 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining policy gradient and Q-learning
Apr 07, 2017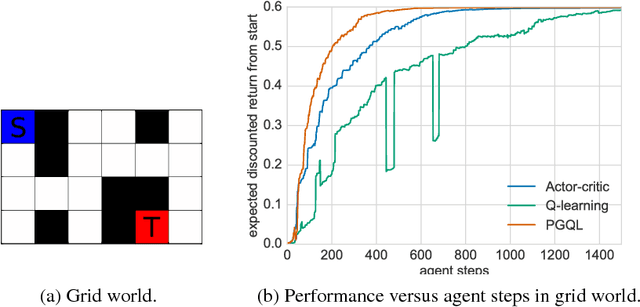
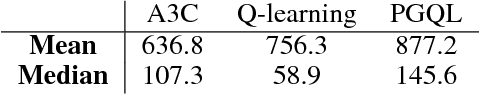
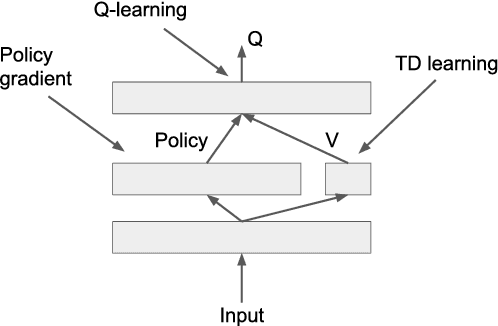
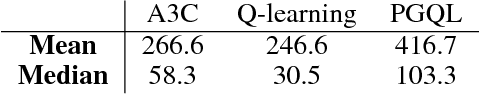
Policy gradient is an efficient technique for improving a policy in a reinforcement learning setting. However, vanilla online variants are on-policy only and not able to take advantage of off-policy data. In this paper we describe a new technique that combines policy gradient with off-policy Q-learning, drawing experience from a replay buffer. This is motivated by making a connection between the fixed points of the regularized policy gradient algorithm and the Q-values. This connection allows us to estimate the Q-values from the action preferences of the policy, to which we apply Q-learning updates. We refer to the new technique as 'PGQL', for policy gradient and Q-learning. We also establish an equivalency between action-value fitting techniques and actor-critic algorithms, showing that regularized policy gradient techniques can be interpreted as advantage function learning algorithms. We conclude with some numerical examples that demonstrate improved data efficiency and stability of PGQL. In particular, we tested PGQL on the full suite of Atari games and achieved performance exceeding that of both asynchronous advantage actor-critic (A3C) and Q-learning.
Learning to reinforcement learn
Jan 23, 2017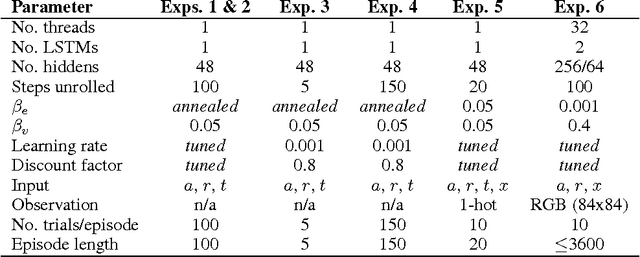
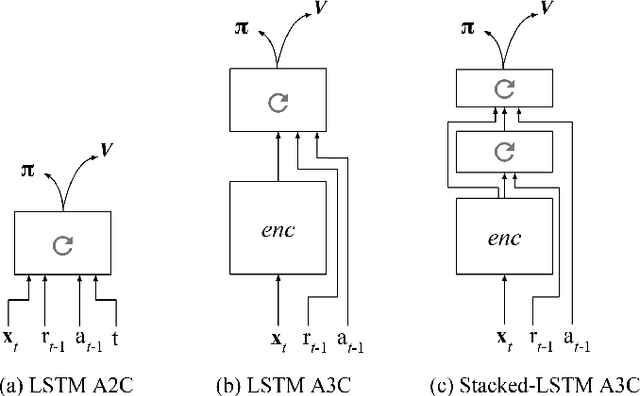
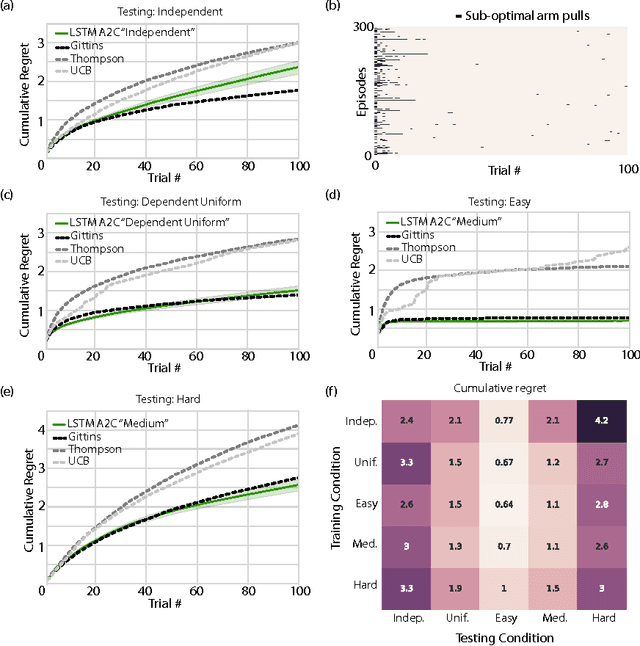
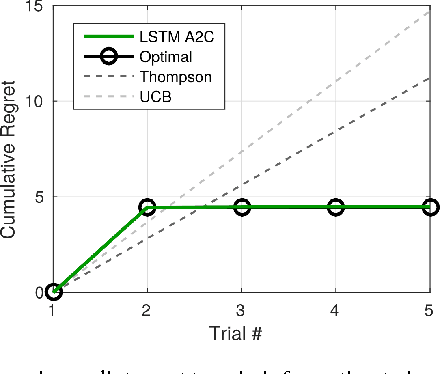
