 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Hierarchical Learning: Benefits of Neural Representations
Jun 24, 2020Deep neural networks can empirically perform efficient hierarchical learning, in which the layers learn useful representations of the data. However, how they make use of the intermediate representations are not explained by recent theories that relate them to "shallow learners" such as kernels. In this work, we demonstrate that intermediate neural representations add more flexibility to neural networks and can be advantageous over raw inputs. We consider a fixed, randomly initialized neural network as a representation function fed into another trainable network. When the trainable network is the quadratic Taylor model of a wide two-layer network, we show that neural representation can achieve improved sample complexities compared with the raw input: For learning a low-rank degree-$p$ polynomial ($p \geq 4$) in $d$ dimension, neural representation requires only $\tilde{O}(d^{\lceil p/2 \rceil})$ samples, while the best-known sample complexity upper bound for the raw input is $\tilde{O}(d^{p-1})$. We contrast our result with a lower bound showing that neural representations do not improve over the raw input (in the infinite width limit), when the trainable network is instead a neural tangent kernel. Our results characterize when neural representations are beneficial, and may provide a new perspective on why depth is important in deep learning.
A High-Quality Multilingual Dataset for Structured Documentation Translation
Jun 24, 2020
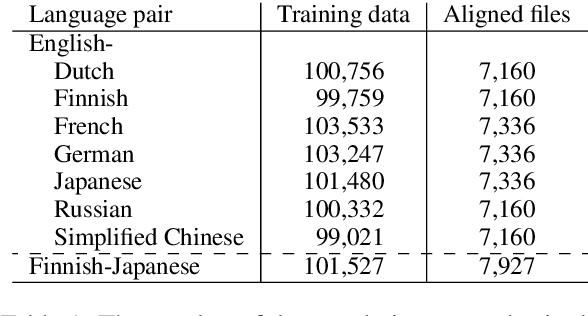
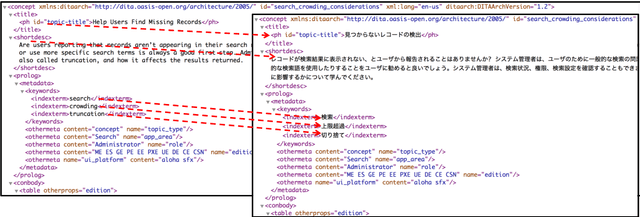
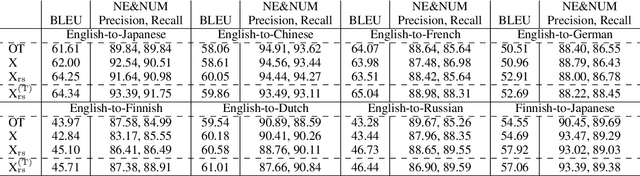
This paper presents a high-quality multilingual dataset for the documentation domain to advance research on localization of structured text. Unlike widely-used datasets for translation of plain text, we collect XML-structured parallel text segments from the online documentation for an enterprise software platform. These Web pages have been professionally translated from English into 16 languages and maintained by domain experts, and around 100,000 text segments are available for each language pair. We build and evaluate translation models for seven target languages from English, with several different copy mechanisms and an XML-constrained beam search. We also experiment with a non-English pair to show that our dataset has the potential to explicitly enable $17 \times 16$ translation settings. Our experiments show that learning to translate with the XML tags improves translation accuracy, and the beam search accurately generates XML structures. We also discuss trade-offs of using the copy mechanisms by focusing on translation of numerical words and named entities. We further provide a detailed human analysis of gaps between the model output and human translations for real-world applications, including suitability for post-editing.
