 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Optimization of an Autoencoder for Clustering and Embedding
Dec 07, 2020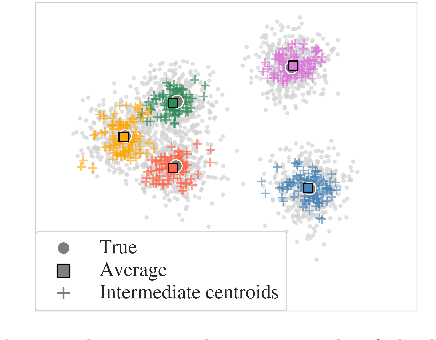
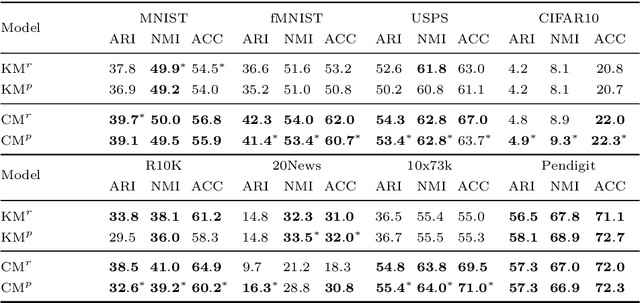
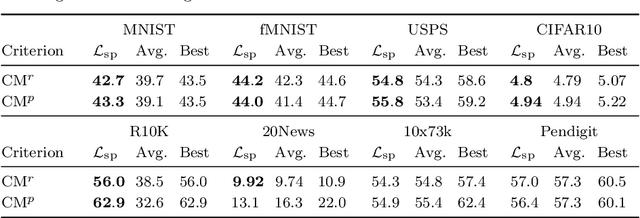
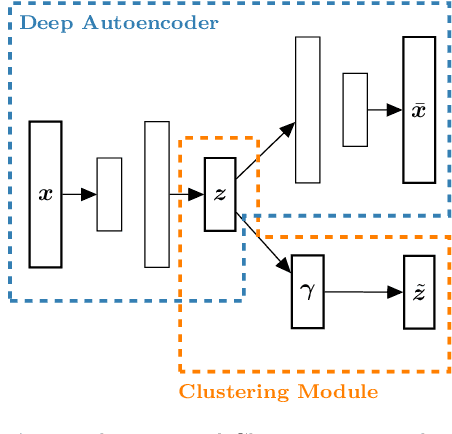
Incorporating k-means-like clustering techniques into (deep) autoencoders constitutes an interesting idea as the clustering may exploit the learned similarities in the embedding to compute a non-linear grouping of data at-hand. Unfortunately, the resulting contributions are often limited by ad-hoc choices, decoupled optimization problems and other issues. We present a theoretically-driven deep clustering approach that does not suffer from these limitations and allows for joint optimization of clustering and embedding. The network in its simplest form is derived from a Gaussian mixture model and can be incorporated seamlessly into deep autoencoders for state-of-the-art performance.
