 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs There More Pattern in Knowledge Graph? Exploring Proximity Pattern for Knowledge Graph Embedding
Oct 02, 2021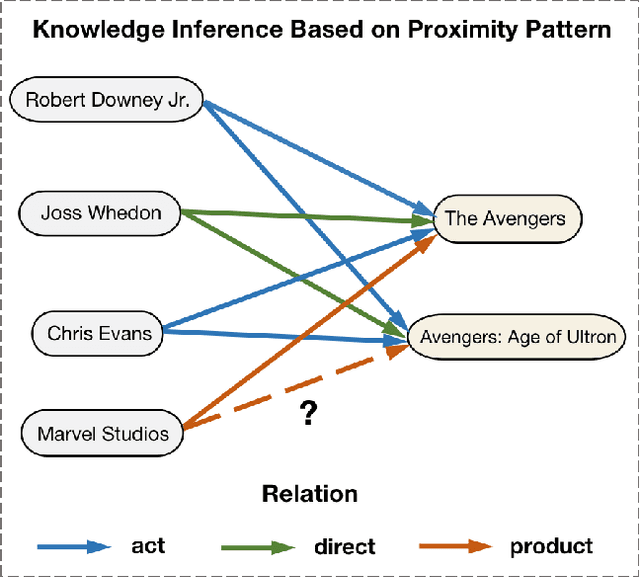

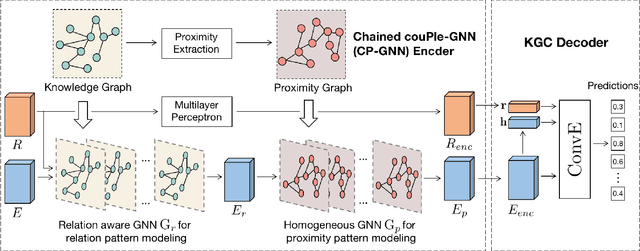
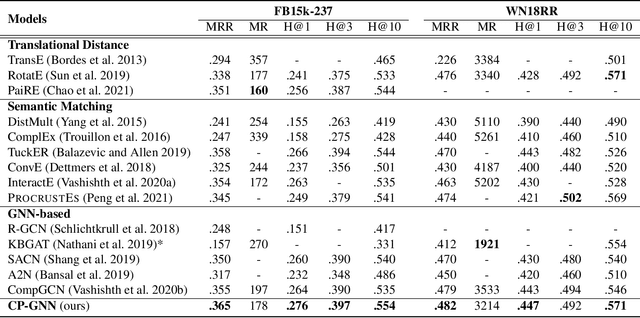
Modeling of relation pattern is the core focus of previous Knowledge Graph Embedding works, which represents how one entity is related to another semantically by some explicit relation. However, there is a more natural and intuitive relevancy among entities being always ignored, which is that how one entity is close to another semantically, without the consideration of any explicit relation. We name such semantic phenomenon in knowledge graph as proximity pattern. In this work, we explore the problem of how to define and represent proximity pattern, and how it can be utilized to help knowledge graph embedding. Firstly, we define the proximity of any two entities according to their statistically shared queries, then we construct a derived graph structure and represent the proximity pattern from global view. Moreover, with the original knowledge graph, we design a Chained couPle-GNN (CP-GNN) architecture to deeply merge the two patterns (graphs) together, which can encode a more comprehensive knowledge embedding. Being evaluated on FB15k-237 and WN18RR datasets, CP-GNN achieves state-of-the-art results for Knowledge Graph Completion task, and can especially boost the modeling capacity for complex queries that contain multiple answer entities, proving the effectiveness of introduced proximity pattern.
