 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust Do It!? Computer-Use Agents Exhibit Blind Goal-Directedness
Oct 02, 2025



Computer-Use Agents (CUAs) are an increasingly deployed class of agents that take actions on GUIs to accomplish user goals. In this paper, we show that CUAs consistently exhibit Blind Goal-Directedness (BGD): a bias to pursue goals regardless of feasibility, safety, reliability, or context. We characterize three prevalent patterns of BGD: (i) lack of contextual reasoning, (ii) assumptions and decisions under ambiguity, and (iii) contradictory or infeasible goals. We develop BLIND-ACT, a benchmark of 90 tasks capturing these three patterns. Built on OSWorld, BLIND-ACT provides realistic environments and employs LLM-based judges to evaluate agent behavior, achieving 93.75% agreement with human annotations. We use BLIND-ACT to evaluate nine frontier models, including Claude Sonnet and Opus 4, Computer-Use-Preview, and GPT-5, observing high average BGD rates (80.8%) across them. We show that BGD exposes subtle risks that arise even when inputs are not directly harmful. While prompting-based interventions lower BGD levels, substantial risk persists, highlighting the need for stronger training- or inference-time interventions. Qualitative analysis reveals observed failure modes: execution-first bias (focusing on how to act over whether to act), thought-action disconnect (execution diverging from reasoning), and request-primacy (justifying actions due to user request). Identifying BGD and introducing BLIND-ACT establishes a foundation for future research on studying and mitigating this fundamental risk and ensuring safe CUA deployment.
Lessons From Red Teaming 100 Generative AI Products
Jan 13, 2025In recent years, AI red teaming has emerged as a practice for probing the safety and security of generative AI systems. Due to the nascency of the field, there are many open questions about how red teaming operations should be conducted. Based on our experience red teaming over 100 generative AI products at Microsoft, we present our internal threat model ontology and eight main lessons we have learned: 1. Understand what the system can do and where it is applied 2. You don't have to compute gradients to break an AI system 3. AI red teaming is not safety benchmarking 4. Automation can help cover more of the risk landscape 5. The human element of AI red teaming is crucial 6. Responsible AI harms are pervasive but difficult to measure 7. LLMs amplify existing security risks and introduce new ones 8. The work of securing AI systems will never be complete By sharing these insights alongside case studies from our operations, we offer practical recommendations aimed at aligning red teaming efforts with real world risks. We also highlight aspects of AI red teaming that we believe are often misunderstood and discuss open questions for the field to consider.
PyRIT: A Framework for Security Risk Identification and Red Teaming in Generative AI System
Oct 01, 2024



Generative Artificial Intelligence (GenAI) is becoming ubiquitous in our daily lives. The increase in computational power and data availability has led to a proliferation of both single- and multi-modal models. As the GenAI ecosystem matures, the need for extensible and model-agnostic risk identification frameworks is growing. To meet this need, we introduce the Python Risk Identification Toolkit (PyRIT), an open-source framework designed to enhance red teaming efforts in GenAI systems. PyRIT is a model- and platform-agnostic tool that enables red teamers to probe for and identify novel harms, risks, and jailbreaks in multimodal generative AI models. Its composable architecture facilitates the reuse of core building blocks and allows for extensibility to future models and modalities. This paper details the challenges specific to red teaming generative AI systems, the development and features of PyRIT, and its practical applications in real-world scenarios.
Phi-3 Safety Post-Training: Aligning Language Models with a "Break-Fix" Cycle
Jul 18, 2024



Recent innovations in language model training have demonstrated that it is possible to create highly performant models that are small enough to run on a smartphone. As these models are deployed in an increasing number of domains, it is critical to ensure that they are aligned with human preferences and safety considerations. In this report, we present our methodology for safety aligning the Phi-3 series of language models. We utilized a "break-fix" cycle, performing multiple rounds of dataset curation, safety post-training, benchmarking, red teaming, and vulnerability identification to cover a variety of harm areas in both single and multi-turn scenarios. Our results indicate that this approach iteratively improved the performance of the Phi-3 models across a wide range of responsible AI benchmarks.
A Framework for Automated Measurement of Responsible AI Harms in Generative AI Applications
Oct 26, 2023