CO-Search: COVID-19 Information Retrieval with Semantic Search, Question Answering, and Abstractive Summarization
Jun 17, 2020
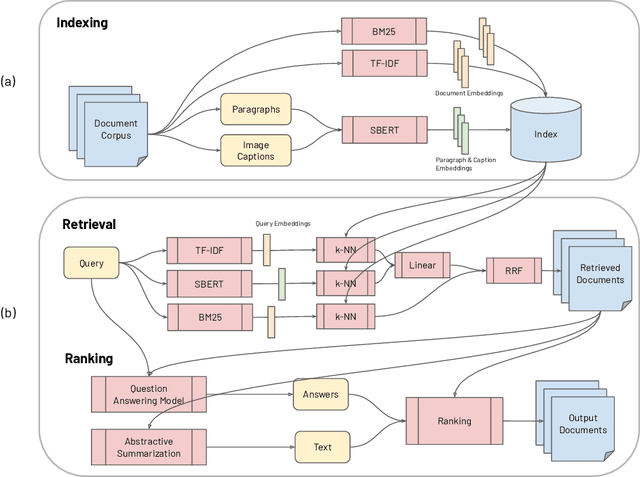
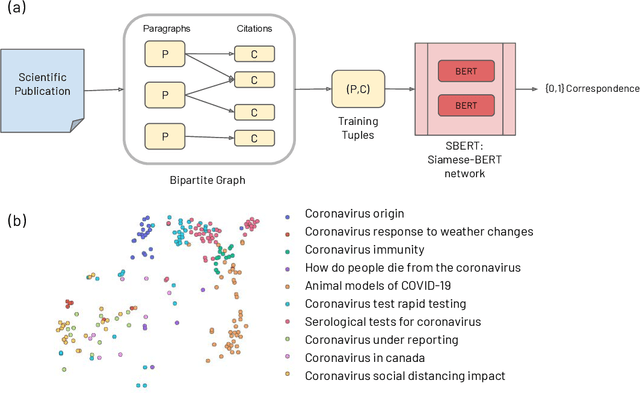
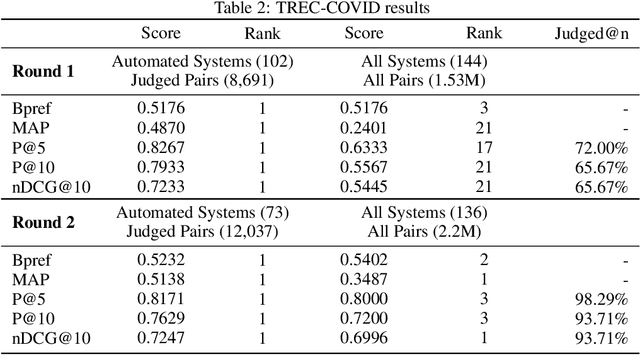
The COVID-19 global pandemic has resulted in international efforts to understand, track, and mitigate the disease, yielding a significant corpus of COVID-19 and SARS-CoV-2-related publications across scientific disciplines. As of May 2020, 128,000 coronavirus-related publications have been collected through the COVID-19 Open Research Dataset Challenge. Here we present CO-Search, a retriever-ranker semantic search engine designed to handle complex queries over the COVID-19 literature, potentially aiding overburdened health workers in finding scientific answers during a time of crisis. The retriever is built from a Siamese-BERT encoder that is linearly composed with a TF-IDF vectorizer, and reciprocal-rank fused with a BM25 vectorizer. The ranker is composed of a multi-hop question-answering module, that together with a multi-paragraph abstractive summarizer adjust retriever scores. To account for the domain-specific and relatively limited dataset, we generate a bipartite graph of document paragraphs and citations, creating 1.3 million (citation title, paragraph) tuples for training the encoder. We evaluate our system on the data of the TREC-COVID information retrieval challenge. CO-Search obtains top performance on the datasets of the first and second rounds, across several key metrics: normalized discounted cumulative gain, precision, mean average precision, and binary preference.
