 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Programmer: Discrete Latent Codes for Program Synthesis
Dec 01, 2020

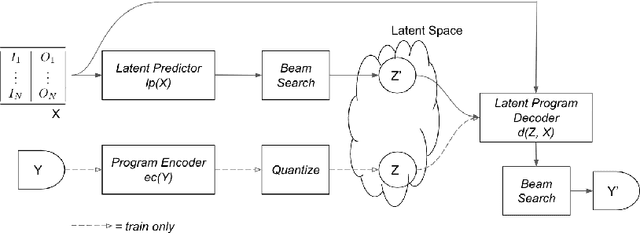

In many sequence learning tasks, such as program synthesis and document summarization, a key problem is searching over a large space of possible output sequences. We propose to learn representations of the outputs that are specifically meant for search: rich enough to specify the desired output but compact enough to make search more efficient. Discrete latent codes are appealing for this purpose, as they naturally allow sophisticated combinatorial search strategies. The latent codes are learned using a self-supervised learning principle, in which first a discrete autoencoder is trained on the output sequences, and then the resulting latent codes are used as intermediate targets for the end-to-end sequence prediction task. Based on these insights, we introduce the \emph{Latent Programmer}, a program synthesis method that first predicts a discrete latent code from input/output examples, and then generates the program in the target language. We evaluate the Latent Programmer on two domains: synthesis of string transformation programs, and generation of programs from natural language descriptions. We demonstrate that the discrete latent representation significantly improves synthesis accuracy.
Learning Discrete Energy-based Models via Auxiliary-variable Local Exploration
Nov 10, 2020
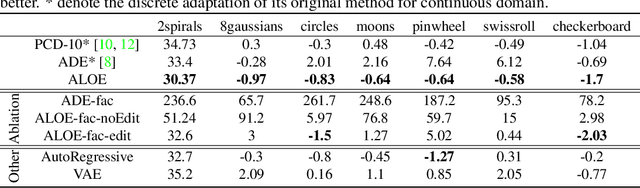
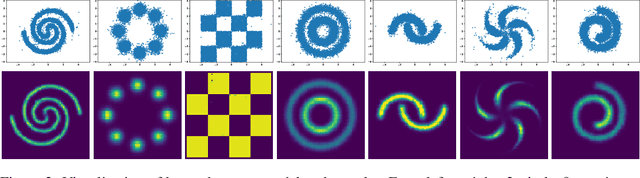

Discrete structures play an important role in applications like program language modeling and software engineering. Current approaches to predicting complex structures typically consider autoregressive models for their tractability, with some sacrifice in flexibility. Energy-based models (EBMs) on the other hand offer a more flexible and thus more powerful approach to modeling such distributions, but require partition function estimation. In this paper we propose ALOE, a new algorithm for learning conditional and unconditional EBMs for discrete structured data, where parameter gradients are estimated using a learned sampler that mimics local search. We show that the energy function and sampler can be trained efficiently via a new variational form of power iteration, achieving a better trade-off between flexibility and tractability. Experimentally, we show that learning local search leads to significant improvements in challenging application domains. Most notably, we present an energy model guided fuzzer for software testing that achieves comparable performance to well engineered fuzzing engines like libfuzzer.
Deep Learning & Software Engineering: State of Research and Future Directions
Sep 17, 2020Given the current transformative potential of research that sits at the intersection of Deep Learning (DL) and Software Engineering (SE), an NSF-sponsored community workshop was conducted in co-location with the 34th IEEE/ACM International Conference on Automated Software Engineering (ASE'19) in San Diego, California. The goal of this workshop was to outline high priority areas for cross-cutting research. While a multitude of exciting directions for future work were identified, this report provides a general summary of the research areas representing the areas of highest priority which were discussed at the workshop. The intent of this report is to serve as a potential roadmap to guide future work that sits at the intersection of SE & DL.
