 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Improve Image Compression without Changing the Standard Decoder
Oct 23, 2020
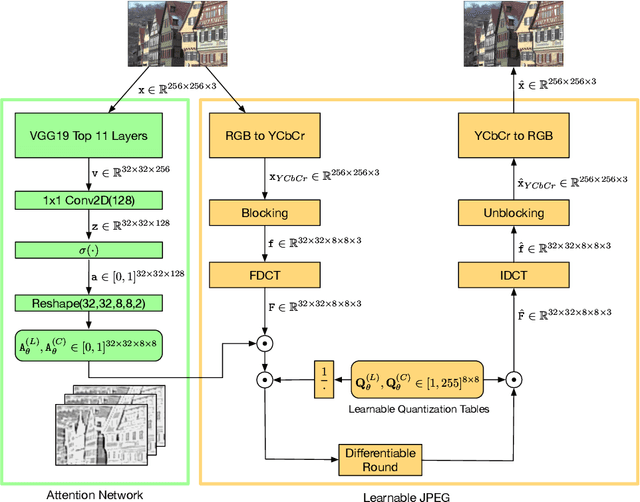
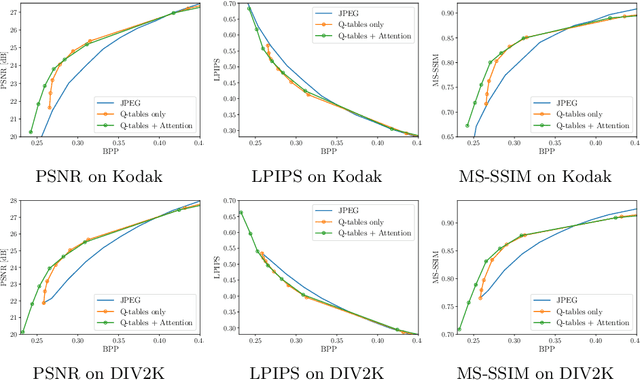

In recent years we have witnessed an increasing interest in applying Deep Neural Networks (DNNs) to improve the rate-distortion performance in image compression. However, the existing approaches either train a post-processing DNN on the decoder side, or propose learning for image compression in an end-to-end manner. This way, the trained DNNs are required in the decoder, leading to the incompatibility to the standard image decoders (e.g., JPEG) in personal computers and mobiles. Therefore, we propose learning to improve the encoding performance with the standard decoder. In this paper, We work on JPEG as an example. Specifically, a frequency-domain pre-editing method is proposed to optimize the distribution of DCT coefficients, aiming at facilitating the JPEG compression. Moreover, we propose learning the JPEG quantization table jointly with the pre-editing network. Most importantly, we do not modify the JPEG decoder and therefore our approach is applicable when viewing images with the widely used standard JPEG decoder. The experiments validate that our approach successfully improves the rate-distortion performance of JPEG in terms of various quality metrics, such as PSNR, MS-SSIM and LPIPS. Visually, this translates to better overall color retention especially when strong compression is applied. The codes are available at https://github.com/YannickStruempler/LearnedJPEG.
