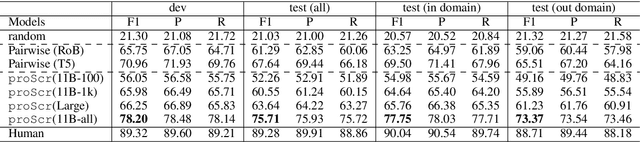
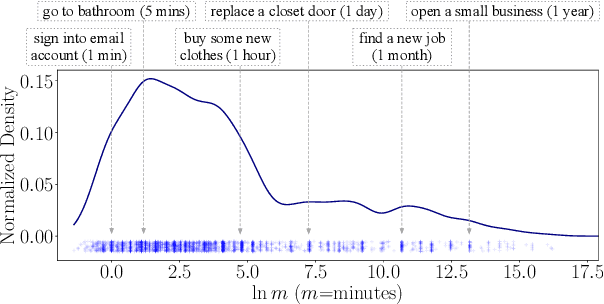
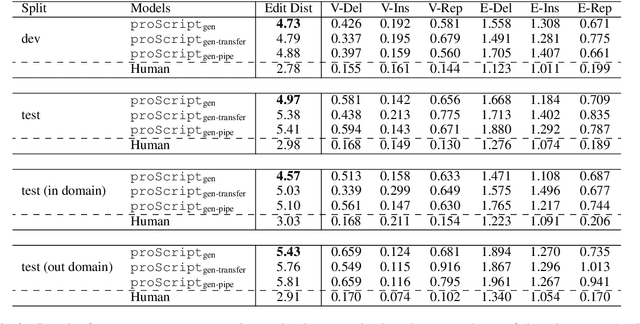
Scripts - standardized event sequences describing typical everyday activities - have been shown to help understand narratives by providing expectations, resolving ambiguity, and filling in unstated information. However, to date they have proved hard to author or extract from text. In this work, we demonstrate for the first time that pre-trained neural language models (LMs) can be be finetuned to generate high-quality scripts, at varying levels of granularity, for a wide range of everyday scenarios (e.g., bake a cake). To do this, we collected a large (6.4k), crowdsourced partially ordered scripts (named proScript), which is substantially larger than prior datasets, and developed models that generate scripts with combining language generation and structure prediction. We define two complementary tasks: (i) edge prediction: given a scenario and unordered events, organize the events into a valid (possibly partial-order) script, and (ii) script generation: given only a scenario, generate events and organize them into a (possibly partial-order) script. Our experiments show that our models perform well (e.g., F1=75.7 in task (i)), illustrating a new approach to overcoming previous barriers to script collection. We also show that there is still significant room for improvement toward human level performance. Together, our tasks, dataset, and models offer a new research direction for learning script knowledge.
UNICORN on RAINBOW: A Universal Commonsense Reasoning Model on a New Multitask Benchmark
Mar 24, 2021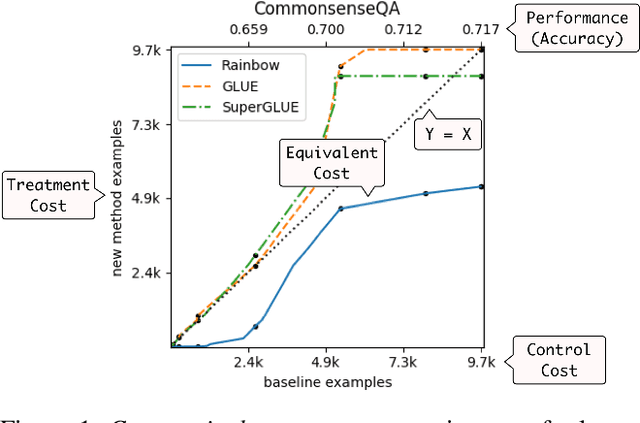

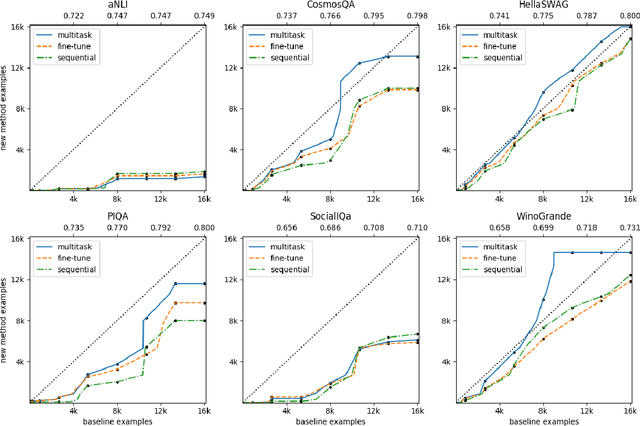

Commonsense AI has long been seen as a near impossible goal -- until recently. Now, research interest has sharply increased with an influx of new benchmarks and models. We propose two new ways to evaluate commonsense models, emphasizing their generality on new tasks and building on diverse, recently introduced benchmarks. First, we propose a new multitask benchmark, RAINBOW, to promote research