 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Automatic Metrics with Incremental Machine Translation Systems
Jul 03, 2024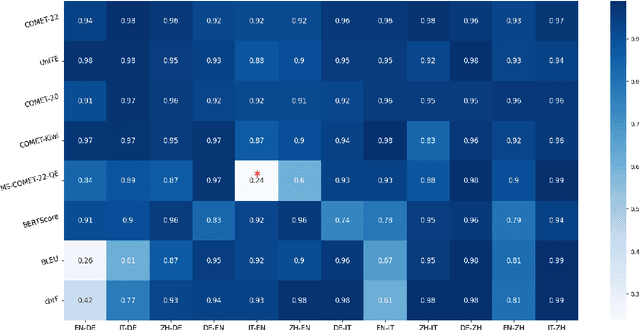
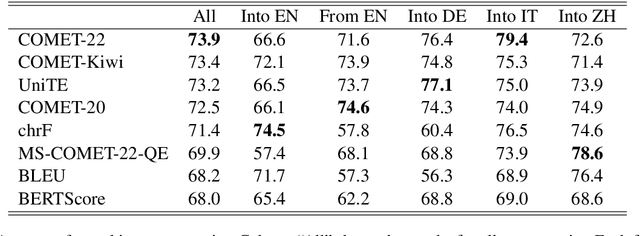
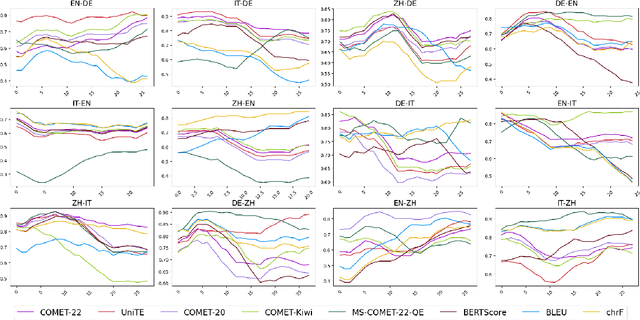
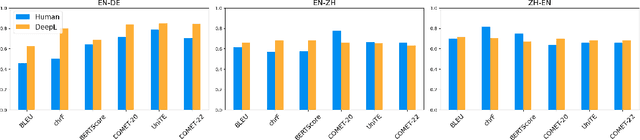
We introduce a dataset comprising commercial machine translations, gathered weekly over six years across 12 translation directions. Since human A/B testing is commonly used, we assume commercial systems improve over time, which enables us to evaluate machine translation (MT) metrics based on their preference for more recent translations. Our study confirms several previous findings in MT metrics research and demonstrates the dataset's value as a testbed for metric evaluation. We release our code at https://github.com/gjwubyron/Evo
SignCLIP: Connecting Text and Sign Language by Contrastive Learning
Jul 01, 2024



We present SignCLIP, which re-purposes CLIP (Contrastive Language-Image Pretraining) to project spoken language text and sign language videos, two classes of natural languages of distinct modalities, into the same space. SignCLIP is an efficient method of learning useful visual representations for sign language processing from large-scale, multilingual video-text pairs, without directly optimizing for a specific task or sign language which is often of limited size. We pretrain SignCLIP on Spreadthesign, a prominent sign language dictionary consisting of ~500 thousand video clips in up to 44 sign languages, and evaluate it with various downstream datasets. SignCLIP discerns in-domain signing with notable text-to-video/video-to-text retrieval accuracy. It also performs competitively for out-of-domain downstream tasks such as isolated sign language recognition upon essential few-shot prompting or fine-tuning. We analyze the latent space formed by the spoken language text and sign language poses, which provides additional linguistic insights. Our code and models are openly available.
An Analysis of BPE Vocabulary Trimming in Neural Machine Translation
Mar 30, 2024We explore threshold vocabulary trimming in Byte-Pair Encoding subword tokenization, a postprocessing step that replaces rare subwords with their component subwords. The technique is available in popular tokenization libraries but has not been subjected to rigorous scientific scrutiny. While the removal of rare subwords is suggested as best practice in machine translation implementations, both as a means to reduce model size and for improving model performance through robustness, our experiments indicate that, across a large space of hyperparameter settings, vocabulary trimming fails to improve performance, and is even prone to incurring heavy degradation.
Linear-time Minimum Bayes Risk Decoding with Reference Aggregation
Feb 06, 2024



Minimum Bayes Risk (MBR) decoding is a text generation technique that has been shown to improve the quality of machine translations, but is expensive, even if a sampling-based approximation is used. Besides requiring a large number of sampled sequences, it requires the pairwise calculation of a utility metric, which has quadratic complexity. In this paper, we propose to approximate pairwise metric scores with scores calculated against aggregated reference representations. This changes the complexity of utility estimation from $O(n^2)$ to $O(n)$, while empirically preserving most of the quality gains of MBR decoding. We release our source code at https://github.com/ZurichNLP/mbr
Machine Translation Meta Evaluation through Translation Accuracy Challenge Sets
Jan 29, 2024



