 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Cascade Bandits: Mitigating Exposure Bias in Online Learning to Rank Recommendation
Aug 07, 2021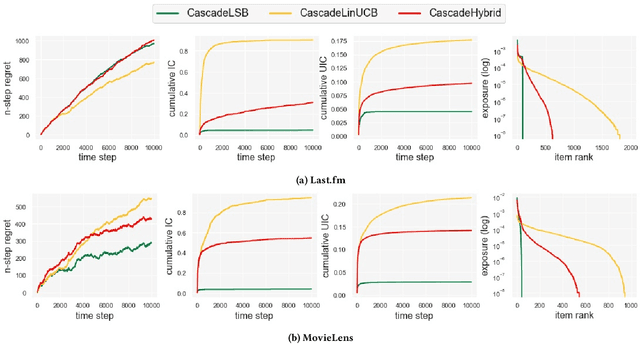
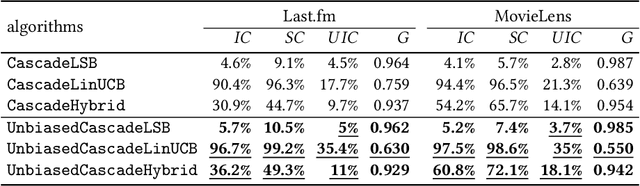
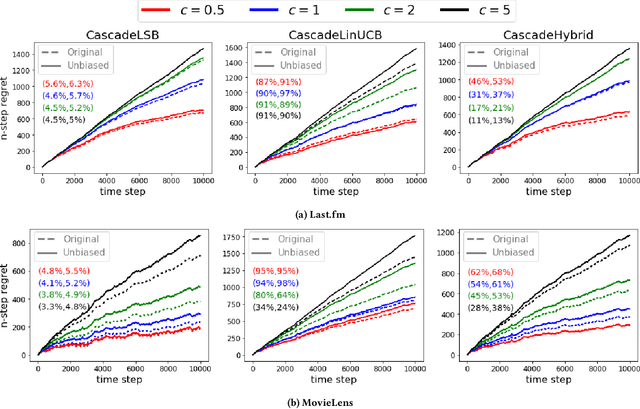
Exposure bias is a well-known issue in recommender systems where items and suppliers are not equally represented in the recommendation results. This is especially problematic when bias is amplified over time as a few popular items are repeatedly over-represented in recommendation lists. This phenomenon can be viewed as a recommendation feedback loop: the system repeatedly recommends certain items at different time points and interactions of users with those items will amplify bias towards those items over time. This issue has been extensively studied in the literature on model-based or neighborhood-based recommendation algorithms, but less work has been done on online recommendation models such as those based on multi-armed Bandit algorithms. In this paper, we study exposure bias in a class of well-known bandit algorithms known as Linear Cascade Bandits. We analyze these algorithms on their ability to handle exposure bias and provide a fair representation for items and suppliers in the recommendation results. Our analysis reveals that these algorithms fail to treat items and suppliers fairly and do not sufficiently explore the item space for each user. To mitigate this bias, we propose a discounting factor and incorporate it into these algorithms that controls the exposure of items at each time step. To show the effectiveness of the proposed discounting factor on mitigating exposure bias, we perform experiments on two datasets using three cascading bandit algorithms and our experimental results show that the proposed method improves the exposure fairness for items and suppliers.
