 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Local Distributions in Graph Signal Processing
Feb 22, 2022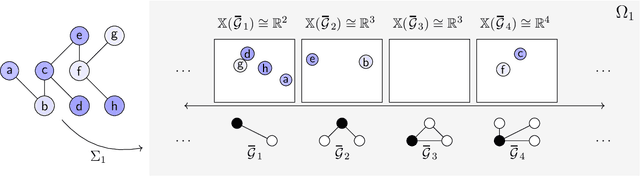
Graph filtering is the cornerstone operation in graph signal processing (GSP). Thus, understanding it is key in developing potent GSP methods. Graph filters are local and distributed linear operations, whose output depends only on the local neighborhood of each node. Moreover, a graph filter's output can be computed separately at each node by carrying out repeated exchanges with immediate neighbors. Graph filters can be compactly written as polynomials of a graph shift operator (typically, a sparse matrix description of the graph). This has led to relating the properties of the filters with the spectral properties of the corresponding matrix -- which encodes global structure of the graph. In this work, we propose a framework that relies solely on the local distribution of the neighborhoods of a graph. The crux of this approach is to describe graphs and graph signals in terms of a measurable space of rooted balls. Leveraging this, we are able to seamlessly compare graphs of different sizes and coming from different models, yielding results on the convergence of spectral densities, transferability of filters across arbitrary graphs, and continuity of graph signal properties with respect to the distribution of local substructures.
Open-Ended Knowledge Tracing
Feb 21, 2022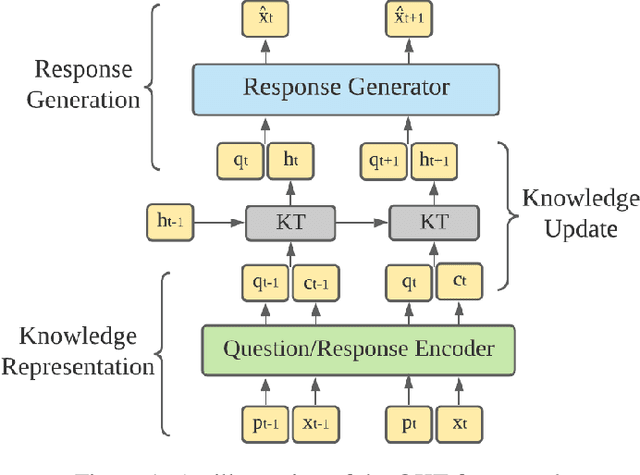
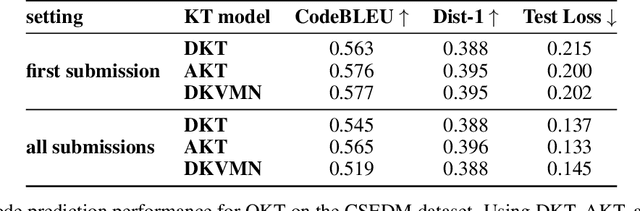
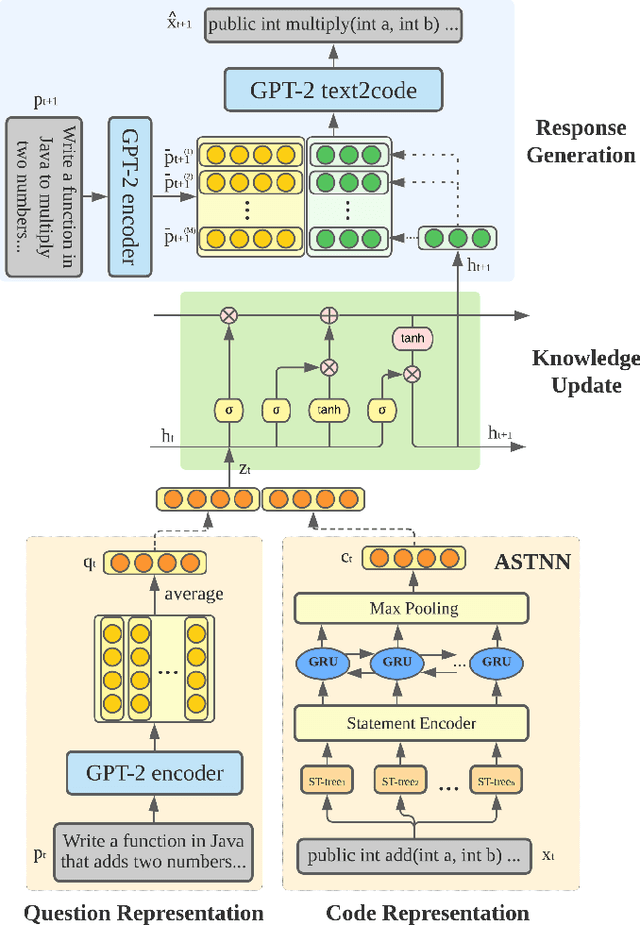
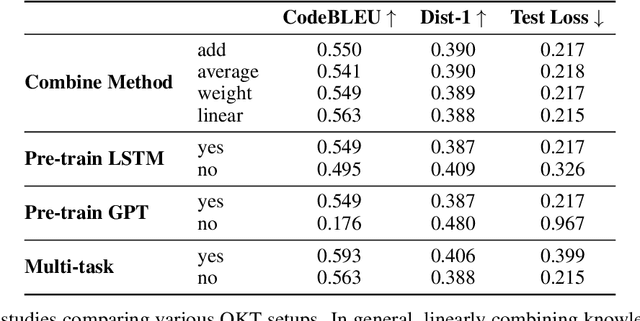
Knowledge tracing refers to the problem of estimating each student's knowledge component/skill mastery level from their past responses to questions in educational applications. One direct benefit knowledge tracing methods provide is the ability to predict each student's performance on the future questions. However, one key limitation of most existing knowledge