How Does Knowledge Graph Embedding Extrapolate to Unseen Data: a Semantic Evidence View
Sep 24, 2021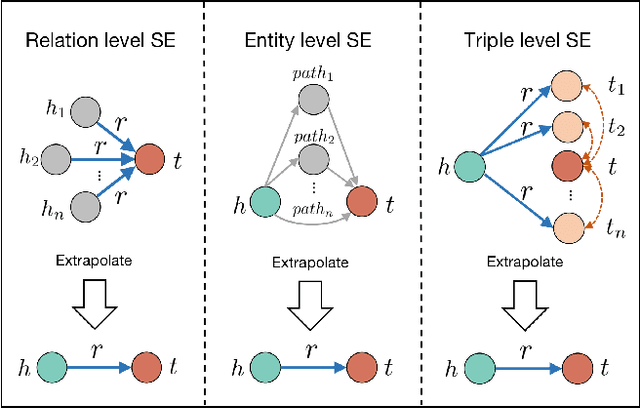
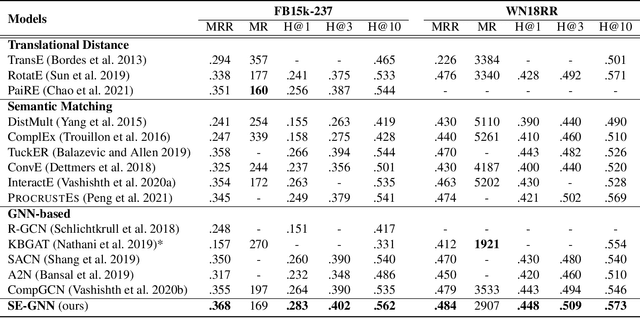
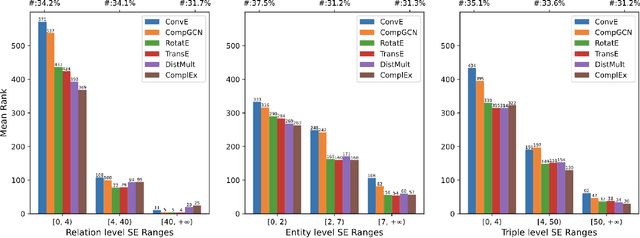
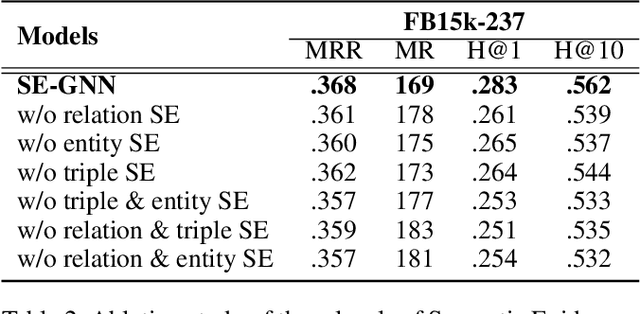
Knowledge Graph Embedding (KGE) aims to learn representations for entities and relations. Most KGE models have gained great success, especially on extrapolation scenarios. Specifically, given an unseen triple (h, r, t), a trained model can still correctly predict t from (h, r, ?), or h from (?, r, t), such extrapolation ability is impressive. However, most existing KGE works focus on the design of delicate triple modeling function, which mainly tell us how to measure the plausibility of observed triples, but we have limited understanding of why the methods can extrapolate to unseen data, and what are the important factors to help KGE extrapolate. Therefore in this work, we attempt to, from a data relevant view, study KGE extrapolation of two problems: 1. How does KGE extrapolate to unseen data? 2. How to design the KGE model with better extrapolation ability? For the problem 1, we first discuss the impact factors for extrapolation and from relation, entity and triple level respectively, propose three Semantic Evidences (SEs), which can be observed from training set and provide important semantic information for extrapolation to unseen data. Then we verify the effectiveness of SEs through extensive experiments on several typical KGE methods, and demonstrate that SEs serve as an important role for understanding the extrapolation ability of KGE. For the problem 2, to make better use of the SE information for more extrapolative knowledge representation, we propose a novel GNN-based KGE model, called Semantic Evidence aware Graph Neural Network (SE-GNN). Finally, through extensive experiments on FB15k-237 and WN18RR datasets, we show that SE-GNN achieves state-of-the-art performance on Knowledge Graph Completion task and perform a better extrapolation ability.