In recent years deep reinforcement learning (RL) systems have attained superhuman performance in a number of challenging task domains. However, a major limitation of such applications is their demand for massive amounts of training data. A critical present objective is thus to develop deep RL methods that can adapt rapidly to new tasks. In the present work we introduce a novel approach to this challenge, which we refer to as deep meta-reinforcement learning. Previous work has shown that recurrent networks can support meta-learning in a fully supervised context. We extend this approach to the RL setting. What emerges is a system that is trained using one RL algorithm, but whose recurrent dynamics implement a second, quite separate RL procedure. This second, learned RL algorithm can differ from the original one in arbitrary ways. Importantly, because it is learned, it is configured to exploit structure in the training domain. We unpack these points in a series of seven proof-of-concept experiments, each of which examines a key aspect of deep meta-RL. We consider prospects for extending and scaling up the approach, and also point out some potentially important implications for neuroscience.
Unifying Count-Based Exploration and Intrinsic Motivation
Nov 07, 2016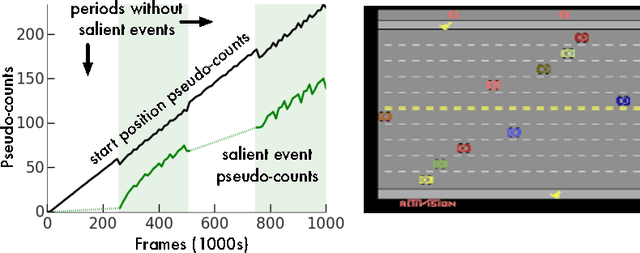
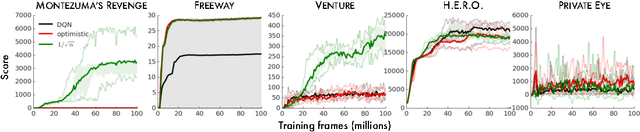

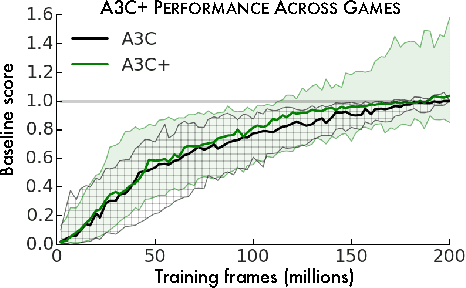
We consider an agent's uncertainty about its environment and the problem of generalizing this uncertainty across observations. Specifically, we focus on the problem of exploration in non-tabular reinforcement learning. Drawing inspiration from the intrinsic motivation literature, we use density models to measure uncertainty, and propose a novel algorithm for deriving a pseudo-count from an arbitrary density model. This technique enables us to generalize count-based exploration algorithms to the non-tabular case. We apply our ideas to Atari 2600 games, providing sensible pseudo-counts from raw pixels. We transform these pseudo-counts into intrinsic rewards and obtain significantly improved exploration in a number of hard games, including the infamously difficult Montezuma's Revenge.
