 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Dynamics and $Φ$-Regret Minimization in Games
Jun 28, 2021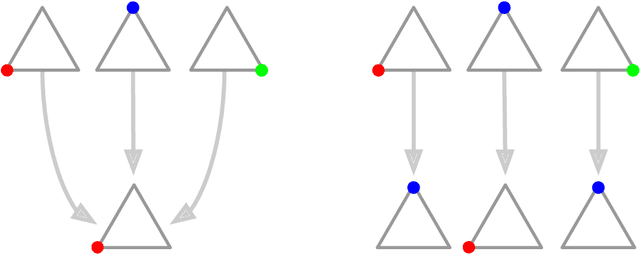
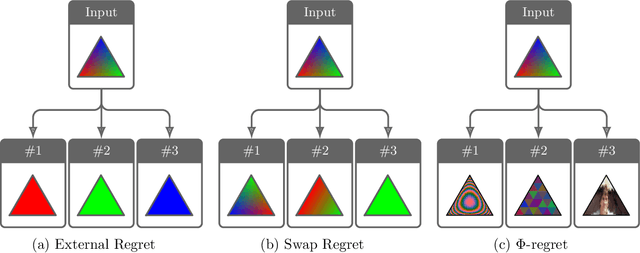
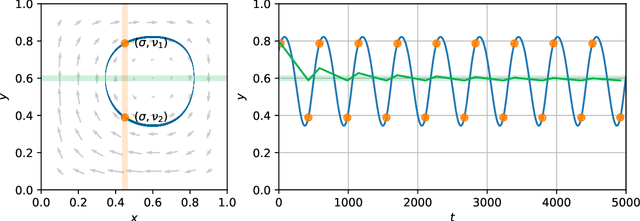
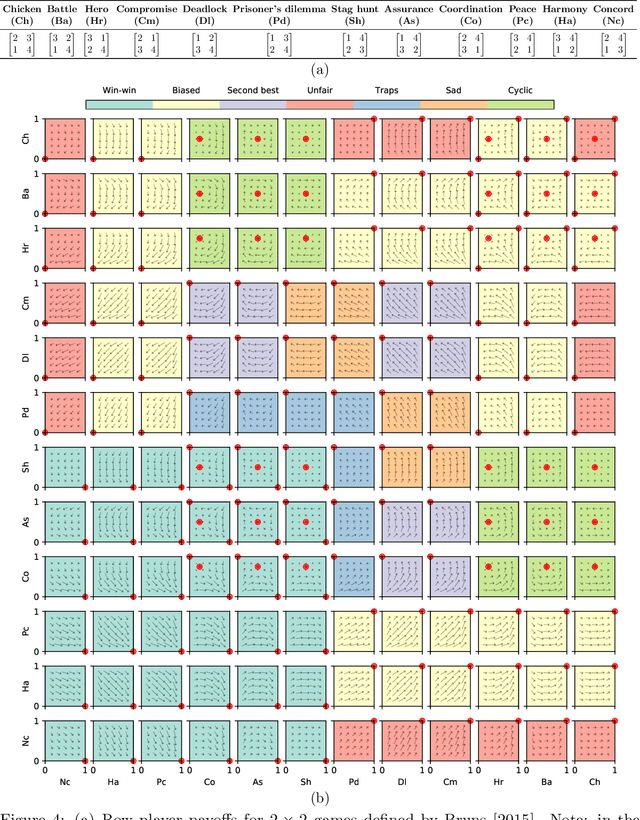
Regret has been established as a foundational concept in online learning, and likewise has important applications in the analysis of learning dynamics in games. Regret quantifies the difference between a learner's performance against a baseline in hindsight. It is well-known that regret-minimizing algorithms converge to certain classes of equilibria in games; however, traditional forms of regret used in game theory predominantly consider baselines that permit deviations to deterministic actions or strategies. In this paper, we revisit our understanding of regret from the perspective of deviations over partitions of the full \emph{mixed} strategy space (i.e., probability distributions over pure strategies), under the lens of the previously-established $\Phi$-regret framework, which provides a continuum of stronger regret measures. Importantly, $\Phi$-regret enables learning agents to consider deviations from and to mixed strategies, generalizing several existing notions of regret such as external, internal, and swap regret, and thus broadening the insights gained from regret-based analysis of learning algorithms. We prove here that the well-studied evolutionary learning algorithm of replicator dynamics (RD) seamlessly minimizes the strongest possible form of $\Phi$-regret in generic $2 \times 2$ games, without any modification of the underlying algorithm itself. We subsequently conduct experiments validating our theoretical results in a suite of 144 $2 \times 2$ games wherein RD exhibits a diverse set of behaviors. We conclude by providing empirical evidence of $\Phi$-regret minimization by RD in some larger games, hinting at further opportunity for $\Phi$-regret based study of such algorithms from both a theoretical and empirical perspective.