Recent machine translation (MT) metrics calibrate their effectiveness by correlating with human judgement but without any insights about their behaviour across different error types. Challenge sets are used to probe specific dimensions of metric behaviour but there are very few such datasets and they either focus on a limited number of phenomena or a limited number of language pairs. We introduce ACES, a contrastive challenge set spanning 146 language pairs, aimed at discovering whether metrics can identify 68 translation accuracy errors. These phenomena range from simple alterations at the word/character level to more complex errors based on discourse and real-world knowledge. We conduct a large-scale study by benchmarking ACES on 50 metrics submitted to the WMT 2022 and 2023 metrics shared tasks. We benchmark metric performance, assess their incremental performance over successive campaigns, and measure their sensitivity to a range of linguistic phenomena. We also investigate claims that Large Language Models (LLMs) are effective as MT evaluators by evaluating on ACES. Our results demonstrate that different metric families struggle with different phenomena and that LLM-based methods fail to demonstrate reliable performance. Our analyses indicate that most metrics ignore the source sentence, tend to prefer surface-level overlap and end up incorporating properties of base models which are not always beneficial. We expand ACES to include error span annotations, denoted as SPAN-ACES and we use this dataset to evaluate span-based error metrics showing these metrics also need considerable improvement. Finally, we provide a set of recommendations for building better MT metrics, including focusing on error labels instead of scores, ensembling, designing strategies to explicitly focus on the source sentence, focusing on semantic content and choosing the right base model for representations.
Modular Adaptation of Multilingual Encoders to Written Swiss German Dialect
Jan 25, 2024


Creating neural text encoders for written Swiss German is challenging due to a dearth of training data combined with dialectal variation. In this paper, we build on several existing multilingual encoders and adapt them to Swiss German using continued pre-training. Evaluation on three diverse downstream tasks shows that simply adding a Swiss German adapter to a modular encoder achieves 97.5% of fully monolithic adaptation performance. We further find that for the task of retrieving Swiss German sentences given Standard German queries, adapting a character-level model is more effective than the other adaptation strategies. We release our code and the models trained for our experiments at https://github.com/ZurichNLP/swiss-german-text-encoders
Machine Translation Models are Zero-Shot Detectors of Translation Direction
Jan 12, 2024



Detecting the translation direction of parallel text has applications for machine translation training and evaluation, but also has forensic applications such as resolving plagiarism or forgery allegations. In this work, we explore an unsupervised approach to translation direction detection based on the simple hypothesis that $p(\text{translation}|\text{original})>p(\text{original}|\text{translation})$, motivated by the well-known simplification effect in translationese or machine-translationese. In experiments with massively multilingual machine translation models across 20 translation directions, we confirm the effectiveness of the approach for high-resource language pairs, achieving document-level accuracies of 82-96% for NMT-produced translations, and 60-81% for human translations, depending on the model used. Code and demo are available at https://github.com/ZurichNLP/translation-direction-detection
Turning English-centric LLMs Into Polyglots: How Much Multilinguality Is Needed?
Dec 20, 2023



The vast majority of today's large language models are English-centric, having been pretrained predominantly on English text. Yet, in order to meet user expectations, models need to be able to respond appropriately in multiple languages once deployed in downstream applications. Given limited exposure to other languages during pretraining, cross-lingual transfer is important for achieving decent performance in non-English settings. In this work, we investigate just how much multilinguality is required during finetuning to elicit strong cross-lingual generalisation across a range of tasks and target languages. We find that, compared to English-only finetuning, multilingual instruction tuning with as few as three languages significantly improves a model's cross-lingual transfer abilities on generative tasks that assume input/output language agreement, while being of less importance for highly structured tasks. Our code and data is available at https://github.com/ZurichNLP/multilingual-instruction-tuning.
Trained MT Metrics Learn to Cope with Machine-translated References
Dec 01, 2023



Neural metrics trained on human evaluations of MT tend to correlate well with human judgments, but their behavior is not fully understood. In this paper, we perform a controlled experiment and compare a baseline metric that has not been trained on human evaluations (Prism) to a trained version of the same metric (Prism+FT). Surprisingly, we find that Prism+FT becomes more robust to machine-translated references, which are a notorious problem in MT evaluation. This suggests that the effects of metric training go beyond the intended effect of improving overall correlation with human judgments.
A Benchmark for Evaluating Machine Translation Metrics on Dialects Without Standard Orthography
Nov 28, 2023



For sensible progress in natural language processing, it is important that we are aware of the limitations of the evaluation metrics we use. In this work, we evaluate how robust metrics are to non-standardized dialects, i.e. spelling differences in language varieties that do not have a standard orthography. To investigate this, we collect a dataset of human translations and human judgments for automatic machine translations from English to two Swiss German dialects. We further create a challenge set for dialect variation and benchmark existing metrics' performances. Our results show that existing metrics cannot reliably evaluate Swiss German text generation outputs, especially on segment level. We propose initial design adaptations that increase robustness in the face of non-standardized dialects, although there remains much room for further improvement. The dataset, code, and models are available here: https://github.com/textshuttle/dialect_eval