 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionNex: A Virtual Outage Manager for Cloud
Apr 03, 2026Outage management in large-scale cloud operations remains heavily manual, requiring rapid triage, cross-team coordination, and experience-driven decisions under partial observability. We present \textbf{ActionNex}, a production-grade agentic system that supports end-to-end outage assistance, including real-time updates, knowledge distillation, and role- and stage-conditioned next-best action recommendations. ActionNex ingests multimodal operational signals (e.g., outage content, telemetry, and human communications) and compresses them into critical events that represent meaningful state transitions. It couples this perception layer with a hierarchical memory subsystem: long-term Key-Condition-Action (KCA) knowledge distilled from playbooks and historical executions, episodic memory of prior outages, and working memory of the live context. A reasoning agent aligns current critical events to preconditions, retrieves relevant memories, and generates actionable recommendations; executed human actions serve as an implicit feedback signal to enable continual self-evolution in a human-agent hybrid system. We evaluate ActionNex on eight real Azure outages (8M tokens, 4,000 critical events) using two complementary ground-truth action sets, achieving 71.4\% precision and 52.8-54.8\% recall. The system has been piloted in production and has received positive early feedback.
Breaking hypothesis testing for failure rates
Jan 13, 2020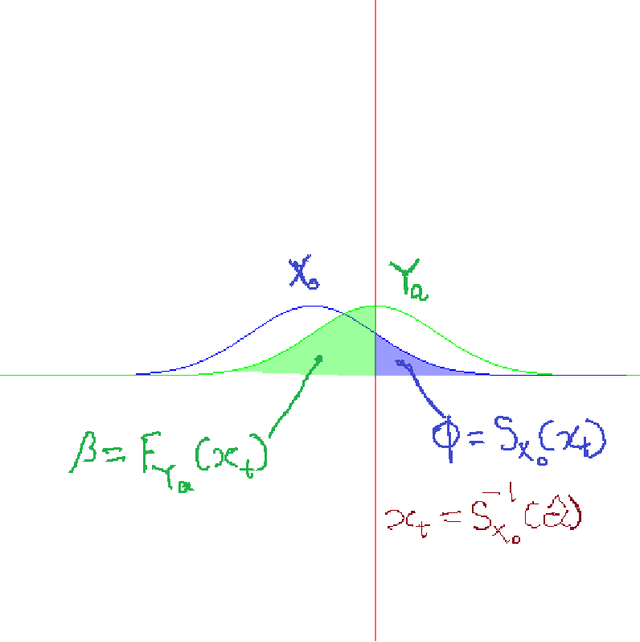
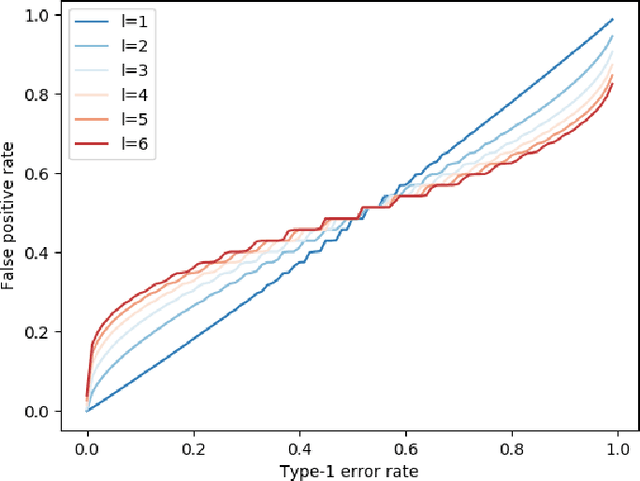
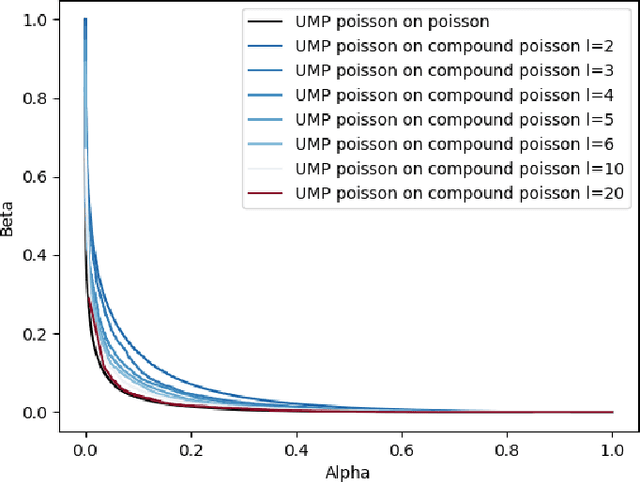
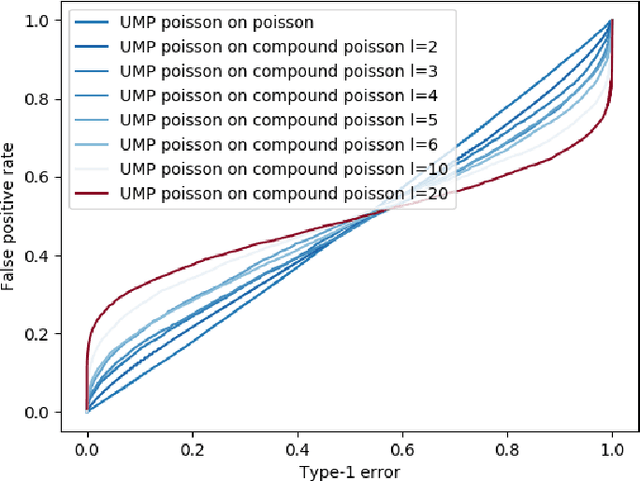
We describe the utility of point processes and failure rates and the most common point process for modeling failure rates, the Poisson point process. Next, we describe the uniformly most powerful test for comparing the rates of two Poisson point processes for a one-sided test (henceforth referred to as the "rate test"). A common argument against using this test is that real world data rarely follows the Poisson point process. We thus investigate what happens when the distributional assumptions of tests like these are violated and the test still applied. We find a non-pathological example (using the rate test on a Compound Poisson distribution with Binomial compounding) where violating the distributional assumptions of the rate test make it perform better (lower error rates). We also find that if we replace the distribution of the test statistic under the null hypothesis with any other arbitrary distribution, the performance of the test (described in terms of the false negative rate to false positive rate trade-off) remains exactly the same. Next, we compare the performance of the rate test to a version of the Wald test customized to the Negative Binomial point process and find it to perform very similarly while being much more general and versatile. Finally, we discuss the applications to Microsoft Azure. The code for all experiments performed is open source and linked in the introduction.