 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Multi-Object Render-and-Compare
Oct 17, 2023



Reconstructing 3D shape and pose of static objects from a single image is an essential task for various industries, including robotics, augmented reality, and digital content creation. This can be done by directly predicting 3D shape in various representations or by retrieving CAD models from a database and predicting their alignments. Directly predicting 3D shapes often produces unrealistic, overly smoothed or tessellated shapes. Retrieving CAD models ensures realistic shapes but requires robust and accurate alignment. Learning to directly predict CAD model poses from image features is challenging and inaccurate. Works, such as ROCA, compute poses from predicted normalised object coordinates which can be more accurate but are susceptible to systematic failure. SPARC demonstrates that following a ''render-and-compare'' approach where a network iteratively improves upon its own predictions achieves accurate alignments. Nevertheless, it performs individual CAD alignment for every object detected in an image. This approach is slow when applied to many objects as the time complexity increases linearly with the number of objects and can not learn inter-object relations. Introducing a new network architecture Multi-SPARC we learn to perform CAD model alignments for multiple detected objects jointly. Compared to other single-view methods we achieve state-of-the-art performance on the challenging real-world dataset ScanNet. By improving the instance alignment accuracy from 31.8% to 40.3% we perform similar to state-of-the-art multi-view methods.
HuManiFlow: Ancestor-Conditioned Normalising Flows on SO(3) Manifolds for Human Pose and Shape Distribution Estimation
May 11, 2023Monocular 3D human pose and shape estimation is an ill-posed problem since multiple 3D solutions can explain a 2D image of a subject. Recent approaches predict a probability distribution over plausible 3D pose and shape parameters conditioned on the image. We show that these approaches exhibit a trade-off between three key properties: (i) accuracy - the likelihood of the ground-truth 3D solution under the predicted distribution, (ii) sample-input consistency - the extent to which 3D samples from the predicted distribution match the visible 2D image evidence, and (iii) sample diversity - the range of plausible 3D solutions modelled by the predicted distribution. Our method, HuManiFlow, predicts simultaneously accurate, consistent and diverse distributions. We use the human kinematic tree to factorise full body pose into ancestor-conditioned per-body-part pose distributions in an autoregressive manner. Per-body-part distributions are implemented using normalising flows that respect the manifold structure of SO(3), the Lie group of per-body-part poses. We show that ill-posed, but ubiquitous, 3D point estimate losses reduce sample diversity, and employ only probabilistic training losses. Code is available at: https://github.com/akashsengupta1997/HuManiFlow.
IMP: Iterative Matching and Pose Estimation with Adaptive Pooling
Apr 28, 2023



Previous methods solve feature matching and pose estimation using a two-stage process by first finding matches and then estimating the pose. As they ignore the geometric relationships between the two tasks, they focus on either improving the quality of matches or filtering potential outliers, leading to limited efficiency or accuracy. In contrast, we propose an iterative matching and pose estimation framework (IMP) leveraging the geometric connections between the two tasks: a few good matches are enough for a roughly accurate pose estimation; a roughly accurate pose can be used to guide the matching by providing geometric constraints. To this end, we implement a geometry-aware recurrent attention-based module which jointly outputs sparse matches and camera poses. Specifically, for each iteration, we first implicitly embed geometric information into the module via a pose-consistency loss, allowing it to predict geometry-aware matches progressively. Second, we introduce an \textbf{e}fficient IMP, called EIMP, to dynamically discard keypoints without potential matches, avoiding redundant updating and significantly reducing the quadratic time complexity of attention computation in transformers. Experiments on YFCC100m, Scannet, and Aachen Day-Night datasets demonstrate that the proposed method outperforms previous approaches in terms of accuracy and efficiency.
SFD2: Semantic-guided Feature Detection and Description
Apr 28, 2023



Visual localization is a fundamental task for various applications including autonomous driving and robotics. Prior methods focus on extracting large amounts of often redundant locally reliable features, resulting in limited efficiency and accuracy, especially in large-scale environments under challenging conditions. Instead, we propose to extract globally reliable features by implicitly embedding high-level semantics into both the detection and description processes. Specifically, our semantic-aware detector is able to detect keypoints from reliable regions (e.g. building, traffic lane) and suppress unreliable areas (e.g. sky, car) implicitly instead of relying on explicit semantic labels. This boosts the accuracy of keypoint matching by reducing the number of features sensitive to appearance changes and avoiding the need of additional segmentation networks at test time. Moreover, our descriptors are augmented with semantics and have stronger discriminative ability, providing more inliers at test time. Particularly, experiments on long-term large-scale visual localization Aachen Day-Night and RobotCar-Seasons datasets demonstrate that our model outperforms previous local features and gives competitive accuracy to advanced matchers but is about 2 and 3 times faster when using 2k and 4k keypoints, respectively.