A Graph-based Approach for Mitigating Multi-sided Exposure Bias in Recommender Systems
Jul 07, 2021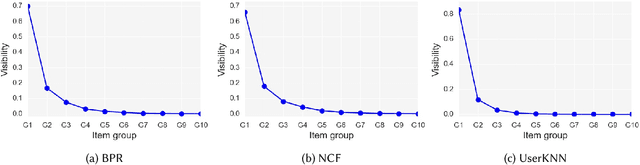
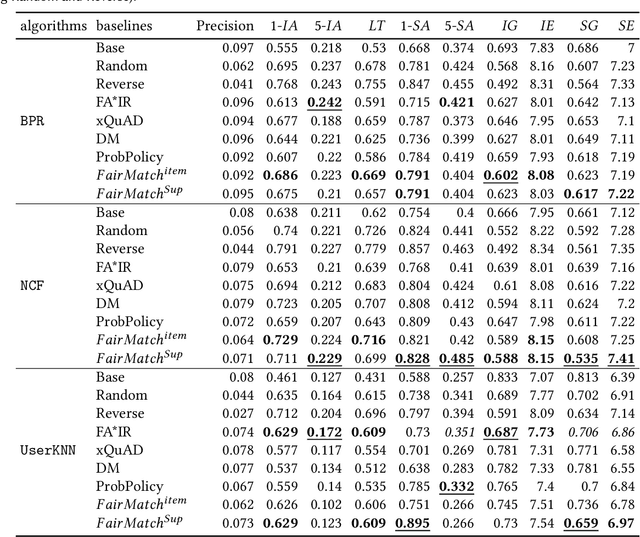
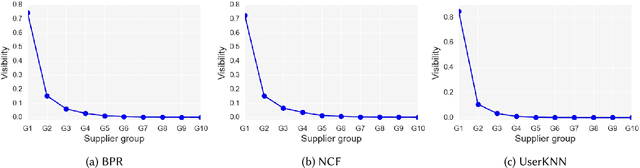
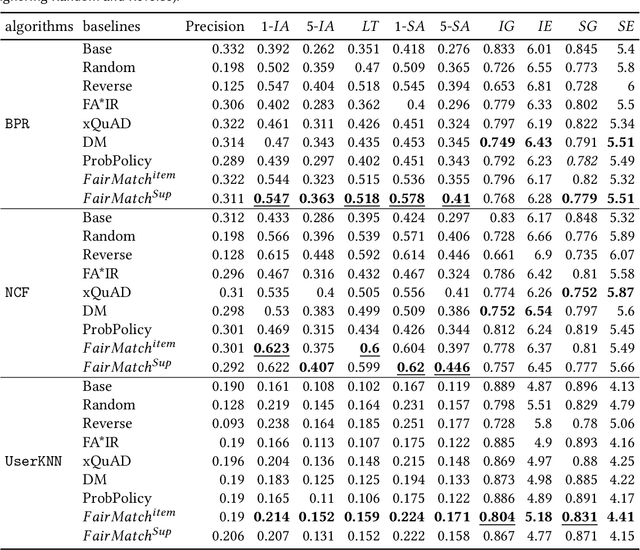
Fairness is a critical system-level objective in recommender systems that has been the subject of extensive recent research. A specific form of fairness is supplier exposure fairness where the objective is to ensure equitable coverage of items across all suppliers in recommendations provided to users. This is especially important in multistakeholder recommendation scenarios where it may be important to optimize utilities not just for the end-user, but also for other stakeholders such as item sellers or producers who desire a fair representation of their items. This type of supplier fairness is sometimes accomplished by attempting to increasing aggregate diversity in order to mitigate popularity bias and to improve the coverage of long-tail items in recommendations. In this paper, we introduce FairMatch, a general graph-based algorithm that works as a post processing approach after recommendation generation to improve exposure fairness for items and suppliers. The algorithm iteratively adds high quality items that have low visibility or items from suppliers with low exposure to the users' final recommendation lists. A comprehensive set of experiments on two datasets and comparison with state-of-the-art baselines show that FairMatch, while significantly improves exposure fairness and aggregate diversity, maintains an acceptable level of relevance of the recommendations.