Concave Utility Reinforcement Learning: the Mean-field Game viewpoint
Jun 09, 2021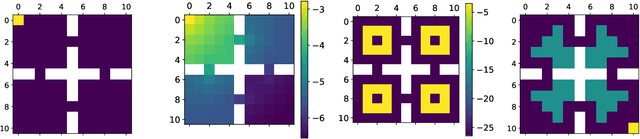
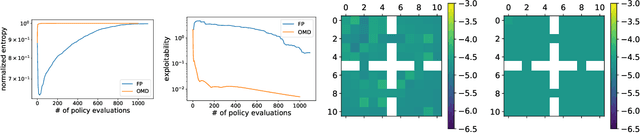
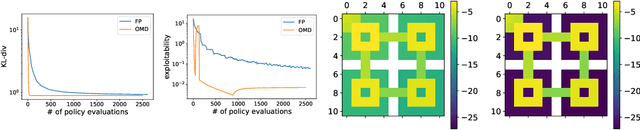

Concave Utility Reinforcement Learning (CURL) extends RL from linear to concave utilities in the occupancy measure induced by the agent's policy. This encompasses not only RL but also imitation learning and exploration, among others. Yet, this more general paradigm invalidates the classical Bellman equations, and calls for new algorithms. Mean-field Games (MFGs) are a continuous approximation of many-agent RL. They consider the limit case of a continuous distribution of identical agents, anonymous with symmetric interests, and reduce the problem to the study of a single representative agent in interaction with the full population. Our core contribution consists in showing that CURL is a subclass of MFGs. We think this important to bridge together both communities. It also allows to shed light on aspects of both fields: we show the equivalence between concavity in CURL and monotonicity in the associated MFG, between optimality conditions in CURL and Nash equilibrium in MFG, or that Fictitious Play (FP) for this class of MFGs is simply Frank-Wolfe, bringing the first convergence rate for discrete-time FP for MFGs. We also experimentally demonstrate that, using algorithms recently introduced for solving MFGs, we can address the CURL problem more efficiently.
Time-series Imputation of Temporally-occluded Multiagent Trajectories
Jun 08, 2021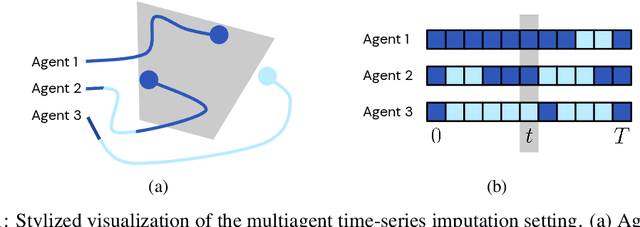
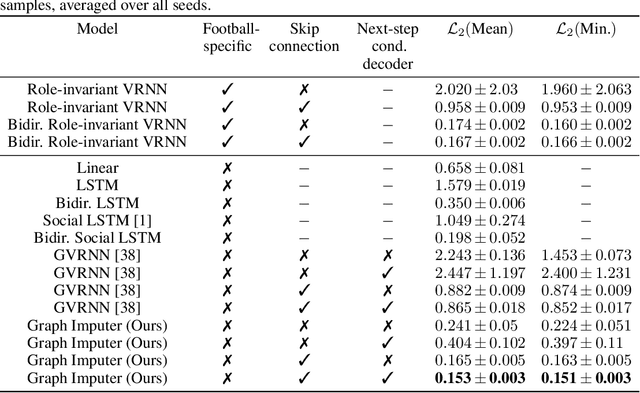
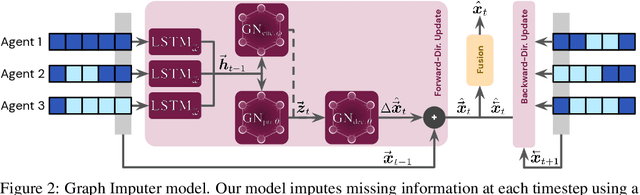
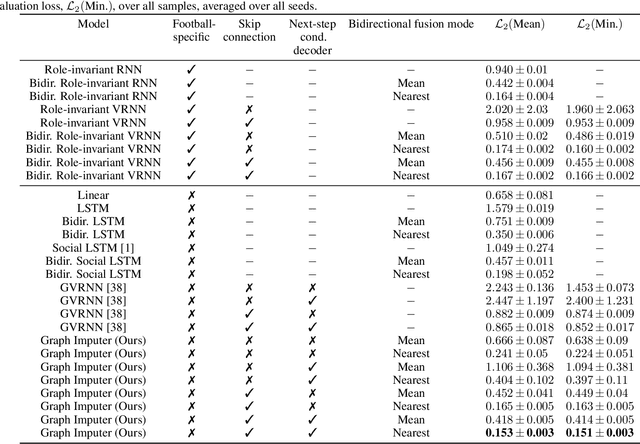
In multiagent environments, several decision-making individuals interact while adhering to the dynamics constraints imposed by the environment. These interactions, combined with the potential stochasticity of the agents' decision-making processes, make such systems complex and interesting to study from a dynamical perspective. Significant research has been conducted