 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fine-Tuning Paradox: Boosting Translation Quality Without Sacrificing LLM Abilities
May 30, 2024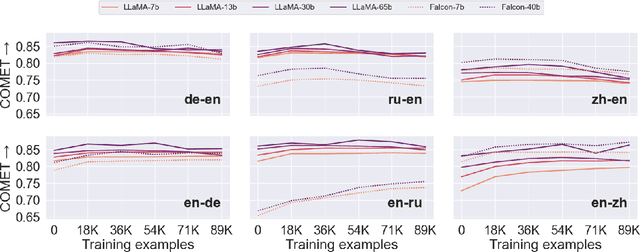

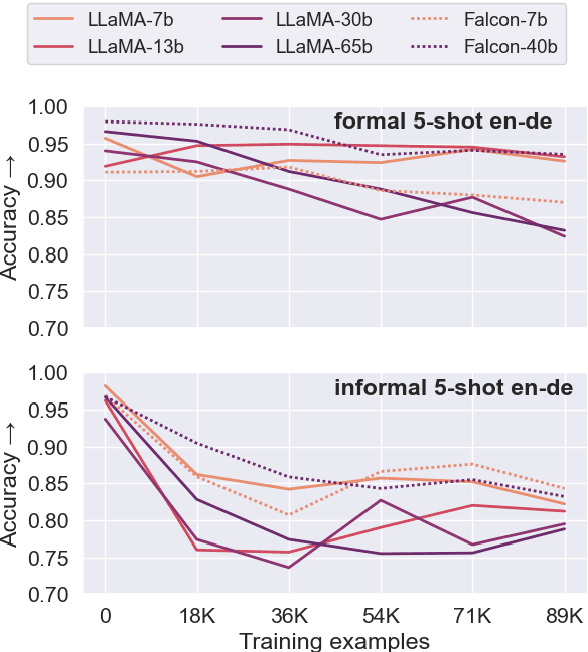
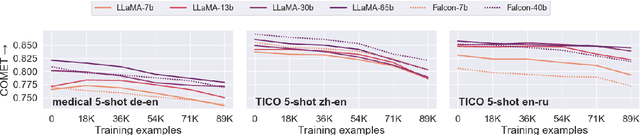
Fine-tuning large language models (LLMs) for machine translation has shown improvements in overall translation quality. However, it is unclear what is the impact of fine-tuning on desirable LLM behaviors that are not present in neural machine translation models, such as steerability, inherent document-level translation abilities, and the ability to produce less literal translations. We perform an extensive translation evaluation on the LLaMA and Falcon family of models with model size ranging from 7 billion up to 65 billion parameters. Our results show that while fine-tuning improves the general translation quality of LLMs, several abilities degrade. In particular, we observe a decline in the ability to perform formality steering, to produce technical translations through few-shot examples, and to perform document-level translation. On the other hand, we observe that the model produces less literal translations after fine-tuning on parallel data. We show that by including monolingual data as part of the fine-tuning data we can maintain the abilities while simultaneously enhancing overall translation quality. Our findings emphasize the need for fine-tuning strategies that preserve the benefits of LLMs for machine translation.
A Preference-driven Paradigm for Enhanced Translation with Large Language Models
Apr 17, 2024



Recent research has shown that large language models (LLMs) can achieve remarkable translation performance through supervised fine-tuning (SFT) using only a small amount of parallel data. However, SFT simply instructs the model to imitate the reference translations at the token level, making it vulnerable to the noise present in the references. Hence, the assistance from SFT often reaches a plateau once the LLMs have achieved a certain level of translation capability, and further increasing the size of parallel data does not provide additional benefits. To overcome this plateau associated with imitation-based SFT, we propose a preference-based approach built upon the Plackett-Luce model. The objective is to steer LLMs towards a more nuanced understanding of translation preferences from a holistic view, while also being more resilient in the absence of gold translations. We further build a dataset named MAPLE to verify the effectiveness of our approach, which includes multiple translations of varying quality for each source sentence. Extensive experiments demonstrate the superiority of our approach in "breaking the plateau" across diverse LLMs and test settings. Our in-depth analysis underscores the pivotal role of diverse translations and accurate preference scores in the success of our approach.
