 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Hallucinations and Off-target Machine Translation with Source-Contrastive and Language-Contrastive Decoding
Sep 13, 2023



Hallucinations and off-target translation remain unsolved problems in machine translation, especially for low-resource languages and massively multilingual models. In this paper, we introduce methods to mitigate both failure cases with a modified decoding objective, without requiring retraining or external models. In source-contrastive decoding, we search for a translation that is probable given the correct input, but improbable given a random input segment, hypothesising that hallucinations will be similarly probable given either. In language-contrastive decoding, we search for a translation that is probable, but improbable given the wrong language indicator token. In experiments on M2M-100 (418M) and SMaLL-100, we find that these methods effectively suppress hallucinations and off-target translations, improving chrF2 by 1.7 and 1.4 points on average across 57 tested translation directions. In a proof of concept on English--German, we also show that we can suppress off-target translations with the Llama 2 chat models, demonstrating the applicability of the method to machine translation with LLMs. We release our source code at https://github.com/ZurichNLP/ContraDecode.
Uncertainty in Natural Language Generation: From Theory to Applications
Jul 28, 2023

Recent advances of powerful Language Models have allowed Natural Language Generation (NLG) to emerge as an important technology that can not only perform traditional tasks like summarisation or translation, but also serve as a natural language interface to a variety of applications. As such, it is crucial that NLG systems are trustworthy and reliable, for example by indicating when they are likely to be wrong; and supporting multiple views, backgrounds and writing styles -- reflecting diverse human sub-populations. In this paper, we argue that a principled treatment of uncertainty can assist in creating systems and evaluation protocols better aligned with these goals. We first present the fundamental theory, frameworks and vocabulary required to represent uncertainty. We then characterise the main sources of uncertainty in NLG from a linguistic perspective, and propose a two-dimensional taxonomy that is more informative and faithful than the popular aleatoric/epistemic dichotomy. Finally, we move from theory to applications and highlight exciting research directions that exploit uncertainty to power decoding, controllable generation, self-assessment, selective answering, active learning and more.
Towards Unsupervised Recognition of Semantic Differences in Related Documents
May 22, 2023Automatically highlighting words that cause semantic differences between two documents could be useful for a wide range of applications. We formulate recognizing semantic differences (RSD) as a token-level regression task and study three unsupervised approaches that rely on a masked language model. To assess the approaches, we begin with basic English sentences and gradually move to more complex, cross-lingual document pairs. Our results show that an approach based on word alignment and sentence-level contrastive learning has a robust correlation to gold labels. However, all unsupervised approaches still leave a large margin of improvement. Code to reproduce our experiments is available at https://github.com/ZurichNLP/recognizing-semantic-differences
Exploiting Biased Models to De-bias Text: A Gender-Fair Rewriting Model
May 18, 2023



Natural language generation models reproduce and often amplify the biases present in their training data. Previous research explored using sequence-to-sequence rewriting models to transform biased model outputs (or original texts) into more gender-fair language by creating pseudo training data through linguistic rules. However, this approach is not practical for languages with more complex morphology than English. We hypothesise that creating training data in the reverse direction, i.e. starting from gender-fair text, is easier for morphologically complex languages and show that it matches the performance of state-of-the-art rewriting models for English. To eliminate the rule-based nature of data creation, we instead propose using machine translation models to create gender-biased text from real gender-fair text via round-trip translation. Our approach allows us to train a rewriting model for German without the need for elaborate handcrafted rules. The outputs of this model increased gender-fairness as shown in a human evaluation study.
What's the Meaning of Superhuman Performance in Today's NLU?
May 15, 2023



In the last five years, there has been a significant focus in Natural Language Processing (NLP) on developing larger Pretrained Language Models (PLMs) and introducing benchmarks such as SuperGLUE and SQuAD to measure their abilities in language understanding, reasoning, and reading comprehension. These PLMs have achieved impressive results on these benchmarks, even surpassing human performance in some cases. This has led to claims of superhuman capabilities and the provocative idea that certain tasks have been solved. In this position paper, we take a critical look at these claims and ask whether PLMs truly have superhuman abilities and what the current benchmarks are really evaluating. We show that these benchmarks have serious limitations affecting the comparison between humans and PLMs and provide recommendations for fairer and more transparent benchmarks.
