 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastCAD: Real-Time CAD Retrieval and Alignment from Scans and Videos
Mar 22, 2024



Digitising the 3D world into a clean, CAD model-based representation has important applications for augmented reality and robotics. Current state-of-the-art methods are computationally intensive as they individually encode each detected object and optimise CAD alignments in a second stage. In this work, we propose FastCAD, a real-time method that simultaneously retrieves and aligns CAD models for all objects in a given scene. In contrast to previous works, we directly predict alignment parameters and shape embeddings. We achieve high-quality shape retrievals by learning CAD embeddings in a contrastive learning framework and distilling those into FastCAD. Our single-stage method accelerates the inference time by a factor of 50 compared to other methods operating on RGB-D scans while outperforming them on the challenging Scan2CAD alignment benchmark. Further, our approach collaborates seamlessly with online 3D reconstruction techniques. This enables the real-time generation of precise CAD model-based reconstructions from videos at 10 FPS. Doing so, we significantly improve the Scan2CAD alignment accuracy in the video setting from 43.0% to 48.2% and the reconstruction accuracy from 22.9% to 29.6%.
Sparse Multi-Object Render-and-Compare
Oct 17, 2023



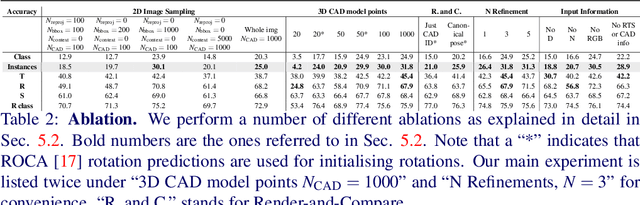
Reconstructing 3D shape and pose of static objects from a single image is an essential task for various industries, including robotics, augmented reality, and digital content creation. This can be done by directly predicting 3D shape in various representations or by retrieving CAD models from a database and predicting their alignments. Directly predicting 3D shapes often produces unrealistic, overly smoothed or tessellated shapes. Retrieving CAD models ensures realistic shapes but requires robust and accurate alignment. Learning to directly predict CAD model poses from image features is challenging and inaccurate. Works, such as ROCA, compute poses from predicted normalised object coordinates which can be more accurate but are susceptible to systematic failure. SPARC demonstrates that following a ''render-and-compare'' approach where a network iteratively improves upon its own predictions achieves accurate alignments. Nevertheless, it performs individual CAD alignment for every object detected in an image. This approach is slow when applied to many objects as the time complexity increases linearly with the number of objects and can not learn inter-object relations. Introducing a new network architecture Multi-SPARC we learn to perform CAD model alignments for multiple detected objects jointly. Compared to other single-view methods we achieve state-of-the-art performance on the challenging real-world dataset ScanNet. By improving the instance alignment accuracy from 31.8% to 40.3% we perform similar to state-of-the-art multi-view methods.
SPARC: Sparse Render-and-Compare for CAD model alignment in a single RGB image
Oct 03, 2022

