 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoLux-GAN: A Generative Model for 3D Face Synthesis with HDRI Relighting
Jan 13, 2022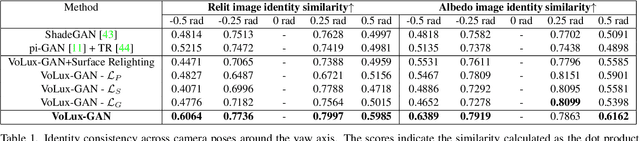
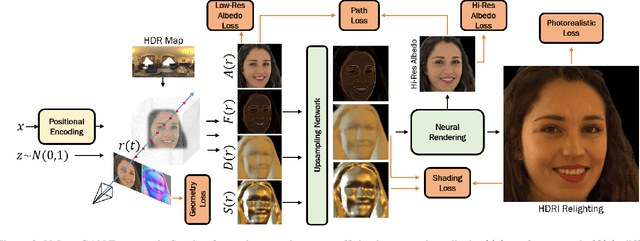
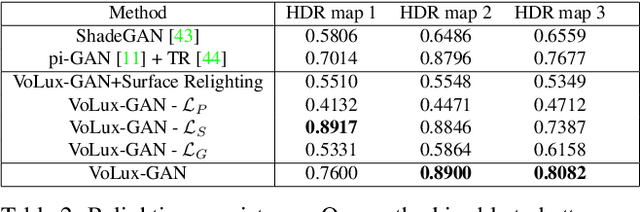

We propose VoLux-GAN, a generative framework to synthesize 3D-aware faces with convincing relighting. Our main contribution is a volumetric HDRI relighting method that can efficiently accumulate albedo, diffuse and specular lighting contributions along each 3D ray for any desired HDR environmental map. Additionally, we show the importance of supervising the image decomposition process using multiple discriminators. In particular, we propose a data augmentation technique that leverages recent advances in single image portrait relighting to enforce consistent geometry, albedo, diffuse and specular components. Multiple experiments and comparisons with other generative frameworks show how our model is a step forward towards photorealistic relightable 3D generative models.
HumanGPS: Geodesic PreServing Feature for Dense Human Correspondences
Mar 29, 2021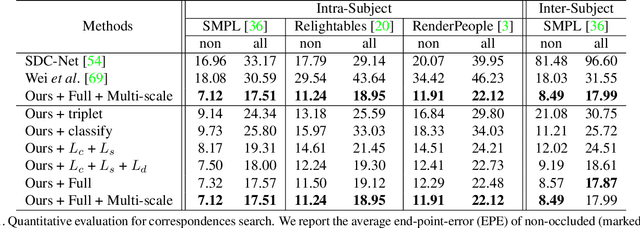
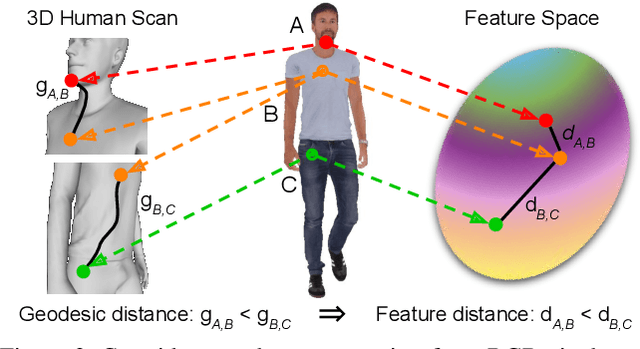
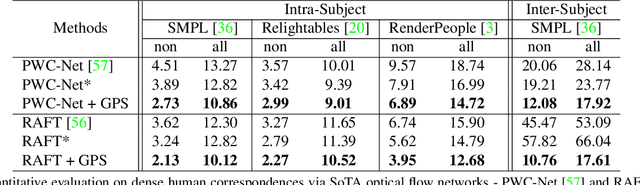
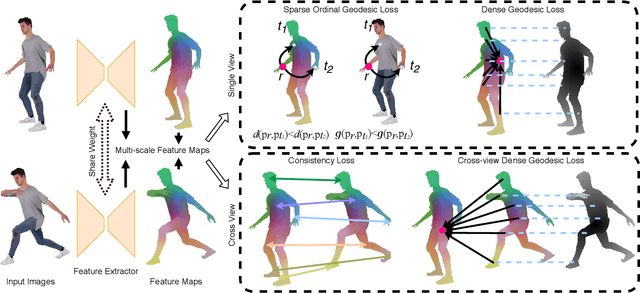
In this paper, we address the problem of building dense correspondences between human images under arbitrary camera viewpoints and body poses. Prior art either assumes small motion between frames or relies on local descriptors, which cannot handle large motion or visually ambiguous body parts, e.g., left vs. right hand. In contrast, we propose a deep learning framework that maps each pixel to a feature space, where the feature distances reflect the geodesic distances among pixels as if they were projected onto the surface of a 3D human scan. To this end, we introduce novel loss functions to push features apart according to their geodesic distances on the