 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Image-to-Image Translation
Feb 06, 2023



Large-scale text-to-image generative models have shown their remarkable ability to synthesize diverse and high-quality images. However, it is still challenging to directly apply these models for editing real images for two reasons. First, it is hard for users to come up with a perfect text prompt that accurately describes every visual detail in the input image. Second, while existing models can introduce desirable changes in certain regions, they often dramatically alter the input content and introduce unexpected changes in unwanted regions. In this work, we propose pix2pix-zero, an image-to-image translation method that can preserve the content of the original image without manual prompting. We first automatically discover editing directions that reflect desired edits in the text embedding space. To preserve the general content structure after editing, we further propose cross-attention guidance, which aims to retain the cross-attention maps of the input image throughout the diffusion process. In addition, our method does not need additional training for these edits and can directly use the existing pre-trained text-to-image diffusion model. We conduct extensive experiments and show that our method outperforms existing and concurrent works for both real and synthetic image editing.
Domain Expansion of Image Generators
Jan 12, 2023Can one inject new concepts into an already trained generative model, while respecting its existing structure and knowledge? We propose a new task - domain expansion - to address this. Given a pretrained generator and novel (but related) domains, we expand the generator to jointly model all domains, old and new, harmoniously. First, we note the generator contains a meaningful, pretrained latent space. Is it possible to minimally perturb this hard-earned representation, while maximally representing the new domains? Interestingly, we find that the latent space offers unused, "dormant" directions, which do not affect the output. This provides an opportunity: By "repurposing" these directions, we can represent new domains without perturbing the original representation. In fact, we find that pretrained generators have the capacity to add several - even hundreds - of new domains! Using our expansion method, one "expanded" model can supersede numerous domain-specific models, without expanding the model size. Additionally, a single expanded generator natively supports smooth transitions between domains, as well as composition of domains. Code and project page available at https://yotamnitzan.github.io/domain-expansion/.
Multi-Concept Customization of Text-to-Image Diffusion
Dec 08, 2022



While generative models produce high-quality images of concepts learned from a large-scale database, a user often wishes to synthesize instantiations of their own concepts (for example, their family, pets, or items). Can we teach a model to quickly acquire a new concept, given a few examples? Furthermore, can we compose multiple new concepts together? We propose Custom Diffusion, an efficient method for augmenting existing text-to-image models. We find that only optimizing a few parameters in the text-to-image conditioning mechanism is sufficiently powerful to represent new concepts while enabling fast tuning (~6 minutes). Additionally, we can jointly train for multiple concepts or combine multiple fine-tuned models into one via closed-form constrained optimization. Our fine-tuned model generates variations of multiple, new concepts and seamlessly composes them with existing concepts in novel settings. Our method outperforms several baselines and concurrent works, regarding both qualitative and quantitative evaluations, while being memory and computationally efficient.
3D-FM GAN: Towards 3D-Controllable Face Manipulation
Aug 24, 2022
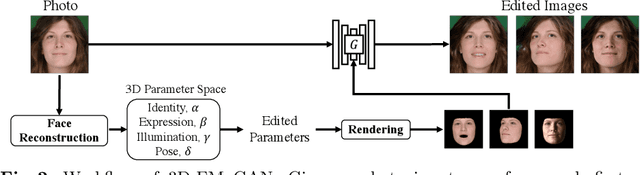

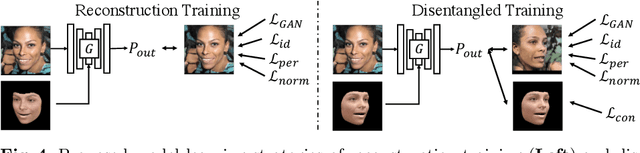
3D-controllable portrait synthesis has significantly advanced, thanks to breakthroughs in generative adversarial networks (GANs). However, it is still challenging to manipulate existing face images with precise 3D control. While concatenating GAN inversion and a 3D-aware, noise-to-image GAN is a straight-forward solution, it is inefficient and may lead to noticeable drop in editing quality. To fill this gap, we propose 3D-FM GAN, a novel conditional GAN framework designed specifically for 3D-controllable face manipulation, and does not require any tuning after the end-to-end learning phase. By carefully encoding both the input face image and a physically-based rendering of 3D edits into a StyleGAN's latent spaces, our image generator provides high-quality, identity-preserved, 3D-controllable face manipulation. To effectively learn such novel framework, we develop two essential training strategies and a novel multiplicative co-modulation architecture that improves significantly upon naive schemes. With extensive evaluations, we show that our method outperforms the prior arts on various tasks, with better editability, stronger identity preservation, and higher photo-realism. In addition, we demonstrate a better generalizability of our design on large pose editing and out-of-domain images.