Learning Local Recurrent Models for Human Mesh Recovery
Jul 27, 2021

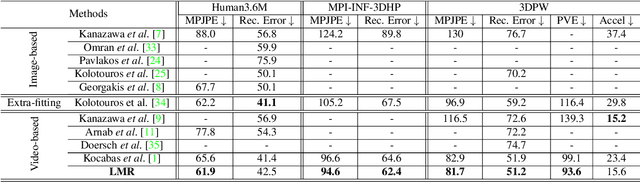
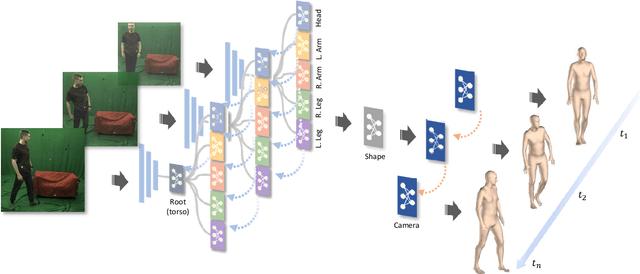
We consider the problem of estimating frame-level full human body meshes given a video of a person with natural motion dynamics. While much progress in this field has been in single image-based mesh estimation, there has been a recent uptick in efforts to infer mesh dynamics from video given its role in alleviating issues such as depth ambiguity and occlusions. However, a key limitation of existing work is the assumption that all the observed motion dynamics can be modeled using one dynamical/recurrent model. While this may work well in cases with relatively simplistic dynamics, inference with in-the-wild videos presents many challenges. In particular, it is typically the case that different body parts of a person undergo different dynamics in the video, e.g., legs may move in a way that may be dynamically different from hands (e.g., a person dancing). To address these issues, we present a new method for video mesh recovery that divides the human mesh into several local parts following the standard skeletal model. We then model the dynamics of each local part with separate recurrent models, with each model conditioned appropriately based on the known kinematic structure of the human body. This results in a structure-informed local recurrent learning architecture that can be trained in an end-to-end fashion with available annotations. We conduct a variety of experiments on standard video mesh recovery benchmark datasets such as Human3.6M, MPI-INF-3DHP, and 3DPW, demonstrating the efficacy of our design of modeling local dynamics as well as establishing state-of-the-art results based on standard evaluation metrics.
Everybody Is Unique: Towards Unbiased Human Mesh Recovery
Jul 13, 2021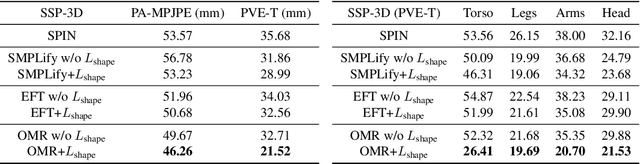
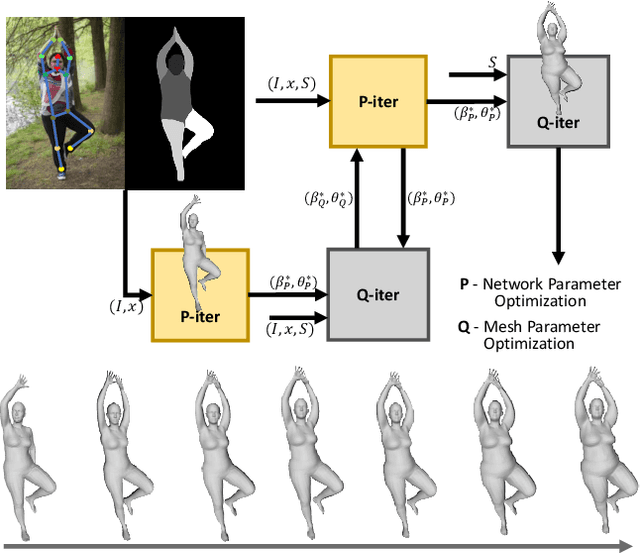
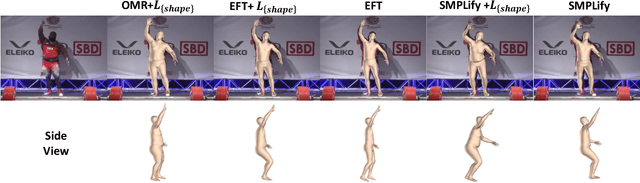
We consider the problem of obese human mesh recovery, i.e., fitting a parametric human mesh to images of obese people. Despite obese person mesh fitting being an important problem with numerous applications (e.g., healthcare), much recent progress in mesh recovery has been restricted to images of non-obese people. In this work, we identify this crucial gap in the current literature by presenting and discussing limitations of existing algorithms. Next, we present a simple baseline to address this problem that is scalable and can be easily used in conjunction with existing algorithms to improve their performance. Finally, we present a generalized human mesh optimization algorithm that substantially improves the performance of existing methods on both obese person images as well as community-standard benchmark datasets. A key innovation of this technique is that it does not rely on supervision from expensive-to-create mesh parameters. Instead, starting from widely and cheaply available 2D keypoints annotations, our method automatically generates mesh parameters that can in turn be used to re-train and fine-tune any existing mesh estimation algorithm. This way, we show our method acts as a drop-in to improve the performance of a wide variety of contemporary mesh estimation methods. We conduct extensive experiments on multiple datasets comprising both standard and obese person images and demonstrate the efficacy of our proposed techniques.