Q($λ$) with Off-Policy Corrections
Aug 11, 2016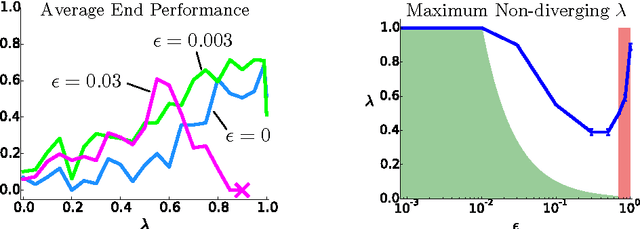
We propose and analyze an alternate approach to off-policy multi-step temporal difference learning, in which off-policy returns are corrected with the current Q-function in terms of rewards, rather than with the target policy in terms of transition probabilities. We prove that such approximate corrections are sufficient for off-policy convergence both in policy evaluation and control, provided certain conditions. These conditions relate the distance between the target and behavior policies, the eligibility trace parameter and the discount factor, and formalize an underlying tradeoff in off-policy TD($\lambda$). We illustrate this theoretical relationship empirically on a continuous-state control task.
Memory-Efficient Backpropagation Through Time
Jun 10, 2016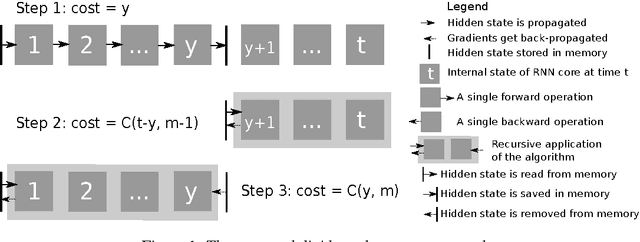
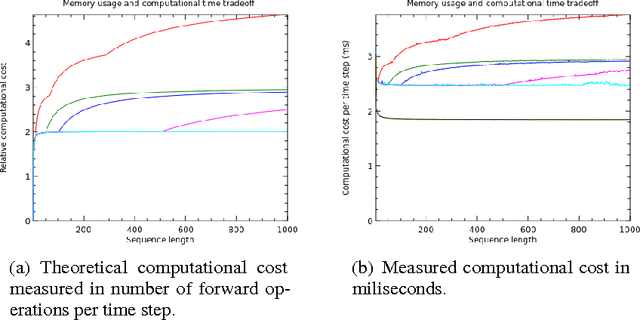
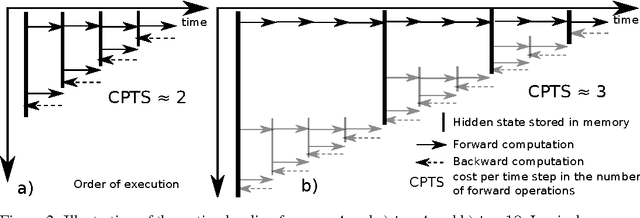
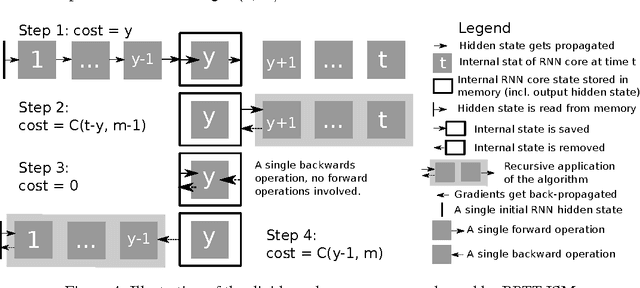
We propose a novel approach to reduce memory consumption of the backpropagation through time (BPTT) algorithm when training recurrent neural networks (RNNs). Our approach uses dynamic programming to balance a trade-off between caching of intermediate results and recomputation. The algorithm is capable of tightly fitting within almost any user-set memory budget while finding an optimal execution policy minimizing the computational cost. Computational devices have limited memory capacity and maximizing a computational performance given a fixed memory budget is a practical use-case. We provide asymptotic computational upper bounds for various regimes. The algorithm is particularly effective for long sequences. For sequences of length 1000, our algorithm saves 95\% of memory usage while using only one third more time per iteration than the standard BPTT.