BUSTLE: Bottom-up program-Synthesis Through Learning-guided Exploration
Jul 28, 2020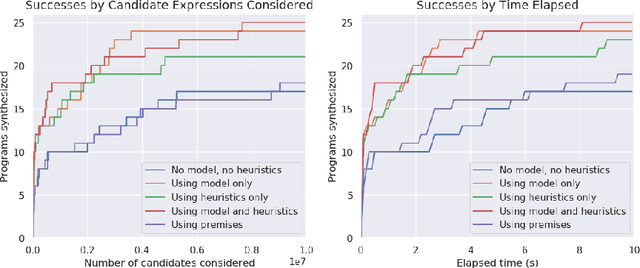
Program synthesis is challenging largely because of the difficulty of search in a large space of programs. Human programmers routinely tackle the task of writing complex programs by writing sub-programs and then analysing their intermediate results to compose them in appropriate ways. Motivated by this intuition, we present a new synthesis approach that leverages learning to guide a bottom-up search over programs. In particular, we train a model to prioritize compositions of intermediate values during search conditioned on a given set of input-output examples. This is a powerful combination because of several emergent properties: First, in bottom-up search, intermediate programs can be executed, providing semantic information to the neural network. Second, given the concrete values from those executions, we can exploit rich features based on recent work on property signatures. Finally, bottom-up search allows the system substantial flexibility in what order to generate the solution, allowing the synthesizer to build up a program from multiple smaller sub-programs. Overall, our empirical evaluation finds that the combination of learning and bottom-up search is remarkably effective, even with simple supervised learning approaches. We demonstrate the effectiveness of our technique on a new data set for synthesis of string transformation programs.
Scaling Symbolic Methods using Gradients for Neural Model Explanation
Jun 29, 2020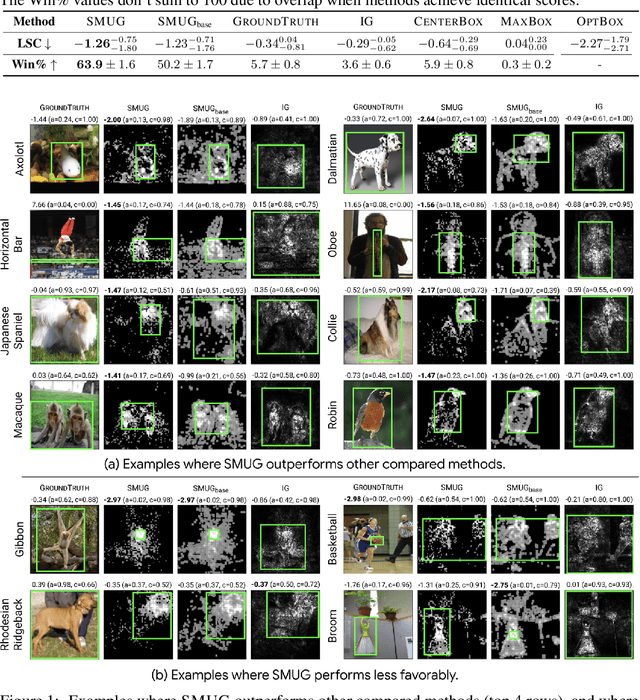
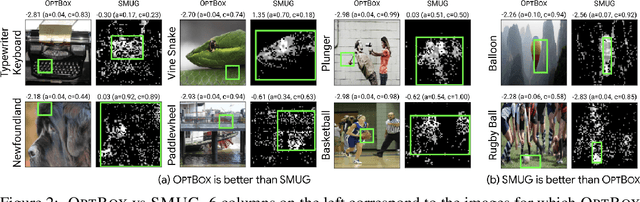
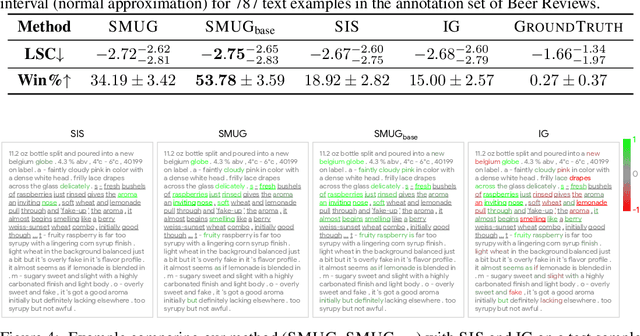

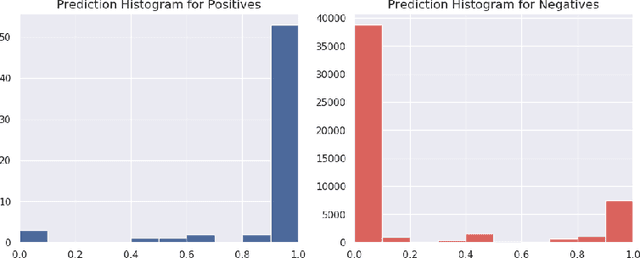
Symbolic techniques based on Satisfiability Modulo Theory (SMT) solvers have been proposed for analyzing and verifying neural network properties, but their usage has been fairly limited owing to their poor scalability with larger networks. In this work, we propose a technique for combining gradient-based methods with symbolic techniques to scale such analyses and demonstrate its application for model explanation. In particular, we apply this technique to identify minimal regions in an input that are most relevant for a neural network's prediction. Our approach uses gradient information (based on Integrated Gradients) to focus on a subset of neurons in the first layer, which allows our technique to scale to large networks. The corresponding SMT constraints encode the minimal input mask discovery problem such that after masking the input, the activations of the selected neurons are still above a threshold. After solving for the minimal masks, our approach scores the mask regions to generate a relative ordering of the features within the mask. This produces a saliency map which explains "where a model is looking" when making a prediction. We evaluate our technique on three datasets - MNIST, ImageNet, and Beer Reviews, and demonstrate both quantitatively and qualitatively that the regions generated by our approach are sparser and achieve higher saliency scores compared to the gradient-based methods alone.
