 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMET-ATOMIC 2020: On Symbolic and Neural Commonsense Knowledge Graphs
Paper and Code
Oct 12, 2020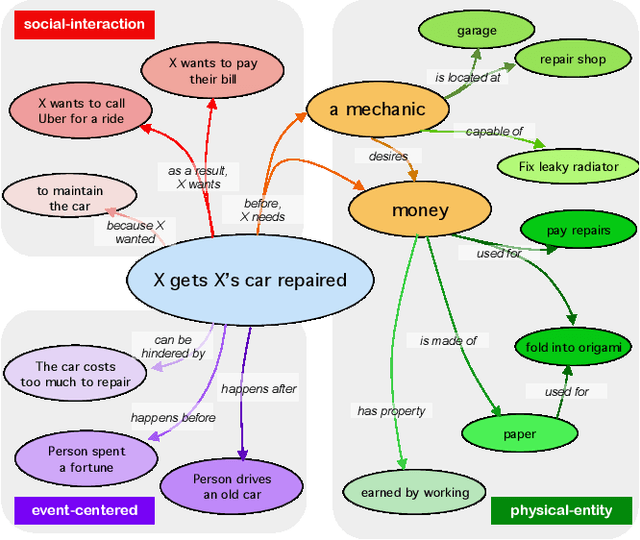
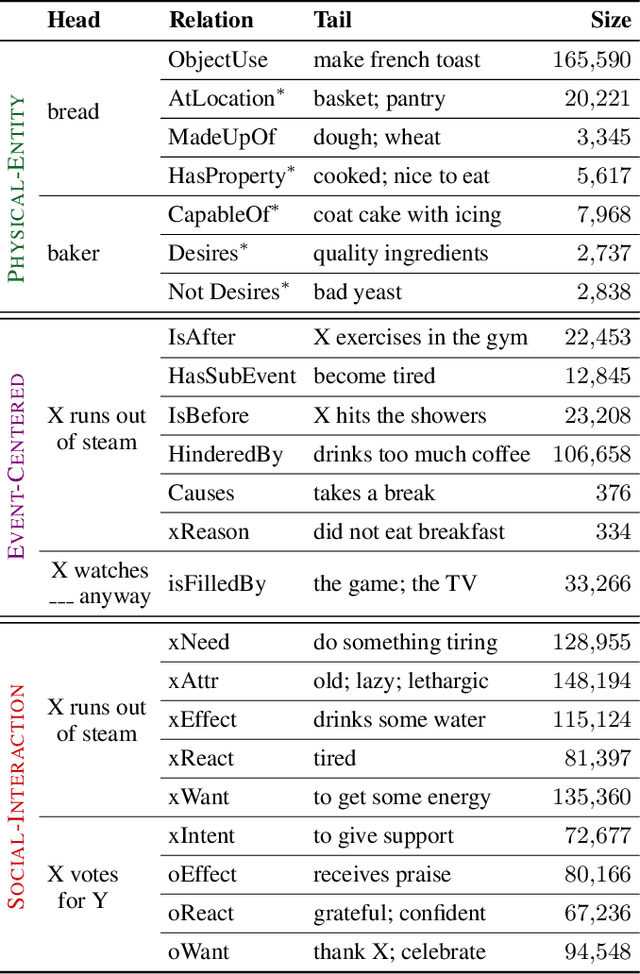
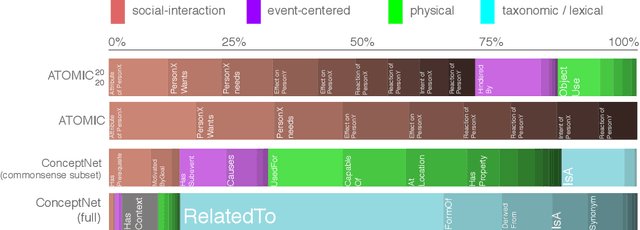
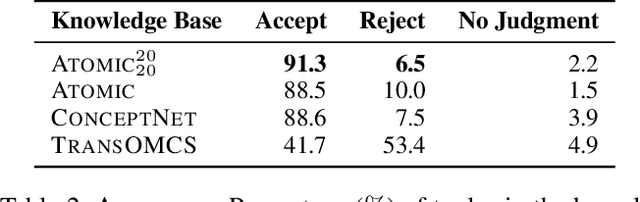
Recent years have brought about a renewed interest in commonsense representation and reasoning in the field of natural language understanding. The development of new commonsense knowledge graphs (CSKG) has been central to these advances as their diverse facts can be used and referenced by machine learning models for tackling new and challenging tasks. At the same time, there remain questions about the quality and coverage of these resources due to the massive scale required to comprehensively encompass general commonsense knowledge. In this work, we posit that manually constructed CSKGs will never achieve the coverage necessary to be applicable in all situations encountered by NLP agents. Therefore, we propose a new evaluation framework for testing the utility of KGs based on how effectively implicit knowledge representations can be learned from them. With this new goal, we propose ATOMIC 2020, a new CSKG of general-purpose commonsense knowledge containing knowledge that is not readily available in pretrained language models. We evaluate its properties in comparison with other leading CSKGs, performing the first large-scale pairwise study of commonsense knowledge resources. Next, we show that ATOMIC 2020 is better suited for training knowledge models that can generate accurate, representative knowledge for new, unseen entities and events. Finally, through human evaluation, we show that the few-shot performance of GPT-3 (175B parameters), while impressive, remains ~12 absolute points lower than a BART-based knowledge model trained on ATOMIC 2020 despite using over 430x fewer parameters.