Learning for Video Compression with Recurrent Auto-Encoder and Recurrent Probability Model
Jun 29, 2020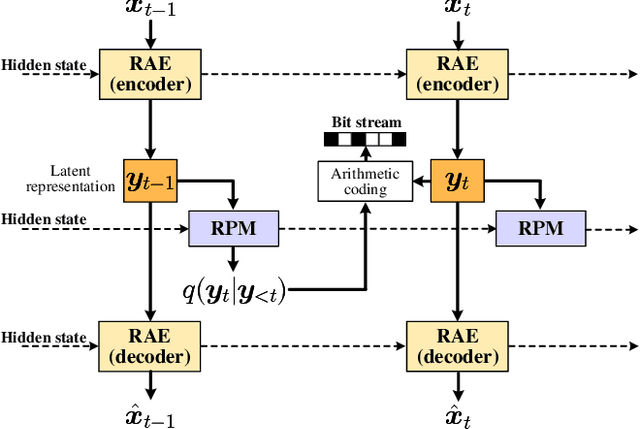
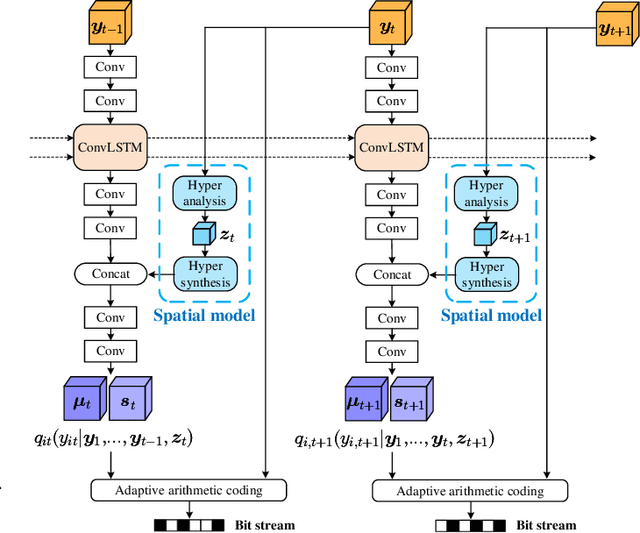
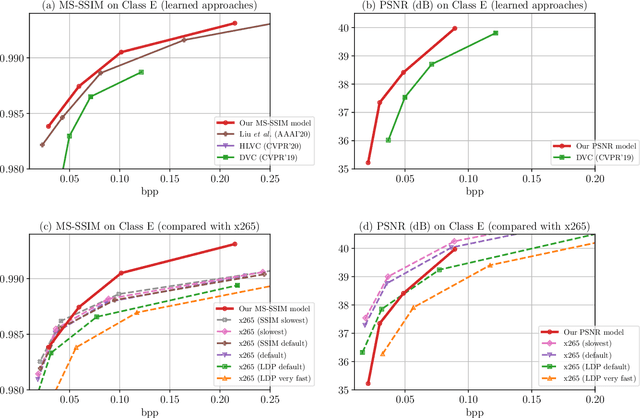
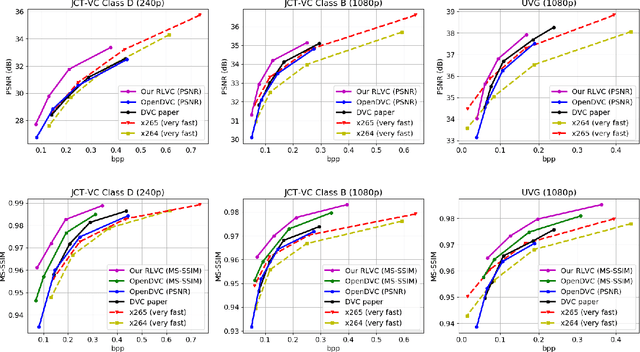
The past few years have witnessed increasing interests in applying deep learning to video compression. However, the existing approaches compress a video frame with only a few number of reference frames, which limits their ability to fully exploit the temporal correlation among video frames. To overcome this shortcoming, this paper proposes a Recurrent Learned Video Compression (RLVC) approach with the Recurrent Auto-Encoder (RAE) and Recurrent Probability Model (RPM). Specifically, the RAE employs recurrent cells in both the encoder and decoder. As such, the temporal information in a large range of frames can be used for generating latent representations and reconstructing compressed outputs. Furthermore, the proposed RPM network recurrently estimates the Probability Mass Function (PMF) of the latent representation, conditioned on the distribution of previous latent representations. Due to the correlation among consecutive frames, the conditional cross entropy can be lower than the independent cross entropy, thus reducing the bit-rate. The experiments show that our approach achieves the state-of-the-art learned video compression performance in terms of both PSNR and MS-SSIM. Moreover, our approach outperforms the default Low-Delay P (LDP) setting of x265 on PSNR, and also has better performance on MS-SSIM than the SSIM-tuned x265 and the slowest setting of x265.