WOAD: Weakly Supervised Online Action Detection in Untrimmed Videos
Jun 05, 2020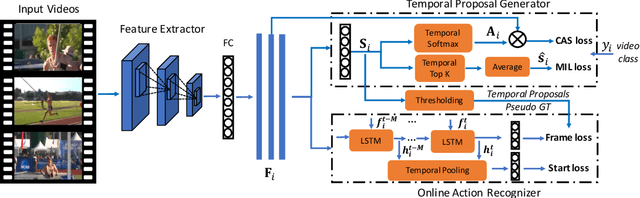
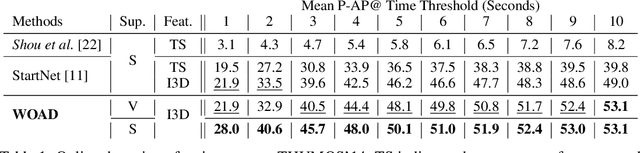
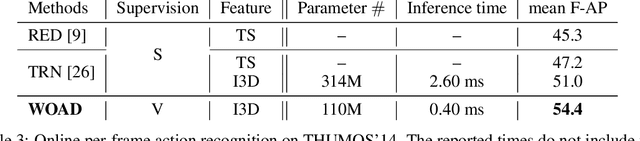
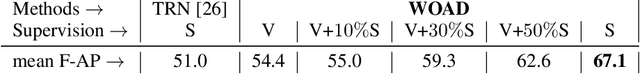
Online action detection in untrimmed videos aims to identify an action as it happens, which makes it very important for real-time applications. Previous methods rely on tedious annotations of temporal action boundaries for model training, which hinders the scalability of online action detection systems. We propose WOAD, a weakly supervised framework that can be trained using only video-class labels. WOAD contains two jointly-trained modules, i.e., temporal proposal generator (TPG) and online action recognizer (OAR). Supervised by video-class labels, TPG works offline and targets on accurately mining pseudo frame-level labels for OAR. With the supervisory signals from TPG, OAR learns to conduct action detection in an online fashion. Experimental results on THUMOS'14 and ActivityNet1.2 show that our weakly-supervised method achieves competitive performance compared to previous strongly-supervised methods. Beyond that, our method is flexible to leverage strong supervision when it is available. When strongly supervised, our method sets new state-of-the-art results in the online action detection tasks including online per-frame action recognition and online detection of action start.
Prototypical Contrastive Learning of Unsupervised Representations
Jun 05, 2020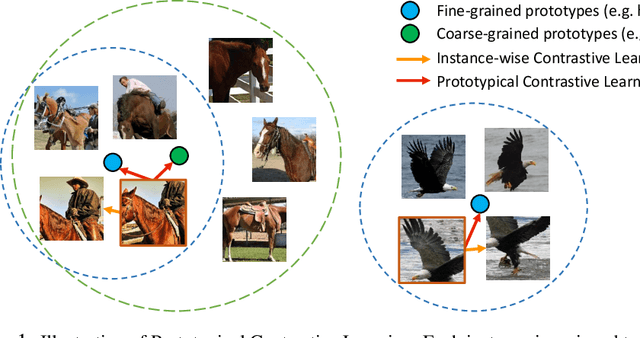
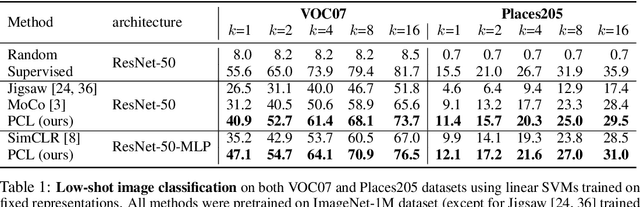
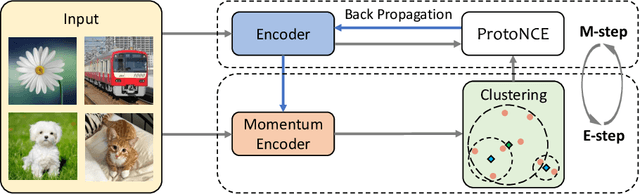
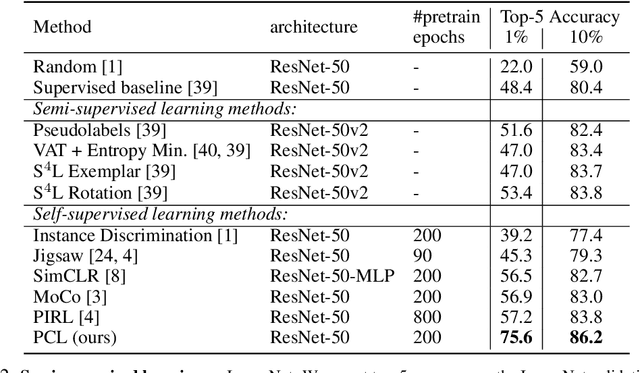