Fairness and Discrimination in Information Access Systems
May 12, 2021

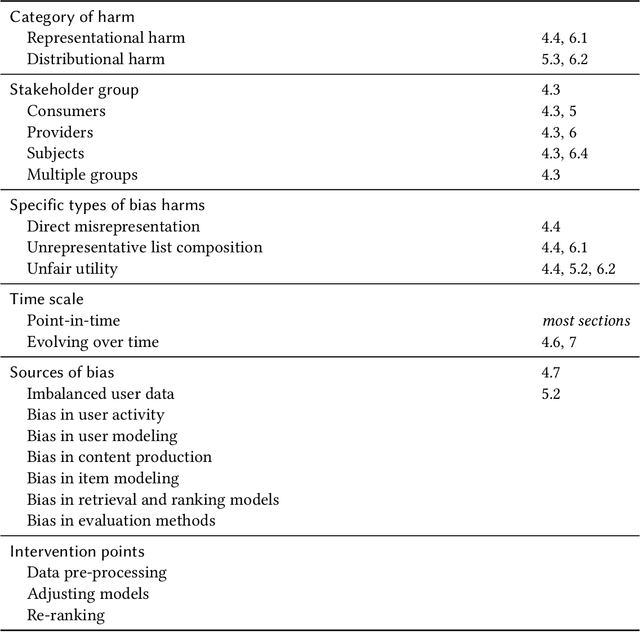
Recommendation, information retrieval, and other information access systems pose unique challenges for investigating and applying the fairness and non-discrimination concepts that have been developed for studying other machine learning systems. While fair information access shares many commonalities with fair classification, the multistakeholder nature of information access applications, the rank-based problem setting, the centrality of personalization in many cases, and the role of user response complicate the problem of identifying precisely what types and operationalizations of fairness may be relevant, let alone measuring or promoting them. In this monograph, we present a taxonomy of the various dimensions of fair information access and survey the literature to date on this new and rapidly-growing topic. We preface this with brief introductions to information access and algorithmic fairness, to facilitate use of this work by scholars with experience in one (or neither) of these fields who wish to learn about their intersection. We conclude with several open problems in fair information access, along with some suggestions for how to approach research in this space.
Fairness and Transparency in Recommendation: The Users' Perspective
Mar 16, 2021Though recommender systems are defined by personalization, recent work has shown the importance of additional, beyond-accuracy objectives, such as fairness. Because users often expect their recommendations to be purely personalized, these new algorithmic objectives must be communicated transparently in a fairness-aware recommender system. While explanation has a long history in recommender systems research, there has been little work that attempts to explain systems that use a fairness objective. Even though the previous work in other branches of AI has explored the use of explanations as a tool to increase fairness, this work has not been focused on recommendation. Here, we consider user perspectives of fairness-aware recommender systems and techniques for enhancing their transparency. We describe the results of an exploratory interview study that investigates user perceptions of fairness, recommender systems, and fairness-aware objectives. We propose three features -- informed by the needs of our participants -- that could improve user understanding of and trust in fairness-aware recommender systems.
User-centered Evaluation of Popularity Bias in Recommender Systems
Mar 10, 2021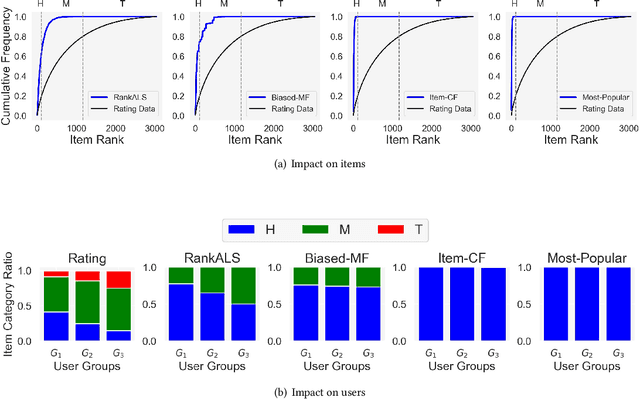
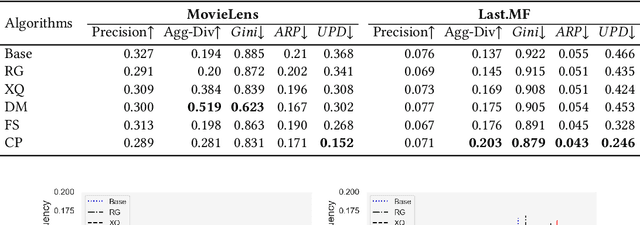
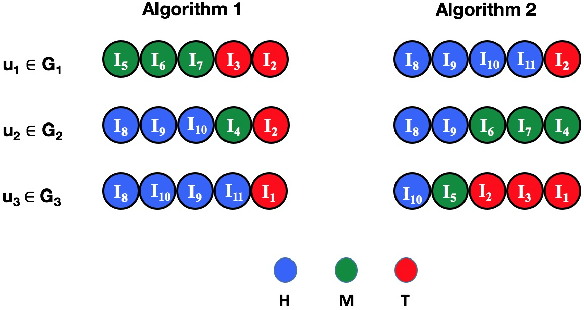
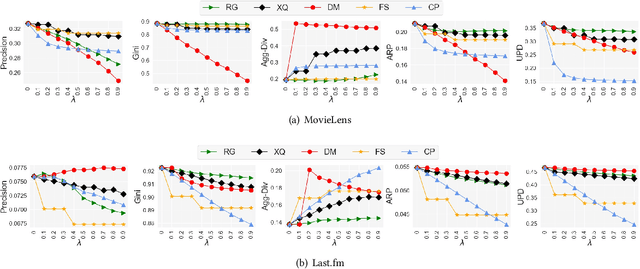