OpenDVC: An Open Source Implementation of the DVC Video Compression Method
Jun 29, 2020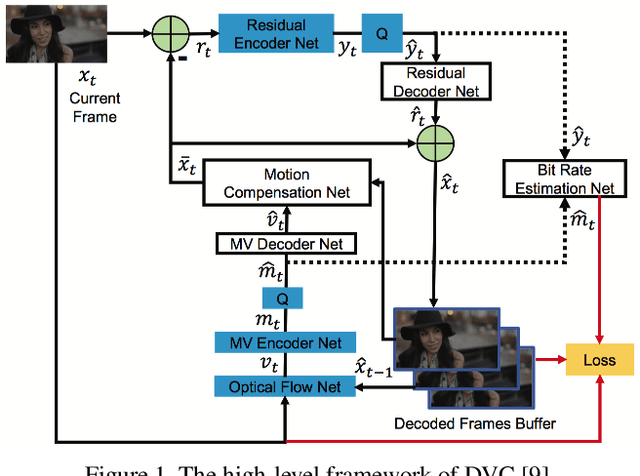
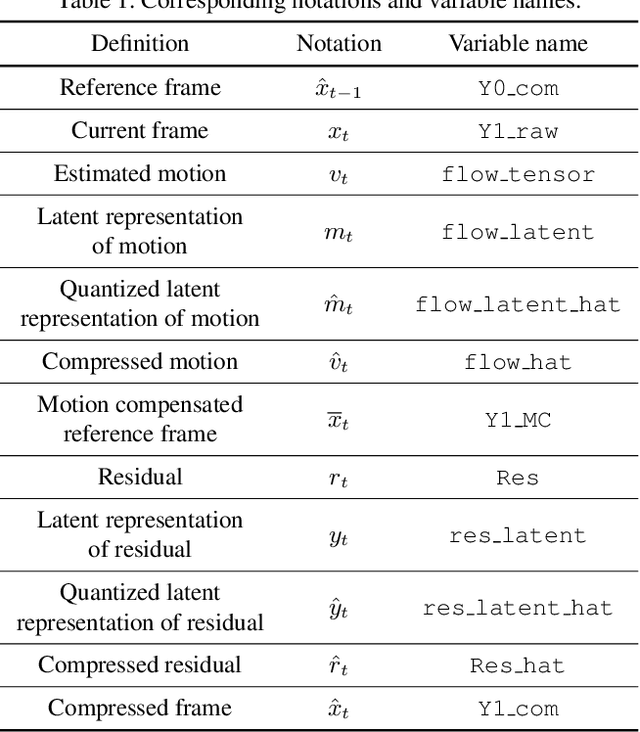
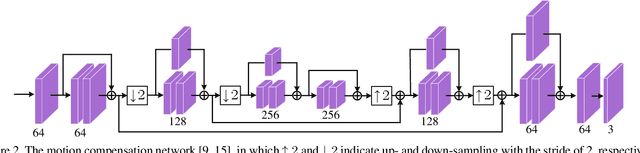
We introduce an open source Tensorflow implementation of the Deep Video Compression (DVC) method in this technical report. DVC is the first end-to-end optimized learned video compression method, achieving better MS-SSIM performance than the Low-Delay P (LDP) very fast setting of x265 and comparable PSNR performance with x265 (LDP very fast). At the time of writing this report, several learned video compression methods are superior to DVC, but currently none of them provides open source codes. We hope that our OpenDVC codes are able to provide a useful model for further development, and facilitate future researches on learned video compression. Different from the original DVC, which is only optimized for PSNR, we release not only the PSNR-optimized re-implementation, denoted by OpenDVC (PSNR), but also the MS-SSIM-optimized model OpenDVC (MS-SSIM). Our OpenDVC (MS-SSIM) model provides a more convincing baseline for MS-SSIM optimized methods, which can only compare with the PSNR optimized DVC in the past. The OpenDVC source codes and pre-trained models are publicly released at https://github.com/RenYang-home/OpenDVC.