This paper presents Prototypical Contrastive Learning (PCL), an unsupervised representation learning method that addresses the fundamental limitations of instance-wise contrastive learning. PCL not only learns low-level features for the task of instance discrimination, but more importantly, it implicitly encodes semantic structures of the data into the learned embedding space. Specifically, we introduce prototypes as latent variables to help find the maximum-likelihood estimation of the network parameters in an Expectation-Maximization framework. We iteratively perform E-step as finding the distribution of prototypes via clustering and M-step as optimizing the network via contrastive learning. We propose ProtoNCE loss, a generalized version of the InfoNCE loss for contrastive learning, which encourages representations to be closer to their assigned prototypes. PCL achieves state-of-the-art results on multiple unsupervised representation learning benchmarks, with >10% accuracy improvement in low-resource transfer tasks.
EMT: Explicit Memory Tracker with Coarse-to-Fine Reasoning for Conversational Machine Reading
May 26, 2020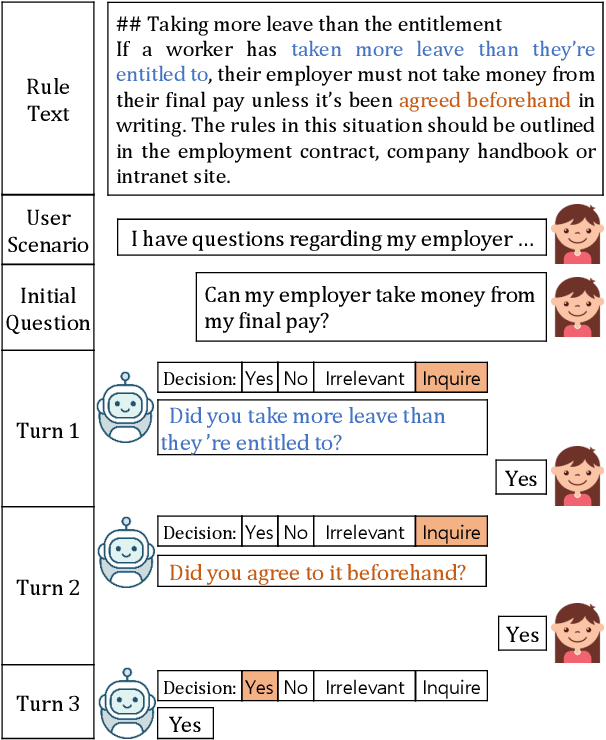
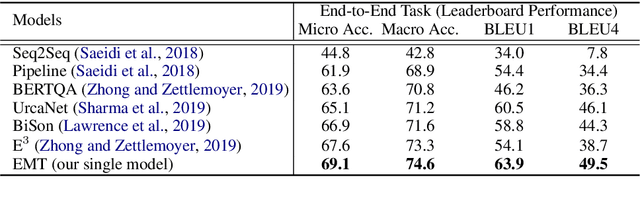
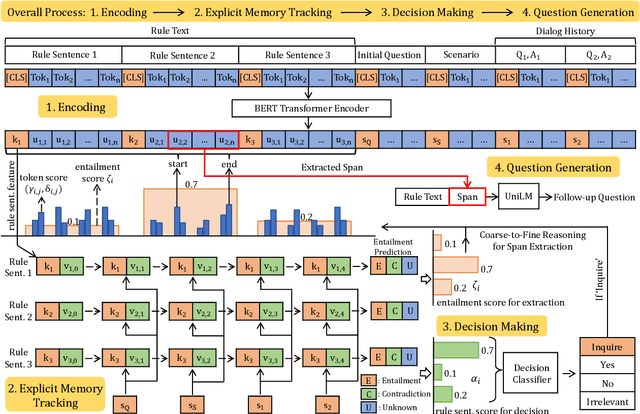

The goal of conversational machine reading is to answer user questions given a knowledge base text which may require asking clarification questions. Existing approaches are limited in their decision making due to struggles in extracting question-related rules and reasoning about them. In this paper, we present a new framework of conversational machine reading that comprises a novel Explicit Memory Tracker (EMT) to track whether conditions listed in the rule text have already been