Recommendation and ranking systems are known to suffer from popularity bias; the tendency of the algorithm to favor a few popular items while under-representing the majority of other items. Prior research has examined various approaches for mitigating popularity bias and enhancing the recommendation of long-tail, less popular, items. The effectiveness of these approaches is often assessed using different metrics to evaluate the extent to which over-concentration on popular items is reduced. However, not much attention has been given to the user-centered evaluation of this bias; how different users with different levels of interest towards popular items are affected by such algorithms. In this paper, we show the limitations of the existing metrics to evaluate popularity bias mitigation when we want to assess these algorithms from the users' perspective and we propose a new metric that can address these limitations. In addition, we present an effective approach that mitigates popularity bias from the user-centered point of view. Finally, we investigate several state-of-the-art approaches proposed in recent years to mitigate popularity bias and evaluate their performances using the existing metrics and also from the users' perspective. Our experimental results using two publicly-available datasets show that existing popularity bias mitigation techniques ignore the users' tolerance towards popular items. Our proposed user-centered method can tackle popularity bias effectively for different users while also improving the existing metrics.
User Factor Adaptation for User Embedding via Multitask Learning
Feb 22, 2021
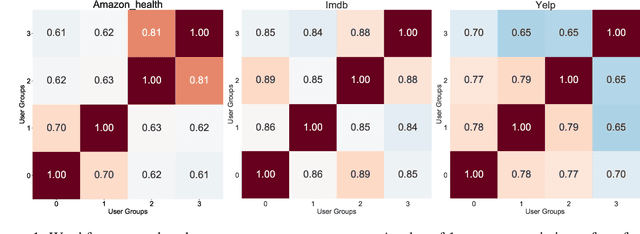
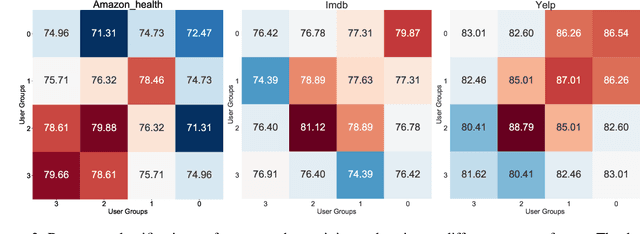
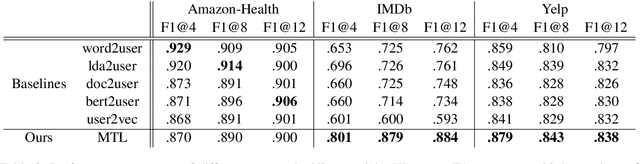
Language varies across users and their interested fields in social media data: words authored by a user across his/her interests may have different meanings (e.g., cool) or sentiments (e.g., fast). However, most of the existing methods to train user embeddings ignore the variations across user interests, such as product and movie categories (e.g., drama vs. action). In this study, we treat the user interest as domains and empirically examine how the user language can vary across the user factor in three English social media datasets. We then propose a user embedding model to account for the language variability of user interests via a multitask learning framework. The model learns user language and its variations without human supervision. While existing work mainly evaluated the user embedding by extrinsic tasks, we propose an intrinsic evaluation via clustering and evaluate user embeddings by an extrinsic task, text classification. The experiments on the three English-language social media datasets show that our proposed approach can generally outperform baselines via adapting the user factor.