Trained MT Metrics Learn to Cope with Machine-translated References
Dec 01, 2023



Neural metrics trained on human evaluations of MT tend to correlate well with human judgments, but their behavior is not fully understood. In this paper, we perform a controlled experiment and compare a baseline metric that has not been trained on human evaluations (Prism) to a trained version of the same metric (Prism+FT). Surprisingly, we find that Prism+FT becomes more robust to machine-translated references, which are a notorious problem in MT evaluation. This suggests that the effects of metric training go beyond the intended effect of improving overall correlation with human judgments.
Analyzing the Use of Influence Functions for Instance-Specific Data Filtering in Neural Machine Translation
Oct 24, 2022Customer feedback can be an important signal for improving commercial machine translation systems. One solution for fixing specific translation errors is to remove the related erroneous training instances followed by re-training of the machine translation system, which we refer to as instance-specific data filtering. Influence functions (IF) have been shown to be effective in finding such relevant training examples for classification tasks such as image classification, toxic speech detection and entailment task. Given a probing instance, IF find influential training examples by measuring the similarity of the probing instance with a set of training examples in gradient space. In this work, we examine the use of influence functions for Neural Machine Translation (NMT). We propose two effective extensions to a state of the art influence function and demonstrate on the sub-problem of copied training examples that IF can be applied more generally than handcrafted regular expressions.
Automatic Evaluation and Analysis of Idioms in Neural Machine Translation
Oct 10, 2022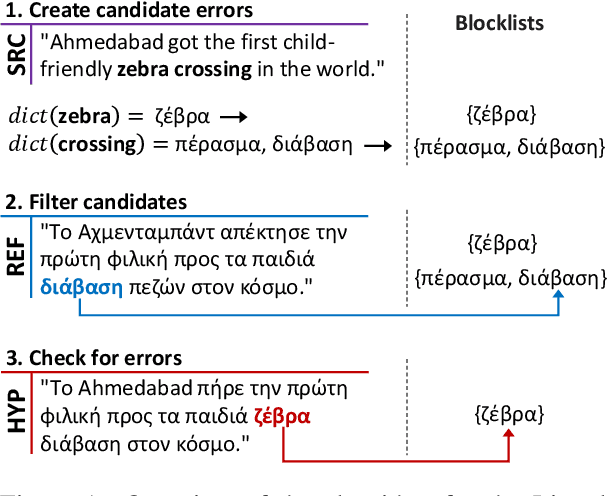
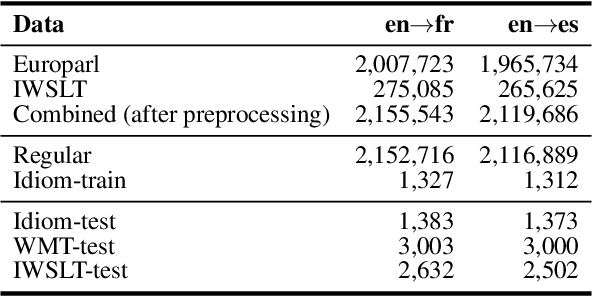
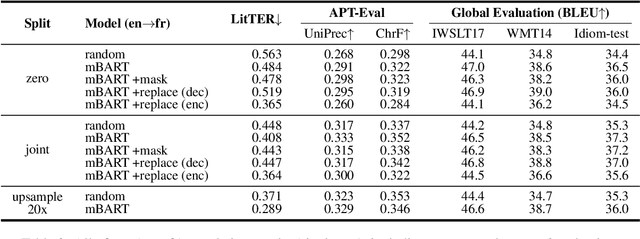
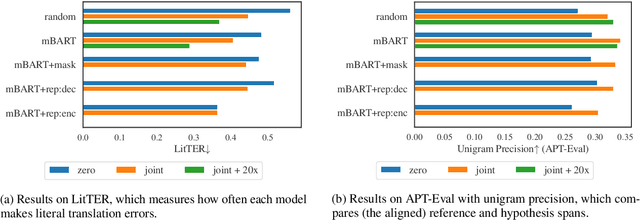
A major open problem in neural machine translation (NMT) is the translation of idiomatic expressions, such as "under the weather". The meaning of these expressions is not composed by the meaning of their constituent words, and NMT models tend to translate them literally (i.e., word-by-word), which leads to confusing and nonsensical translations. Research on idioms in NMT is limited and obstructed by the absence of automatic methods for quantifying these errors. In this work, first, we propose a novel metric for automatically measuring the frequency of literal translation errors without human involvement. Equipped with this metric, we present controlled translation experiments with models trained in different conditions (with/without the test-set idioms) and across a wide range of (global and targeted) metrics and test sets. We explore the role of monolingual pretraining and find that it yields substantial targeted improvements, even without observing any translation examples of the test-set idioms. In our analysis, we probe the role of idiom context. We find that the randomly initialized models are more local or "myopic" as they are relatively unaffected by variations of the idiom context, unlike the pretrained ones.