on learning models for forward-direction estimation of agent behaviors, for example, pedestrian predictions used for collision-avoidance in self-driving cars. However, in many settings, only sporadic observations of agents may be available in a given trajectory sequence. For instance, in football, subsets of players may come in and out of view of broadcast video footage, while unobserved players continue to interact off-screen. In this paper, we study the problem of multiagent time-series imputation, where available past and future observations of subsets of agents are used to estimate missing observations for other agents. Our approach, called the Graph Imputer, uses forward- and backward-information in combination with graph networks and variational autoencoders to enable learning of a distribution of imputed trajectories. We evaluate our approach on a dataset of football matches, using a projective camera module to train and evaluate our model for the off-screen player state estimation setting. We illustrate that our method outperforms several state-of-the-art approaches, including those hand-crafted for football.
Scaling up Mean Field Games with Online Mirror Descent
Feb 28, 2021
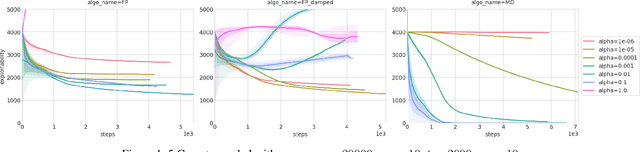

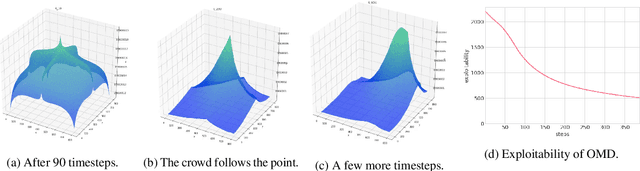
We address scaling up equilibrium computation in Mean Field Games (MFGs) using Online Mirror Descent (OMD). We show that continuous-time OMD provably converges to a Nash equilibrium under a natural and well-motivated set of monotonicity assumptions. This theoretical result nicely extends to multi-population games and to settings involving common noise. A thorough experimental investigation on various single and multi-population MFGs shows that OMD outperforms traditional algorithms such as Fictitious Play (FP). We empirically show that OMD scales up and converges significantly faster than FP by solving, for the first time to our knowledge, examples of MFGs with hundreds of billions states. This study establishes the state-of-the-art for learning in large-scale multi-agent and multi-population games.