SLTUNET: A Simple Unified Model for Sign Language Translation
May 02, 2023



Despite recent successes with neural models for sign language translation (SLT), translation quality still lags behind spoken languages because of the data scarcity and modality gap between sign video and text. To address both problems, we investigate strategies for cross-modality representation sharing for SLT. We propose SLTUNET, a simple unified neural model designed to support multiple SLTrelated tasks jointly, such as sign-to-gloss, gloss-to-text and sign-to-text translation. Jointly modeling different tasks endows SLTUNET with the capability to explore the cross-task relatedness that could help narrow the modality gap. In addition, this allows us to leverage the knowledge from external resources, such as abundant parallel data used for spoken-language machine translation (MT). We show in experiments that SLTUNET achieves competitive and even state-of-the-art performance on PHOENIX-2014T and CSL-Daily when augmented with MT data and equipped with a set of optimization techniques. We further use the DGS Corpus for end-to-end SLT for the first time. It covers broader domains with a significantly larger vocabulary, which is more challenging and which we consider to allow for a more realistic assessment of the current state of SLT than the former two. Still, SLTUNET obtains improved results on the DGS Corpus. Code is available at https://github.com/bzhangGo/sltunet.
SwissBERT: The Multilingual Language Model for Switzerland
Mar 23, 2023



We present SwissBERT, a masked language model created specifically for processing Switzerland-related text. SwissBERT is a pre-trained model that we adapted to news articles written in the national languages of Switzerland -- German, French, Italian, and Romansh. We evaluate SwissBERT on natural language understanding tasks related to Switzerland and find that it tends to outperform previous models on these tasks, especially when processing contemporary news and/or Romansh Grischun. Since SwissBERT uses language adapters, it may be extended to Swiss German dialects in future work. The model and our open-source code are publicly released at https://github.com/ZurichNLP/swissbert.
Efficient CTC Regularization via Coarse Labels for End-to-End Speech Translation
Feb 21, 2023For end-to-end speech translation, regularizing the encoder with the Connectionist Temporal Classification (CTC) objective using the source transcript or target translation as labels can greatly improve quality metrics. However, CTC demands an extra prediction layer over the vocabulary space, bringing in nonnegligible model parameters and computational overheads, although this layer is typically not used for inference. In this paper, we re-examine the need for genuine vocabulary labels for CTC for regularization and explore strategies to reduce the CTC label space, targeting improved efficiency without quality degradation. We propose coarse labeling for CTC (CoLaCTC), which merges vocabulary labels via simple heuristic rules, such as using truncation, division or modulo (MOD) operations. Despite its simplicity, our experiments on 4 source and 8 target languages show that CoLaCTC with MOD particularly can compress the label space aggressively to 256 and even further, gaining training efficiency (1.18x ~ 1.77x speedup depending on the original vocabulary size) yet still delivering comparable or better performance than the CTC baseline. We also show that CoLaCTC successfully generalizes to CTC regularization regardless of using transcript or translation for labeling.