The Devil is in the Details: On the Pitfalls of Vocabulary Selection in Neural Machine Translation
May 13, 2022
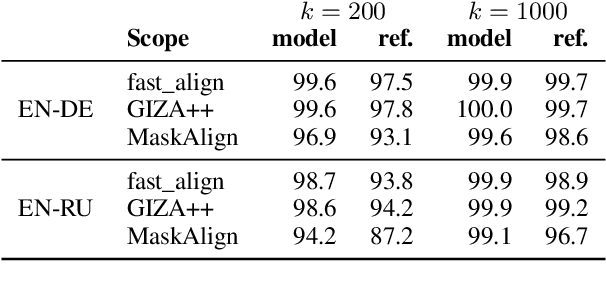
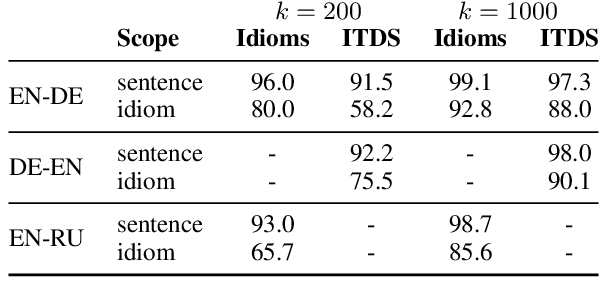
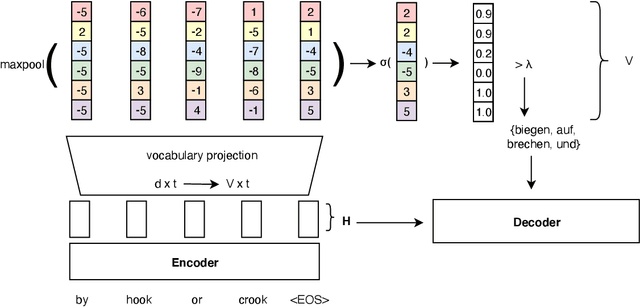
Vocabulary selection, or lexical shortlisting, is a well-known technique to improve latency of Neural Machine Translation models by constraining the set of allowed output words during inference. The chosen set is typically determined by separately trained alignment model parameters, independent of the source-sentence context at inference time. While vocabulary selection appears competitive with respect to automatic quality metrics in prior work, we show that it can fail to select the right set of output words, particularly for semantically non-compositional linguistic phenomena such as idiomatic expressions, leading to reduced translation quality as perceived by humans. Trading off latency for quality by increasing the size of the allowed set is often not an option in real-world scenarios. We propose a model of vocabulary selection, integrated into the neural translation model, that predicts the set of allowed output words from contextualized encoder representations. This restores translation quality of an unconstrained system, as measured by human evaluations on WMT newstest2020 and idiomatic expressions, at an inference latency competitive with alignment-based selection using aggressive thresholds, thereby removing the dependency on separately trained alignment models.