surface. Without any semantic annotation, the proposed embeddings automatically learn to differentiate visually similar parts and align different subjects into an unified feature space. Extensive experiments show that the learned embeddings can produce accurate correspondences between images with remarkable generalization capabilities on both intra and inter subjects.
Neural Light Transport for Relighting and View Synthesis
Aug 20, 2020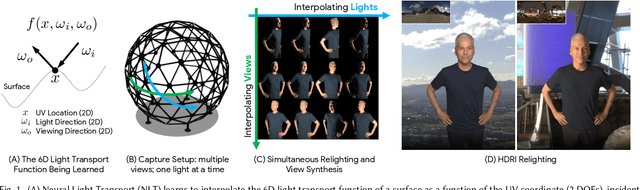

The light transport (LT) of a scene describes how it appears under different lighting and viewing directions, and complete knowledge of a scene's LT enables the synthesis of novel views under arbitrary lighting. In this paper, we focus on image-based LT acquisition, primarily for human bodies within a light stage setup. We propose a semi-parametric approach to learn a neural representation of LT that is embedded in the space of a texture atlas of known geometric properties, and model all non-diffuse and global LT as residuals added to a physically-accurate diffuse base rendering. In particular, we show how to fuse previously seen observations of illuminants and views to synthesize a new image of the same scene under a desired lighting condition from a chosen viewpoint. This strategy allows the network to learn complex material effects (such as subsurface scattering) and global illumination, while guaranteeing the physical correctness of the diffuse LT (such as hard shadows). With this learned LT, one can relight the scene photorealistically with a directional light or an HDRI map, synthesize novel views with view-dependent effects, or do both simultaneously, all in a unified framework using a set of sparse, previously seen observations. Qualitative and quantitative experiments demonstrate that our neural LT (NLT) outperforms state-of-the-art solutions for relighting and view synthesis, without separate treatment for both problems that prior work requires.
