 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Recommendation Framework for Enhancing User Engagement in Local News
Aug 27, 2025


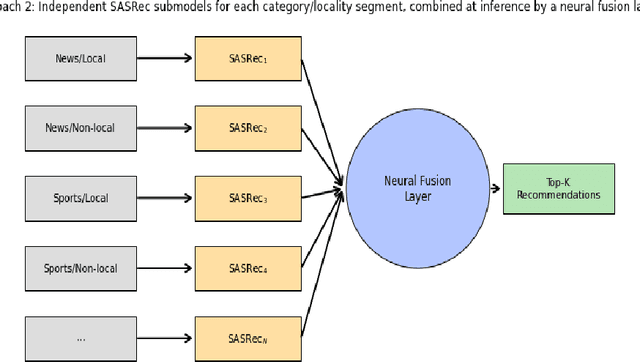
Local news organizations face an urgent need to boost reader engagement amid declining circulation and competition from global media. Personalized news recommender systems offer a promising solution by tailoring content to user interests. Yet, conventional approaches often emphasize general preferences and may overlook nuanced or eclectic interests in local news. We propose a hybrid news recommender that integrates local and global preference models to improve engagement. Building on evidence of the value of localized models, our method unifies local and non-local predictors in one framework. The system adaptively combines recommendations from a local model, specialized in region-specific content, and a global model that captures broader preferences. Ensemble strategies and multiphase training balance the two. We evaluated the model on two datasets: a synthetic set based on Syracuse newspaper distributions and a Danish dataset (EB-NeRD) labeled for local and non-local content with an LLM. Results show our integrated approach outperforms single-model baselines in accuracy and coverage, suggesting improved personalization that can drive user engagement. The findings have practical implications for publishers, especially local outlets. By leveraging both community-specific and general user interests, the hybrid recommender can deliver more relevant content, increasing retention and subscriptions. In sum, this work introduces a new direction for recommender systems, bridging local and global models to revitalize local news consumption through scalable, personalized user experiences.
Temporal User Profiling with LLMs: Balancing Short-Term and Long-Term Preferences for Recommendations
Aug 11, 2025Accurately modeling user preferences is crucial for improving the performance of content-based recommender systems. Existing approaches often rely on simplistic user profiling methods, such as averaging or concatenating item embeddings, which fail to capture the nuanced nature of user preference dynamics, particularly the interactions between long-term and short-term preferences. In this work, we propose LLM-driven Temporal User Profiling (LLM-TUP), a novel method for user profiling that explicitly models short-term and long-term preferences by leveraging interaction timestamps and generating natural language representations of user histories using a large language model (LLM). These representations are encoded into high-dimensional embeddings using a pre-trained BERT model, and an attention mechanism is applied to dynamically fuse the short-term and long-term embeddings into a comprehensive user profile. Experimental results on real-world datasets demonstrate that LLM-TUP achieves substantial improvements over several baselines, underscoring the effectiveness of our temporally aware user-profiling approach and the use of semantically rich user profiles, generated by LLMs, for personalized content-based recommendation.
Using LLMs to Capture Users' Temporal Context for Recommendation
Aug 11, 2025Effective recommender systems demand dynamic user understanding, especially in complex, evolving environments. Traditional user profiling often fails to capture the nuanced, temporal contextual factors of user preferences, such as transient short-term interests and enduring long-term tastes. This paper presents an assessment of Large Language Models (LLMs) for generating semantically rich, time-aware user profiles. We do not propose a novel end-to-end recommendation architecture; instead, the core contribution is a systematic investigation into the degree of LLM effectiveness in capturing the dynamics of user context by disentangling short-term and long-term preferences. This approach, framing temporal preferences as dynamic user contexts for recommendations, adaptively fuses these distinct contextual components into comprehensive user embeddings. The evaluation across Movies&TV and Video Games domains suggests that while LLM-generated profiles offer semantic depth and temporal structure, their effectiveness for context-aware recommendations is notably contingent on the richness of user interaction histories. Significant gains are observed in dense domains (e.g., Movies&TV), whereas improvements are less pronounced in sparse environments (e.g., Video Games). This work highlights LLMs' nuanced potential in enhancing user profiling for adaptive, context-aware recommendations, emphasizing the critical role of dataset characteristics for practical applicability.