Neural Machine Translation Decoding with Terminology Constraints
May 09, 2018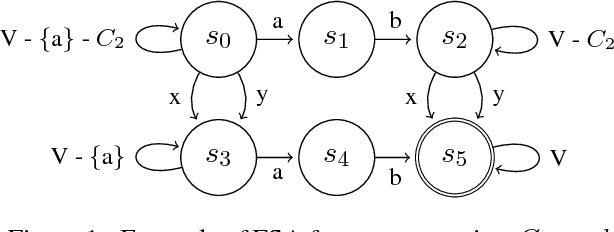
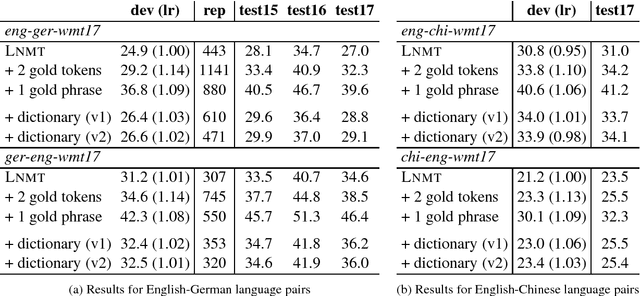

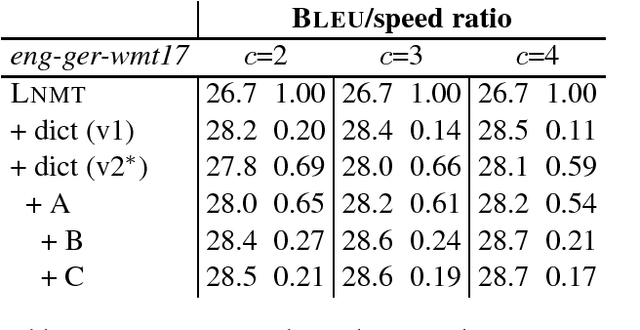
Despite the impressive quality improvements yielded by neural machine translation (NMT) systems, controlling their translation output to adhere to user-provided terminology constraints remains an open problem. We describe our approach to constrained neural decoding based on finite-state machines and multi-stack decoding which supports target-side constraints as well as constraints with corresponding aligned input text spans. We demonstrate the performance of our framework on multiple translation tasks and motivate the need for constrained decoding with attentions as a means of reducing misplacement and duplication when translating user constraints.
Accelerating NMT Batched Beam Decoding with LMBR Posteriors for Deployment
Apr 30, 2018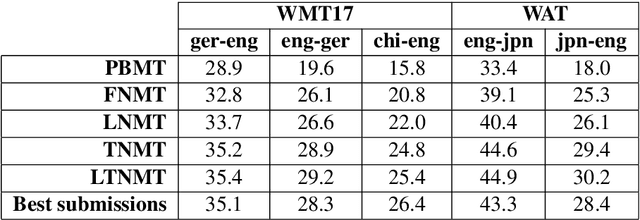
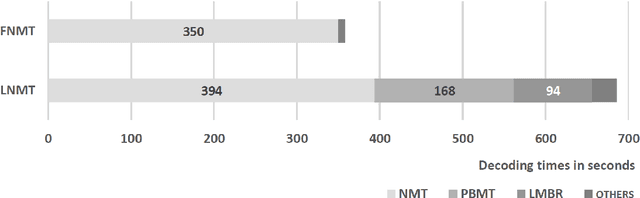
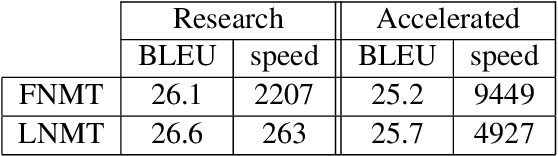
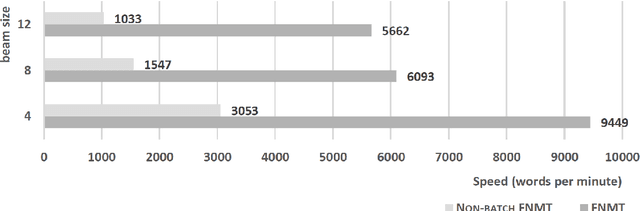
We describe a batched beam decoding algorithm for NMT with LMBR n-gram posteriors, showing that LMBR techniques still yield gains on top of the best recently reported results with Transformers. We also discuss acceleration strategies for deployment, and the effect of the beam size and batching on memory and speed.