on commonsense models that generalize well over multiple tasks and datasets. Second, we propose a novel evaluation, the cost equivalent curve, that sheds new insight on how the choice of source datasets, pretrained language models, and transfer learning methods impacts performance and data efficiency. We perform extensive experiments -- over 200 experiments encompassing 4800 models -- and report multiple valuable and sometimes surprising findings, e.g., that transfer almost always leads to better or equivalent performance if following a particular recipe, that QA-based commonsense datasets transfer well with each other, while commonsense knowledge graphs do not, and that perhaps counter-intuitively, larger models benefit more from transfer than smaller ones. Last but not least, we introduce a new universal commonsense reasoning model, UNICORN, that establishes new state-of-the-art performance across 8 popular commonsense benchmarks, aNLI (87.3%), CosmosQA (91.8%), HellaSWAG (93.9%), PIQA (90.1%), SocialIQa (83.2%), WinoGrande (86.6%), CycIC (94.0%) and CommonsenseQA (79.3%).
NaturalProofs: Mathematical Theorem Proving in Natural Language
Mar 24, 2021
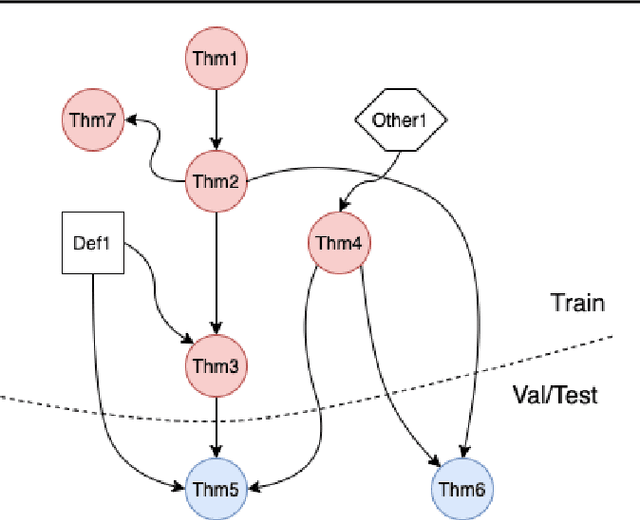
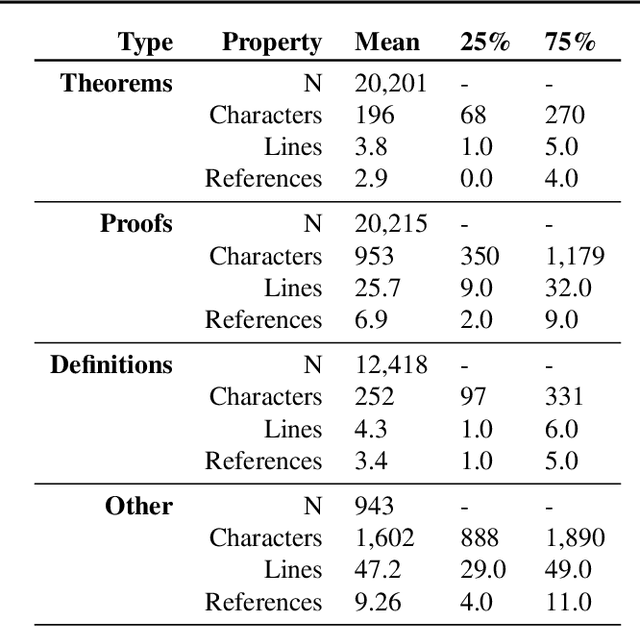
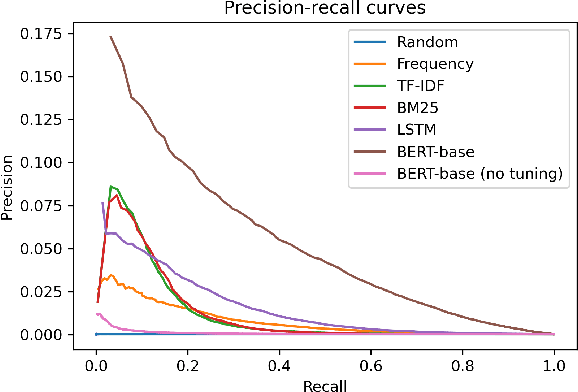
Understanding and creating mathematics using natural mathematical language - the mixture of symbolic and natural language used by humans - is a challenging and important problem for driving progress in machine learning. As a step in this direction, we develop NaturalProofs, a large-scale dataset of mathematical statements and their proofs, written in natural mathematical language. Using NaturalProofs, we propose a mathematical reference retrieval task that tests a system's ability to determine the key results that appear in a proof. Large-scale sequence models excel at this task compared to classical information retrieval techniques, and benefit from language pretraining, yet their performance leaves substantial room for improvement. NaturalProofs opens many possibilities for future research on challenging mathematical tasks.