GeLaTO: Generative Latent Textured Objects
Aug 11, 2020
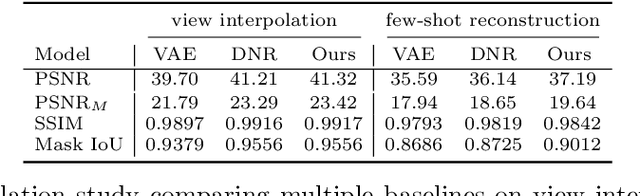

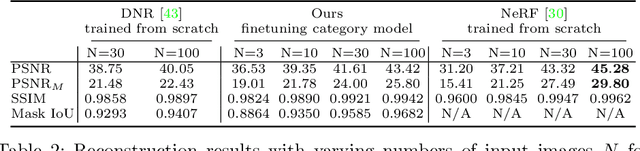
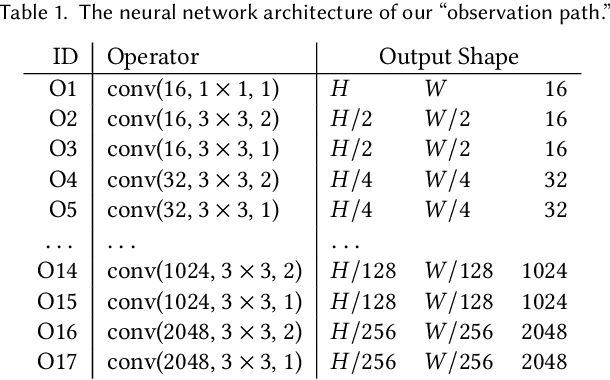
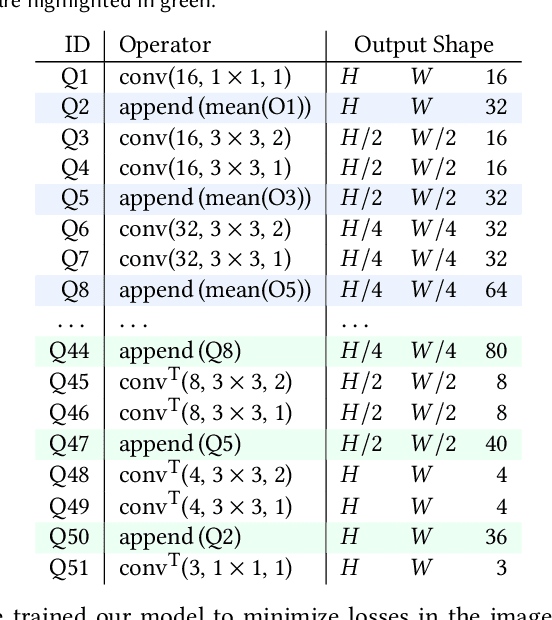
Accurate modeling of 3D objects exhibiting transparency, reflections and thin structures is an extremely challenging problem. Inspired by billboards and geometric proxies used in computer graphics, this paper proposes Generative Latent Textured Objects (GeLaTO), a compact representation that combines a set of coarse shape proxies defining low frequency geometry with learned neural textures, to encode both medium and fine scale geometry as well as view-dependent appearance. To generate the proxies' textures, we learn a joint latent space allowing category-level appearance and geometry interpolation. The proxies are independently rasterized with their corresponding neural texture and composited using a U-Net, which generates an output photorealistic image including an alpha map. We demonstrate the effectiveness of our approach by reconstructing complex objects from a sparse set of views. We show results on a dataset of real images of eyeglasses frames, which are particularly challenging to reconstruct using classical methods. We also demonstrate that these coarse proxies can be handcrafted when the underlying object geometry is easy to model, like eyeglasses, or generated using a neural network for more complex categories, such as cars.