Towards Explainable Temporal User Profiling with LLMs
May 01, 2025Accurately modeling user preferences is vital not only for improving recommendation performance but also for enhancing transparency in recommender systems. Conventional user profiling methods, such as averaging item embeddings, often overlook the evolving, nuanced nature of user interests, particularly the interplay between short-term and long-term preferences. In this work, we leverage large language models (LLMs) to generate natural language summaries of users' interaction histories, distinguishing recent behaviors from more persistent tendencies. Our framework not only models temporal user preferences but also produces natural language profiles that can be used to explain recommendations in an interpretable manner. These textual profiles are encoded via a pre-trained model, and an attention mechanism dynamically fuses the short-term and long-term embeddings into a comprehensive user representation. Beyond boosting recommendation accuracy over multiple baselines, our approach naturally supports explainability: the interpretable text summaries and attention weights can be exposed to end users, offering insights into why specific items are suggested. Experiments on real-world datasets underscore both the performance gains and the promise of generating clearer, more transparent justifications for content-based recommendations.
Mitigating Exposure Bias in Online Learning to Rank Recommendation: A Novel Reward Model for Cascading Bandits
Aug 08, 2024



Exposure bias is a well-known issue in recommender systems where items and suppliers are not equally represented in the recommendation results. This bias becomes particularly problematic over time as a few items are repeatedly over-represented in recommendation lists, leading to a feedback loop that further amplifies this bias. Although extensive research has addressed this issue in model-based or neighborhood-based recommendation algorithms, less attention has been paid to online recommendation models, such as those based on top-K contextual bandits, where recommendation models are dynamically updated with ongoing user feedback. In this paper, we study exposure bias in a class of well-known contextual bandit algorithms known as Linear Cascading Bandits. We analyze these algorithms in their ability to handle exposure bias and provide a fair representation of items in the recommendation results. Our analysis reveals that these algorithms fail to mitigate exposure bias in the long run during the course of ongoing user interactions. We propose an Exposure-Aware reward model that updates the model parameters based on two factors: 1) implicit user feedback and 2) the position of the item in the recommendation list. The proposed model mitigates exposure bias by controlling the utility assigned to the items based on their exposure in the recommendation list. Our experiments with two real-world datasets show that our proposed reward model improves the exposure fairness of the linear cascading bandits over time while maintaining the recommendation accuracy. It also outperforms the current baselines. Finally, we prove a high probability upper regret bound for our proposed model, providing theoretical guarantees for its performance.
Beyond Static Calibration: The Impact of User Preference Dynamics on Calibrated Recommendation
May 16, 2024



Calibration in recommender systems is an important performance criterion that ensures consistency between the distribution of user preference categories and that of recommendations generated by the system. Standard methods for mitigating miscalibration typically assume that user preference profiles are static, and they measure calibration relative to the full history of user's interactions, including possibly outdated and stale preference categories. We conjecture that this approach can lead to recommendations that, while appearing calibrated, in fact, distort users' true preferences. In this paper, we conduct a preliminary investigation of recommendation calibration at a more granular level, taking into account evolving user preferences. By analyzing differently sized training time windows from the most recent interactions to the oldest, we identify the most relevant segment of user's preferences that optimizes the calibration metric. We perform an exploratory analysis with datasets from different domains with distinctive user-interaction characteristics. We demonstrate how the evolving nature of user preferences affects recommendation calibration, and how this effect is manifested differently depending on the characteristics of the data in a given domain. Datasets, codes, and more detailed experimental results are available at: https://github.com/nicolelin13/DynamicCalibrationUMAP.
Fairness of Exposure in Dynamic Recommendation
Sep 05, 2023



Exposure bias is a well-known issue in recommender systems where the exposure is not fairly distributed among items in the recommendation results. This is especially problematic when bias is amplified over time as a few items (e.g., popular ones) are repeatedly over-represented in recommendation lists and users' interactions with those items will amplify bias towards those items over time resulting in a feedback loop. This issue has been extensively studied in the literature in static recommendation environment where a single round of recommendation result is processed to improve the exposure fairness. However, less work has been done on addressing exposure bias in a dynamic recommendation setting where the system is operating over time, the recommendation model and the input data are dynamically updated with ongoing user feedback on recommended items at each round. In this paper, we study exposure bias in a dynamic recommendation setting. Our goal is to show that existing bias mitigation methods that are designed to operate in a static recommendation setting are unable to satisfy fairness of exposure for items in long run. In particular, we empirically study one of these methods and show that repeatedly applying this method fails to fairly distribute exposure among items in long run. To address this limitation, we show how this method can be adapted to effectively operate in a dynamic recommendation setting and achieve exposure fairness for items in long run. Experiments on a real-world dataset confirm that our solution is superior in achieving long-term exposure fairness for the items while maintaining the recommendation accuracy.