Uncertainty-Aware Deep Ensembles for Reliable and Explainable Predictions of Clinical Time Series
Oct 16, 2020
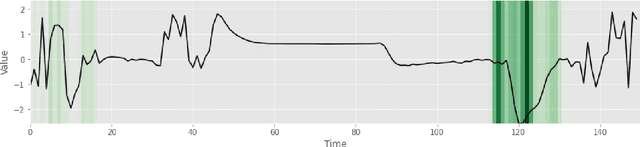
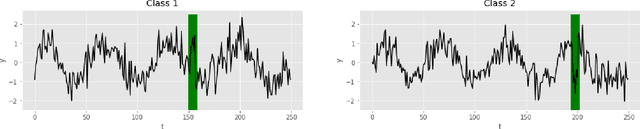
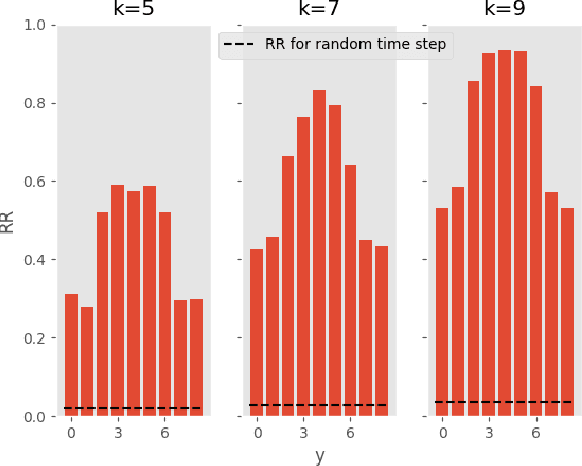
Deep learning-based support systems have demonstrated encouraging results in numerous clinical applications involving the processing of time series data. While such systems often are very accurate, they have no inherent mechanism for explaining what influenced the predictions, which is critical for clinical tasks. However, existing explainability techniques lack an important component for trustworthy and reliable decision support, namely a notion of uncertainty. In this paper, we address this lack of uncertainty by proposing a deep ensemble approach where a collection of DNNs are trained independently. A measure of uncertainty in the relevance scores is computed by taking the standard deviation across the relevance scores produced by each model in the ensemble, which in turn is used to make the explanations more reliable. The class activation mapping method is used to assign a relevance score for each time step in the time series. Results demonstrate that the proposed ensemble is more accurate in locating relevant time steps and is more consistent across random initializations, thus making the model more trustworthy. The proposed methodology paves the way for constructing trustworthy and dependable support systems for processing clinical time series for healthcare related tasks.
SCG-Net: Self-Constructing Graph Neural Networks for Semantic Segmentation
Sep 03, 2020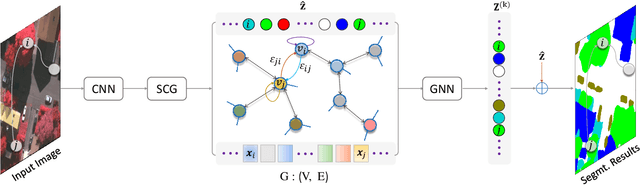
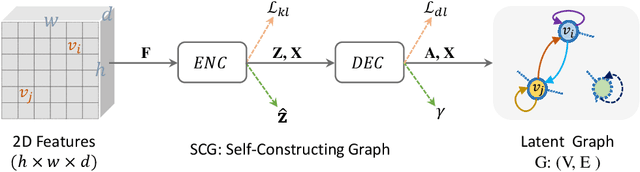
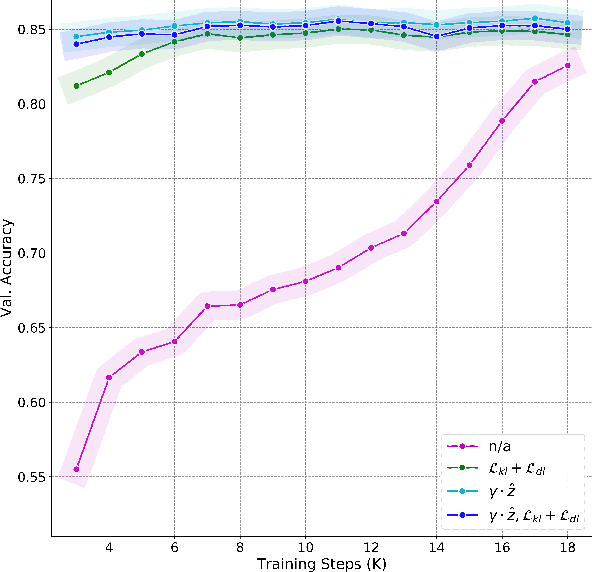
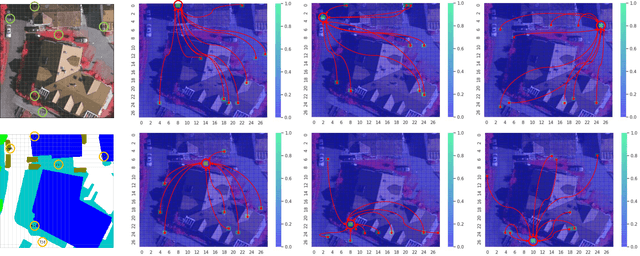
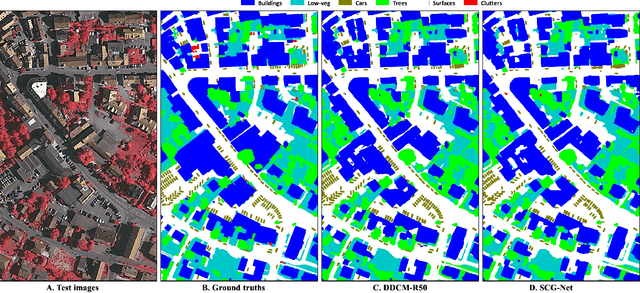