Model-Based Imitation Learning for Urban Driving
Oct 14, 2022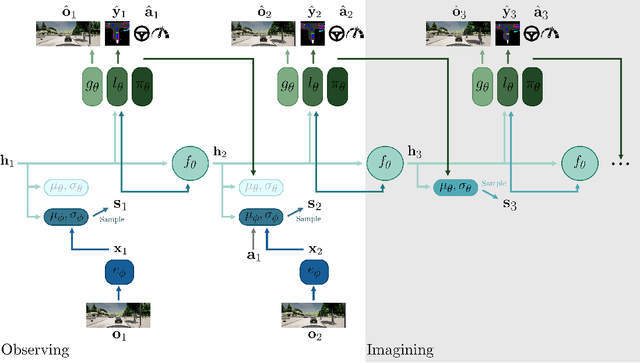
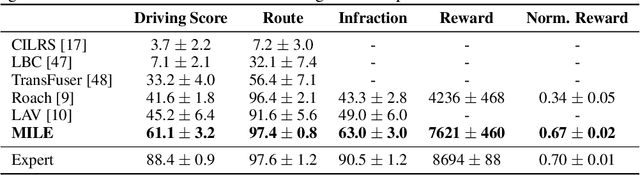
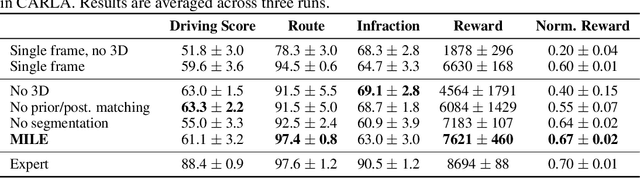
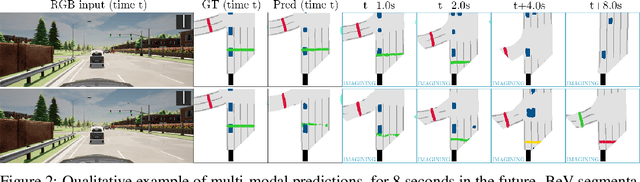
An accurate model of the environment and the dynamic agents acting in it offers great potential for improving motion planning. We present MILE: a Model-based Imitation LEarning approach to jointly learn a model of the world and a policy for autonomous driving. Our method leverages 3D geometry as an inductive bias and learns a highly compact latent space directly from high-resolution videos of expert demonstrations. Our model is trained on an offline corpus of urban driving data, without any online interaction with the environment. MILE improves upon prior state-of-the-art by 35% in driving score on the CARLA simulator when deployed in a completely new town and new weather conditions. Our model can predict diverse and plausible states and actions, that can be interpretably decoded to bird's-eye view semantic segmentation. Further, we demonstrate that it can execute complex driving manoeuvres from plans entirely predicted in imagination. Our approach is the first camera-only method that models static scene, dynamic scene, and ego-behaviour in an urban driving environment. The code and model weights are available at https://github.com/wayveai/mile.
A CNN Based Approach for the Point-Light Photometric Stereo Problem
Oct 10, 2022Reconstructing the 3D shape of an object using several images under different light sources is a very challenging task, especially when realistic assumptions such as light propagation and attenuation, perspective viewing geometry and specular light reflection are considered. Many of works tackling Photometric Stereo (PS) problems often relax most of the aforementioned assumptions. Especially they ignore specular reflection and global illumination effects. In this work, we propose a CNN-based approach capable of handling these realistic assumptions by leveraging recent improvements of deep neural networks for far-field Photometric Stereo and adapt them to the point light setup. We achieve this by employing an iterative procedure of point-light PS for shape estimation which has two main steps. Firstly we train a per-pixel CNN to predict surface normals from reflectance samples. Secondly, we compute the depth by integrating the normal field in order to iteratively estimate light directions and attenuation which is used to compensate the input images to compute reflectance samples for the next iteration. Our approach sigificantly outperforms the state-of-the-art on the DiLiGenT real world dataset. Furthermore, in order to measure the performance of our approach for near-field point-light source PS data, we introduce LUCES the first real-world 'dataset for near-fieLd point light soUrCe photomEtric Stereo' of 14 objects of different materials were the effects of point light sources and perspective viewing are a lot more significant. Our approach also outperforms the competition on this dataset as well. Data and test code are available at the project page.