satisfied to make a decision. Moreover, our framework generates clarification questions by adopting a coarse-to-fine reasoning strategy, utilizing sentence-level entailment scores to weight token-level distributions. On the ShARC benchmark (blind, held-out) testset, EMT achieves new state-of-the-art results of 74.6% micro-averaged decision accuracy and 49.5 BLEU4. We also show that EMT is more interpretable by visualizing the entailment-oriented reasoning process as the conversation flows. Code and models are released at \url{https://github.com/Yifan-Gao/explicit_memory_tracker}.
A Simple Language Model for Task-Oriented Dialogue
May 25, 2020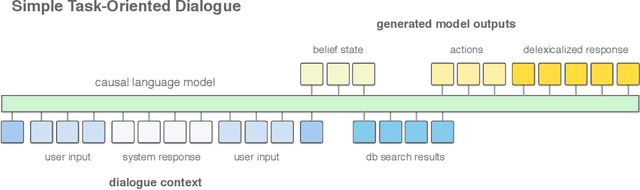


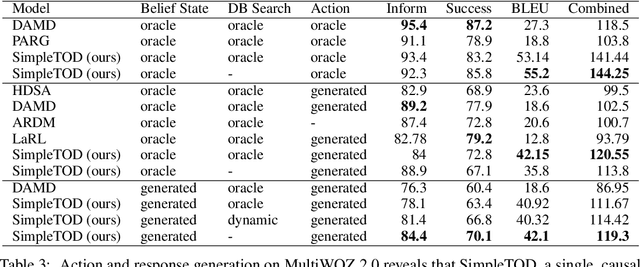
Task-oriented dialogue is often decomposed into three tasks: understanding user input, deciding actions, and generating a response. While such decomposition might suggest a dedicated model for each sub-task, we find a simple, unified approach leads to state-of-the-art performance on the MultiWOZ dataset. SimpleTOD is a simple approach to task-oriented dialogue that uses a single causal language model trained on all sub-tasks recast as a single sequence prediction problem. This allows SimpleTOD to fully leverage transfer learning from pre-trained, open domain, causal language models such as GPT-2. SimpleTOD improves over the prior state-of-the-art by 0.49 points in joint goal accuracy for dialogue state tracking. More impressively, SimpleTOD also improves the main metrics used to evaluate action decisions and response generation in an end-to-end setting for task-oriented dialog systems: inform rate by 8.1 points, success rate by 9.7 points, and combined score by 7.2 points.