Capturing global contextual representations by exploiting long-range pixel-pixel dependencies has shown to improve semantic segmentation performance. However, how to do this efficiently is an open question as current approaches of utilising attention schemes or very deep models to increase the models field of view, result in complex models with large memory consumption. Inspired by recent work on graph neural networks, we propose the Self-Constructing Graph (SCG) module that learns a long-range dependency graph directly from the image and uses it to propagate contextual information efficiently to improve semantic segmentation. The module is optimised via a novel adaptive diagonal enhancement method and a variational lower bound that consists of a customized graph reconstruction term and a Kullback-Leibler divergence regularization term. When incorporated into a neural network (SCG-Net), semantic segmentation is performed in an end-to-end manner and competitive performance (mean F1-scores of 92.0% and 89.8% respectively) on the publicly available ISPRS Potsdam and Vaihingen datasets is achieved, with much fewer parameters, and at a lower computational cost compared to related pure convolutional neural network (CNN) based models.
The 1st Agriculture-Vision Challenge: Methods and Results
Apr 23, 2020
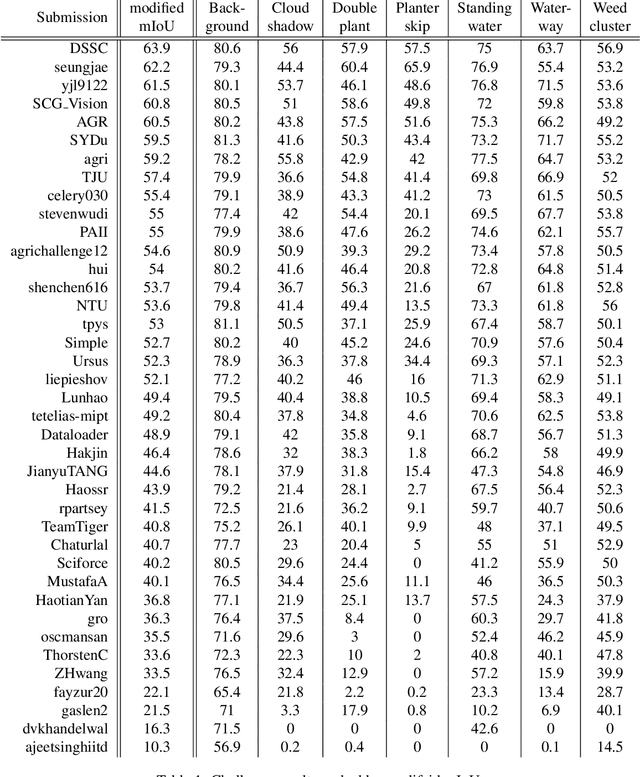
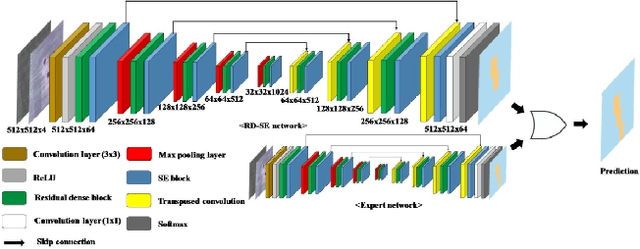
The first Agriculture-Vision Challenge aims to encourage research in developing novel and effective algorithms for agricultural pattern recognition from aerial images, especially for the semantic segmentation task associated with our challenge dataset. Around 57 participating teams from various countries compete to achieve state-of-the-art in aerial agriculture semantic segmentation. The Agriculture-Vision Challenge Dataset was employed, which comprises of 21,061 aerial and multi-spectral farmland images. This paper provides a summary of notable methods and results in the challenge. Our submission server and leaderboard will continue to open for researchers that are interested in this challenge dataset and task; the link can be found here.