tracing methods is that they treat student responses to questions as binary-valued, i.e., whether the responses are correct or incorrect. Response correctness analysis/prediction is easy to navigate but loses important information, especially for open-ended questions: the exact student responses can potentially provide much more information about their knowledge states than only response correctness. In this paper, we present our first exploration into open-ended knowledge tracing, i.e., the analysis and prediction of students' open-ended responses to questions in the knowledge tracing setup. We first lay out a generic framework for open-ended knowledge tracing before detailing its application to the domain of computer science education with programming questions. We define a series of evaluation metrics in this domain and conduct a series of quantitative and qualitative experiments to test the boundaries of open-ended knowledge tracing methods on a real-world student code dataset.
MINER: Multiscale Implicit Neural Representations
Feb 07, 2022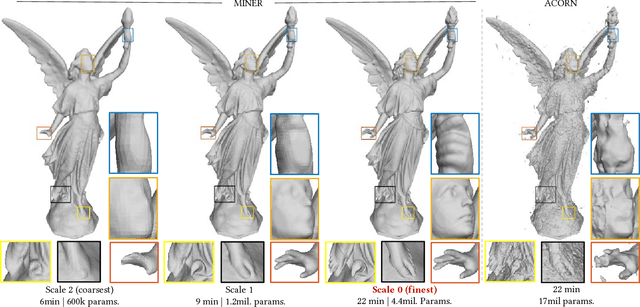
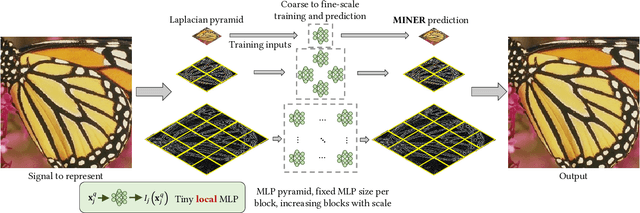
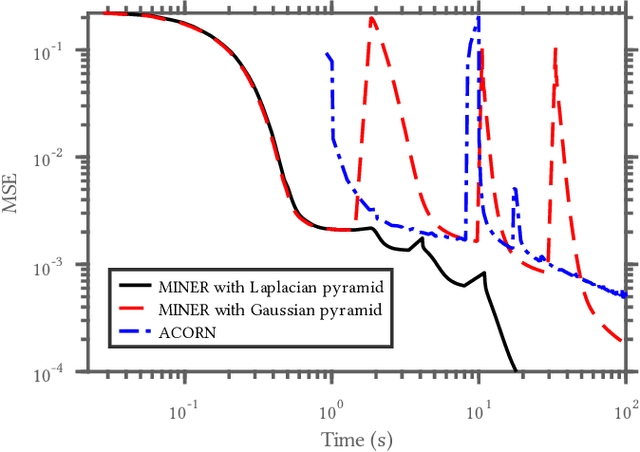

We introduce a new neural signal representation designed for the efficient high-resolution representation of large-scale signals. The key innovation in our multiscale implicit neural representation (MINER) is an internal representation via a Laplacian pyramid, which provides a sparse multiscale representation of the signal that captures orthogonal parts of the signal across scales. We leverage the advantages of the Laplacian pyramid by representing small disjoint patches of the pyramid at each scale with a tiny MLP. This enables the capacity of the network to adaptively increase from coarse to fine scales, and only represent parts of the signal with strong signal energy. The parameters of each MLP are optimized from coarse-to-fine scale which results in faster approximations