A Hierarchical Deep Convolutional Neural Network and Gated Recurrent Unit Framework for Structural Damage Detection
May 29, 2020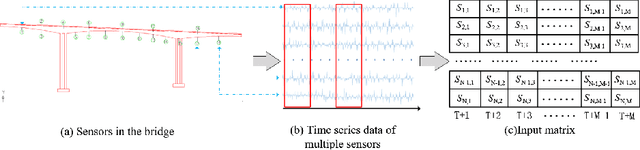

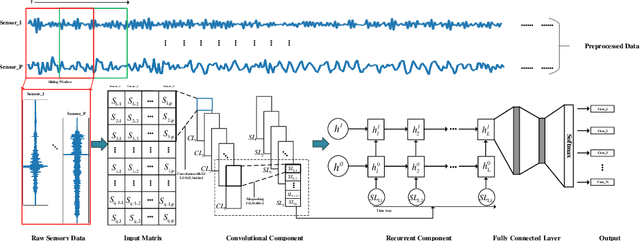

Structural damage detection has become an interdisciplinary area of interest for various engineering fields, while the available damage detection methods are being in the process of adapting machine learning concepts. Most machine learning based methods heavily depend on extracted ``hand-crafted" features that are manually selected in advance by domain experts and then, fixed. Recently, deep learning has demonstrated remarkable performance on traditional challenging tasks, such as image classification, object detection, etc., due to the powerful feature learning capabilities. This breakthrough has inspired researchers to explore deep learning techniques for structural damage detection problems. However, existing methods have considered either spatial relation (e.g., using convolutional neural network (CNN)) or temporal relation (e.g., using long short term memory network (LSTM)) only. In this work, we propose a novel Hierarchical CNN and Gated recurrent unit (GRU) framework to model both spatial and temporal relations, termed as HCG, for structural damage detection. Specifically, CNN is utilized to model the spatial relations and the short-term temporal dependencies among sensors, while the output features of CNN are fed into the GRU to learn the long-term temporal dependencies jointly. Extensive experiments on IASC-ASCE structural health monitoring benchmark and scale model of three-span continuous rigid frame bridge structure datasets have shown that our proposed HCG outperforms other existing methods for structural damage detection significantly.
Iteratively Optimized Patch Label Inference Network for Automatic Pavement Disease Detection
May 27, 2020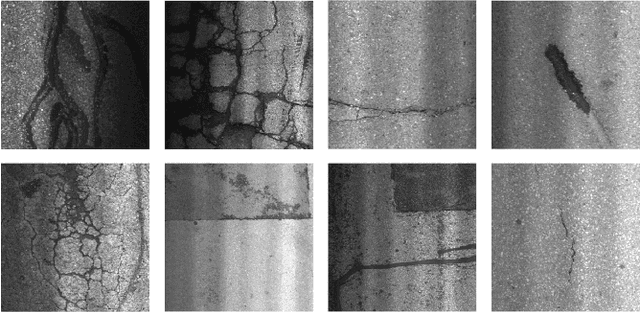
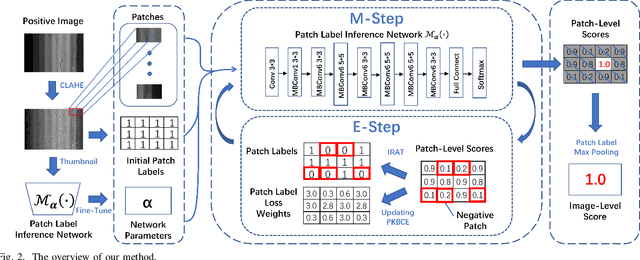
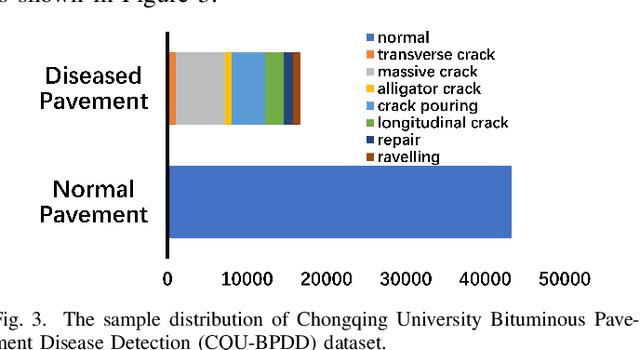
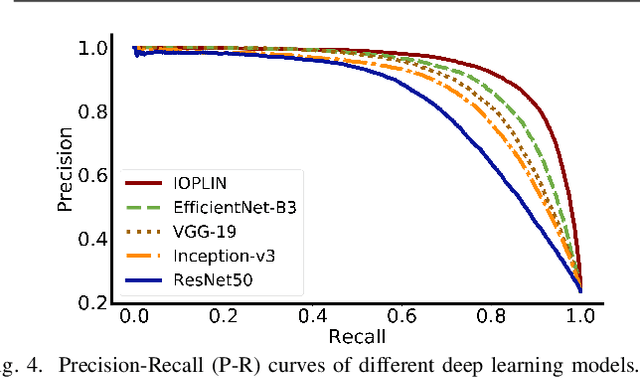