Self-Constructing Graph Convolutional Networks for Semantic Labeling
Apr 23, 2020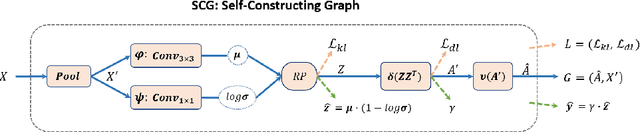
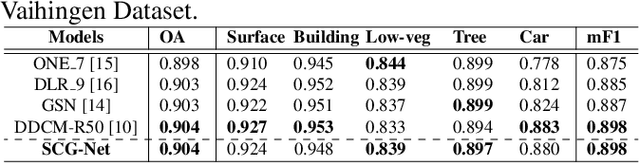
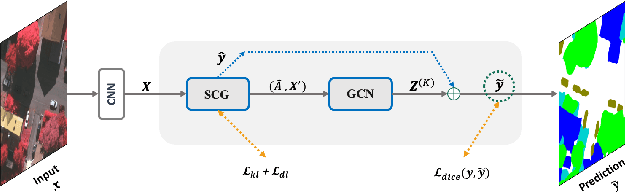
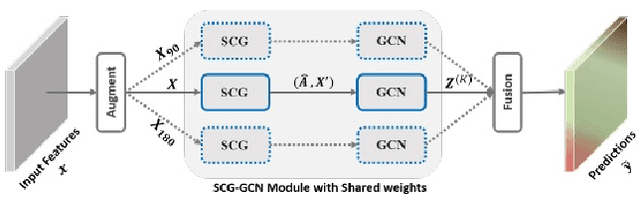
Graph Neural Networks (GNNs) have received increasing attention in many fields. However, due to the lack of prior graphs, their use for semantic labeling has been limited. Here, we propose a novel architecture called the Self-Constructing Graph (SCG), which makes use of learnable latent variables to generate embeddings and to self-construct the underlying graphs directly from the input features without relying on manually built prior knowledge graphs. SCG can automatically obtain optimized non-local context graphs from complex-shaped objects in aerial imagery. We optimize SCG via an adaptive diagonal enhancement method and a variational lower bound that consists of a customized graph reconstruction term and a Kullback-Leibler divergence regularization term. We demonstrate the effectiveness and flexibility of the proposed SCG on the publicly available ISPRS Vaihingen dataset and our model SCG-Net achieves competitive results in terms of F1-score with much fewer parameters and at a lower computational cost compared to related pure-CNN based work. Our code will be made public soon.