at coarser scales, thereby ultimately an extremely fast training process. We apply MINER to a range of large-scale signal representation tasks, including gigapixel images and very large point clouds, and demonstrate that it requires fewer than 25% of the parameters, 33% of the memory footprint, and 10% of the computation time of competing techniques such as ACORN to reach the same representation error.
Parameters or Privacy: A Provable Tradeoff Between Overparameterization and Membership Inference
Feb 02, 2022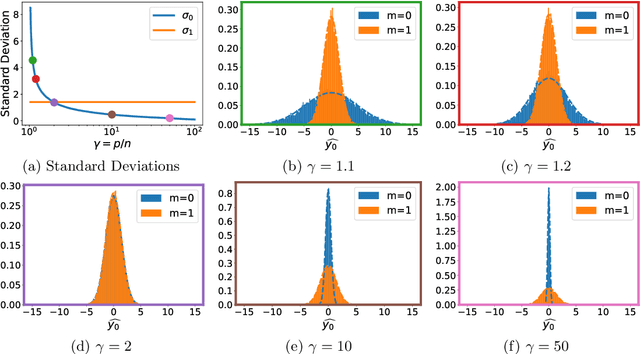

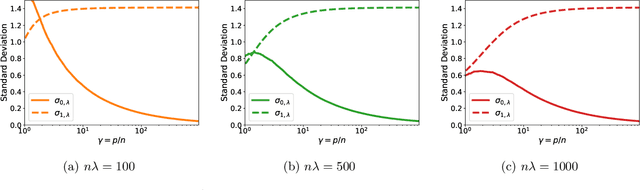
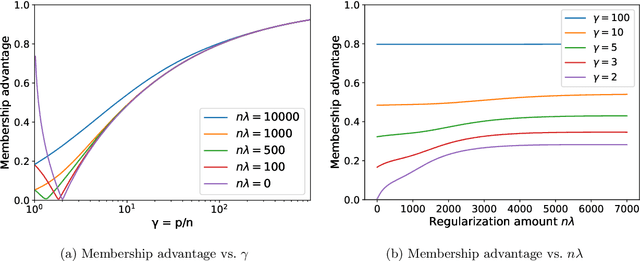
A surprising phenomenon in modern machine learning is the ability of a highly overparameterized model to generalize well (small error on the test data) even when it is trained to memorize the training data (zero error on the training data). This has led to an arms race towards increasingly overparameterized models (c.f., deep learning). In this paper, we study an underexplored hidden cost of overparameterization: the fact that overparameterized models are more vulnerable to privacy attacks, in particular the membership inference attack that predicts the (potentially sensitive) examples used to train a model. We significantly extend the relatively few empirical results on this problem by theoretically proving for an overparameterized linear regression model with Gaussian data that the membership inference vulnerability increases with the number of parameters. Moreover, a range of empirical studies indicates that more complex, nonlinear models exhibit the same behavior. Finally, we study different methods for mitigating such attacks in the overparameterized regime, such as noise addition and regularization, and conclude that simply reducing the parameters of an overparameterized model is an effective strategy to protect it from membership inference without greatly decreasing its generalization error.