"And the Winner Is": Dynamic Lotteries for Multi-group Fairness-Aware Recommendation
Sep 05, 2020

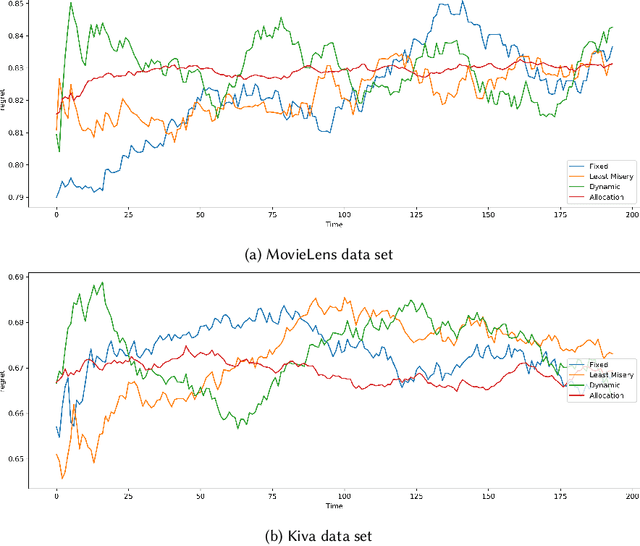
As recommender systems are being designed and deployed for an increasing number of socially-consequential applications, it has become important to consider what properties of fairness these systems exhibit. There has been considerable research on recommendation fairness. However, we argue that the previous literature has been based on simple, uniform and often uni-dimensional notions of fairness assumptions that do not recognize the real-world complexities of fairness-aware applications. In this paper, we explicitly represent the design decisions that enter into the trade-off between accuracy and fairness across multiply-defined and intersecting protected groups, supporting multiple fairness metrics. The framework also allows the recommender to adjust its performance based on the historical view of recommendations that have been delivered over a time horizon, dynamically rebalancing between fairness concerns. Within this framework, we formulate lottery-based mechanisms for choosing between fairness concerns, and demonstrate their performance in two recommendation domains.
Opportunistic Multi-aspect Fairness through Personalized Re-ranking
May 21, 2020
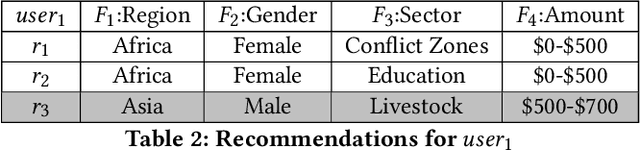
As recommender systems have become more widespread and moved into areas with greater social impact, such as employment and housing, researchers have begun to seek ways to ensure fairness in the results that such systems produce. This work has primarily focused on developing recommendation approaches in which fairness metrics are jointly optimized along with recommendation accuracy. However, the previous work had largely ignored how individual preferences may limit the ability of an algorithm to produce fair recommendations. Furthermore, with few exceptions, researchers have only considered scenarios in which fairness is measured relative to a single sensitive feature or attribute (such as race or gender). In this paper, we present a re-ranking approach to fairness-aware recommendation that learns individual preferences across multiple fairness dimensions and uses them to enhance provider fairness in recommendation results. Specifically, we show that our opportunistic and metric-agnostic approach achieves a better trade-off between accuracy and fairness than prior re-ranking approaches and does so across multiple fairness dimensions.
Exploring User Opinions of Fairness in Recommender Systems
Apr 17, 2020Algorithmic fairness for artificial intelligence has become increasingly relevant as these systems become more pervasive in society. One realm of AI, recommender systems, presents unique challenges for fairness due to trade offs between optimizing accuracy for users and fairness to providers. But what is fair in the context of recommendation--particularly when there are multiple stakeholders? In an initial exploration of this problem, we ask users what their ideas of fair treatment in recommendation might be, and why. We analyze what might cause discrepancies or changes between user's opinions towards fairness to eventually help inform the design of fairer and more transparent recommendation algorithms.
Developing a Recommendation Benchmark for MLPerf Training and Inference
Apr 14, 2020Deep learning-based recommendation models are used pervasively and broadly, for example, to recommend movies, products, or other information most relevant to users, in order to enhance the user experience. Among various application domains which have received significant industry and academia research attention, such as image classification, object detection, language and speech translation, the performance of deep learning-based recommendation models is less well explored, even though recommendation tasks unarguably represent significant AI inference cycles at large-scale datacenter fleets. To advance the state of understanding and enable machine learning system development and optimization for the commerce domain, we aim to define an industry-relevant recommendation benchmark for the MLPerf Training andInference Suites. The paper synthesizes the desirable modeling strategies for personalized recommendation systems. We lay out desirable characteristics of recommendation model architectures and data sets. We then summarize the discussions and advice from the MLPerf Recommendation Advisory Board.