Multi-view Self-Constructing Graph Convolutional Networks with Adaptive Class Weighting Loss for Semantic Segmentation
Apr 21, 2020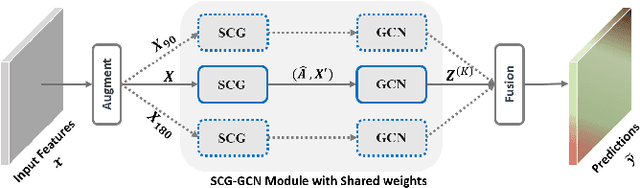
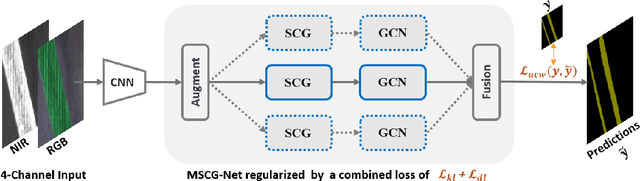


We propose a novel architecture called the Multi-view Self-Constructing Graph Convolutional Networks (MSCG-Net) for semantic segmentation. Building on the recently proposed Self-Constructing Graph (SCG) module, which makes use of learnable latent variables to self-construct the underlying graphs directly from the input features without relying on manually built prior knowledge graphs, we leverage multiple views in order to explicitly exploit the rotational invariance in airborne images. We further develop an adaptive class weighting loss to address the class imbalance. We demonstrate the effectiveness and flexibility of the proposed method on the Agriculture-Vision challenge dataset and our model achieves very competitive results (0.547 mIoU) with much fewer parameters and at a lower computational cost compared to related pure-CNN based work. Code will be available at: github.com/samleoqh/MSCG-Net
Code-Aligned Autoencoders for Unsupervised Change Detection in Multimodal Remote Sensing Images
Apr 15, 2020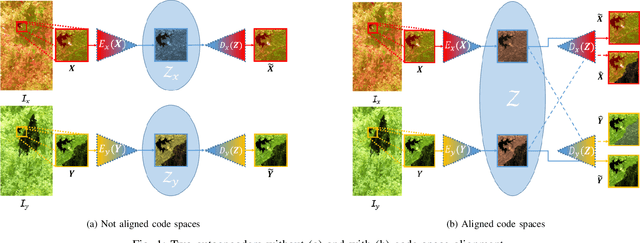

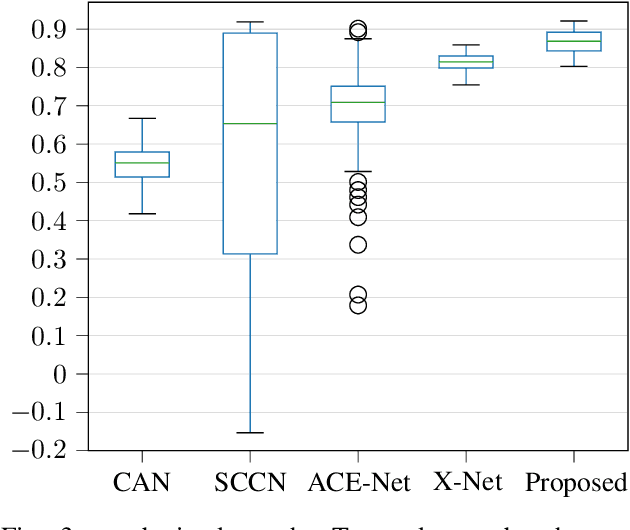
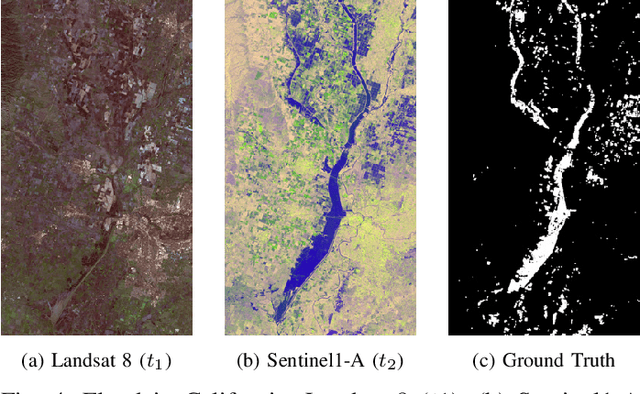
Image translation with convolutional autoencoders has recently been used as an approach to multimodal change detection in bitemporal satellite images. A main challenge is the alignment of the code spaces by reducing the contribution of change pixels to the learning of the translation function. Many existing approaches train the networks by exploiting supervised information of the change areas, which, however, is not always available. We propose to extract relational pixel information captured by domain-specific affinity matrices at the input and use this to enforce alignment of the code spaces and reduce the impact of change pixels on the learning objective. A change prior is derived in an unsupervised fashion from pixel pair affinities that are comparable across domains. To achieve code space alignment we enforce that pixel with similar affinity relations in the input domains should be correlated also in code space. We demonstrate the utility of this procedure in combination with cycle consistency. The proposed approach are compared with state-of-the-art deep learning algorithms. Experiments conducted on four real datasets show the effectiveness of our methodology.