Spatially-Adaptive Multilayer Selection for GAN Inversion and Editing
Jun 16, 2022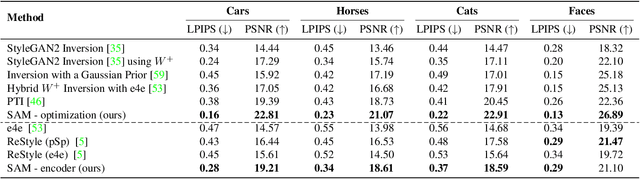
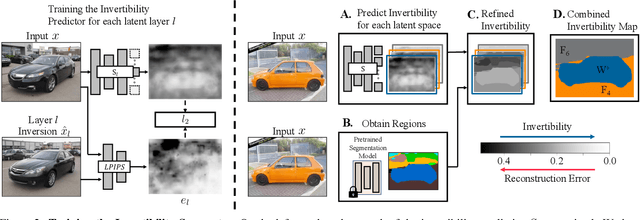
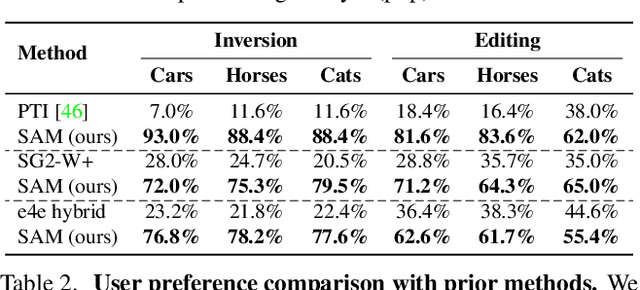

Existing GAN inversion and editing methods work well for aligned objects with a clean background, such as portraits and animal faces, but often struggle for more difficult categories with complex scene layouts and object occlusions, such as cars, animals, and outdoor images. We propose a new method to invert and edit such complex images in the latent space of GANs, such as StyleGAN2. Our key idea is to explore inversion with a collection of layers, spatially adapting the inversion process to the difficulty of the image. We learn to predict the "invertibility" of different image segments and project each segment into a latent layer. Easier regions can be inverted into an earlier layer in the generator's latent space, while more challenging regions can be inverted into a later feature space. Experiments show that our method obtains better inversion results compared to the recent approaches on complex categories, while maintaining downstream editability. Please refer to our project page at https://www.cs.cmu.edu/~SAMInversion.
ASSET: Autoregressive Semantic Scene Editing with Transformers at High Resolutions
May 24, 2022
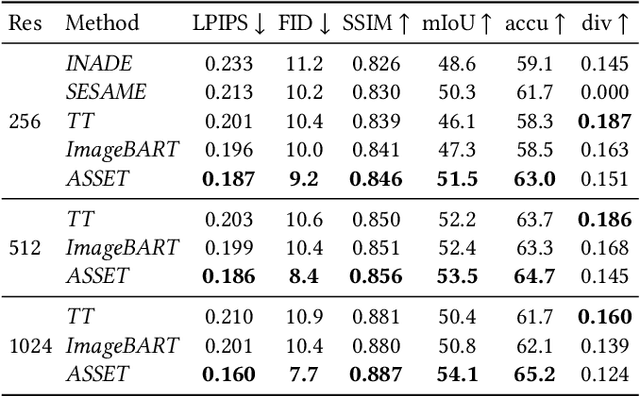
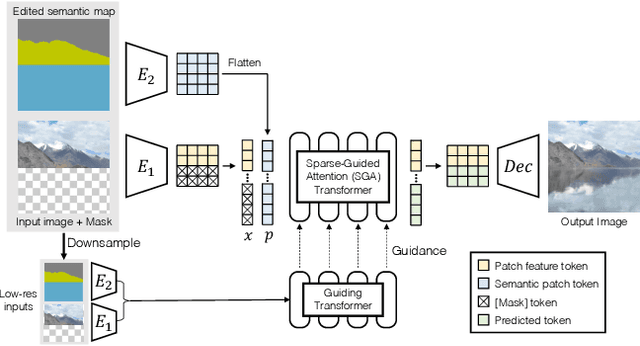
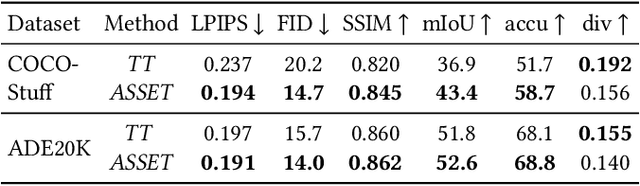
We present ASSET, a neural architecture for automatically modifying an input high-resolution image according to a user's edits on its semantic segmentation map. Our architecture is based on a transformer with a novel attention mechanism. Our key idea is to sparsify the transformer's attention matrix at high resolutions, guided by dense attention extracted at lower image resolutions. While previous attention mechanisms are computationally too expensive for handling high-resolution images or are overly constrained within specific image regions hampering long-range interactions, our novel attention mechanism is both computationally efficient and effective. Our sparsified attention mechanism is able to capture long-range interactions and context, leading to synthesizing interesting phenomena in scenes, such as reflections of landscapes onto water or flora consistent with the rest of the landscape, that were not possible to generate reliably with previous convnets and transformer approaches. We present qualitative and quantitative results, along with user studies, demonstrating the effectiveness of our method.