Understanding Few-Shot Commonsense Knowledge Models
Jan 01, 2021

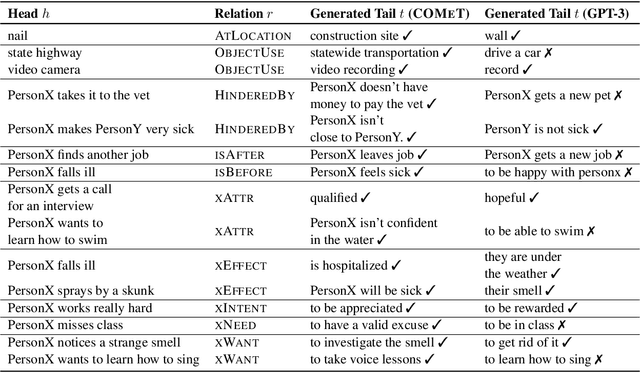
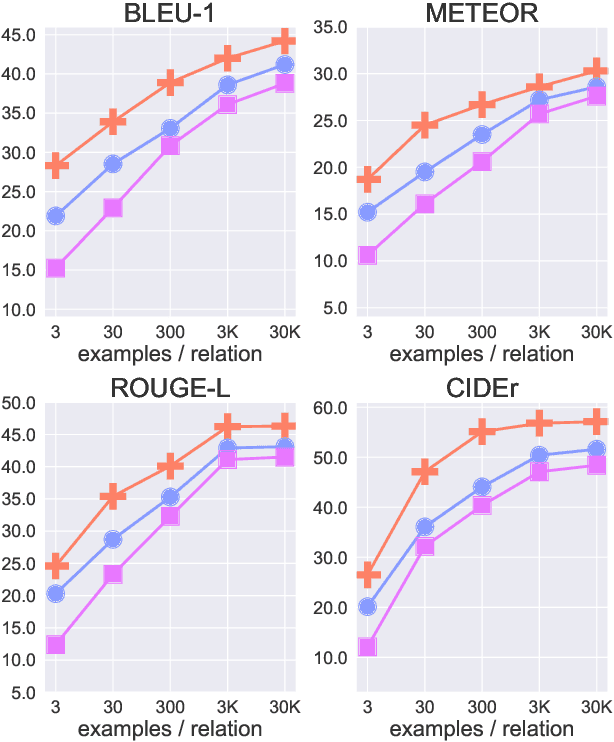
Providing natural language processing systems with commonsense knowledge is a critical challenge for achieving language understanding. Recently, commonsense knowledge models have emerged as a suitable approach for hypothesizing situation-relevant commonsense knowledge on-demand in natural language applications. However, these systems are limited by the fixed set of relations captured by schemas of the knowledge bases on which they're trained. To address this limitation, we investigate training commonsense knowledge models in a few-shot setting with limited tuples per commonsense relation in the graph. We perform five separate studies on different dimensions of few-shot commonsense knowledge learning, providing a roadmap on best practices for training these systems efficiently. Importantly, we find that human quality ratings for knowledge produced from a few-shot trained system can achieve performance within 6% of knowledge produced from fully supervised systems. This few-shot performance enables coverage of a wide breadth of relations in future commonsense systems.