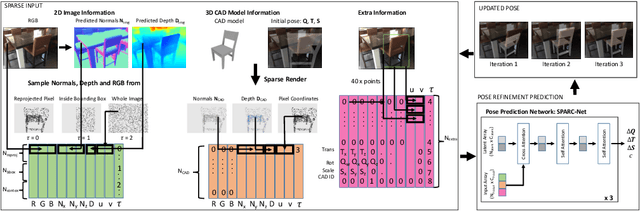
Estimating 3D shapes and poses of static objects from a single image has important applications for robotics, augmented reality and digital content creation. Often this is done through direct mesh predictions which produces unrealistic, overly tessellated shapes or by formulating shape prediction as a retrieval task followed by CAD model alignment. Directly predicting CAD model poses from 2D image features is difficult and inaccurate. Some works, such as ROCA, regress normalised object coordinates and use those for computing poses. While this can produce more accurate pose estimates, predicting normalised object coordinates is susceptible to systematic failure. Leveraging efficient transformer architectures we demonstrate that a sparse, iterative, render-and-compare approach is more accurate and robust than relying on normalised object coordinates. For this we combine 2D image information including sparse depth and surface normal values which we estimate directly from the image with 3D CAD model information in early fusion. In particular, we reproject points sampled from the CAD model in an initial, random pose and compute their depth and surface normal values. This combined information is the input to a pose prediction network, SPARC-Net which we train to predict a 9 DoF CAD model pose update. The CAD model is reprojected again and the next pose update is predicted. Our alignment procedure converges after just 3 iterations, improving the state-of-the-art performance on the challenging real-world dataset ScanNet from 25.0% to 31.8% instance alignment accuracy. Code will be released at https://github.com/florianlanger/SPARC .
Leveraging Geometry for Shape Estimation from a Single RGB Image
Nov 10, 2021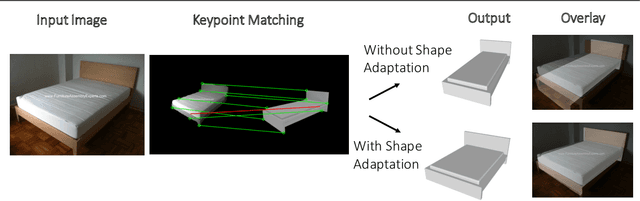
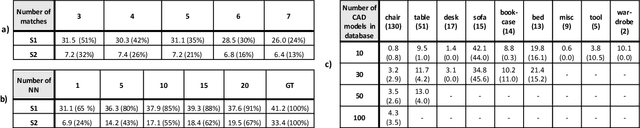
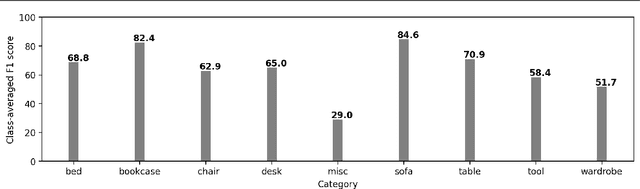
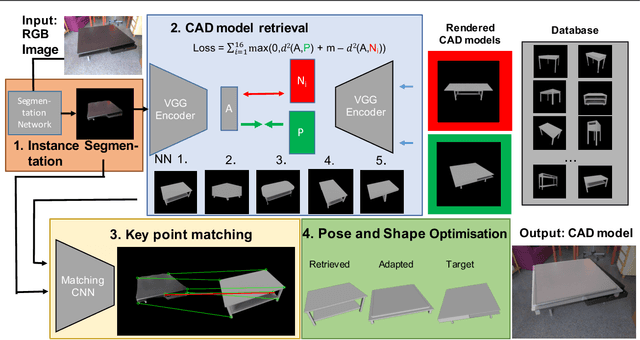
Predicting 3D shapes and poses of static objects from a single RGB image is an important research area in modern computer vision. Its applications range from augmented reality to robotics and digital content creation. Typically this task is performed through direct object shape and pose predictions which is inaccurate. A promising research direction ensures meaningful shape predictions by retrieving CAD models from large scale databases and aligning them to the objects observed in the image. However, existing work does not take the object geometry into account, leading to inaccurate object pose predictions, especially for unseen objects. In this work we demonstrate how cross-domain keypoint matches from an RGB image to a rendered CAD model allow for more precise object pose predictions compared to ones obtained through direct predictions. We further show that keypoint matches can not only be used to estimate the pose of an object, but also to modify the shape of the object itself. This is important as the accuracy that can be achieved with object retrieval alone is inherently limited to the available CAD models. Allowing shape adaptation bridges the gap between the retrieved CAD model and the observed shape. We demonstrate our approach on the challenging Pix3D dataset. The proposed geometric shape prediction improves the AP mesh over the state-of-the-art from 33.2 to 37.8 on seen objects and from 8.2 to 17.1 on unseen objects. Furthermore, we demonstrate more accurate shape predictions without closely matching CAD models when following the proposed shape adaptation. Code is publicly available at https://github.com/florianlanger/leveraging_geometry_for_shape_estimation .