 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Language Model for Large Scale Search, Recommendation, and Reasoning
Mar 18, 2026LLMs are increasingly applied to recommendation, retrieval, and reasoning, yet deploying a single end-to-end model that can jointly support these behaviors over large, heterogeneous catalogs remains challenging. Such systems must generate unambiguous references to real items, handle multiple entity types, and operate under strict latency and reliability constraints requirements that are difficult to satisfy with text-only generation. While tool-augmented recommender systems address parts of this problem, they introduce orchestration complexity and limit end-to-end optimization. We view this setting as an instance of a broader research problem: how to adapt LLMs to reason jointly over multiple-domain entities, users, and language in a fully self-contained manner. To this end, we introduce NEO, a framework that adapts a pre-trained decoder-only LLM into a tool-free, catalog-grounded generator. NEO represents items as SIDs and trains a single model to interleave natural language and typed item identifiers within a shared sequence. Text prompts control the task, target entity type, and output format (IDs, text, or mixed), while constrained decoding guarantees catalog-valid item generation without restricting free-form text. We refer to this instruction-conditioned controllability as language-steerability. We treat SIDs as a distinct modality and study design choices for integrating discrete entity representations into LLMs via staged alignment and instruction tuning. We evaluate NEO at scale on a real-world catalog of over 10M items across multiple media types and discovery tasks, including recommendation, search, and user understanding. In offline experiments, NEO consistently outperforms strong task-specific baselines and exhibits cross-task transfer, demonstrating a practical path toward consolidating large-scale discovery capabilities into a single language-steerable generative model.
Deploying Semantic ID-based Generative Retrieval for Large-Scale Podcast Discovery at Spotify
Mar 18, 2026Podcast listening is often grounded in a set of favorite shows, while listener intent can evolve over time. This combination of stable preferences and changing intent motivates recommendation approaches that support both familiarity and exploration. Traditional recommender systems typically emphasize long-term interaction patterns, and are less explicitly designed to incorporate rich contextual signals or flexible, intent-aware discovery objectives. In this setting, models that can jointly reason over semantics, context, and user state offer a promising direction. Large Language Models (LLMs) provide strong semantic reasoning and contextual conditioning for discovery-oriented recommendation, but deploying them in production introduces challenges in catalog grounding, user-level personalization, and latency-critical serving. We address these challenges with GLIDE, a production-scale generative recommender for podcast discovery at Spotify. GLIDE formulates recommendation as an instruction-following task over a discretized catalog using Semantic IDs, enabling grounded generation over a large inventory. The model conditions on recent listening history and lightweight user context, while injecting long-term user embeddings as soft prompts to capture stable preferences under strict inference constraints. We evaluate GLIDE using offline retrieval metrics, human judgments, and LLM-based evaluation, and validate its impact through large-scale online A/B testing. Across experiments involving millions of users, GLIDE increases non-habitual podcast streaming on Spotify home surface by up to 5.4% and new-show discovery by up to 14.3%, while meeting production cost and latency constraints.
Developing a Recommendation Benchmark for MLPerf Training and Inference
Apr 14, 2020Deep learning-based recommendation models are used pervasively and broadly, for example, to recommend movies, products, or other information most relevant to users, in order to enhance the user experience. Among various application domains which have received significant industry and academia research attention, such as image classification, object detection, language and speech translation, the performance of deep learning-based recommendation models is less well explored, even though recommendation tasks unarguably represent significant AI inference cycles at large-scale datacenter fleets. To advance the state of understanding and enable machine learning system development and optimization for the commerce domain, we aim to define an industry-relevant recommendation benchmark for the MLPerf Training andInference Suites. The paper synthesizes the desirable modeling strategies for personalized recommendation systems. We lay out desirable characteristics of recommendation model architectures and data sets. We then summarize the discussions and advice from the MLPerf Recommendation Advisory Board.
Gradient Boosted Decision Tree Neural Network
Nov 05, 2019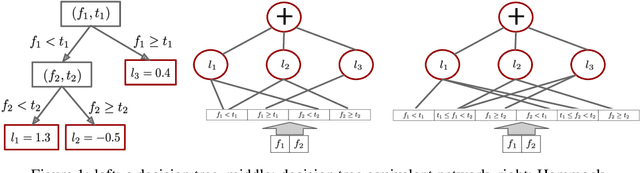
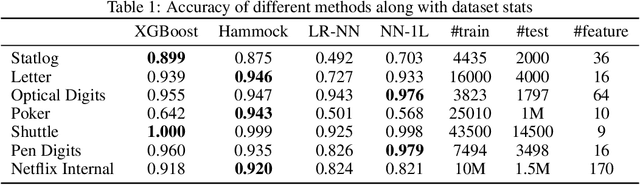
In this paper we propose a method to build a neural network that is similar to an ensemble of decision trees. We first illustrate how to convert a learned ensemble of decision trees to a single neural network with one hidden layer and an input transformation. We then relax some properties of this network such as thresholds and activation functions to train an approximately equivalent decision tree ensemble. The final model, Hammock, is surprisingly simple: a fully connected two layers neural network where the input is quantized and one-hot encoded. Experiments on large and small datasets show this simple method can achieve performance similar to that of Gradient Boosted Decision Trees.