Learning for Video Compression with Hierarchical Quality and Recurrent Enhancement
Apr 08, 2020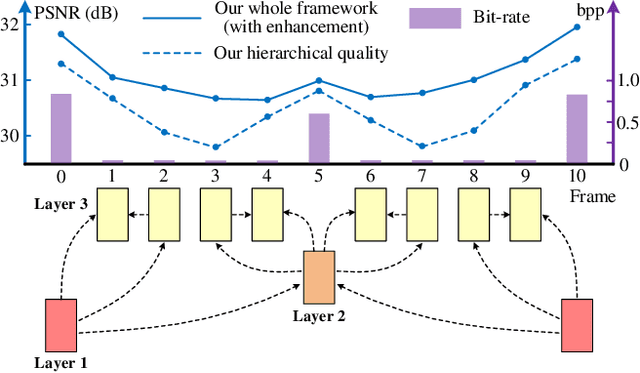
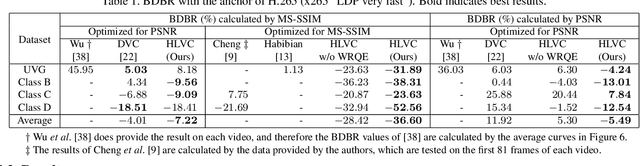
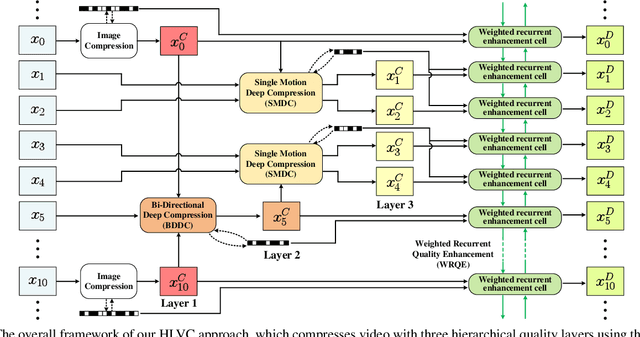
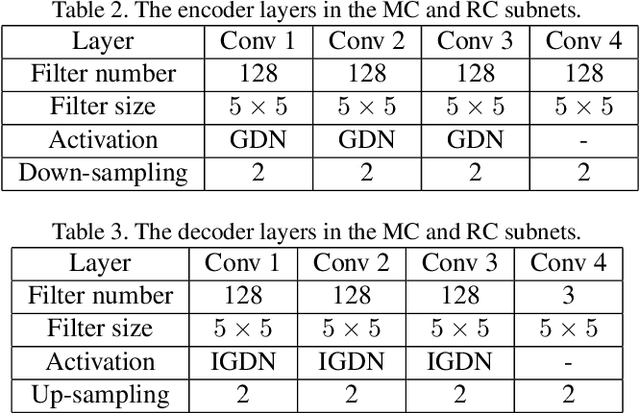
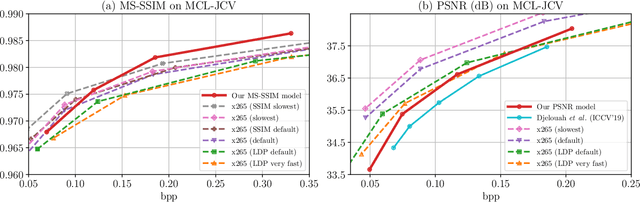
In this paper, we propose a Hierarchical Learned Video Compression (HLVC) method with three hierarchical quality layers and a recurrent enhancement network. The frames in the first layer are compressed by an image compression method with the highest quality. Using these frames as references, we propose the Bi-Directional Deep Compression (BDDC) network to compress the second layer with relatively high quality. Then, the third layer frames are compressed with the lowest quality, by the proposed Single Motion Deep Compression (SMDC) network, which adopts a single motion map to estimate the motions of multiple frames, thus saving bits for motion information. In our deep decoder, we develop the Weighted Recurrent Quality Enhancement (WRQE) network, which takes both compressed frames and the bit stream as inputs. In the recurrent cell of WRQE, the memory and update signal are weighted by quality features to reasonably leverage multi-frame information for enhancement. In our HLVC approach, the hierarchical quality benefits the coding efficiency, since the high quality information facilitates the compression and enhancement of low quality frames at encoder and decoder sides, respectively. Finally, the experiments validate that our HLVC approach advances the state-of-the-art of deep video compression methods, and outperforms the "Low-Delay P (LDP) very fast" mode of x265 in terms of both PSNR and MS-SSIM. The project page is at https://github.com/RenYang-home/HLVC.