BlobGAN: Spatially Disentangled Scene Representations
May 05, 2022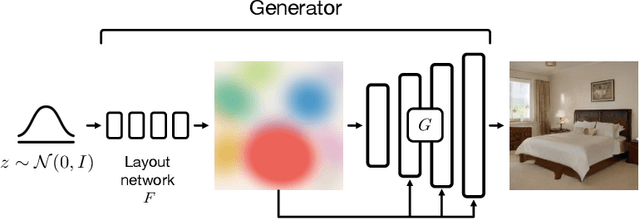
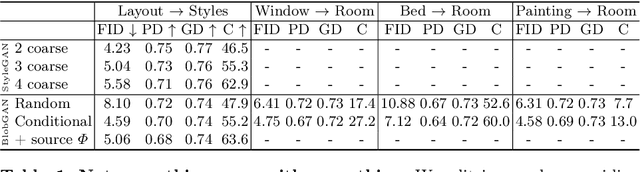
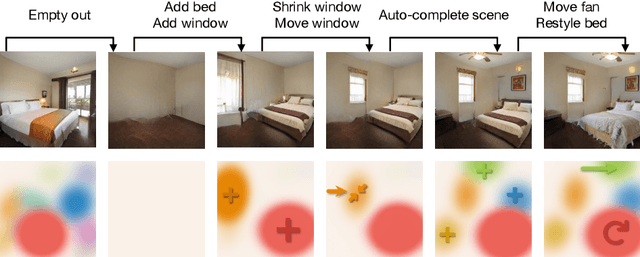
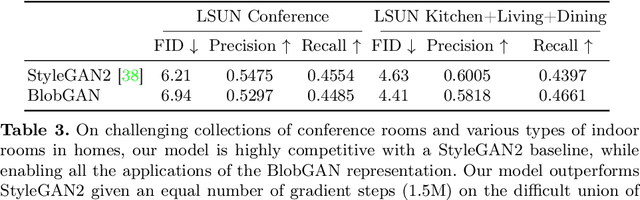
We propose an unsupervised, mid-level representation for a generative model of scenes. The representation is mid-level in that it is neither per-pixel nor per-image; rather, scenes are modeled as a collection of spatial, depth-ordered "blobs" of features. Blobs are differentiably placed onto a feature grid that is decoded into an image by a generative adversarial network. Due to the spatial uniformity of blobs and the locality inherent to convolution, our network learns to associate different blobs with different entities in a scene and to arrange these blobs to capture scene layout. We demonstrate this emergent behavior by showing that, despite training without any supervision, our method enables applications such as easy manipulation of objects within a scene (e.g., moving, removing, and restyling furniture), creation of feasible scenes given constraints (e.g., plausible rooms with drawers at a particular location), and parsing of real-world images into constituent parts. On a challenging multi-category dataset of indoor scenes, BlobGAN outperforms StyleGAN2 in image quality as measured by FID. See our project page for video results and interactive demo: http://www.dave.ml/blobgan
Any-resolution Training for High-resolution Image Synthesis
Apr 14, 2022
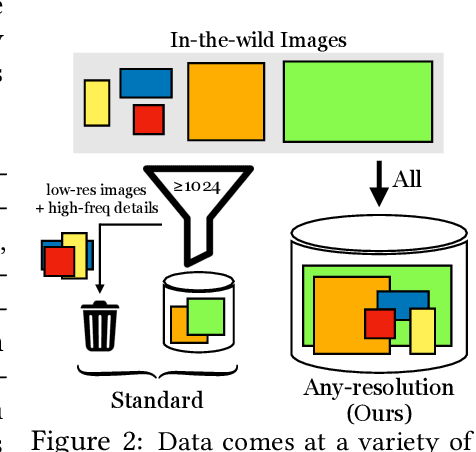
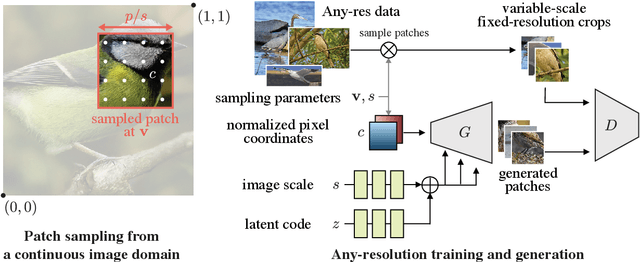
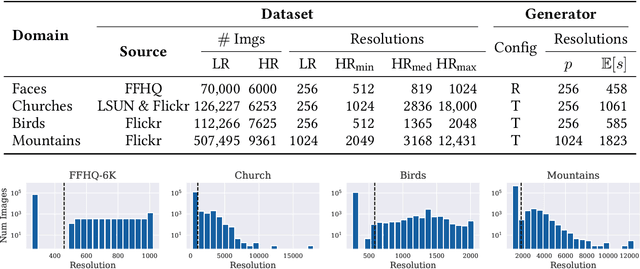
Generative models operate at fixed resolution, even though natural images come in a variety of sizes. As high-resolution details are downsampled away, and low-resolution images are discarded altogether, precious supervision is lost. We argue that every pixel matters and create datasets with variable-size