A Comparison of Neural Models for Word Ordering
Aug 05, 2017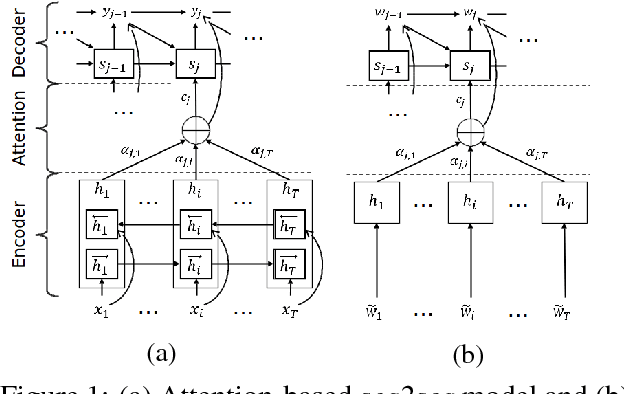


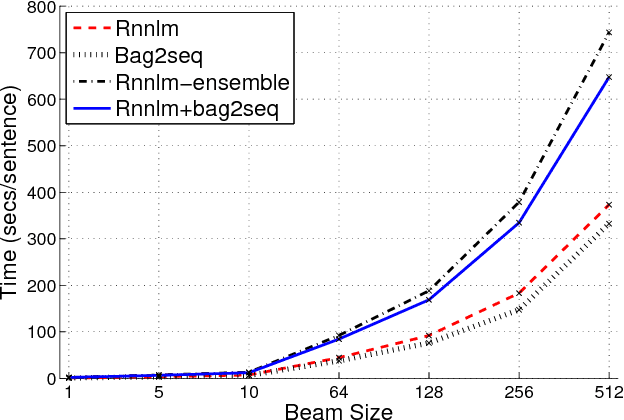
We compare several language models for the word-ordering task and propose a new bag-to-sequence neural model based on attention-based sequence-to-sequence models. We evaluate the model on a large German WMT data set where it significantly outperforms existing models. We also describe a novel search strategy for LM-based word ordering and report results on the English Penn Treebank. Our best model setup outperforms prior work both in terms of speed and quality.
SGNMT -- A Flexible NMT Decoding Platform for Quick Prototyping of New Models and Search Strategies
Jul 21, 2017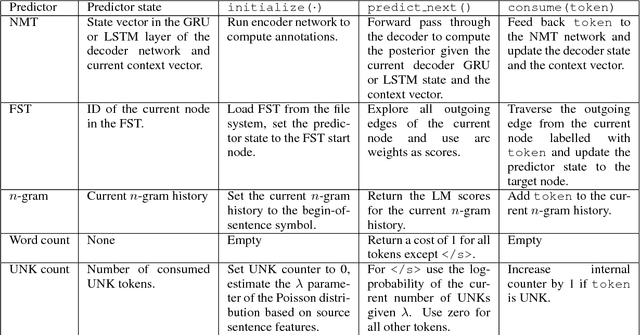

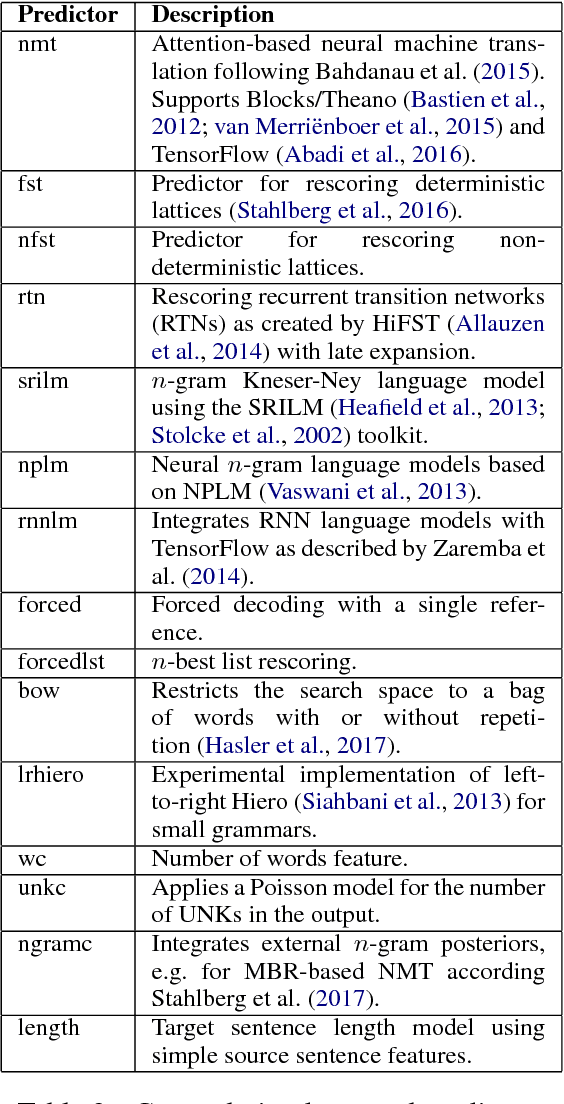
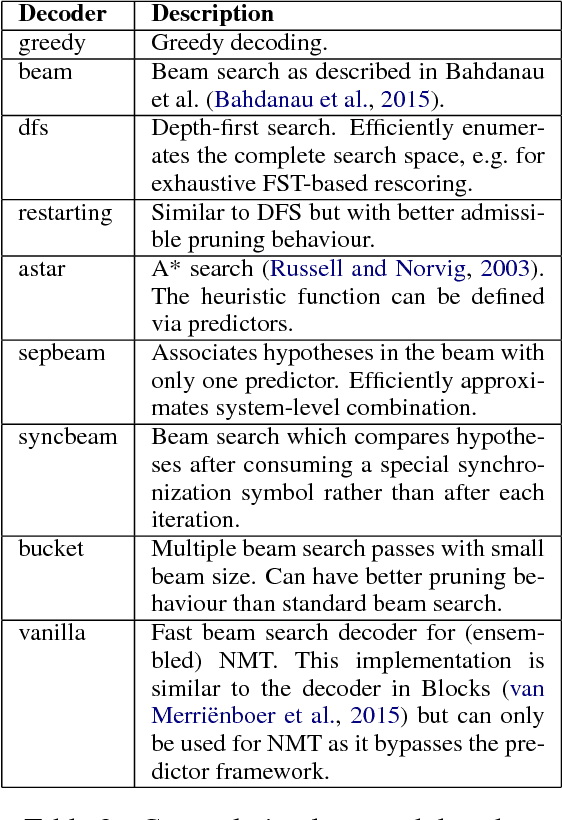
This paper introduces SGNMT, our experimental platform for machine translation research. SGNMT provides a generic interface to neural and symbolic scoring modules (predictors) with left-to-right semantic such as translation models like NMT, language models, translation lattices, $n$-best lists or other kinds of scores and constraints. Predictors can be combined with other predictors to form complex decoding tasks. SGNMT implements a number of search strategies for traversing the space spanned by the predictors which are appropriate for different predictor constellations. Adding new predictors or decoding strategies is particularly easy, making it a very efficient tool for prototyping new research ideas. SGNMT is actively being used by students in the MPhil program in Machine Learning, Speech and Language Technology at the University of Cambridge for course work and theses, as well as for most of the research work in our group.