Wavelet Domain Style Transfer for an Effective Perception-distortion Tradeoff in Single Image Super-Resolution
Oct 09, 2019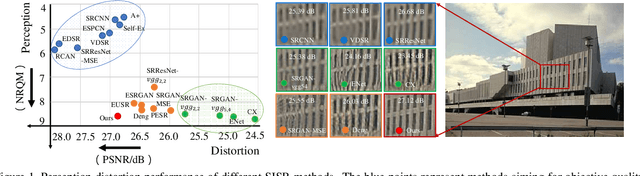
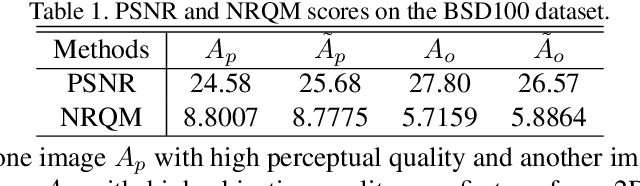
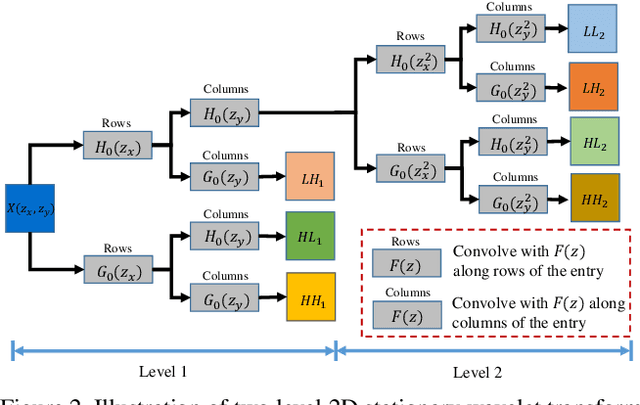
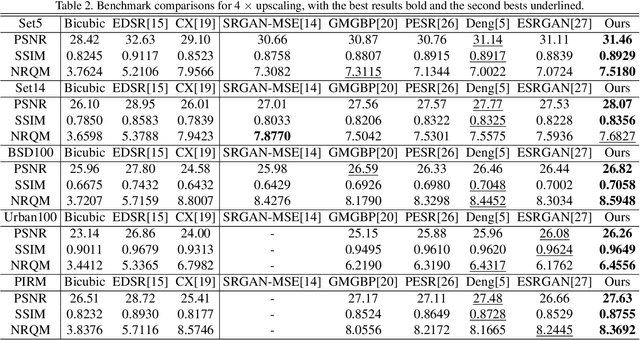
In single image super-resolution (SISR), given a low-resolution (LR) image, one wishes to find a high-resolution (HR) version of it which is both accurate and photo-realistic. Recently, it has been shown that there exists a fundamental tradeoff between low distortion and high perceptual quality, and the generative adversarial network (GAN) is demonstrated to approach the perception-distortion (PD) bound effectively. In this paper, we propose a novel method based on wavelet domain style transfer (WDST), which achieves a better PD tradeoff than the GAN based methods. Specifically, we propose to use 2D stationary wavelet transform (SWT) to decompose one image into low-frequency and high-frequency sub-bands. For the low-frequency sub-band, we improve its objective quality through an enhancement network. For the high-frequency sub-band, we propose to use WDST to effectively improve its perceptual quality. By feat of the perfect reconstruction property of wavelets, these sub-bands can be re-combined to obtain an image which has simultaneously high objective and perceptual quality. The numerical results on various datasets show that our method achieves the best trade-off between the distortion and perceptual quality among the existing state-of-the-art SISR methods.