* ECCV 2020 Spotlight. Project website: https://gelato-paper.github.io
Learning Illumination from Diverse Portraits
Aug 05, 2020
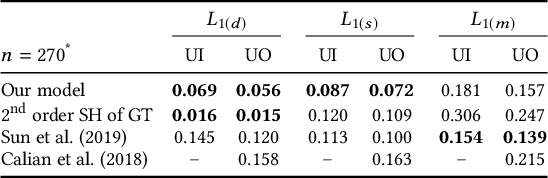
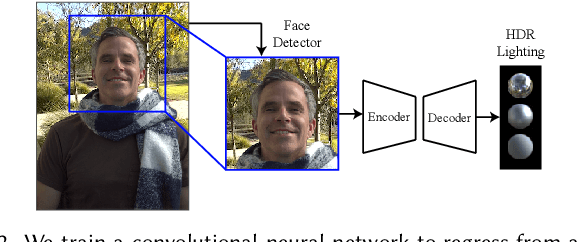
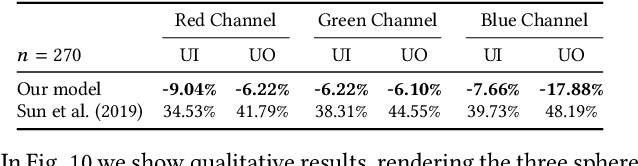
We present a learning-based technique for estimating high dynamic range (HDR), omnidirectional illumination from a single low dynamic range (LDR) portrait image captured under arbitrary indoor or outdoor lighting conditions. We train our model using portrait photos paired with their ground truth environmental illumination. We generate a rich set of such photos by using a light stage to record the reflectance field and alpha matte of 70 diverse subjects in various expressions. We then relight the subjects using image-based relighting with a database of one million HDR lighting environments, compositing the relit subjects onto paired high-resolution background imagery recorded during the lighting acquisition. We train the lighting estimation model using rendering-based loss functions and add a multi-scale adversarial loss to estimate plausible high frequency lighting detail. We show that our technique outperforms the state-of-the-art technique for portrait-based lighting estimation, and we also show that our method reliably handles the inherent ambiguity between overall lighting strength and surface albedo, recovering a similar scale of illumination for subjects with diverse skin tones. We demonstrate that our method allows virtual objects and digital characters to be added to a portrait photograph with consistent illumination. Our lighting inference runs in real-time on a smartphone, enabling realistic rendering and compositing of virtual objects into live video for augmented reality applications.
Portrait Shadow Manipulation
May 20, 2020
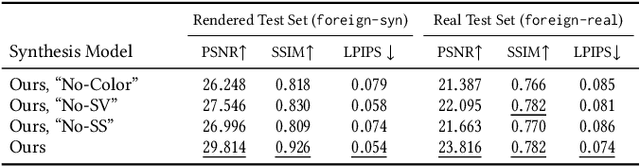
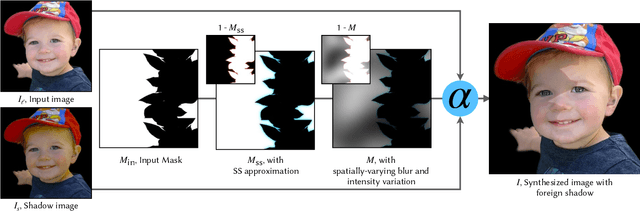
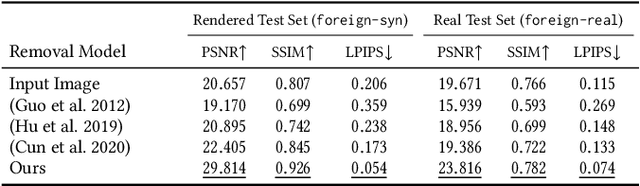
Casually-taken portrait photographs often suffer from unflattering lighting and shadowing because of suboptimal conditions in the environment. Aesthetic qualities such as the position and softness of shadows and the lighting ratio between the bright and dark parts of the face are frequently determined by the constraints of the environment rather than by the photographer. Professionals address this issue by adding light shaping tools such as scrims, bounce cards, and flashes. In this paper, we present a computational approach that gives casual photographers some of this control, thereby allowing poorly-lit portraits to be relit post-capture in a realistic and easily-controllable way. Our approach relies on a pair of neural networks---one to remove foreign shadows cast by external objects, and another to soften facial shadows cast