We present a novel deep learning framework named Iteratively Optimized Patch Label Inference Network (IOPLIN) for automatically detecting various pavement diseases not just limited to the specific ones, such as crack and pothole. IOPLIN can be iteratively trained with only the image label via using Expectation-Maximization Inspired Patch Label Distillation (EMIPLD) strategy, and accomplishes this task well by inferring the labels of patches from the pavement images. IOPLIN enjoys many desirable properties over the state-of-the-art single branch CNN models such as GoogLeNet and EfficientNet. It is able to handle any resolution of image and sufficiently utilize image information particularly for the high-resolution ones. Moreover, it can roughly localize the pavement distress without using any prior localization information in training phase. In order to better evaluate the effectiveness of our method in practice, we construct a large-scale Bituminous Pavement Disease Detection dataset named CQU-BPDD consists of 60059 high-resolution pavement images, which are acquired from different areas at different time. Extensive results on this dataset demonstrate the superiority of IOPLIN over the state-of-the-art image classificaiton approaches in automatic pavement disease detection.
Hierarchical Kinematic Human Mesh Recovery
Mar 09, 2020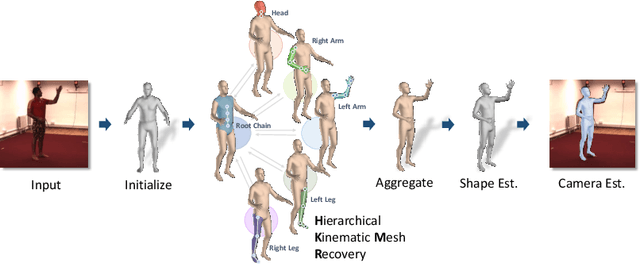
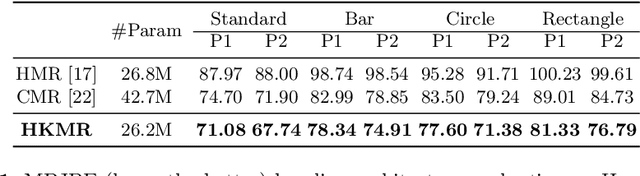
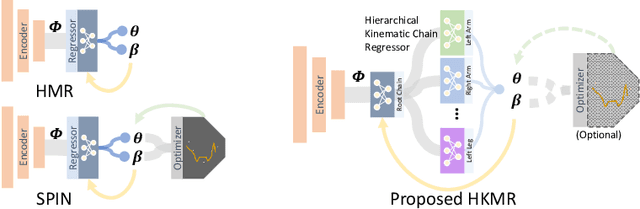

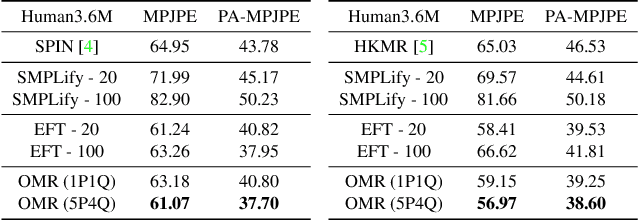
We consider the problem of estimating a parametric model of 3D human mesh from a single image. While there has been substantial recent progress in this area with direct regression of model parameters, these methods only implicitly exploit the human body kinematic structure, leading to sub-optimal use of the model prior. In this work, we address this gap by proposing a new technique for regression of human parametric model that is explicitly informed by the known hierarchical structure, including joint interdependencies of the model. This results in a strong prior-informed design of the regressor architecture and an associated hierarchical optimization that is flexible to be used in conjunction with the current standard frameworks for 3D human mesh recovery. We demonstrate these aspects by means of extensive experiments on standard benchmark datasets, showing how our proposed new design outperforms several existing and popular methods, establishing new state-of-the-art results. With our explicit consideration of joint interdependencies, our proposed method is equipped to infer joints even under data corruptions, which we demonstrate with experiments under varying degrees of occlusion.
DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery Detection
Jan 09, 2020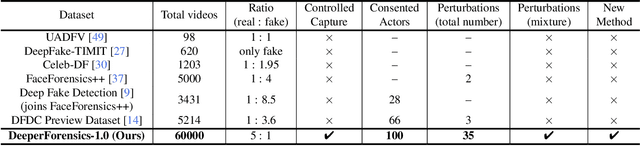
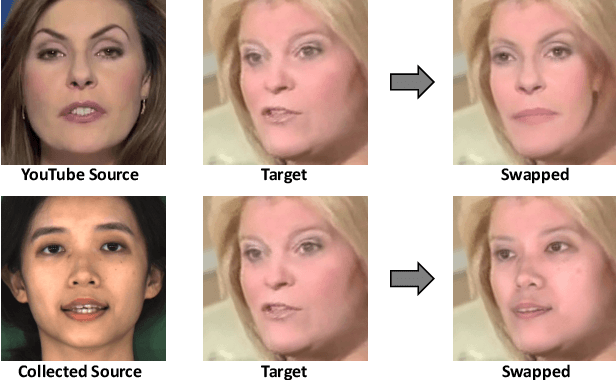


In this paper, we present our on-going effort of constructing a large-scale benchmark, DeeperForensics-1.0, for face forgery detection. Our benchmark represents the largest face forgery detection dataset by far, with 60, 000 videos constituted by a total of 17.6 million frames, 10 times larger than existing datasets of the same kind. Extensive real-world perturbations are applied to obtain a more challenging benchmark of larger scale and higher diversity. All source videos in DeeperForensics-1.0 are carefully collected, and fake videos are generated by a newly proposed end-to-end face swapping framework. The quality of generated videos outperforms those in existing datasets, validated by user studies. The benchmark features a hidden test set, which contains manipulated videos achieving high deceptive scores in human evaluations. We further contribute a comprehensive study that evaluates five representative detection baselines and make a thorough analysis of different settings. We believe this dataset will contribute to real-world face forgery detection research.
Towards Robust RGB-D Human Mesh Recovery
Nov 18, 2019
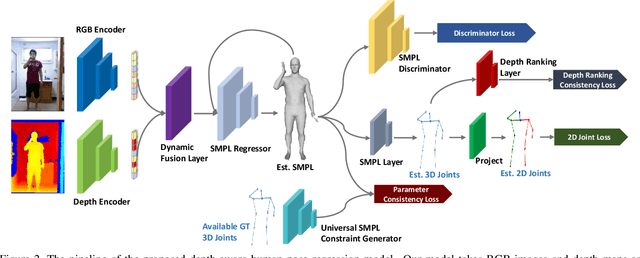
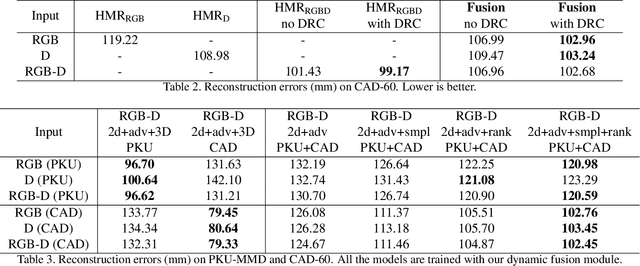
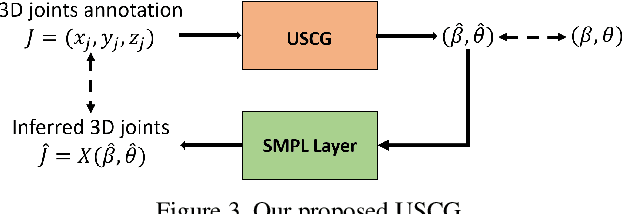
We consider the problem of human pose estimation. While much recent work has focused on the RGB domain, these techniques are inherently under-constrained since there can be many 3D configurations that explain the same 2D projection. To this end, we propose a new method that uses RGB-D data to estimate a parametric human mesh model. Our key innovations include (a) the design of a new dynamic data fusion module that facilitates learning with a combination of RGB-only and RGB-D datasets, (b) a new constraint generator module that provides SMPL supervisory signals when explicit SMPL annotations are not available, and (c) the design of a new depth ranking learning objective, all of which enable principled model training with RGB-D data. We conduct extensive experiments on a variety of RGB-D datasets to demonstrate efficacy.