Generalized Emphatic Temporal Difference Learning: Bias-Variance Analysis
Nov 27, 2015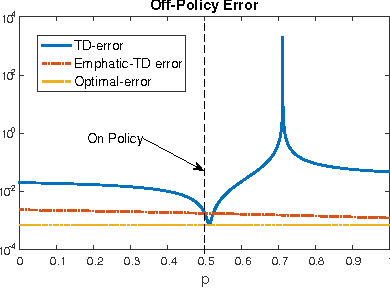
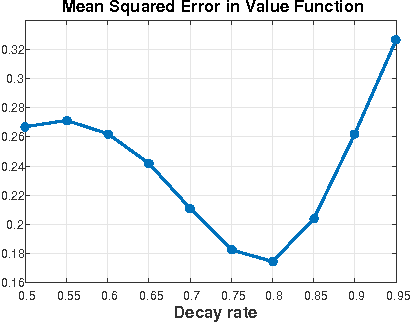
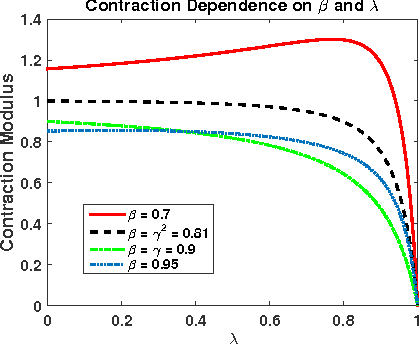
We consider the off-policy evaluation problem in Markov decision processes with function approximation. We propose a generalization of the recently introduced \emph{emphatic temporal differences} (ETD) algorithm \citep{SuttonMW15}, which encompasses the original ETD($\lambda$), as well as several other off-policy evaluation algorithms as special cases. We call this framework \ETD, where our introduced parameter $\beta$ controls the decay rate of an importance-sampling term. We study conditions under which the projected fixed-point equation underlying \ETD\ involves a contraction operator, allowing us to present the first asymptotic error bounds (bias) for \ETD. Our results show that the original ETD algorithm always involves a contraction operator, and its bias is bounded. Moreover, by controlling $\beta$, our proposed generalization allows trading-off bias for variance reduction, thereby achieving a lower total error.
Bounded Regret for Finite-Armed Structured Bandits
Nov 11, 2014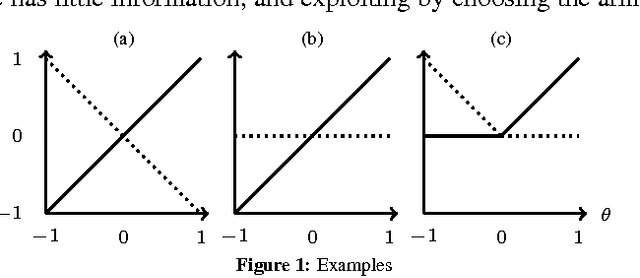
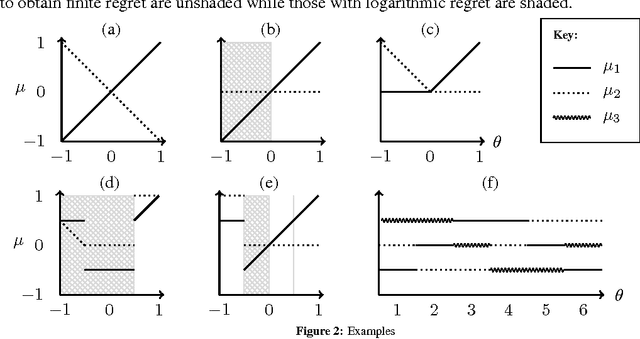
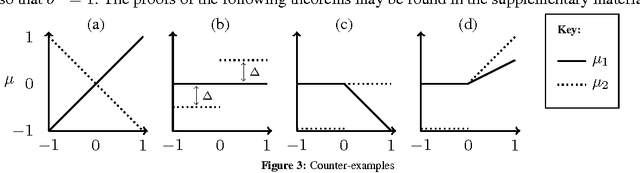
We study a new type of K-armed bandit problem where the expected return of one arm may depend on the returns of other arms. We present a new algorithm for this general class of problems and show that under certain circumstances it is possible to achieve finite expected cumulative regret. We also give problem-dependent lower bounds on the cumulative regret showing that at least in special cases the new algorithm is nearly optimal.