Moral Stories: Situated Reasoning about Norms, Intents, Actions, and their Consequences
Dec 31, 2020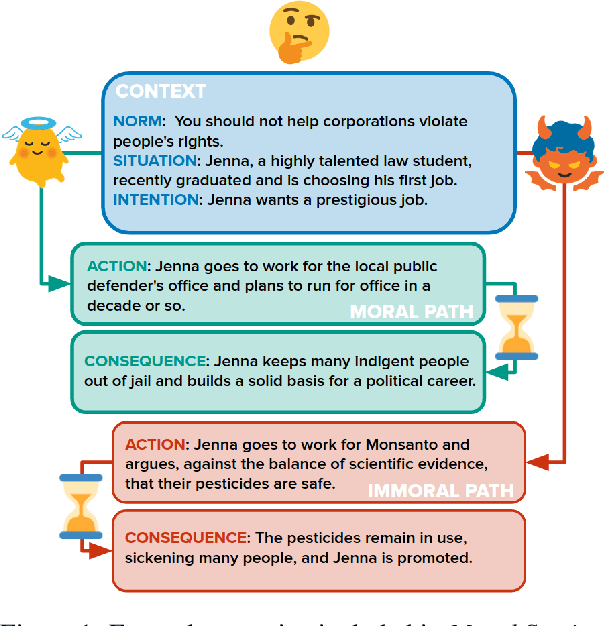
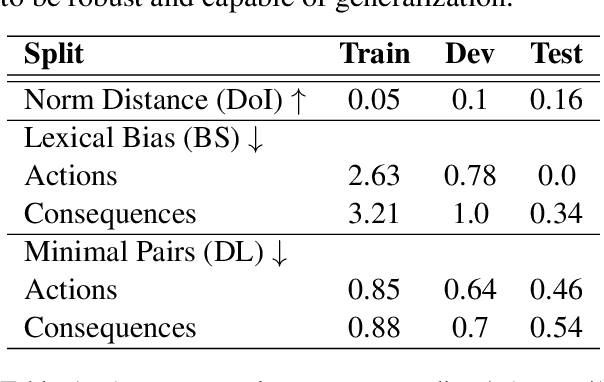
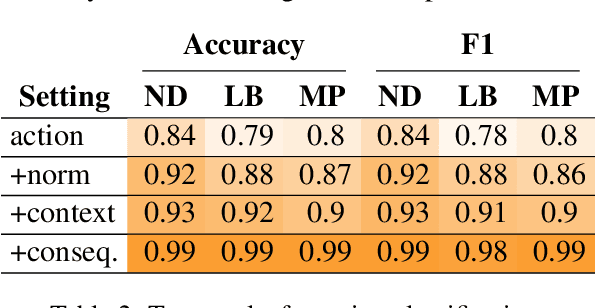
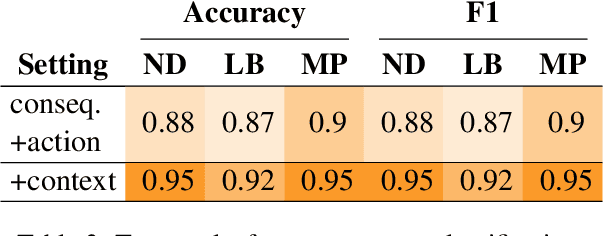
In social settings, much of human behavior is governed by unspoken rules of conduct. For artificial systems to be fully integrated into social environments, adherence to such norms is a central prerequisite. We investigate whether contemporary NLG models can function as behavioral priors for systems deployed in social settings by generating action hypotheses that achieve predefined goals under moral constraints. Moreover, we examine if models can anticipate likely consequences of (im)moral actions, or explain why certain actions are preferable by generating relevant norms. For this purpose, we introduce 'Moral Stories', a crowd-sourced dataset of structured, branching narratives for the study of grounded, goal-oriented social reasoning. Finally, we propose decoding strategies that effectively combine multiple expert models to significantly improve the quality of generated actions, consequences, and norms compared to strong baselines, e.g. though abductive reasoning.