A Kernel to Exploit Informative Missingness in Multivariate Time Series from EHRs
Feb 27, 2020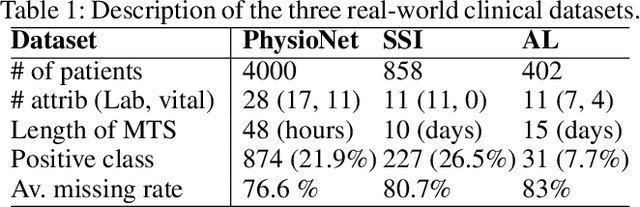
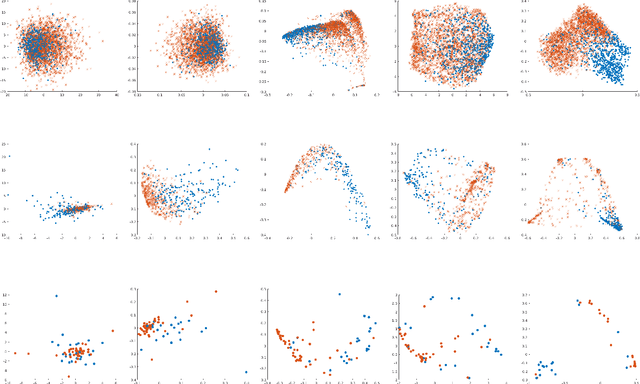
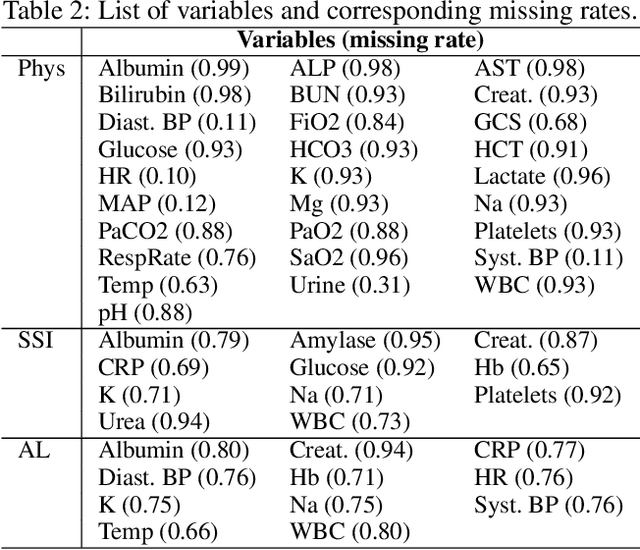
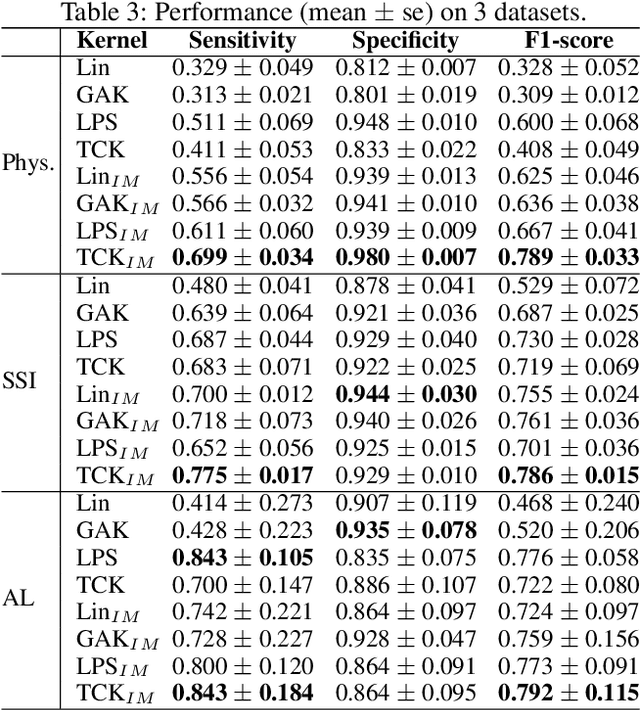
A large fraction of the electronic health records (EHRs) consists of clinical measurements collected over time, such as lab tests and vital signs, which provide important information about a patient's health status. These sequences of clinical measurements are naturally represented as time series, characterized by multiple variables and large amounts of missing data, which complicate the analysis. In this work, we propose a novel kernel which is capable of exploiting both the information from the observed values as well the information hidden in the missing patterns in multivariate time series (MTS) originating e.g. from EHRs. The kernel, called TCK$_{IM}$, is designed using an ensemble learning strategy in which the base models are novel mixed mode Bayesian mixture models which can effectively exploit informative missingness without having to resort to imputation methods. Moreover, the ensemble approach ensures robustness to hyperparameters and therefore TCK$_{IM}$ is particularly well suited if there is a lack of labels - a known challenge in medical applications. Experiments on three real-world clinical datasets demonstrate the effectiveness of the proposed kernel.
LS-Net: Fast Single-Shot Line-Segment Detector
Jan 24, 2020
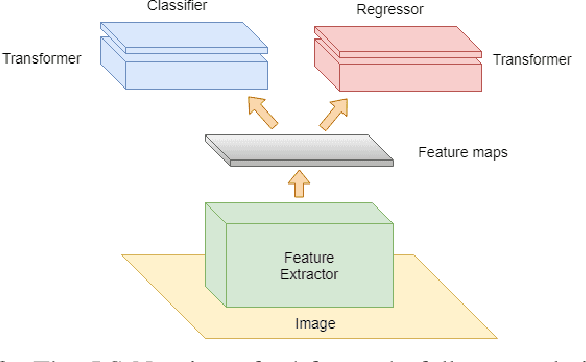
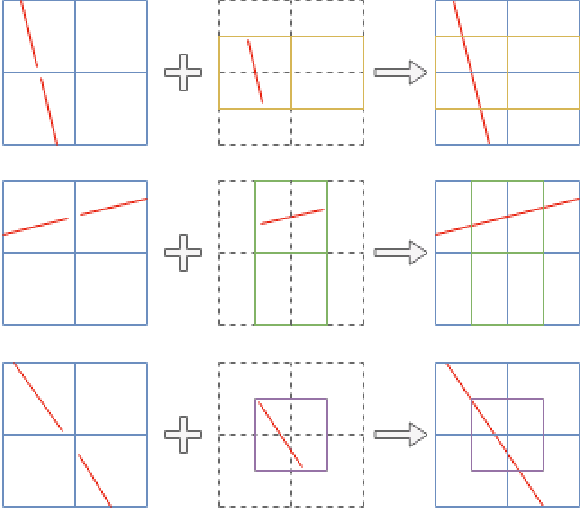