by the features of the subject and to add a synthetic fill light to improve the lighting ratio. To train our first network we construct a dataset of real-world portraits wherein synthetic foreign shadows are rendered onto the face, and we show that our network learns to remove those unwanted shadows. To train our second network we use a dataset of Light Stage scans of human subjects to construct input/output pairs of input images harshly lit by a small light source, and variably softened and fill-lit output images of each face. We propose a way to explicitly encode facial symmetry and show that our dataset and training procedure enable the model to generalize to images taken in the wild. Together, these networks enable the realistic and aesthetically pleasing enhancement of shadows and lights in real-world portrait images
State of the Art on Neural Rendering
Apr 08, 2020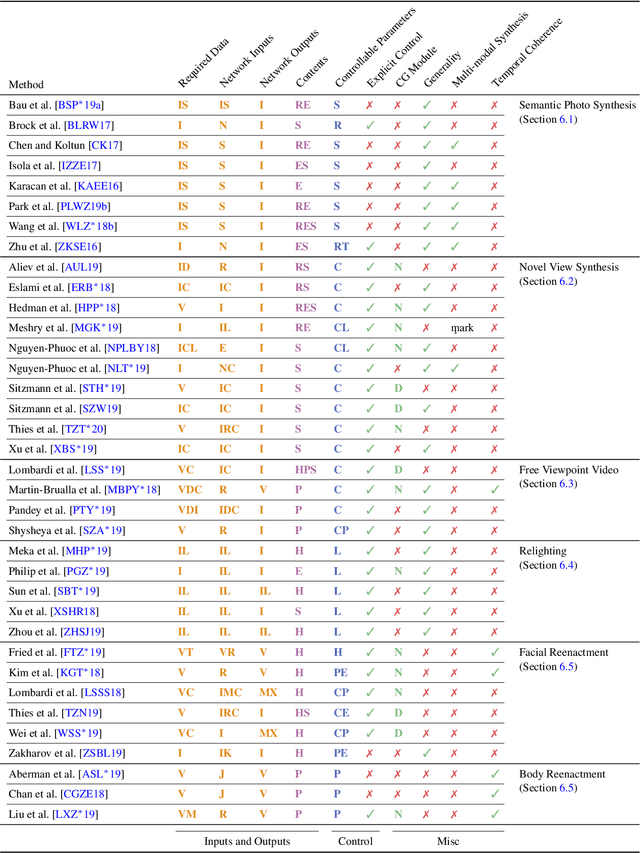



Efficient rendering of photo-realistic virtual worlds is a long standing effort of computer graphics. Modern graphics techniques have succeeded in synthesizing photo-realistic images from hand-crafted scene representations. However, the automatic generation of shape, materials, lighting, and other aspects of scenes remains a challenging problem that, if solved, would make photo-realistic computer graphics more widely accessible. Concurrently, progress in computer vision and machine learning have given rise to a new approach to image synthesis and editing, namely deep generative models. Neural rendering is a new and rapidly emerging field that combines generative machine learning techniques with physical knowledge from computer graphics, e.g., by the integration of differentiable rendering into network training. With a plethora of applications in computer graphics and vision, neural rendering is poised to become a new area in the graphics community, yet no survey of this emerging field exists. This state-of-the-art report summarizes the recent trends and applications of neural rendering. We focus on approaches that combine classic computer graphics techniques with deep generative models to obtain controllable and photo-realistic outputs. Starting with an overview of the underlying computer graphics and machine learning concepts, we discuss critical aspects of neural rendering approaches. This state-of-the-art report is focused on the many important use cases for the described algorithms such as novel view synthesis, semantic photo manipulation, facial and body reenactment, relighting, free-viewpoint video, and the creation of photo-realistic avatars for virtual and augmented reality telepresence. Finally, we conclude with a discussion of the social implications of such technology and investigate open research problems.