Training on the test set? An analysis of Spampinato et al.
Dec 18, 2018
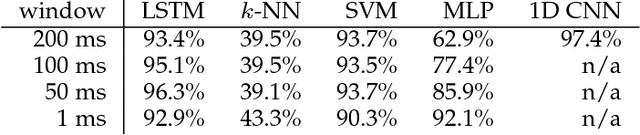
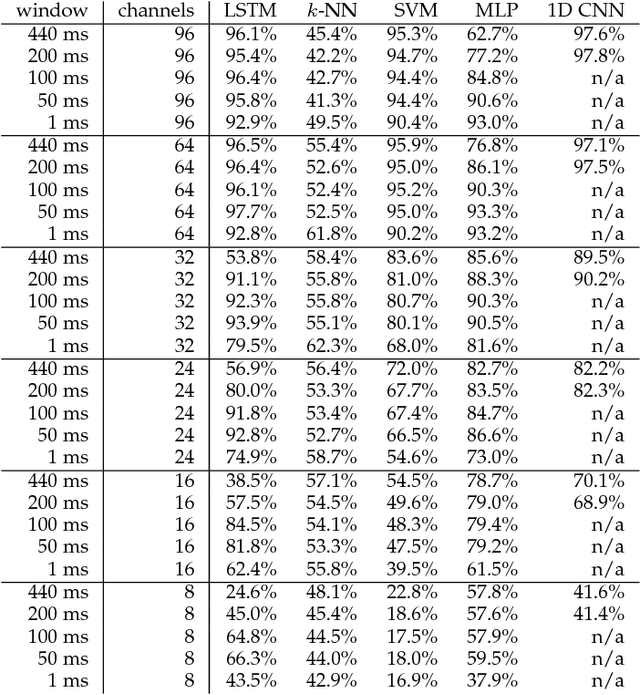
A recent paper [31] claims to classify brain processing evoked in subjects watching ImageNet stimuli as measured with EEG and to use a representation derived from this processing to create a novel object classifier. That paper, together with a series of subsequent papers [8, 15, 17, 20, 21, 30, 35], claims to revolutionize the field by achieving extremely successful results on several computer-vision tasks, including object classification, transfer learning, and generation of images depicting human perception and thought using brain-derived representations measured through EEG. Our novel experiments and analyses demonstrate that their results crucially depend on the block design that they use, where all stimuli of a given class are presented together, and fail with a rapid-event design, where stimuli of different classes are randomly intermixed. The block design leads to classification of arbitrary brain states based on block-level temporal correlations that tend to exist in all EEG data, rather than stimulus-related activity. Because every trial in their test sets comes from the same block as many trials in the corresponding training sets, their block design thus leads to surreptitiously training on the test set. This invalidates all subsequent analyses performed on this data in multiple published papers and calls into question all of the purported results. We further show that a novel object classifier constructed with a random codebook performs as well as or better than a novel object classifier constructed with the representation extracted from EEG data, suggesting that the performance of their classifier constructed with a representation extracted from EEG data does not benefit at all from the brain-derived representation. Our results calibrate the underlying difficulty of the tasks involved and caution against sensational and overly optimistic, but false, claims to the contrary.