Quality-Gated Convolutional LSTM for Enhancing Compressed Video
Apr 14, 2019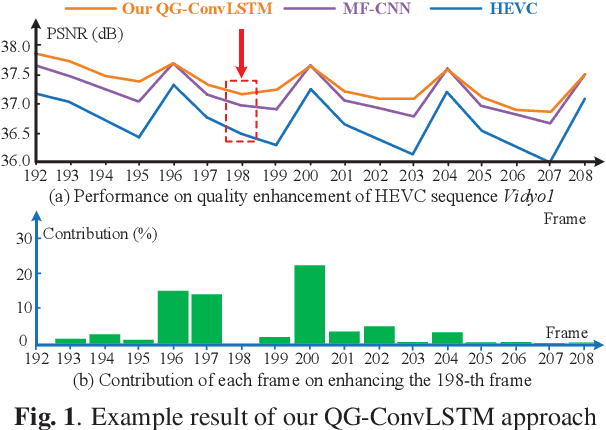
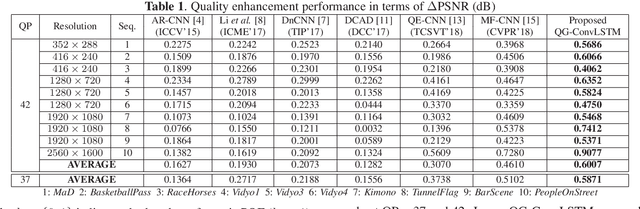
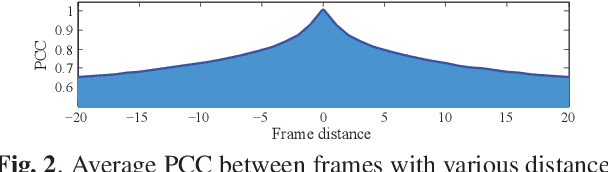
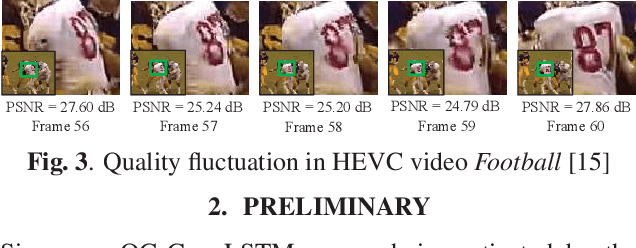
The past decade has witnessed great success in applying deep learning to enhance the quality of compressed video. However, the existing approaches aim at quality enhancement on a single frame, or only using fixed neighboring frames. Thus they fail to take full advantage of the inter-frame correlation in the video. This paper proposes the Quality-Gated Convolutional Long Short-Term Memory (QG-ConvLSTM) network with bi-directional recurrent structure to fully exploit the advantageous information in a large range of frames. More importantly, due to the obvious quality fluctuation among compressed frames, higher quality frames can provide more useful information for other frames to enhance quality. Therefore, we propose learning the "forget" and "input" gates in the ConvLSTM cell from quality-related features. As such, the frames with various quality contribute to the memory in ConvLSTM with different importance, making the information of each frame reasonably and adequately used. Finally, the experiments validate the effectiveness of our QG-ConvLSTM approach in advancing the state-of-the-art quality enhancement of compressed video, and the ablation study shows that our QG-ConvLSTM approach is learnt to make a trade-off between quality and correlation when leveraging multi-frame information. The project page: https://github.com/ryangchn/QG-ConvLSTM.git.
A DenseNet Based Approach for Multi-Frame In-Loop Filter in HEVC
Mar 05, 2019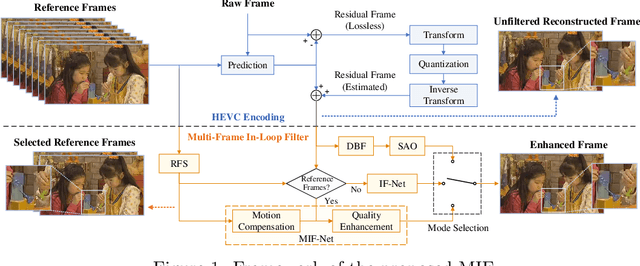
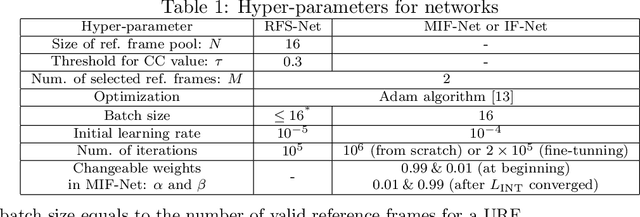
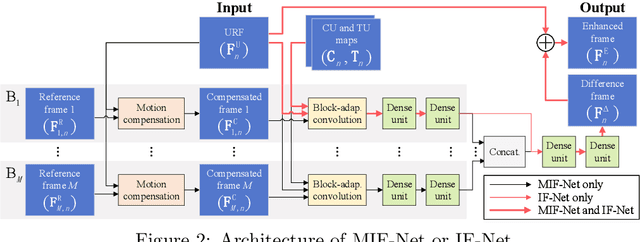
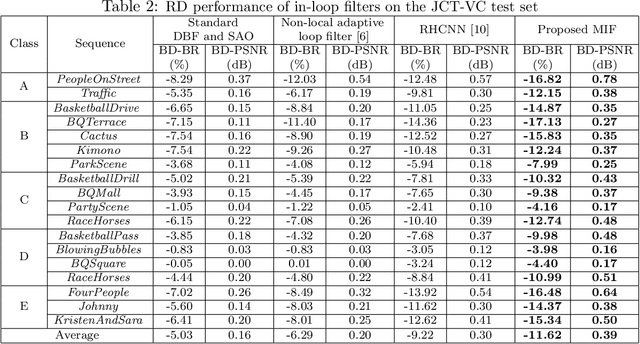
High efficiency video coding (HEVC) has brought outperforming efficiency for video compression. To reduce the compression artifacts of HEVC, we propose a DenseNet based approach as the in-loop filter of HEVC, which leverages multiple adjacent frames to enhance the quality of each encoded frame. Specifically, the higher-quality frames are found by a reference frame selector (RFS). Then, a deep neural network for multi-frame in-loop filter (named MIF-Net) is developed to enhance the quality of each encoded frame by utilizing the spatial information of this frame and the temporal information of its neighboring higher-quality frames. The MIF-Net is built on the recently developed DenseNet, benefiting from the improved generalization capacity and computational efficiency. Finally, experimental results verify the effectiveness of our multi-frame in-loop filter, outperforming the HM baseline and other state-of-the-art approaches.