Beta Survival Models
May 09, 2019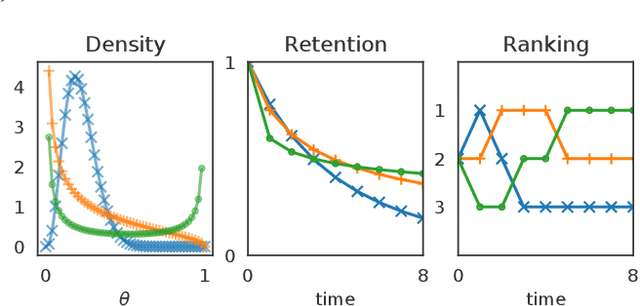
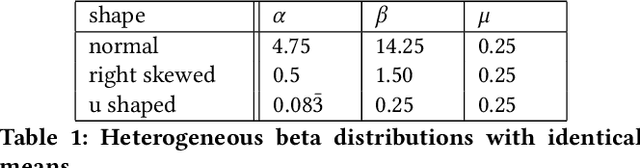
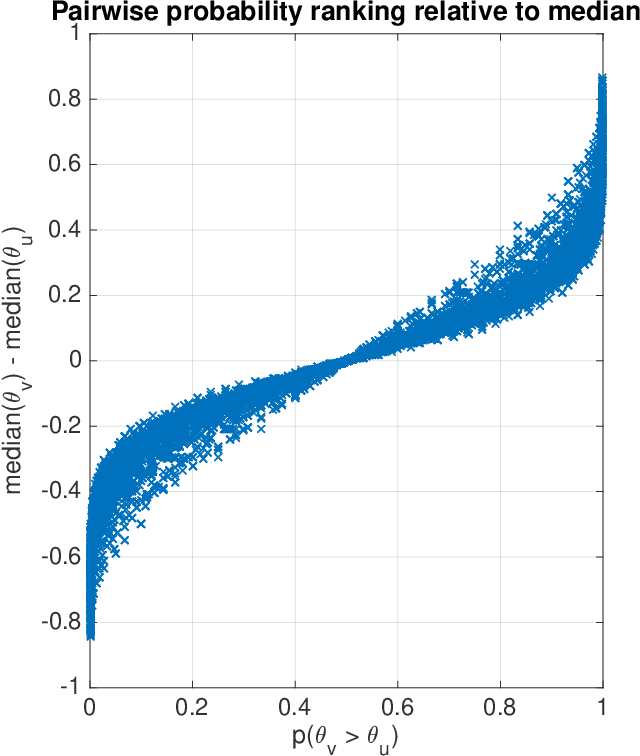
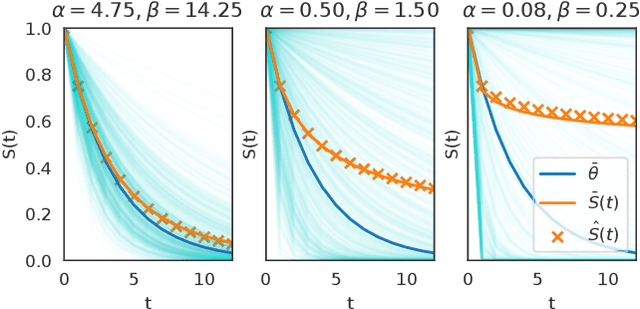
This article analyzes the problem of estimating the time until an event occurs, also known as survival modeling. We observe through substantial experiments on large real-world datasets and use-cases that populations are largely heterogeneous. Sub-populations have different mean and variance in their survival rates requiring flexible models that capture heterogeneity. We leverage a classical extension of the logistic function into the survival setting to characterize unobserved heterogeneity using the beta distribution. This yields insights into the geometry of the problem as well as efficient estimation methods for linear, tree and neural network models that adjust the beta distribution based on observed covariates. We also show that the additional information captured by the beta distribution leads to interesting ranking implications as we determine who is most-at-risk. We show theoretically that the ranking is variable as we forecast forward in time and prove that pairwise comparisons of survival remain transitive. Empirical results using large-scale datasets across two use-cases (online conversions and retention modeling), demonstrate the competitiveness of the method. The simplicity of the method and its ability to capture skew in the data makes it a viable alternative to standard techniques particularly when we are interested in the time to event and when the underlying probabilities are heterogeneous.