We present a framework for the automated measurement of responsible AI (RAI) metrics for large language models (LLMs) and associated products and services. Our framework for automatically measuring harms from LLMs builds on existing technical and sociotechnical expertise and leverages the capabilities of state-of-the-art LLMs, such as GPT-4. We use this framework to run through several case studies investigating how different LLMs may violate a range of RAI-related principles. The framework may be employed alongside domain-specific sociotechnical expertise to create measurements for new harm areas in the future. By implementing this framework, we aim to enable more advanced harm measurement efforts and further the responsible use of LLMs.
Fairlearn: Assessing and Improving Fairness of AI Systems
Mar 29, 2023Fairlearn is an open source project to help practitioners assess and improve fairness of artificial intelligence (AI) systems. The associated Python library, also named fairlearn, supports evaluation of a model's output across affected populations and includes several algorithms for mitigating fairness issues. Grounded in the understanding that fairness is a sociotechnical challenge, the project integrates learning resources that aid practitioners in considering a system's broader societal context.
NFL Play Prediction
Jan 04, 2016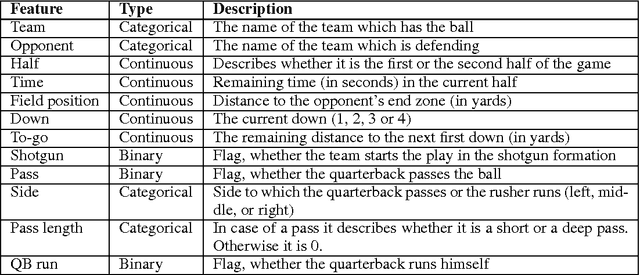

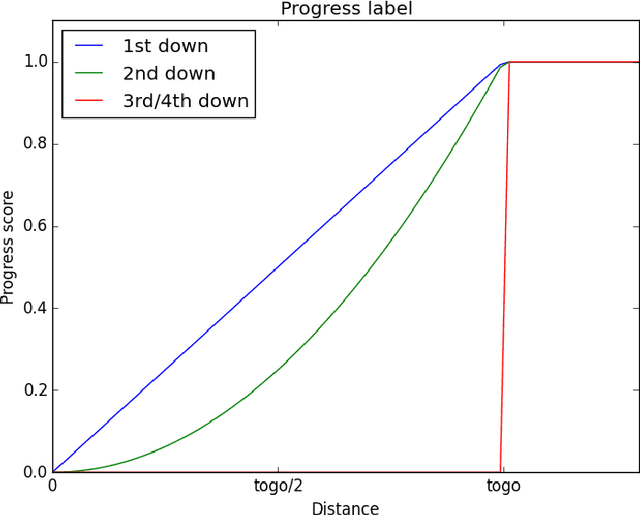
Based on NFL game data we try to predict the outcome of a play in multiple different ways. An application of this is the following: by plugging in various play options one could determine the best play for a given situation in real time. While the outcome of a play can be described in many ways we had the most promising results with a newly defined measure that we call "progress". We see this work as a first step to include predictive analysis into NFL playcalling.
Fantasy Football Prediction
May 26, 2015
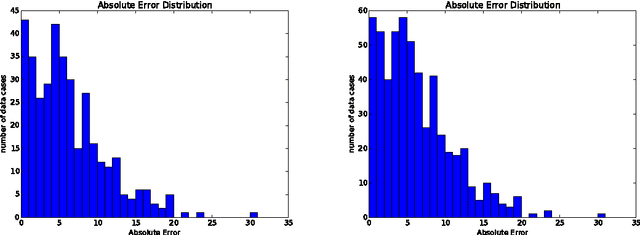
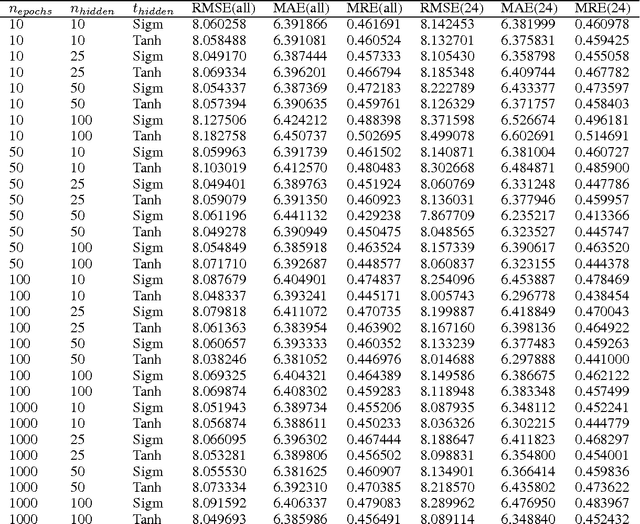
The ubiquity of professional sports and specifically the NFL have lead to an increase in popularity for Fantasy Football. Users have many tools at their disposal: statistics, predictions, rankings of experts and even recommendations of peers. There are issues with all of these, though. Especially since many people pay money to play, the prediction tools should be enhanced as they provide unbiased and easy-to-use assistance for users. This paper provides and discusses approaches to predict Fantasy Football scores of Quarterbacks with relatively limited data. In addition to that, it includes several suggestions on how the data could be enhanced to achieve better results. The dataset consists only of game data from the last six NFL seasons. I used two different methods to predict the Fantasy Football scores of NFL players: Support Vector Regression (SVR) and Neural Networks. The results of both are promising given the limited data that was used.