Transformer with a Mixture of Gaussian Keys
Oct 16, 2021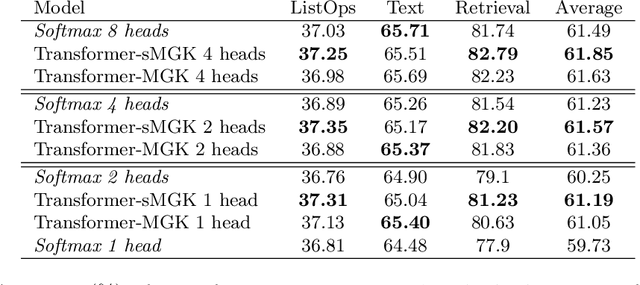
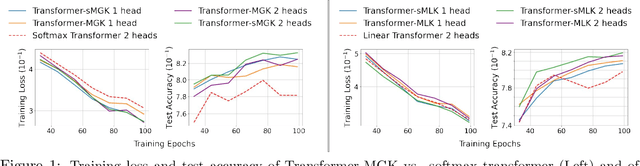
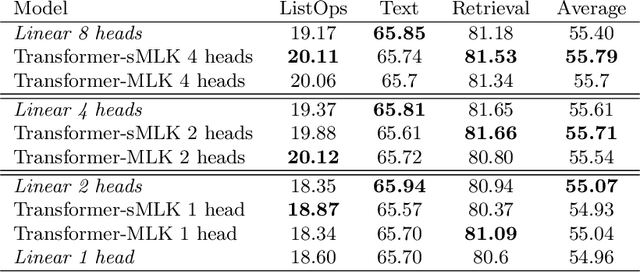
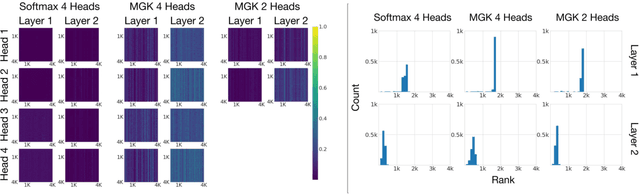
Multi-head attention is a driving force behind state-of-the-art transformers which achieve remarkable performance across a variety of natural language processing (NLP) and computer vision tasks. It has been observed that for many applications, those attention heads learn redundant embedding, and most of them can be removed without degrading the performance of the model. Inspired by this observation, we propose Transformer with a Mixture of Gaussian Keys (Transformer-MGK), a novel transformer architecture that replaces redundant heads in transformers with a mixture of keys at each head. These mixtures of keys follow a Gaussian mixture model and allow each attention head to focus on different parts of the input sequence efficiently. Compared to its conventional transformer counterpart, Transformer-MGK accelerates training and inference, has fewer parameters, and requires less FLOPs to compute while achieving comparable or better accuracy across tasks. Transformer-MGK can also be easily extended to use with linear attentions. We empirically demonstrate the advantage of Transformer-MGK in a range of practical applications including language modeling and tasks that involve very long sequences. On the Wikitext-103 and Long Range Arena benchmark, Transformer-MGKs with 4 heads attain comparable or better performance to the baseline transformers with 8 heads.