ESPRIT: Explaining Solutions to Physical Reasoning Tasks
May 14, 2020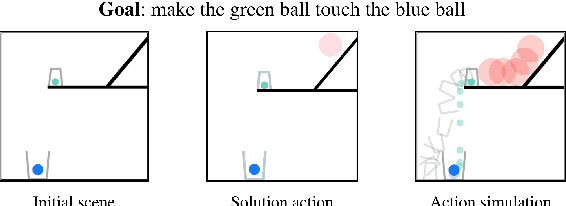

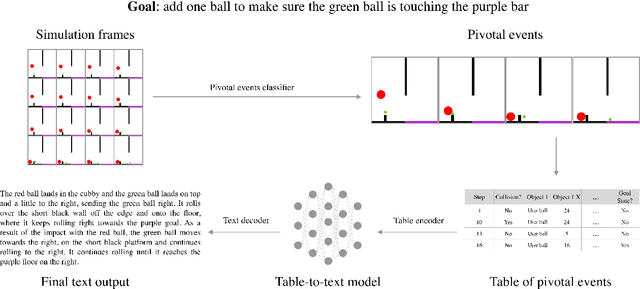
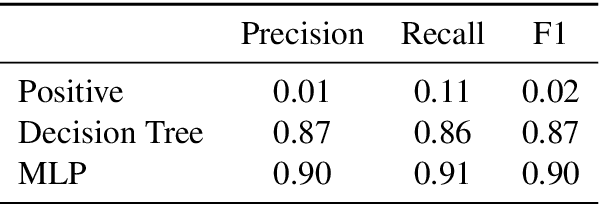
Neural networks lack the ability to reason about qualitative physics and so cannot generalize to scenarios and tasks unseen during training. We propose ESPRIT, a framework for commonsense reasoning about qualitative physics in natural language that generates interpretable descriptions of physical events. We use a two-step approach of first identifying the pivotal physical events in an environment and then generating natural language descriptions of those events using a data-to-text approach. Our framework learns to generate explanations of how the physical simulation will causally evolve so that an agent or a human can easily reason about a solution using those interpretable descriptions. Human evaluations indicate that ESPRIT produces crucial fine-grained details and has high coverage of physical concepts compared to even human annotations. Dataset, code and documentation are available at https://github.com/salesforce/esprit.
It's Morphin' Time! Combating Linguistic Discrimination with Inflectional Perturbations
May 09, 2020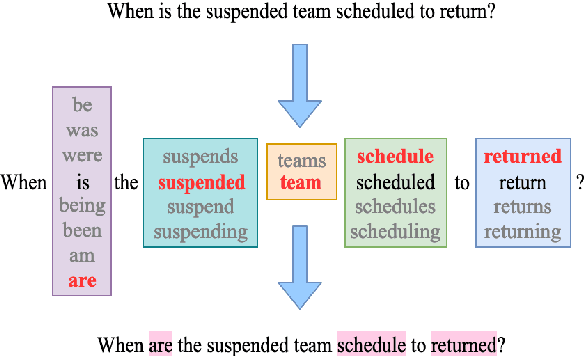

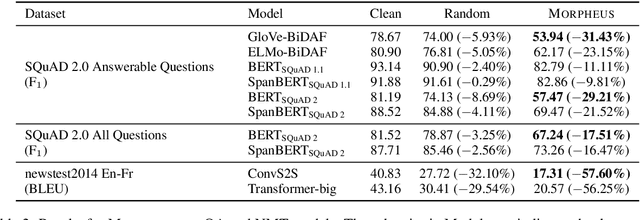
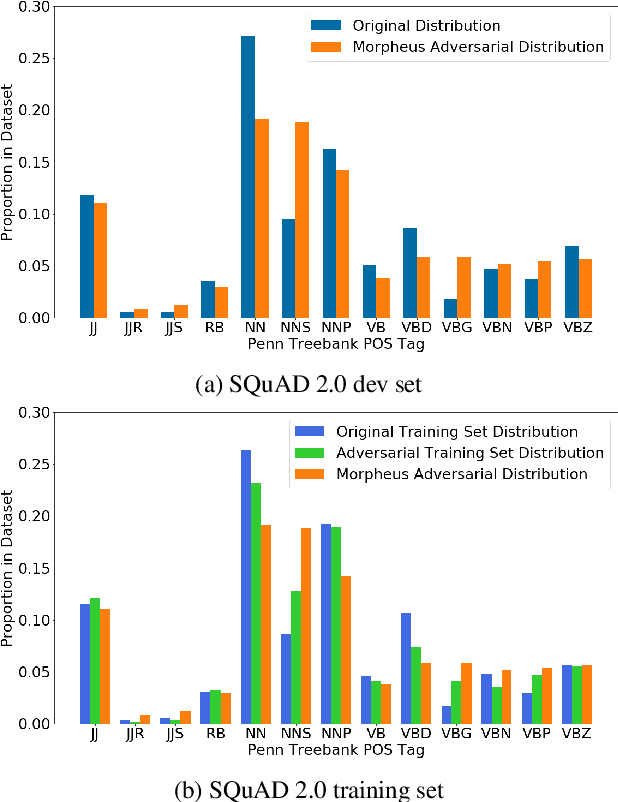
Training on only perfect Standard English corpora predisposes pre-trained neural networks to discriminate against minorities from non-standard linguistic backgrounds (e.g., African American Vernacular English, Colloquial Singapore English, etc.). We perturb the inflectional morphology of words to craft plausible and semantically similar adversarial examples that expose these biases in popular NLP models, e.g., BERT and Transformer, and show that adversarially fine-tuning them for a single epoch significantly improves robustness without sacrificing performance on clean data.
