 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG-DAUG: Generative Data Augmentation for Commonsense Reasoning
Paper and Code

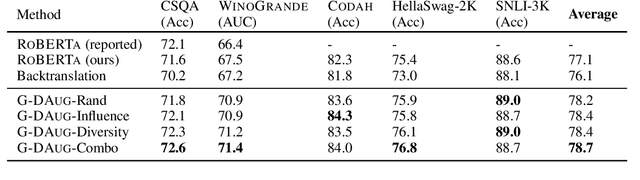
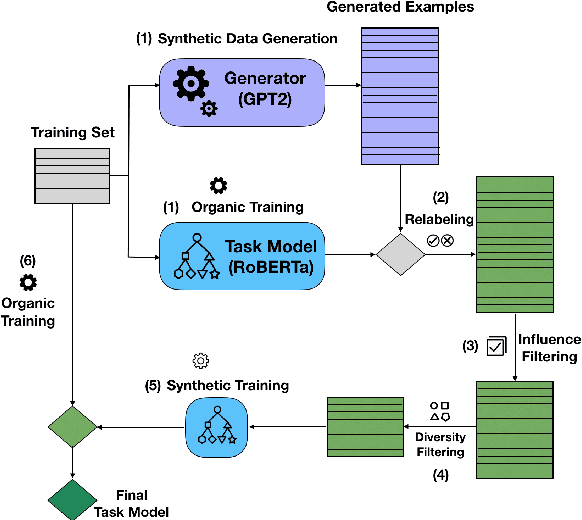
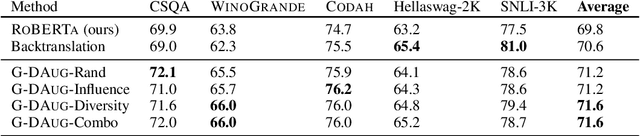
Recent advances in commonsense reasoning depend on large-scale human-annotated training data to achieve peak performance. However, manual curation of training examples is expensive and has been shown to introduce annotation artifacts that neural models can readily exploit and overfit on. We investigate G-DAUG, a novel generative data augmentation method that aims to achieve more accurate and robust learning in the low-resource setting. Our approach generates synthetic examples using pretrained language models, and selects the most informative and diverse set of examples for data augmentation. In experiments with multiple commonsense reasoning benchmarks, G-DAUG consistently outperforms existing data augmentation methods based on back-translation, and establishes a new state-of-the-art on WinoGrande, CODAH, and CommonsenseQA. Further, in addition to improvements in in-distribution accuracy, G-DAUG-augmented training also enhances out-of-distribution generalization, showing greater robustness against adversarial or perturbed examples. Our analysis demonstrates that G-DAUG produces a diverse set of fluent training examples, and that its selection and training approaches are important for performance. Our findings encourage future research toward generative data augmentation to enhance both in-distribution learning and out-of-distribution generalization.