Exposure-Aware Recommendation using Contextual Bandits
Sep 04, 2022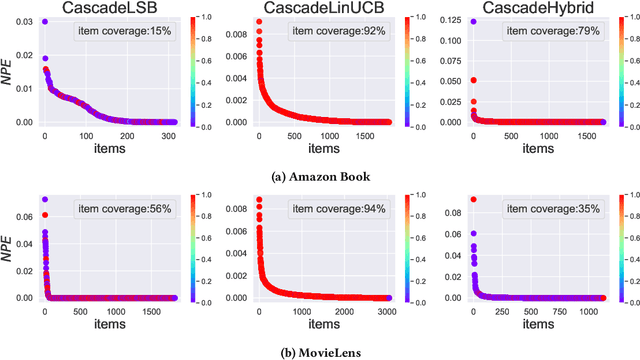
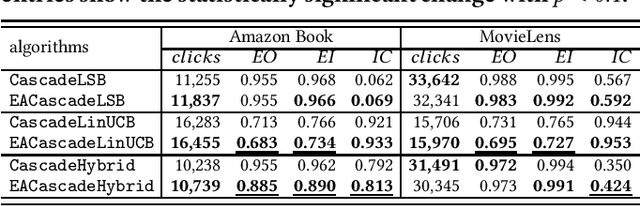
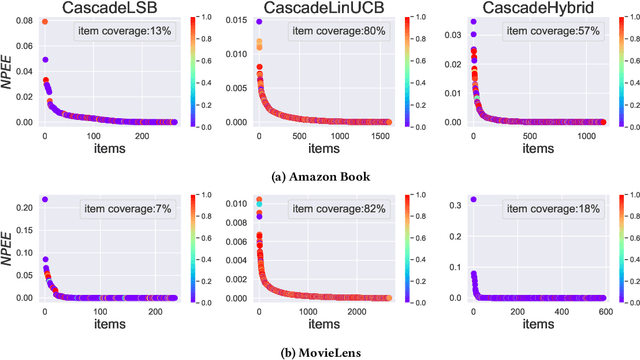
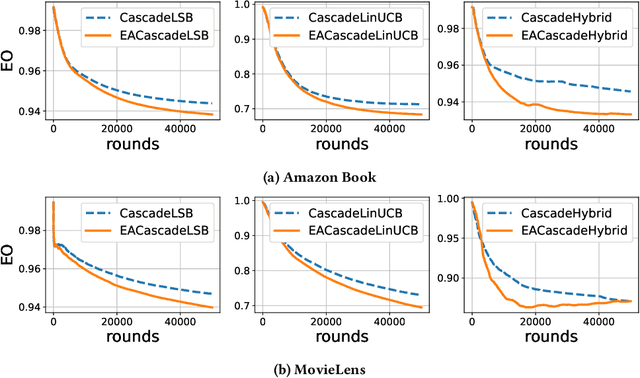
Exposure bias is a well-known issue in recommender systems where items and suppliers are not equally represented in the recommendation results. This is especially problematic when bias is amplified over time as a few items (e.g., popular ones) are repeatedly over-represented in recommendation lists and users' interactions with those items will amplify bias towards those items over time resulting in a feedback loop. This issue has been extensively studied in the literature on model-based or neighborhood-based recommendation algorithms, but less work has been done on online recommendation models, such as those based on top-K contextual bandits, where recommendation models are dynamically updated with ongoing user feedback. In this paper, we study exposure bias in a class of well-known contextual bandit algorithms known as Linear Cascading Bandits. We analyze these algorithms on their ability to handle exposure bias and provide a fair representation for items in the recommendation results. Our analysis reveals that these algorithms tend to amplify exposure disparity among items over time. In particular, we observe that these algorithms do not properly adapt to the feedback provided by the users and frequently recommend certain items even when those items are not selected by users. To mitigate this bias, we propose an Exposure-Aware (EA) reward model that updates the model parameters based on two factors: 1) user feedback (i.e., clicked or not), and 2) position of the item in the recommendation list. This way, the proposed model controls the utility assigned to items based on their exposure in the recommendation list. Extensive experiments on two real-world datasets using three contextual bandit algorithms show that the proposed reward model reduces exposure bias amplification in long run while maintaining the recommendation accuracy.