* 10 pages, 4 figures. Accepted by Data Compression Conference 2019
MFQE 2.0: A New Approach for Multi-frame Quality Enhancement on Compressed Video
Feb 26, 2019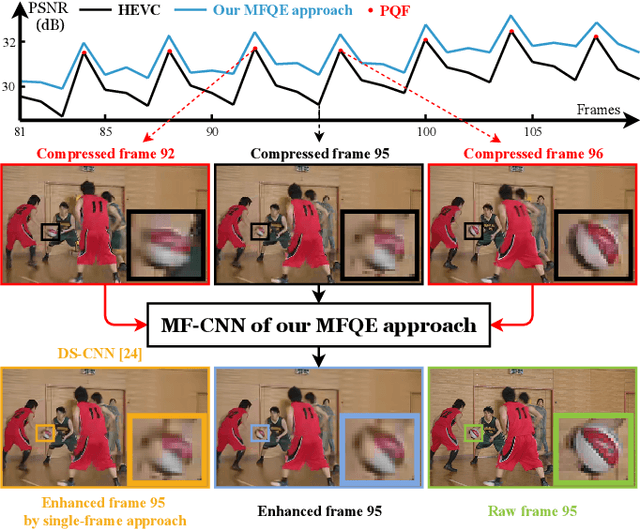
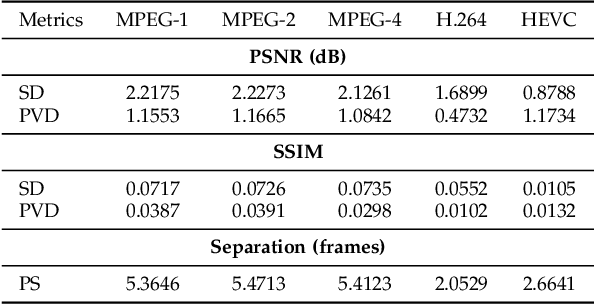

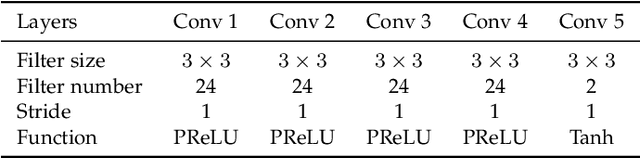
The past few years have witnessed great success in applying deep learning to enhance the quality of compressed image/video. The existing approaches mainly focus on enhancing the quality of a single frame, not considering the similarity between consecutive frames. Since heavy fluctuation exists across compressed video frames as investigated in this paper, frame similarity can be utilized for quality enhancement of low-quality frames by using their neighboring high-quality frames. This task can be seen as Multi-Frame Quality Enhancement (MFQE). Accordingly, this paper proposes an MFQE approach for compressed video, as the first attempt in this direction. In our approach, we firstly develop a Bidirectional Long Short-Term Memory (BiLSTM) based detector to locate Peak Quality Frames (PQFs) in compressed video. Then, a novel Multi-Frame Convolutional Neural Network (MF-CNN) is designed to enhance the quality of compressed video, in which the non-PQF and its nearest two PQFs are the input. In MF-CNN, motion between the non-PQF and PQFs is compensated by a motion compensation subnet. Subsequently, a quality enhancement subnet fuses the non-PQF and compensated PQFs, and then reduces the compression artifacts of the non-PQF. Finally, experiments validate the effectiveness and generalization ability of our MFQE approach in advancing the state-of-the-art quality enhancement of compressed video. The code of our MFQE approach is available at https://github.com/RyanXingQL/MFQE2.0.git.