Neural Program Synthesis with a Differentiable Fixer
Jun 19, 2020
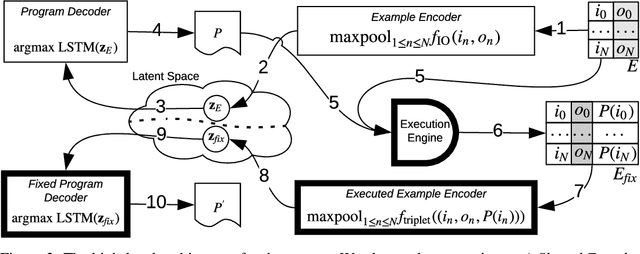
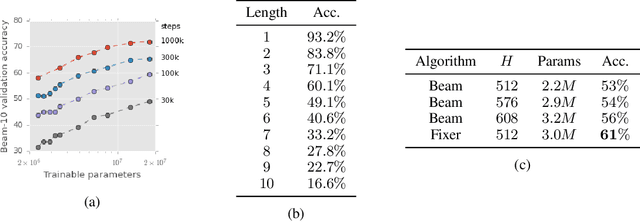
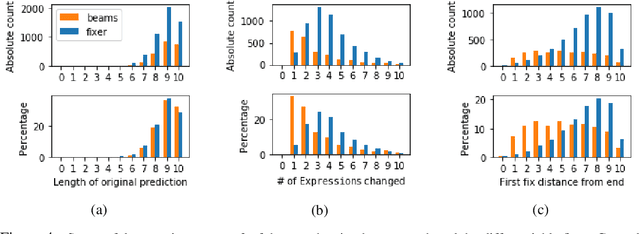
We present a new program synthesis approach that combines an encoder-decoder based synthesis architecture with a differentiable program fixer. Our approach is inspired from the fact that human developers seldom get their program correct on the first attempt, and perform iterative testing-based program fixing to get to the desired program functionality. Similarly, our approach first learns a distribution over programs conditioned on an encoding of a set of input-output examples, and then iteratively performs fix operations using the differentiable fixer. The fixer takes as input the original examples and the current program's outputs on example inputs, and generates a new distribution over the programs with the goal of reducing the discrepancies between the current program outputs and the desired example outputs. We train our architecture end-to-end on the RobustFill domain, and show that the addition of the fixer module leads to a significant improvement on synthesis accuracy compared to using beam search.