IronDepth: Iterative Refinement of Single-View Depth using Surface Normal and its Uncertainty
Oct 07, 2022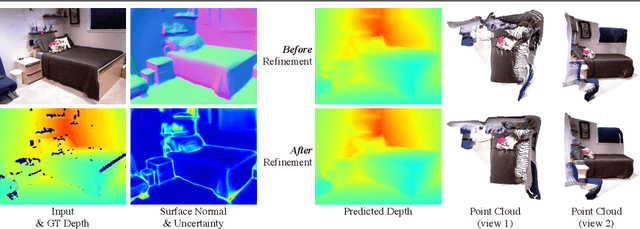
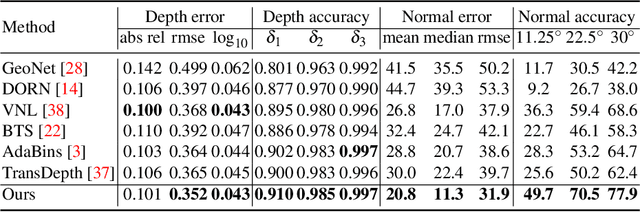
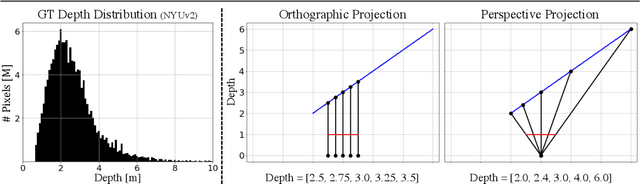
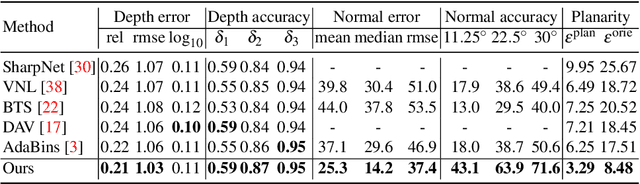
Single image surface normal estimation and depth estimation are closely related problems as the former can be calculated from the latter. However, the surface normals computed from the output of depth estimation methods are significantly less accurate than the surface normals directly estimated by networks. To reduce such discrepancy, we introduce a novel framework that uses surface normal and its uncertainty to recurrently refine the predicted depth-map. The depth of each pixel can be propagated to a query pixel, using the predicted surface normal as guidance. We thus formulate depth refinement as a classification of choosing the neighboring pixel to propagate from. Then, by propagating to sub-pixel points, we upsample the refined, low-resolution output. The proposed method shows state-of-the-art performance on NYUv2 and iBims-1 - both in terms of depth and normal. Our refinement module can also be attached to the existing depth estimation methods to improve their accuracy. We also show that our framework, only trained for depth estimation, can also be used for depth completion. The code is available at https://github.com/baegwangbin/IronDepth.
DigiFace-1M: 1 Million Digital Face Images for Face Recognition
Oct 05, 2022


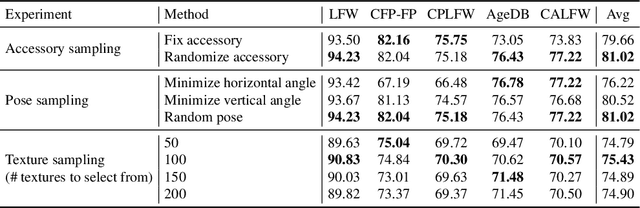
State-of-the-art face recognition models show impressive accuracy, achieving over 99.8% on Labeled Faces in the Wild (LFW) dataset. Such models are trained on large-scale datasets that contain millions of real human face images collected from the internet. Web-crawled face images are severely biased (in terms of race, lighting, make-up, etc) and often contain label noise. More importantly, the face images are collected without explicit consent, raising ethical concerns. To avoid such problems, we introduce a large-scale synthetic dataset for face recognition, obtained by rendering digital faces using a computer graphics pipeline. We first demonstrate that aggressive data augmentation can significantly reduce the synthetic-to-real domain gap. Having full control over the rendering pipeline, we also study how each attribute (e.g., variation in facial pose, accessories and textures) affects the accuracy. Compared to SynFace, a recent method trained on GAN-generated synthetic faces, we reduce the error rate on LFW by 52.5% (accuracy from 91.93% to 96.17%). By fine-tuning the network on a smaller number of real face images that could reasonably be obtained with consent, we achieve accuracy that is comparable to the methods trained on millions of real face images.