Improving the Cross-Lingual Generalisation in Visual Question Answering
Sep 07, 2022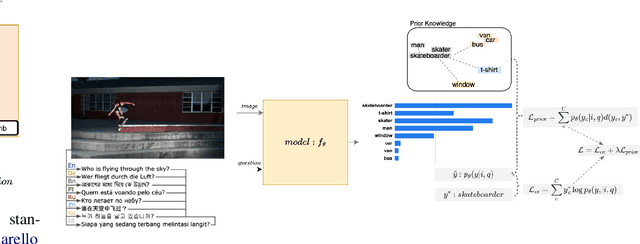
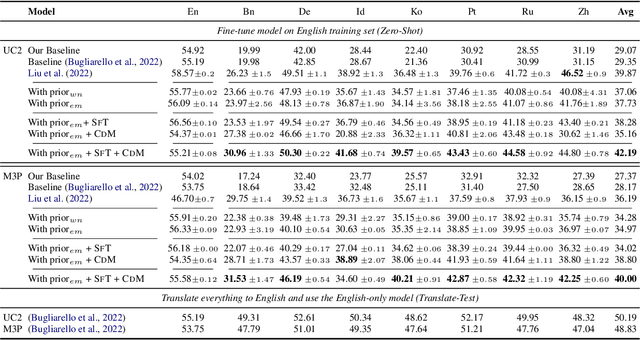
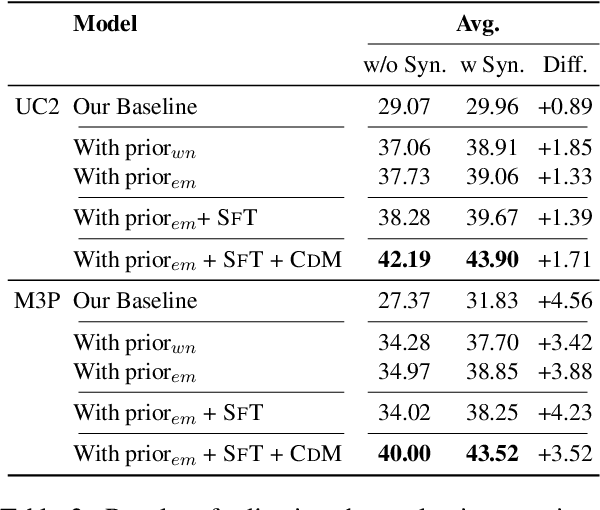
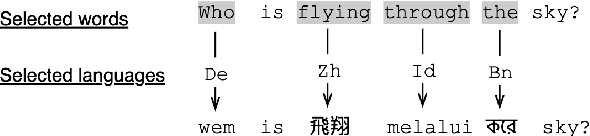
While several benefits were realized for multilingual vision-language pretrained models, recent benchmarks across various tasks and languages showed poor cross-lingual generalisation when multilingually pre-trained vision-language models are applied to non-English data, with a large gap between (supervised) English performance and (zero-shot) cross-lingual transfer. In this work, we explore the poor performance of these models on a zero-shot cross-lingual visual question answering (VQA) task, where models are fine-tuned on English visual-question data and evaluated on 7 typologically diverse languages. We improve cross-lingual transfer with three strategies: (1) we introduce a linguistic prior objective to augment the cross-entropy loss with a similarity-based loss to guide the model during training, (2) we learn a task-specific subnetwork that improves cross-lingual generalisation and reduces variance without model modification, (3) we augment training examples using synthetic code-mixing to promote alignment of embeddings between source and target languages. Our experiments on xGQA using the pretrained multilingual multimodal transformers UC2 and M3P demonstrate the consistent effectiveness of the proposed fine-tuning strategy for 7 languages, outperforming existing transfer methods with sparse models. Code and data to reproduce our findings are publicly available.