Breaking hypothesis testing for failure rates
Jan 13, 2020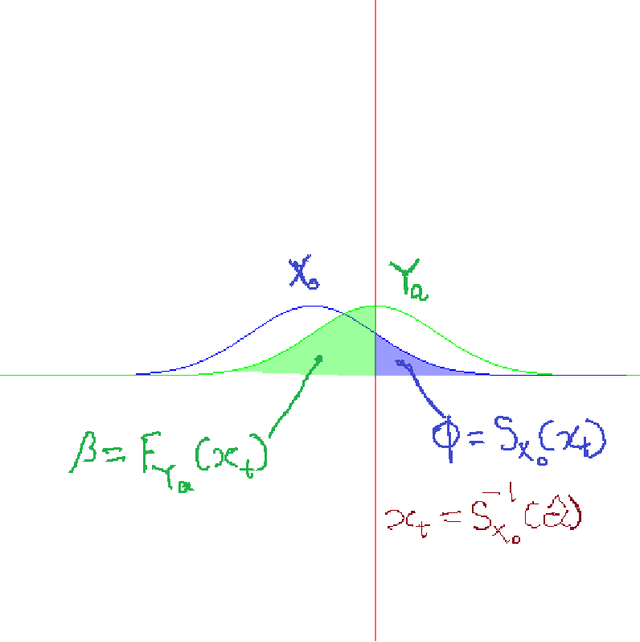
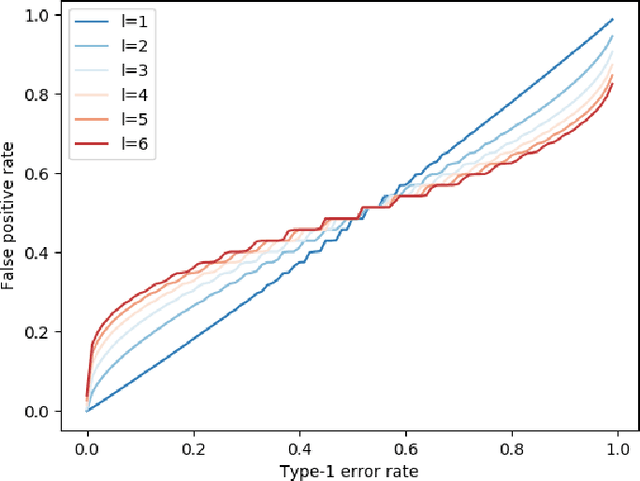
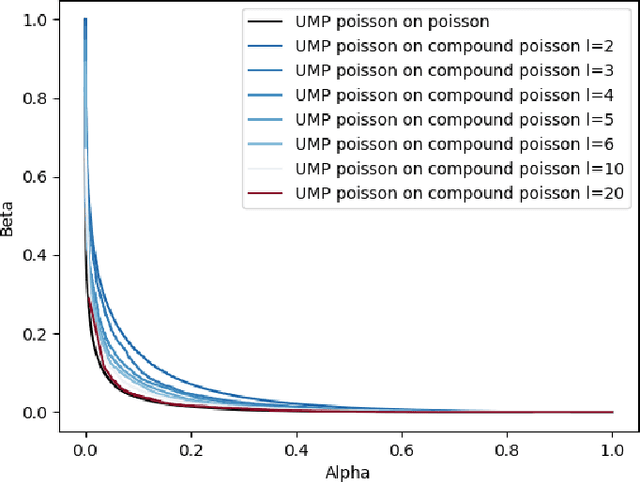
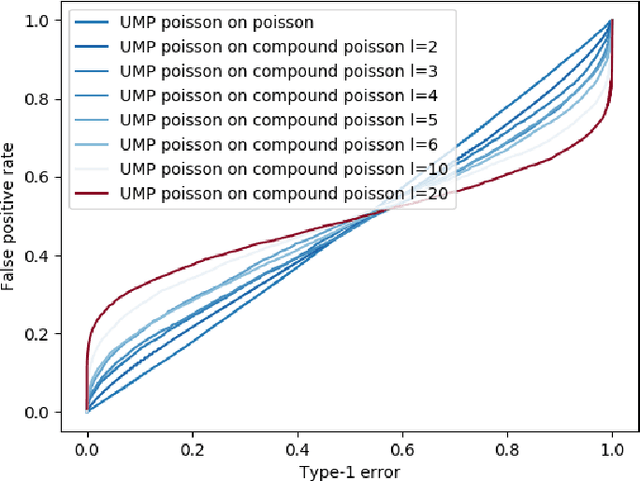
We describe the utility of point processes and failure rates and the most common point process for modeling failure rates, the Poisson point process. Next, we describe the uniformly most powerful test for comparing the rates of two Poisson point processes for a one-sided test (henceforth referred to as the "rate test"). A common argument against using this test is that real world data rarely follows the Poisson point process. We thus investigate what happens when the distributional assumptions of tests like these are violated and the test still applied. We find a non-pathological example (using the rate test on a Compound Poisson distribution with Binomial compounding) where violating the distributional assumptions of the rate test make it perform better (lower error rates). We also find that if we replace the distribution of the test statistic under the null hypothesis with any other arbitrary distribution, the performance of the test (described in terms of the false negative rate to false positive rate trade-off) remains exactly the same. Next, we compare the performance of the rate test to a version of the Wald test customized to the Negative Binomial point process and find it to perform very similarly while being much more general and versatile. Finally, we discuss the applications to Microsoft Azure. The code for all experiments performed is open source and linked in the introduction.