SPARC: Sparse Render-and-Compare for CAD model alignment in a single RGB image
Oct 03, 2022

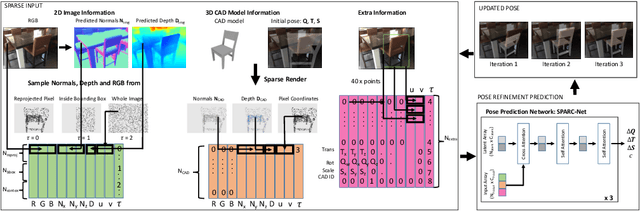
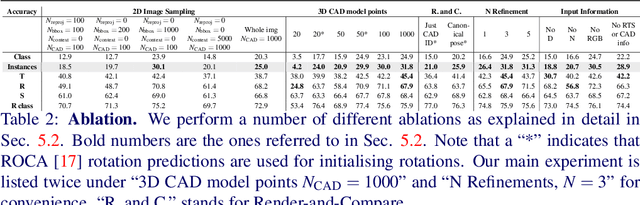
Estimating 3D shapes and poses of static objects from a single image has important applications for robotics, augmented reality and digital content creation. Often this is done through direct mesh predictions which produces unrealistic, overly tessellated shapes or by formulating shape prediction as a retrieval task followed by CAD model alignment. Directly predicting CAD model poses from 2D image features is difficult and inaccurate. Some works, such as ROCA, regress normalised object coordinates and use those for computing poses. While this can produce more accurate pose estimates, predicting normalised object coordinates is susceptible to systematic failure. Leveraging efficient transformer architectures we demonstrate that a sparse, iterative, render-and-compare approach is more accurate and robust than relying on normalised object coordinates. For this we combine 2D image information including sparse depth and surface normal values which we estimate directly from the image with 3D CAD model information in early fusion. In particular, we reproject points sampled from the CAD model in an initial, random pose and compute their depth and surface normal values. This combined information is the input to a pose prediction network, SPARC-Net which we train to predict a 9 DoF CAD model pose update. The CAD model is reprojected again and the next pose update is predicted. Our alignment procedure converges after just 3 iterations, improving the state-of-the-art performance on the challenging real-world dataset ScanNet from 25.0% to 31.8% instance alignment accuracy. Code will be released at https://github.com/florianlanger/SPARC .
Contrastive Unsupervised Learning of World Model with Invariant Causal Features
Sep 29, 2022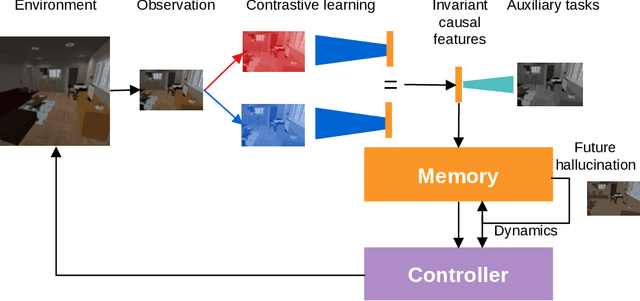
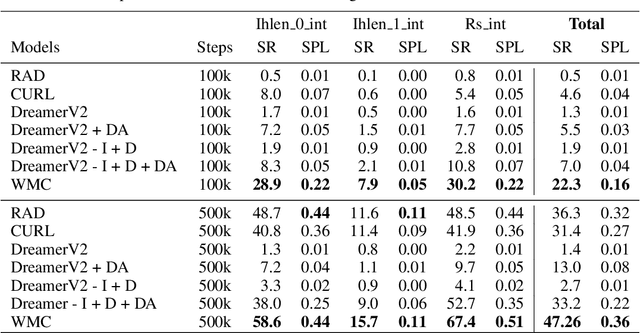
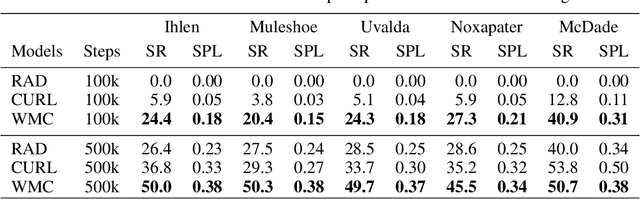
In this paper we present a world model, which learns causal features using the invariance principle. In particular, we use contrastive unsupervised learning to learn the invariant causal features, which enforces invariance across augmentations of irrelevant parts or styles of the observation. The world-model-based reinforcement learning methods independently optimize representation learning and the policy. Thus naive contrastive loss implementation collapses due to a lack of supervisory signals to the representation learning module. We propose an intervention invariant auxiliary task to mitigate this issue. Specifically, we utilize depth prediction to explicitly enforce the invariance and use data augmentation as style intervention on the RGB observation space. Our design leverages unsupervised representation learning to learn the world model with invariant causal features. Our proposed method significantly outperforms current state-of-the-art model-based and model-free reinforcement learning methods on out-of-distribution point navigation tasks on the iGibson dataset. Moreover, our proposed model excels at the sim-to-real transfer of our perception learning module. Finally, we evaluate our approach on the DeepMind control suite and enforce invariance only implicitly since depth is not available. Nevertheless, our proposed model performs on par with the state-of-the-art counterpart.