images, collected at their native resolutions. Taking advantage of this data is challenging; high-resolution processing is costly, and current architectures can only process fixed-resolution data. We introduce continuous-scale training, a process that samples patches at random scales to train a new generator with variable output resolutions. First, conditioning the generator on a target scale allows us to generate higher resolutions images than previously possible, without adding layers to the model. Second, by conditioning on continuous coordinates, we can sample patches that still obey a consistent global layout, which also allows for scalable training at higher resolutions. Controlled FFHQ experiments show our method takes advantage of the multi-resolution training data better than discrete multi-scale approaches, achieving better FID scores and cleaner high-frequency details. We also train on other natural image domains including churches, mountains, and birds, and demonstrate arbitrary scale synthesis with both coherent global layouts and realistic local details, going beyond 2K resolution in our experiments. Our project page is available at: https://chail.github.io/anyres-gan/.
Ensembling Off-the-shelf Models for GAN Training
Jan 18, 2022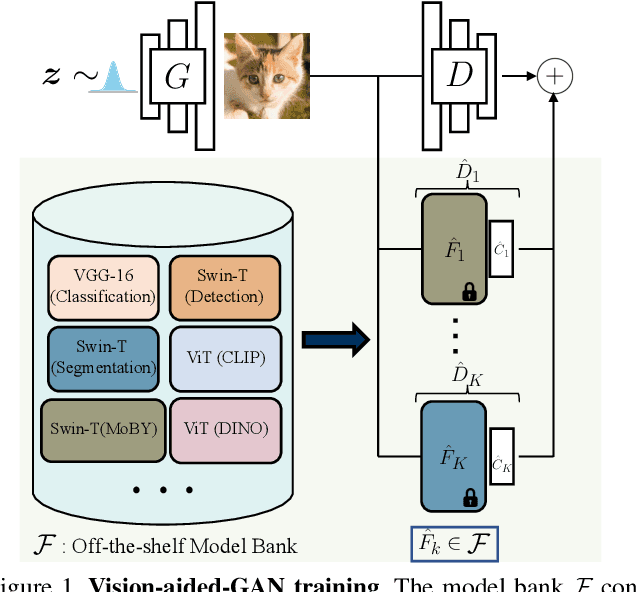
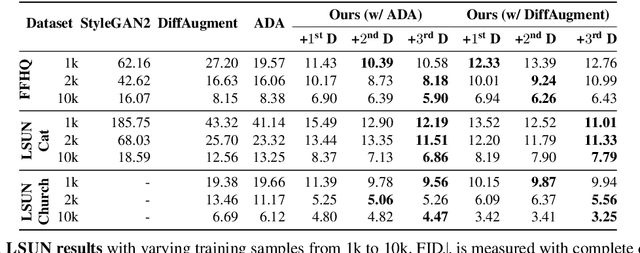
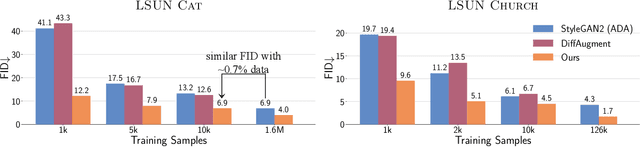
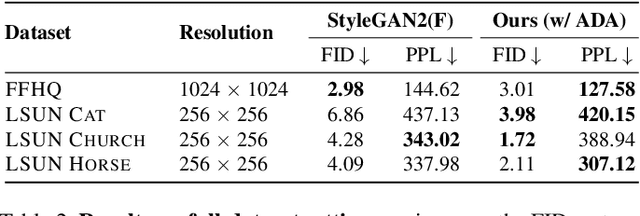
The advent of large-scale training has produced a cornucopia of powerful visual recognition models. However, generative models, such as GANs, have traditionally been trained from scratch in an unsupervised manner. Can the collective "knowledge" from a large bank of pretrained vision models be leveraged to improve GAN training? If so, with so many models to choose from, which one(s) should be selected, and in what manner are they most effective? We find that pretrained computer vision models can significantly improve