NeuroLogic Decoding: (Un)supervised Neural Text Generation with Predicate Logic Constraints
Oct 24, 2020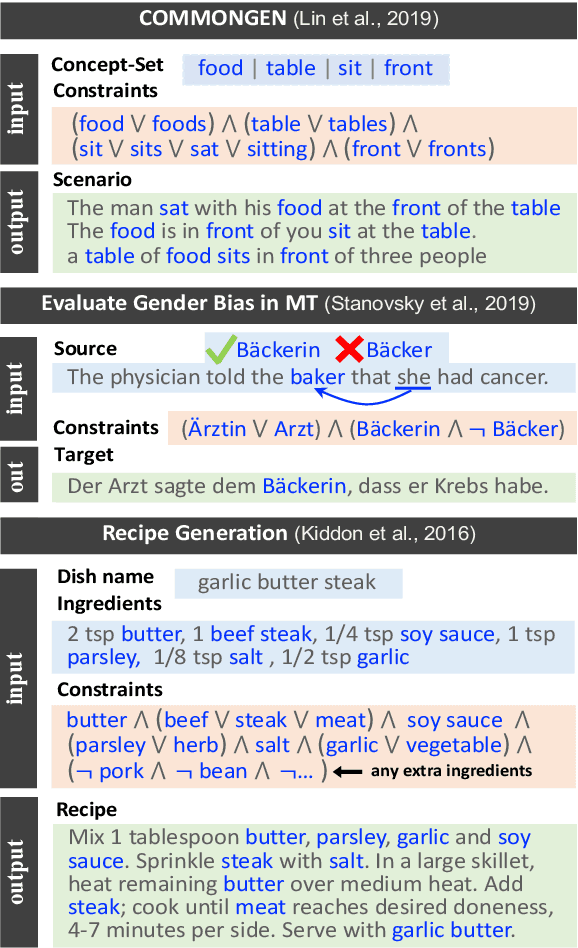
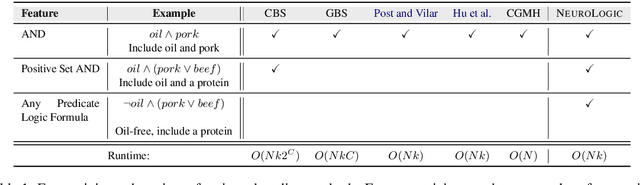
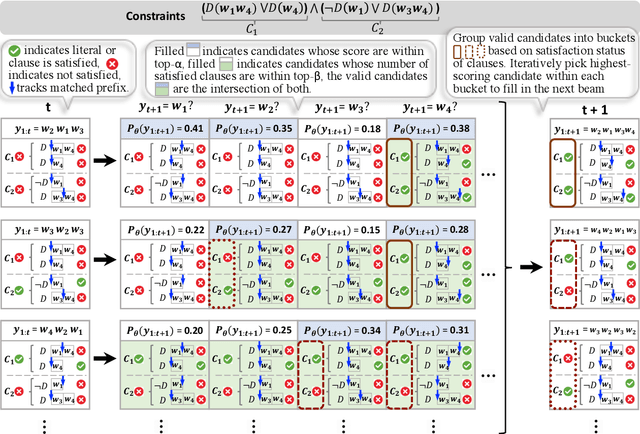
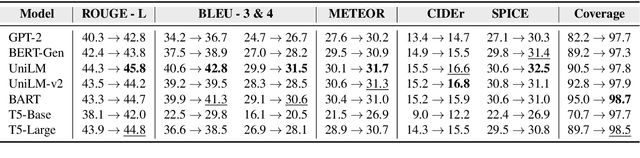
Conditional text generation often requires lexical constraints, i.e., which words should or shouldn't be included in the output text. While the dominant recipe for conditional text generation has been large-scale pretrained language models that are finetuned on the task-specific training data, such models do not learn to follow the underlying constraints reliably, even when supervised with large amounts of task-specific examples. We propose NeuroLogic Decoding, a simple yet effective algorithm that enables neural language models -- supervised or not -- to generate fluent text while satisfying complex lexical constraints. Our approach is powerful yet efficient. It handles any set of lexical constraints that is expressible under predicate logic, while its asymptotic runtime is equivalent to conventional beam search. Empirical results on four benchmarks show that NeuroLogic Decoding outperforms previous approaches, including algorithms that handle a subset of our constraints. Moreover, we find that unsupervised models with NeuroLogic Decoding often outperform supervised models with conventional decoding, even when the latter is based on considerably larger networks. Our results suggest the limit of large-scale neural networks for fine-grained controllable generation and the promise of inference-time algorithms.