TF-Coder: Program Synthesis for Tensor Manipulations
Mar 19, 2020
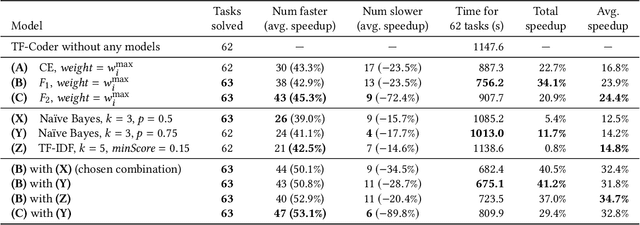

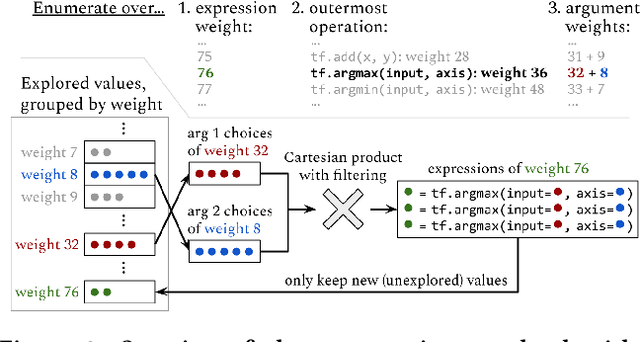
The success and popularity of deep learning is on the rise, partially due to powerful deep learning frameworks such as TensorFlow and PyTorch that make it easier to develop deep learning models. However, these libraries also come with steep learning curves, since programming in these frameworks is quite different from traditional imperative programming with explicit loops and conditionals. In this work, we present a tool called TF-Coder for programming by example in TensorFlow. TF-Coder uses a bottom-up weighted enumerative search, with value-based pruning of equivalent expressions and flexible type- and value-based filtering to ensure that expressions adhere to various requirements imposed by the TensorFlow library. We also train models that predict TensorFlow operations from features of the input and output tensors and natural language descriptions of tasks, and use the models to prioritize relevant operations during the search. TF-Coder solves 63 of 70 real-world tasks within 5 minutes, often finding solutions that are simpler than those written by TensorFlow experts.
Towards Modular Algorithm Induction
Feb 27, 2020
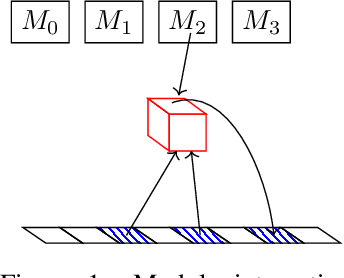
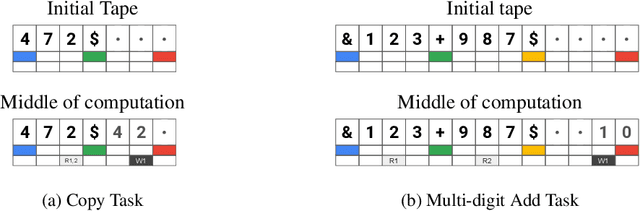
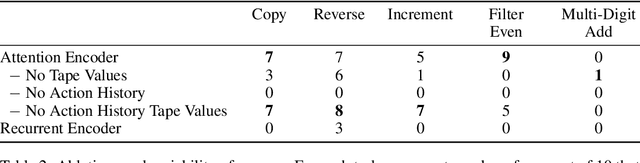
We present a modular neural network architecture Main that learns algorithms given a set of input-output examples. Main consists of a neural controller that interacts with a variable-length input tape and learns to compose modules together with their corresponding argument choices. Unlike previous approaches, Main uses a general domain-agnostic mechanism for selection of modules and their arguments. It uses a general input tape layout together with a parallel history tape to indicate most recently used locations. Finally, it uses a memoryless controller with a length-invariant self-attention based input tape encoding to allow for random access to tape locations. The Main architecture is trained end-to-end using reinforcement learning from a set of input-output examples. We evaluate Main on five algorithmic tasks and show that it can learn policies that generalizes perfectly to inputs of much longer lengths than the ones used for training.