Behavioral Player Rating in Competitive Online Shooter Games
Jul 01, 2022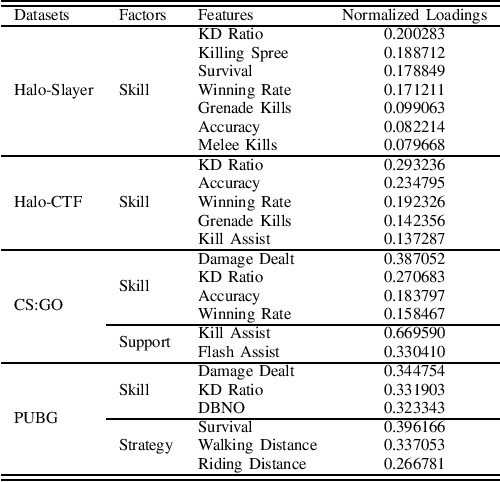
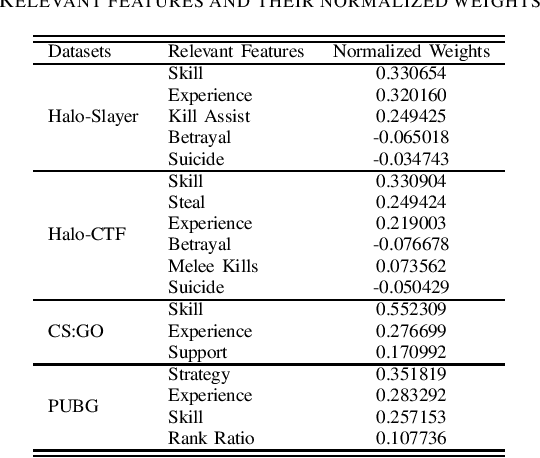
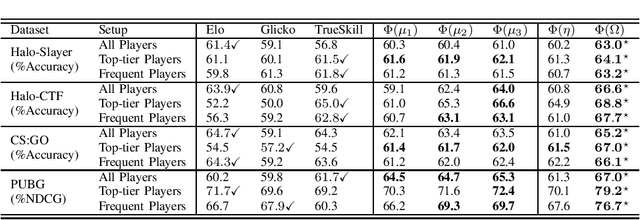
Competitive online games use rating systems for matchmaking; progression-based algorithms that estimate the skill level of players with interpretable ratings in terms of the outcome of the games they played. However, the overall experience of players is shaped by factors beyond the sole outcome of their games. In this paper, we engineer several features from in-game statistics to model players and create ratings that accurately represent their behavior and true performance level. We then compare the estimating power of our behavioral ratings against ratings created with three mainstream rating systems by predicting rank of players in four popular game modes from the competitive shooter genre. Our results show that the behavioral ratings present more accurate performance estimations while maintaining the interpretability of the created representations. Considering different aspects of the playing behavior of players and using behavioral ratings for matchmaking can lead to match-ups that are more aligned with players' goals and interests, consequently resulting in a more enjoyable gaming experience.
Using user's local context to support local news
May 26, 2022

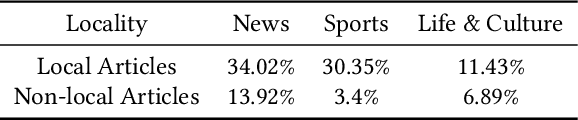
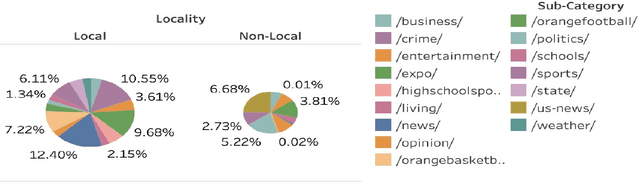
American local newspapers have been experiencing a large loss of reader retention and business within the past 15 years due to the proliferation of online news sources. Local media companies are starting to shift from an advertising-supported business model to one based on subscriptions to mitigate this problem. With this subscription model, there is a need to increase user engagement and personalization, and recommender systems are one way for these news companies to accomplish this goal. However, using standard modeling approaches that focus on users' global preferences is not appropriate in this context because the local preferences of users exhibit some specific characteristics which do not necessarily match their long-term or global preferences in the news. Our research explores a localized session-based recommendation approach, using recommendations based on local news articles and articles pertaining to the different local news categories. Experiments performed on a news dataset from a local newspaper show that these local models, particularly certain categories of items, do indeed provide more accuracy and effectiveness for personalization which, in turn, may lead to more user engagement with local news content.