Active Regression by Stratification
Oct 22, 2014We propose a new active learning algorithm for parametric linear regression with random design. We provide finite sample convergence guarantees for general distributions in the misspecified model. This is the first active learner for this setting that provably can improve over passive learning. Unlike other learning settings (such as classification), in regression the passive learning rate of $O(1/\epsilon)$ cannot in general be improved upon. Nonetheless, the so-called `constant' in the rate of convergence, which is characterized by a distribution-dependent risk, can be improved in many cases. For a given distribution, achieving the optimal risk requires prior knowledge of the distribution. Following the stratification technique advocated in Monte-Carlo function integration, our active learner approaches the optimal risk using piecewise constant approximations.
On Minimax Optimal Offline Policy Evaluation
Sep 12, 2014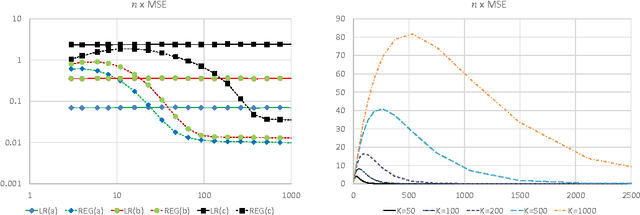
This paper studies the off-policy evaluation problem, where one aims to estimate the value of a target policy based on a sample of observations collected by another policy. We first consider the multi-armed bandit case, establish a minimax risk lower bound, and analyze the risk of two standard estimators. It is shown, and verified in simulation, that one is minimax optimal up to a constant, while another can be arbitrarily worse, despite its empirical success and popularity. The results are applied to related problems in contextual bandits and fixed-horizon Markov decision processes, and are also related to semi-supervised learning.
Bandit Algorithms for Tree Search
Aug 09, 2014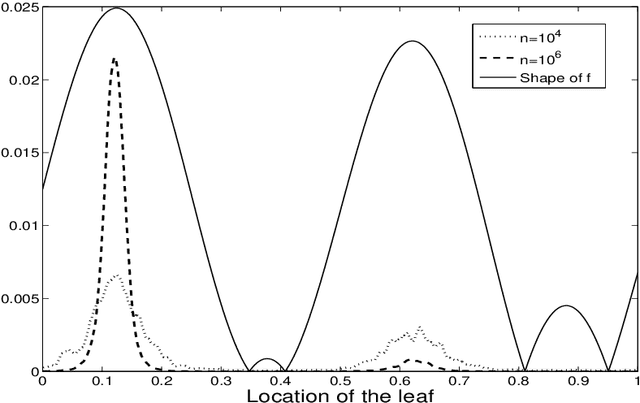
Bandit based methods for tree search have recently gained popularity when applied to huge trees, e.g. in the game of go [6]. Their efficient exploration of the tree enables to re- turn rapidly a good value, and improve preci- sion if more time is provided. The UCT algo- rithm [8], a tree search method based on Up- per Confidence Bounds (UCB) [2], is believed to adapt locally to the effective smoothness of the tree. However, we show that UCT is "over-optimistic" in some sense, leading to a worst-case regret that may be very poor. We propose alternative bandit algorithms for tree search. First, a modification of UCT us- ing a confidence sequence that scales expo- nentially in the horizon depth is analyzed. We then consider Flat-UCB performed on the leaves and provide a finite regret bound with high probability. Then, we introduce and analyze a Bandit Algorithm for Smooth Trees (BAST) which takes into account ac- tual smoothness of the rewards for perform- ing efficient "cuts" of sub-optimal branches with high confidence. Finally, we present an incremental tree expansion which applies when the full tree is too big (possibly in- finite) to be entirely represented and show that with high probability, only the optimal branches are indefinitely developed. We illus- trate these methods on a global optimization problem of a continuous function, given noisy values.