Volumetric Capture of Humans with a Single RGBD Camera via Semi-Parametric Learning
May 29, 2019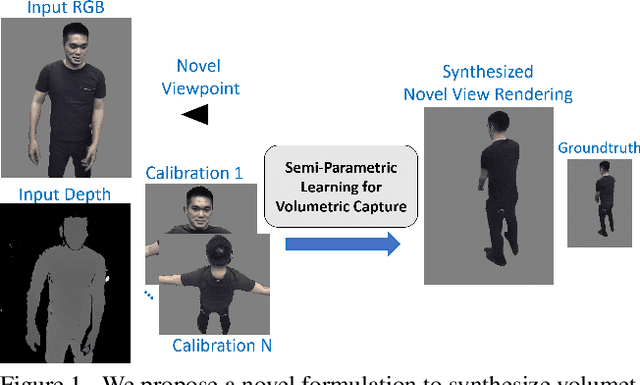

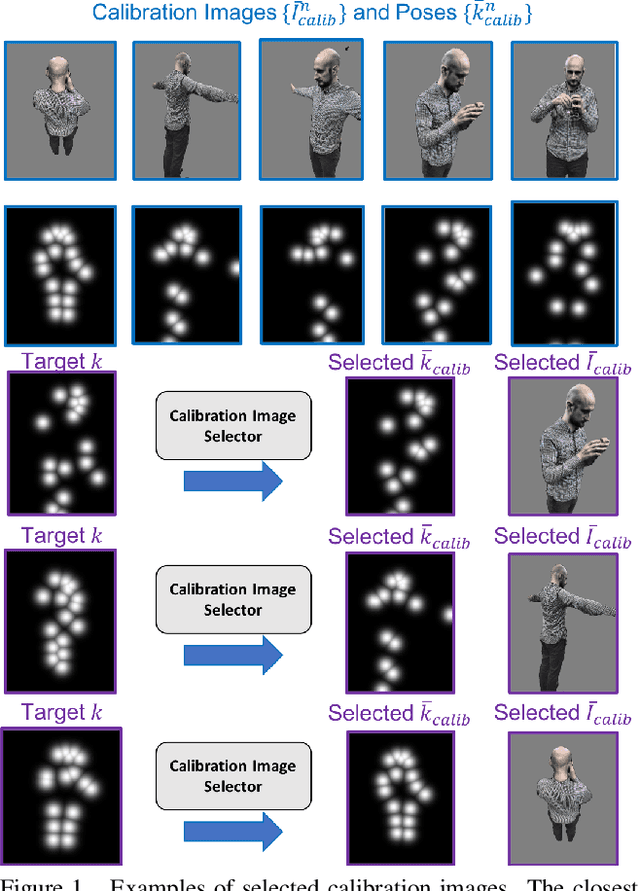
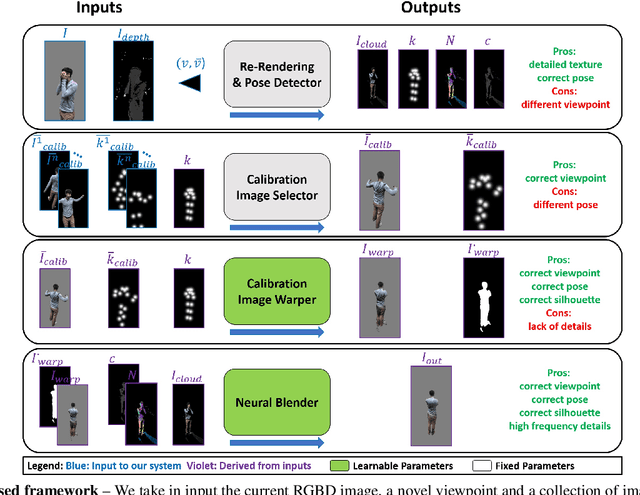
Volumetric (4D) performance capture is fundamental for AR/VR content generation. Whereas previous work in 4D performance capture has shown impressive results in studio settings, the technology is still far from being accessible to a typical consumer who, at best, might own a single RGBD sensor. Thus, in this work, we propose a method to synthesize free viewpoint renderings using a single RGBD camera. The key insight is to leverage previously seen "calibration" images of a given user to extrapolate what should be rendered in a novel viewpoint from the data available in the sensor. Given these past observations from multiple viewpoints, and the current RGBD image from a fixed view, we propose an end-to-end framework that fuses both these data sources to generate novel renderings of the performer. We demonstrate that the method can produce high fidelity images, and handle extreme changes in subject pose and camera viewpoints. We also show that the system generalizes to performers not seen in the training data. We run exhaustive experiments demonstrating the effectiveness of the proposed semi-parametric model (i.e. calibration images available