performance when used in an ensemble of discriminators. Notably, the particular subset of selected models greatly affects performance. We propose an effective selection mechanism, by probing the linear separability between real and fake samples in pretrained model embeddings, choosing the most accurate model, and progressively adding it to the discriminator ensemble. Interestingly, our method can improve GAN training in both limited data and large-scale settings. Given only 10k training samples, our FID on LSUN Cat matches the StyleGAN2 trained on 1.6M images. On the full dataset, our method improves FID by 1.5x to 2x on cat, church, and horse categories of LSUN.
GAN-Supervised Dense Visual Alignment
Dec 09, 2021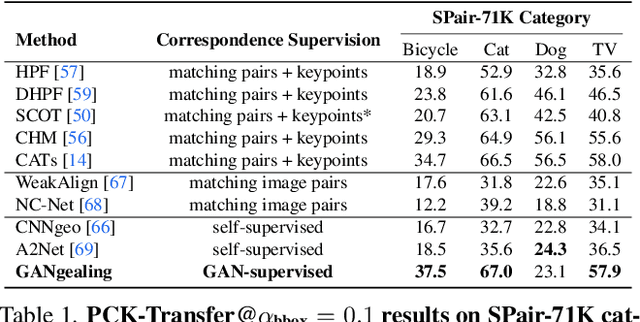
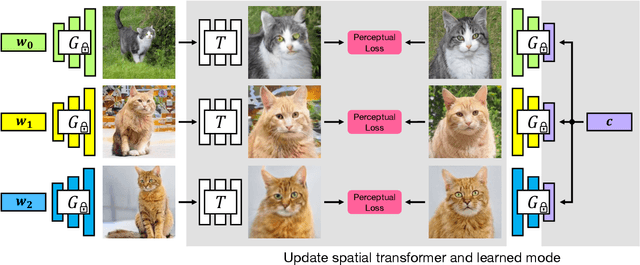


We propose GAN-Supervised Learning, a framework for learning discriminative models and their GAN-generated training data jointly end-to-end. We apply our framework to the dense visual alignment problem. Inspired by the classic Congealing method, our GANgealing algorithm trains a Spatial Transformer to map random samples from a GAN trained on unaligned data to a common, jointly-learned target mode. We show results on eight datasets, all of which demonstrate our method successfully aligns complex data and discovers dense correspondences. GANgealing significantly outperforms past self-supervised correspondence algorithms and performs on-par with (and sometimes exceeds) state-of-the-art supervised correspondence algorithms on several datasets -- without making use of any correspondence supervision or data augmentation and despite being trained exclusively on GAN-generated data. For precise correspondence, we improve upon state-of-the-art supervised methods by as much as $3\times$. We show applications of our method for augmented reality, image editing and automated pre-processing of image datasets for downstream GAN training.