A Priority Map for Vision-and-Language Navigation with Trajectory Plans and Feature-Location Cues
Jul 24, 2022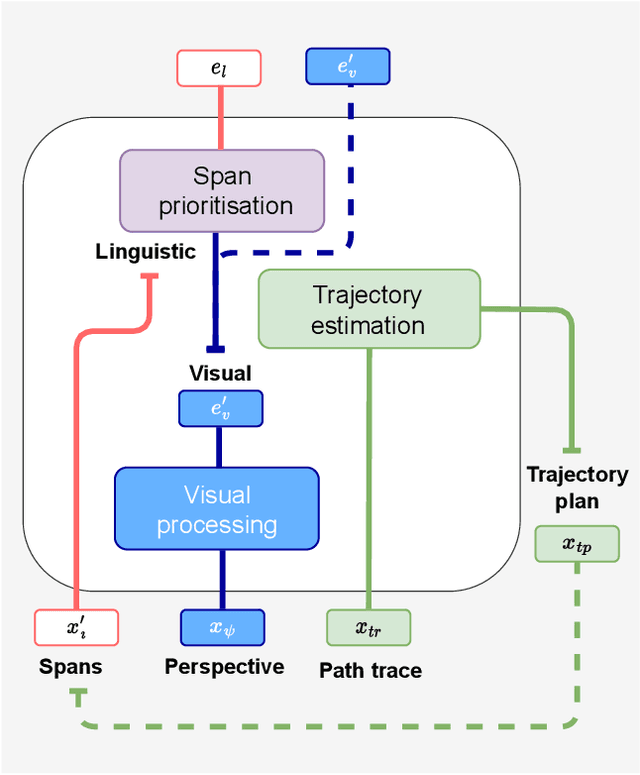
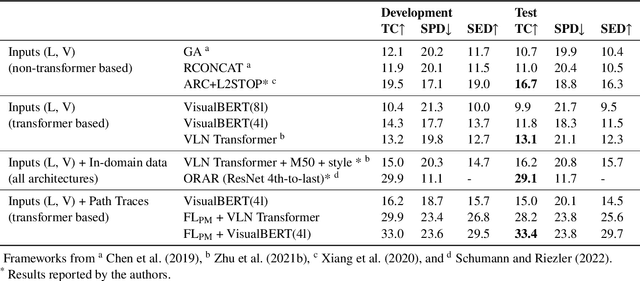
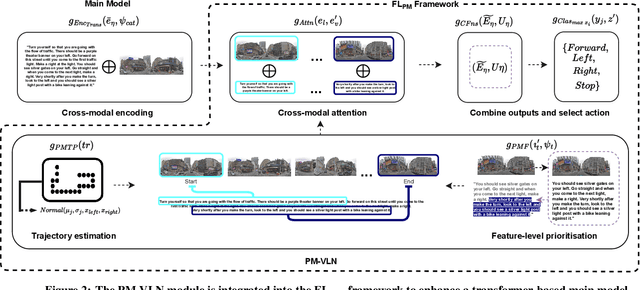
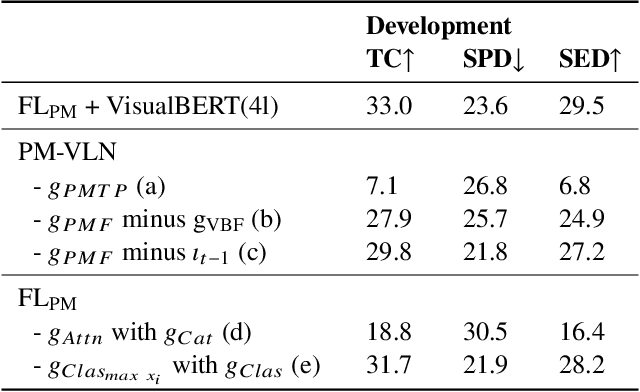
In a busy city street, a pedestrian surrounded by distractions can pick out a single sign if it is relevant to their route. Artificial agents in outdoor Vision-and-Language Navigation (VLN) are also confronted with detecting supervisory signal on environment features and location in inputs. To boost the prominence of relevant features in transformer-based architectures without costly preprocessing and pretraining, we take inspiration from priority maps - a mechanism described in neuropsychological studies. We implement a novel priority map module and pretrain on auxiliary tasks using low-sample datasets with high-level representations of routes and environment-related references to urban features. A hierarchical process of trajectory planning - with subsequent parameterised visual boost filtering on visual inputs and prediction of corresponding textual spans - addresses the core challenges of cross-modal alignment and feature-level localisation. The priority map module is integrated into a feature-location framework that doubles the task completion rates of standalone transformers and attains state-of-the-art performance on the Touchdown benchmark for VLN. Code and data are referenced in Appendix C.