Conditional Versus Adversarial Euler-based Generators For Time Series
Feb 10, 2021
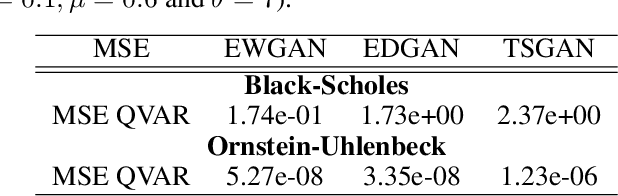

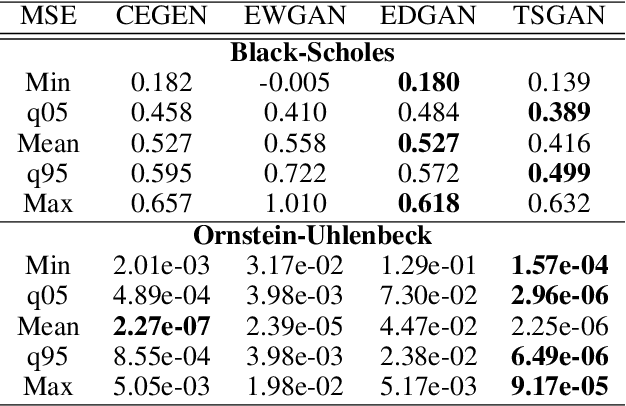
We introduce new generative models for time series based on Euler discretization that do not require any pre-stationarization procedure. Specifically, we develop two GAN based methods, relying on the adaptation of Wasserstein GANs (Arjovsky et al., 2017) and DVD GANs (Clark et al., 2019b) to time series. Alternatively, we consider a conditional Euler Generator (CEGEN) minimizing a distance between the induced conditional densities. In the context of It\^o processes, we theoretically validate this approach and demonstrate using the Bures metric that reaching a low loss level provides accurate estimations for both the drift and the volatility terms of the underlying process. Tests on simple models show how the Euler discretization and the use of Wasserstein distance allow the proposed GANs and (more considerably) CEGEN to outperform state-of-the-art Time Series GAN generation( Yoon et al., 2019b) on time structure metrics. In higher dimensions we observe that CEGEN manages to get the correct covariance structures. Finally we illustrate how our model can be combined to a Monte Carlo simulator in a low data context by using a transfer learning technique
Game Plan: What AI can do for Football, and What Football can do for AI
Nov 18, 2020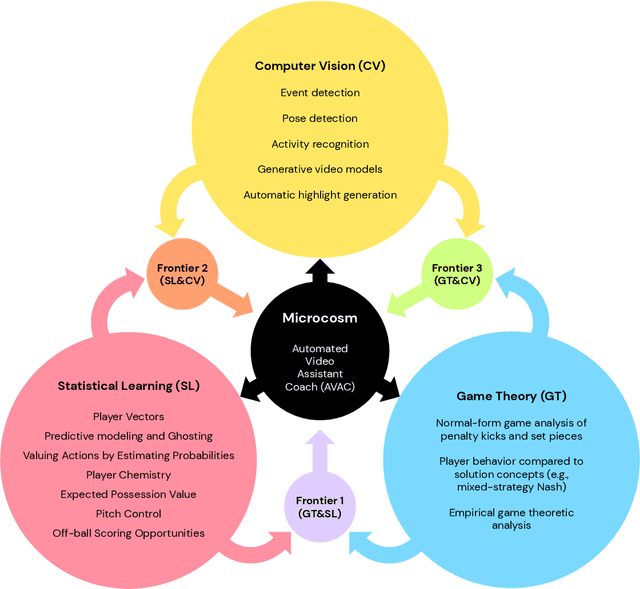



The rapid progress in artificial intelligence (AI) and machine learning has opened unprecedented analytics possibilities in various team and individual sports, including baseball, basketball, and tennis. More recently, AI techniques have been applied to football, due to a huge increase in data collection by professional teams, increased computational power, and advances in machine learning, with the goal of better addressing new scientific challenges involved in the analysis of both individual players' and coordinated teams' behaviors. The research challenges associated with predictive and prescriptive football analytics require new developments and progress at the intersection of statistical learning, game theory, and computer vision. In this paper, we provide an overarching perspective highlighting how the combination of these fields, in particular, forms a unique microcosm for AI research, while offering mutual benefits for professional teams, spectators, and broadcasters in the years to come. We illustrate that this duality makes football analytics a game changer of tremendous value, in terms of not only changing the game of football itself, but also in terms of what this domain can mean for the field of AI. We review the state-of-the-art and exemplify the types of analysis enabled by combining the aforementioned fields, including illustrative examples of counterfactual analysis using predictive models, and the combination of game-theoretic analysis of penalty kicks with statistical learning of player attributes. We conclude by highlighting envisioned downstream impacts, including possibilities for extensions to other sports (real and virtual).