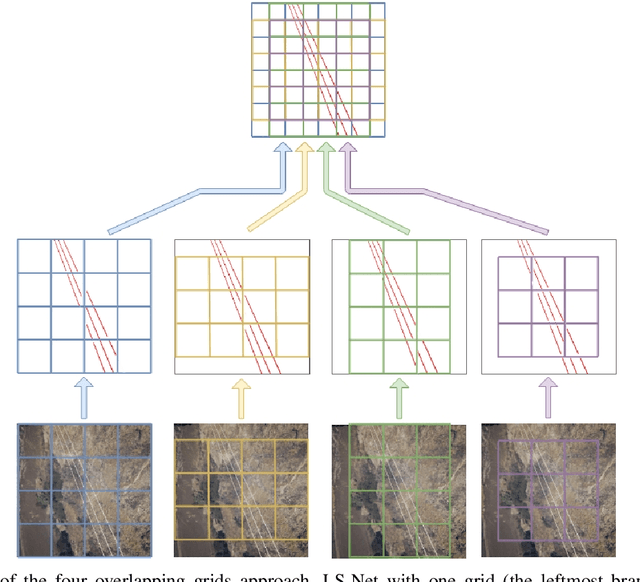
In low-altitude Unmanned Aerial Vehicle (UAV) flights, power lines are considered as one of the most threatening hazards and one of the most difficult obstacles to avoid. In recent years, many vision-based techniques have been proposed to detect power lines to facilitate self-driving UAVs and automatic obstacle avoidance. However, most of the proposed methods are typically based on a common three-step approach: (i) edge detection, (ii) the Hough transform, and (iii) spurious line elimination based on power line constrains. These approaches not only are slow and inaccurate but also require a huge amount of effort in post-processing to distinguish between power lines and spurious lines. In this paper, we introduce LS-Net, a fast single-shot line-segment detector, and apply it to power line detection. The LS-Net is by design fully convolutional and consists of three modules: (i) a fully convolutional feature extractor, (ii) a classifier, and (iii) a line segment regressor. Due to the unavailability of large datasets with annotations of power lines, we render synthetic images of power lines using the Physically Based Rendering (PBR) approach and propose a series of effective data augmentation techniques to generate more training data. With a customized version of the VGG-16 network as the backbone, the proposed approach outperforms existing state-of-the-art approaches. In addition, the LS-Net can detect power lines in near real-time (20.4 FPS). This suggests that our proposed approach has a promising role in automatic obstacle avoidance and as a valuable component of self-driving UAVs, especially for automatic autonomous power line inspection.