NeuroView: Explainable Deep Network Decision Making
Oct 15, 2021
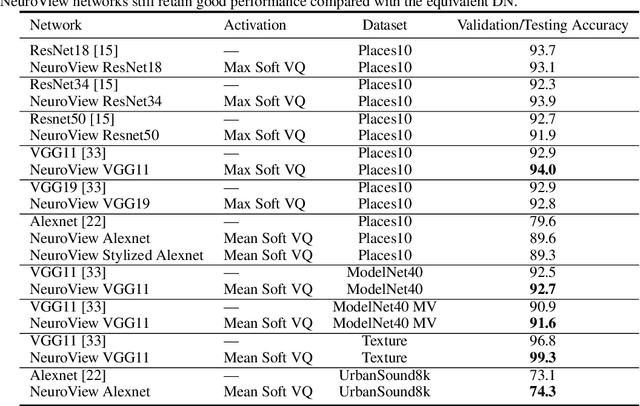
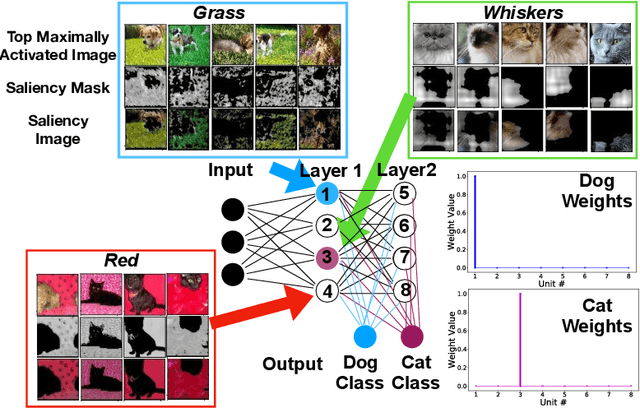
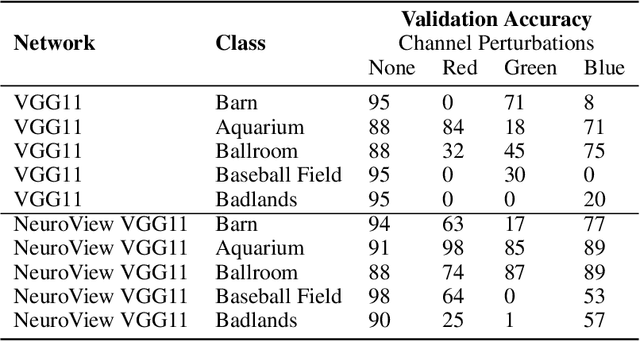
Deep neural networks (DNs) provide superhuman performance in numerous computer vision tasks, yet it remains unclear exactly which of a DN's units contribute to a particular decision. NeuroView is a new family of DN architectures that are interpretable/explainable by design. Each member of the family is derived from a standard DN architecture by vector quantizing the unit output values and feeding them into a global linear classifier. The resulting architecture establishes a direct, causal link between the state of each unit and the classification decision. We validate NeuroView on standard datasets and classification tasks to show that how its unit/class mapping aids in understanding the decision-making process.