Fictitious Play for Mean Field Games: Continuous Time Analysis and Applications
Jul 05, 2020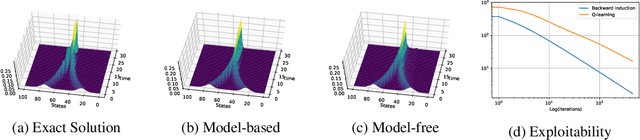
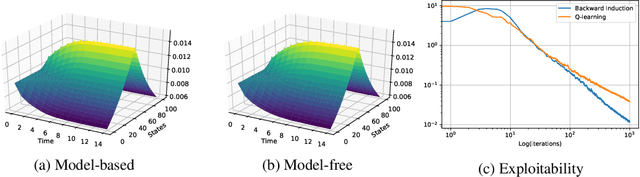
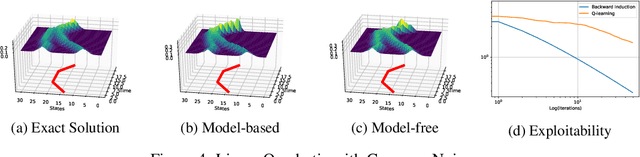
In this paper, we deepen the analysis of continuous time Fictitious Play learning algorithm to the consideration of various finite state Mean Field Game settings (finite horizon, $\gamma$-discounted), allowing in particular for the introduction of an additional common noise. We first present a theoretical convergence analysis of the continuous time Fictitious Play process and prove that the induced exploitability decreases at a rate $O(\frac{1}{t})$. Such analysis emphasizes the use of exploitability as a relevant metric for evaluating the convergence towards a Nash equilibrium in the context of Mean Field Games. These theoretical contributions are supported by numerical experiments provided in either model-based or model-free settings. We provide hereby for the first time converging learning dynamics for Mean Field Games in the presence of common noise.
Reinforcement Learning in Economics and Finance
Mar 22, 2020
Reinforcement learning algorithms describe how an agent can learn an optimal action policy in a sequential decision process, through repeated experience. In a given environment, the agent policy provides him some running and terminal rewards. As in online learning, the agent learns sequentially. As in multi-armed bandit problems, when an agent picks an action, he can not infer ex-post the rewards induced by other action choices. In reinforcement learning, his actions have consequences: they influence not only rewards, but also future states of the world. The goal of reinforcement learning is to find an optimal policy -- a mapping from the states of the world to the set of actions, in order to maximize cumulative reward, which is a long term strategy. Exploring might be sub-optimal on a short-term horizon but could lead to optimal long-term ones. Many problems of optimal control, popular in economics for more than forty years, can be expressed in the reinforcement learning framework, and recent advances in computational science, provided in particular by deep learning algorithms, can be used by economists in order to solve complex behavioral problems. In this article, we propose a state-of-the-art of reinforcement learning techniques, and present applications in economics, game theory, operation research and finance.
Approximate Fictitious Play for Mean Field Games
Jul 04, 2019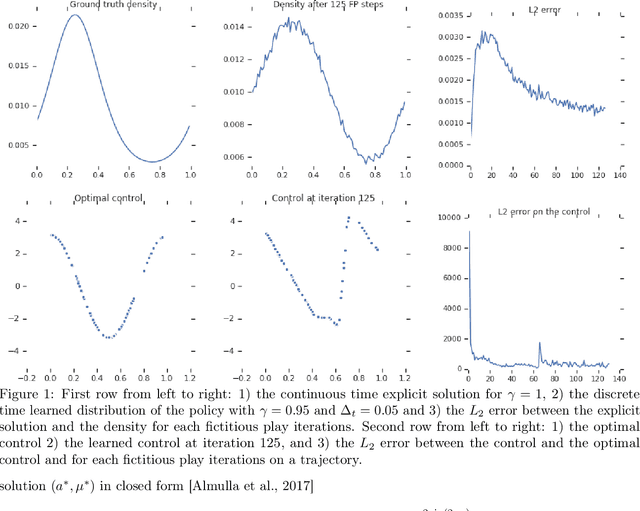
The theory of Mean Field Games (MFG) allows characterizing the Nash equilibria of an infinite number of identical players, and provides a convenient and relevant mathematical framework for the study of games with a large number of agents in interaction. Until very recently, the literature only considered Nash equilibria between fully informed players. In this paper, we focus on the realistic setting where agents with no prior information on the game learn their best response policy through repeated experience. We study the convergence to a (possibly approximate) Nash equilibrium of a fictitious play iterative learning scheme where the best response is approximately computed, typically by a reinforcement learning (RL) algorithm. Notably, we show for the first time convergence of model free learning algorithms towards non-stationary MFG equilibria, relying only on classical assumptions on the MFG dynamics. We illustrate our theoretical results with a numerical experiment in continuous action-space setting, where the best response of the iterative fictitious play scheme is computed with a deep RL algorithm.