 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Rationales with Full-Stack Visual Reasoning: From Pixels to Semantic Frames to Commonsense Graphs
Paper and Code
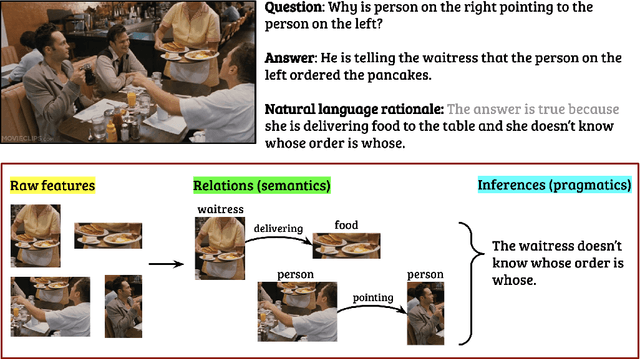
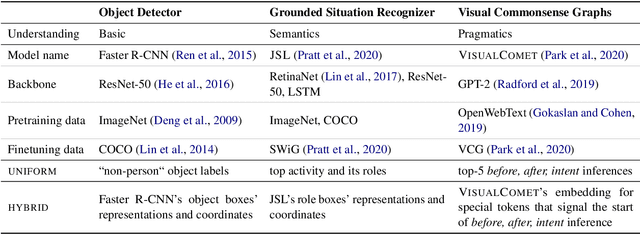
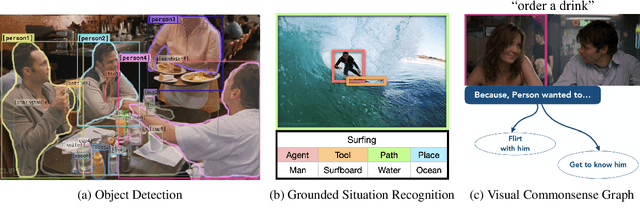
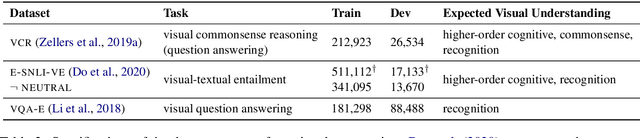
Natural language rationales could provide intuitive, higher-level explanations that are easily understandable by humans, complementing the more broadly studied lower-level explanations based on gradients or attention weights. We present the first study focused on generating natural language rationales across several complex visual reasoning tasks: visual commonsense reasoning, visual-textual entailment, and visual question answering. The key challenge of accurate rationalization is comprehensive image understanding at all levels: not just their explicit content at the pixel level, but their contextual contents at the semantic and pragmatic levels. We present Rationale^VT Transformer, an integrated model that learns to generate free-text rationales by combining pretrained language models with object recognition, grounded visual semantic frames, and visual commonsense graphs. Our experiments show that the base pretrained language model benefits from visual adaptation and that free-text rationalization is a promising research direction to complement model interpretability for complex visual-textual reasoning tasks.