Understanding and Predicting the Memorability of Natural Scene Images
Oct 17, 2018
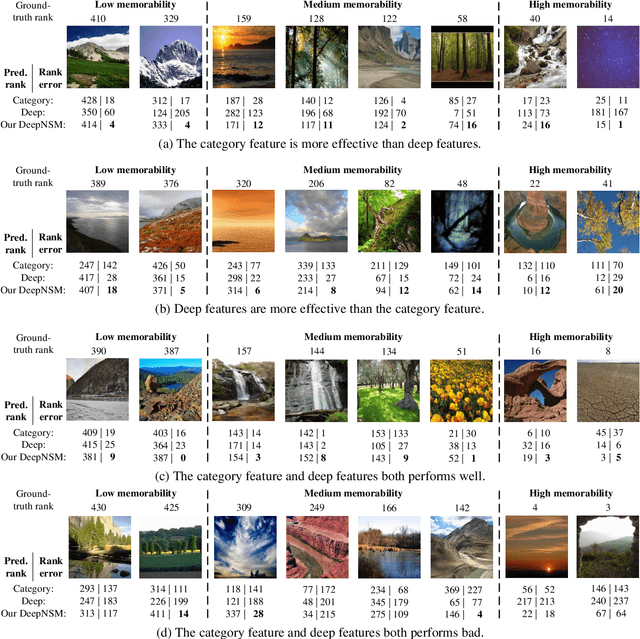

Memorability measures how easily an image is to be memorized after glancing, which may contribute to designing magazine covers, tourism publicity materials, and so forth. Recent works have shed light on the visual features that make generic images, object images or face photographs memorable. However, a clear understanding and reliable estimation of natural scene memorability remain elusive. In this paper, we provide an attempt to answer: "what exactly makes natural scene memorable". To this end, we first establish a large-scale natural scene image memorability (LNSIM) database, containing 2,632 natural scene images and their ground truth memorability scores. Then, we mine our database to investigate how low-, middle- and high-level handcrafted features affect the memorability of natural scene. In particular, we find that high-level feature of scene category is rather correlated with natural scene memorability. We also find that deep feature is effective in predicting the memorability scores. Therefore, we propose a deep neural network based natural scene memorability (DeepNSM) predictor, which takes advantage of scene category. Finally, the experimental results validate the effectiveness of our DeepNSM, exceeding the state-of-the-art methods.
What Makes Natural Scene Memorable?
Aug 27, 2018

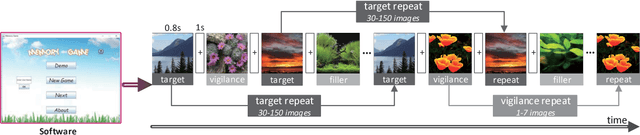

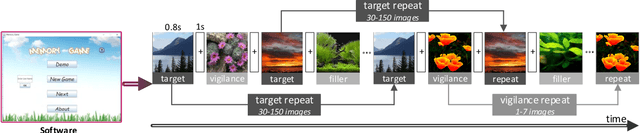
Recent studies on image memorability have shed light on the visual features that make generic images, object images or face photographs memorable. However, a clear understanding and reliable estimation of natural scene memorability remain elusive. In this paper, we provide an attempt to answer: "what exactly makes natural scene memorable". Specifically, we first build LNSIM, a large-scale natural scene image memorability database (containing 2,632 images and memorability annotations). Then, we mine our database to investigate how low-, middle- and high-level handcrafted features affect the memorability of natural scene. In particular, we find that high-level feature of scene category is rather correlated with natural scene memorability. Thus, we propose a deep neural network based natural scene memorability (DeepNSM) predictor, which takes advantage of scene category. Finally, the experimental results validate the effectiveness of DeepNSM.