ToD-BERT: Pre-trained Natural Language Understanding for Task-Oriented Dialogues
Apr 29, 2020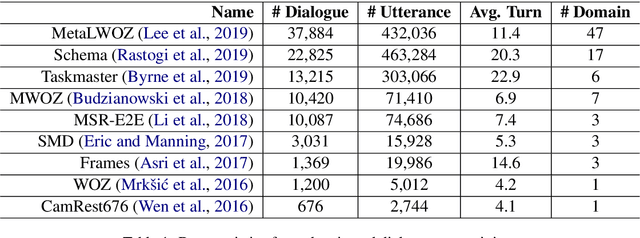
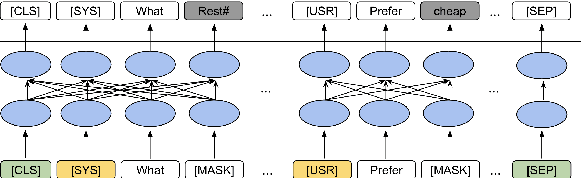
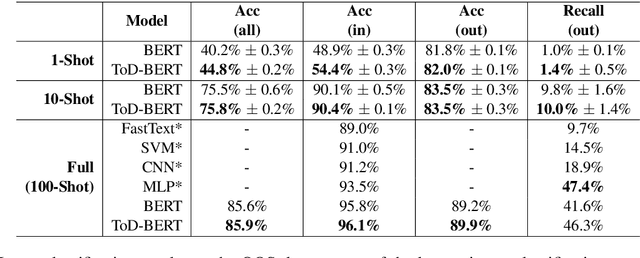
The use of pre-trained language models has emerged as a promising direction for improving dialogue systems. However, the underlying difference of linguistic patterns between conversational data and general text makes the existing pre-trained language models not as effective as they have been shown to be. Recently, there are some pre-training approaches based on open-domain dialogues, leveraging large-scale social media data such as Twitter or Reddit. Pre-training for task-oriented dialogues, on the other hand, is rarely discussed because of the long-standing and crucial data scarcity problem. In this work, we combine nine English-based, human-human, multi-turn and publicly available task-oriented dialogue datasets to conduct language model pre-training. The experimental results show that our pre-trained task-oriented dialogue BERT (ToD-BERT) surpasses BERT and other strong baselines in four downstream task-oriented dialogue applications, including intention detection, dialogue state tracking, dialogue act prediction, and response selection. Moreover, in the simulated limited data experiments, we show that ToD-BERT has stronger few-shot capacity that can mitigate the data scarcity problem in task-oriented dialogues.