to the neural network) compared to other state of the art machine learned solutions. Further, we compare the method with more traditional pipelines that employ multi-view capture. We show that our framework is able to achieve compelling results, with substantially less infrastructure than previously required.
Neural Rerendering in the Wild
Apr 08, 2019
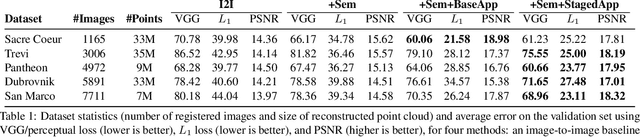

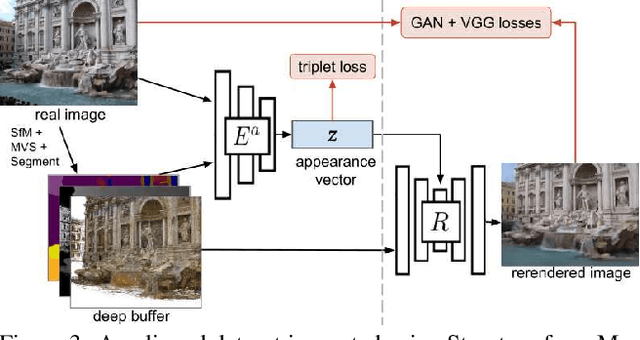
We explore total scene capture -- recording, modeling, and rerendering a scene under varying appearance such as season and time of day. Starting from internet photos of a tourist landmark, we apply traditional 3D reconstruction to register the photos and approximate the scene as a point cloud. For each photo, we render the scene points into a deep framebuffer, and train a neural network to learn the mapping of these initial renderings to the actual photos. This rerendering network also takes as input a latent appearance vector and a semantic mask indicating the location of transient objects like pedestrians. The model is evaluated on several datasets of publicly available images spanning a broad range of illumination conditions. We create short videos demonstrating realistic manipulation of the image viewpoint, appearance, and semantic labeling. We also compare results with prior work on scene reconstruction from internet photos.