Deep Image Clustering with Tensor Kernels and Unsupervised Companion Objectives
Jan 20, 2020
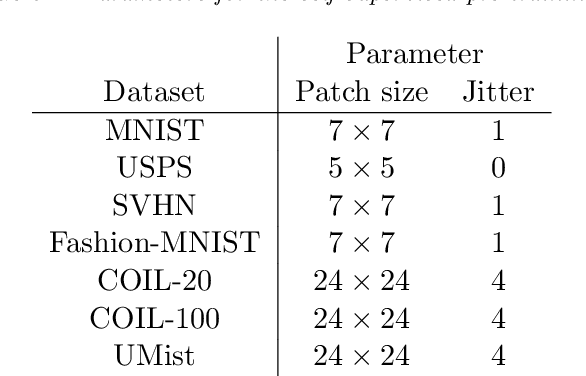
In this paper we develop a new model for deep image clustering, using convolutional neural networks and tensor kernels. The proposed Deep Tensor Kernel Clustering (DTKC) consists of a convolutional neural network (CNN), which is trained to reflect a common cluster structure at the output of its intermediate layers. Encouraging a consistent cluster structure throughout the network has the potential to guide it towards meaningful clusters, even though these clusters might appear to be nonlinear in the input space. The cluster structure is enforced through the idea of unsupervised companion objectives, where separate loss functions are attached to layers in the network. These unsupervised companion objectives are constructed based on a proposed generalization of the Cauchy-Schwarz (CS) divergence, from vectors to tensors of arbitrary rank. Generalizing the CS divergence to tensor-valued data is a crucial step, due to the tensorial nature of the intermediate representations in the CNN. Several experiments are conducted to thoroughly assess the performance of the proposed DTKC model. The results indicate that the model outperforms, or performs comparable to, a wide range of baseline algorithms. We also empirically demonstrate that our model does not suffer from objective function mismatch, which can be a problematic artifact in autoencoder-based clustering models.