Towards a Kernel based Physical Interpretation of Model Uncertainty
Feb 21, 2020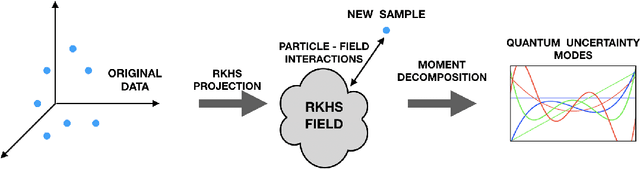
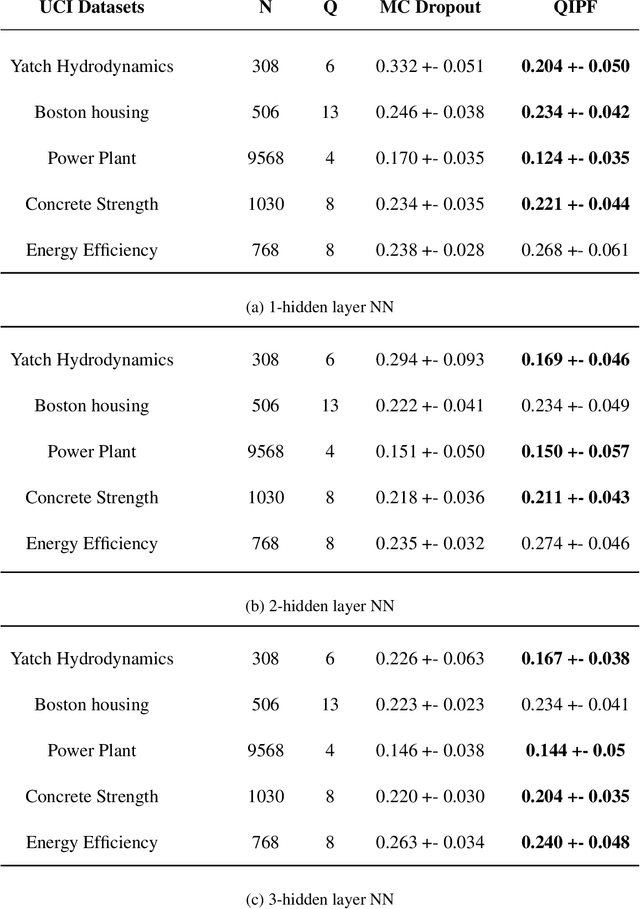
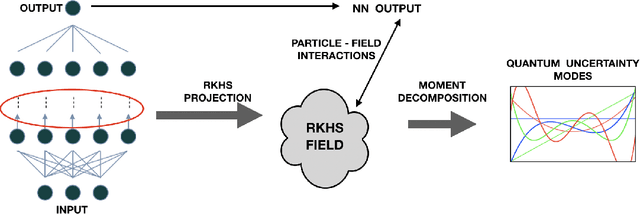
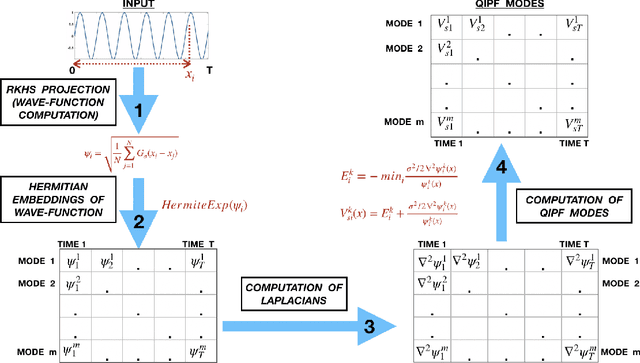
This paper introduces a new information theoretic framework that provides a sensitive multi-modal quantification of data uncertainty by leveraging a quantum physical description of its metric space. We specifically work with the kernel mean embedding metric which yields an intuitive physical interpretation of the signal as a potential field, resulting in its new energy based formulation. This enables one to extract multi-scale uncertainty features of data in the form of information eigenmodes by utilizing moment decomposition concepts of quantum physics. In essence, this approach decomposes local realizations of the signal's PDF in terms of quantum uncertainty moments. We specifically present the application of this framework as a non-parametric and non-intrusive surrogate tool for predictive uncertainty quantification of point-prediction neural network models, overcoming various limitations of conventional Bayesian and ensemble based UQ methods. Experimental comparisons with some established uncertainty quantification methods illustrate performance advantages exhibited by our framework.
Synthetic Datasets for Neural Program Synthesis
Dec 27, 2019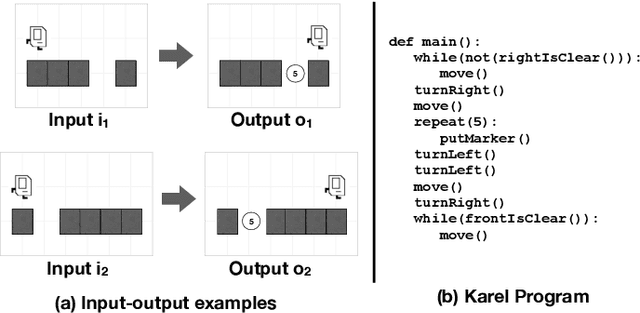



The goal of program synthesis is to automatically generate programs in a particular language from corresponding specifications, e.g. input-output behavior. Many current approaches achieve impressive results after training on randomly generated I/O examples in limited domain-specific languages (DSLs), as with string transformations in RobustFill. However, we empirically discover that applying test input generation techniques for languages with control flow and rich input space causes deep networks to generalize poorly to certain data distributions; to correct this, we propose a new methodology for controlling and evaluating the bias of synthetic data distributions over both programs and specifications. We demonstrate, using the Karel DSL and a small Calculator DSL, that training deep networks on these distributions leads to improved cross-distribution generalization performance.