NFT-K: Non-Fungible Tangent Kernels
Oct 11, 2021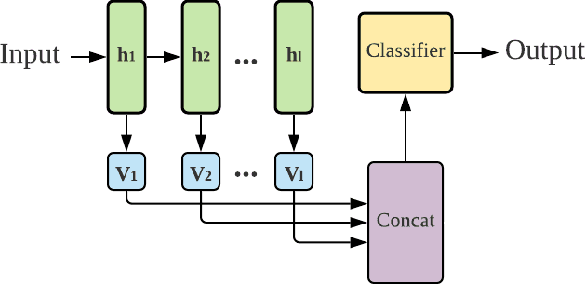
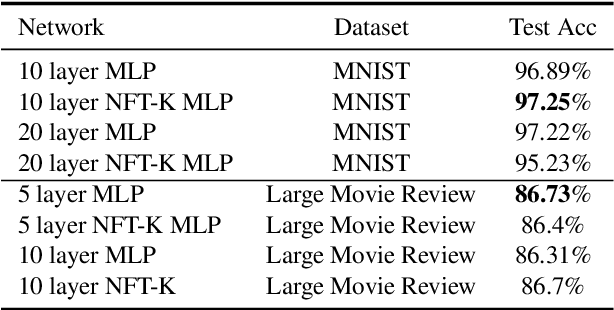
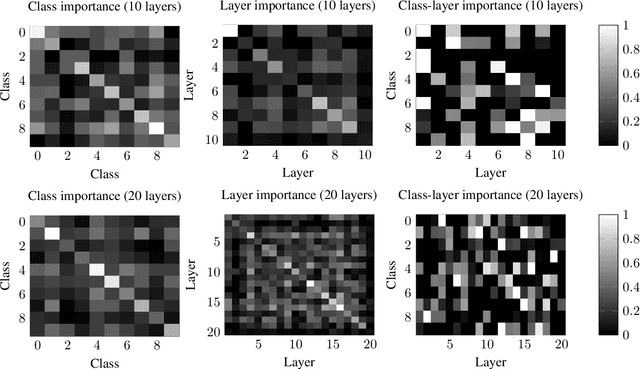
Deep neural networks have become essential for numerous applications due to their strong empirical performance such as vision, RL, and classification. Unfortunately, these networks are quite difficult to interpret, and this limits their applicability in settings where interpretability is important for safety, such as medical imaging. One type of deep neural network is neural tangent kernel that is similar to a kernel machine that provides some aspect of interpretability. To further contribute interpretability with respect to classification and the layers, we develop a new network as a combination of multiple neural tangent kernels, one to model each layer of the deep neural network individually as opposed to past work which attempts to represent the entire network via a single neural tangent kernel. We demonstrate the interpretability of this model on two datasets, showing that the multiple kernels model elucidates the interplay between the layers and predictions.
Evaluating generative networks using Gaussian mixtures of image features
Oct 08, 2021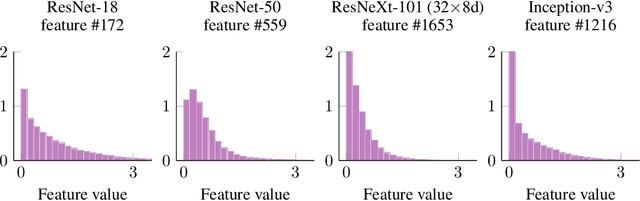

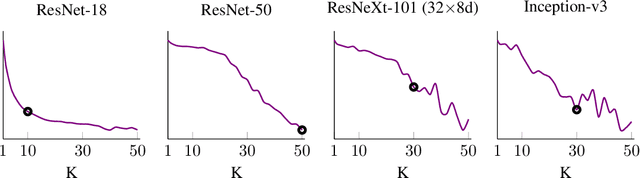

We develop a measure for evaluating the performance of generative networks given two sets of images. A popular performance measure currently used to do this is the Fr\'echet Inception Distance (FID). However, FID assumes that images featurized using the penultimate layer of Inception-v3 follow a Gaussian distribution. This assumption allows FID to be easily computed, since FID uses the 2-Wasserstein distance of two Gaussian distributions fitted to the featurized images. However, we show that Inception-v3 features of the ImageNet dataset are not Gaussian; in particular, each marginal is not Gaussian. To remedy this problem, we model the featurized images using Gaussian mixture models (GMMs) and compute the 2-Wasserstein distance restricted to GMMs. We define a performance measure, which we call WaM, on two sets of images by using Inception-v3 (or another classifier) to featurize the images, estimate two GMMs, and use the restricted 2-Wasserstein distance to compare the GMMs. We experimentally show the advantages of WaM over FID, including how FID is more sensitive than WaM to image perturbations. By modelling the non-Gaussian features obtained from Inception-v3 as GMMs and using a GMM metric, we can more accurately evaluate generative network performance.
Unrolling Particles: Unsupervised Learning of Sampling Distributions
Oct 06, 2021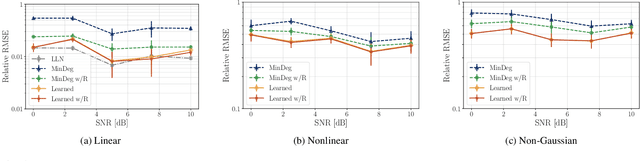
Particle filtering is used to compute good nonlinear estimates of complex systems. It samples trajectories from a chosen distribution and computes the estimate as a weighted average. Easy-to-sample distributions often lead to degenerate samples where only one trajectory carries all the weight, negatively affecting the resulting performance of the estimate. While much research has been done on the design of appropriate sampling distributions that would lead to controlled degeneracy, in this paper our objective is to \emph{learn} sampling distributions. Leveraging the framework of algorithm unrolling, we model the sampling distribution as a multivariate normal, and we use neural networks to learn both the mean and the covariance. We carry out unsupervised training of the model to minimize weight degeneracy, relying only on the observed measurements of the system. We show in simulations that the resulting particle filter yields good estimates in a wide range of scenarios.
Math Word Problem Generation with Mathematical Consistency and Problem Context Constraints
Sep 09, 2021
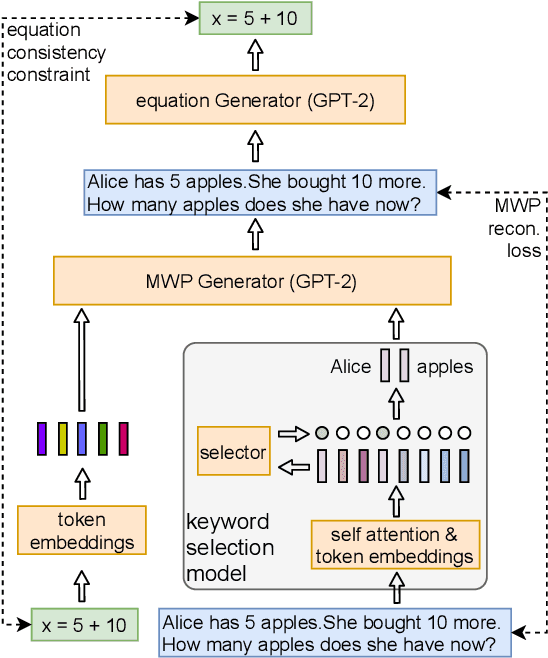

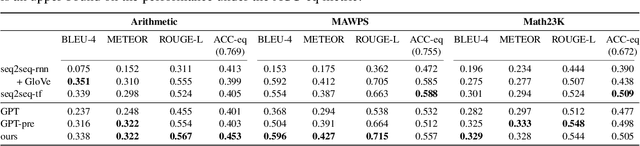
We study the problem of generating arithmetic math word problems (MWPs) given a math equation that specifies the mathematical computation and a context that specifies the problem scenario. Existing approaches are prone to generating MWPs that are either mathematically invalid or have unsatisfactory language quality. They also either ignore the context or require manual specification of a problem template, which compromises the diversity of the generated MWPs. In this paper, we develop a novel MWP generation approach that leverages i) pre-trained language models and a context keyword selection model to improve the language quality of the generated MWPs and ii) an equation consistency constraint for math equations to improve the mathematical validity of the generated MWPs. Extensive quantitative and qualitative experiments on three real-world MWP datasets demonstrate the superior performance of our approach compared to various baselines.