 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRedefining Research Crowdsourcing: Incorporating Human Feedback with LLM-Powered Digital Twins
May 29, 2025Crowd work platforms like Amazon Mechanical Turk and Prolific are vital for research, yet workers' growing use of generative AI tools poses challenges. Researchers face compromised data validity as AI responses replace authentic human behavior, while workers risk diminished roles as AI automates tasks. To address this, we propose a hybrid framework using digital twins, personalized AI models that emulate workers' behaviors and preferences while keeping humans in the loop. We evaluate our system with an experiment (n=88 crowd workers) and in-depth interviews with crowd workers (n=5) and social science researchers (n=4). Our results suggest that digital twins may enhance productivity and reduce decision fatigue while maintaining response quality. Both researchers and workers emphasized the importance of transparency, ethical data use, and worker agency. By automating repetitive tasks and preserving human engagement for nuanced ones, digital twins may help balance scalability with authenticity.
FareShare: A Tool for Labor Organizers to Estimate Lost Wages and Contest Arbitrary AI and Algorithmic Deactivations
May 13, 2025



What happens when a rideshare driver is suddenly locked out of the platform connecting them to riders, wages, and daily work? Deactivation-the abrupt removal of gig workers' platform access-typically occurs through arbitrary AI and algorithmic decisions with little explanation or recourse. This represents one of the most severe forms of algorithmic control and often devastates workers' financial stability. Recent U.S. state policies now mandate appeals processes and recovering compensation during the period of wrongful deactivation based on past earnings. Yet, labor organizers still lack effective tools to support these complex, error-prone workflows. We designed FareShare, a computational tool automating lost wage estimation for deactivated drivers, through a 6 month partnership with the State of Washington's largest rideshare labor union. Over the following 3 months, our field deployment of FareShare registered 178 account signups. We observed that the tool could reduce lost wage calculation time by over 95%, eliminate manual data entry errors, and enable legal teams to generate arbitration-ready reports more efficiently. Beyond these gains, the deployment also surfaced important socio-technical challenges around trust, consent, and tool adoption in high-stakes labor contexts.
RAVEN: Multitask Retrieval Augmented Vision-Language Learning
Jun 27, 2024



The scaling of large language models to encode all the world's knowledge in model parameters is unsustainable and has exacerbated resource barriers. Retrieval-Augmented Generation (RAG) presents a potential solution, yet its application to vision-language models (VLMs) is under explored. Existing methods focus on models designed for single tasks. Furthermore, they're limited by the need for resource intensive pre training, additional parameter requirements, unaddressed modality prioritization and lack of clear benefit over non-retrieval baselines. This paper introduces RAVEN, a multitask retrieval augmented VLM framework that enhances base VLMs through efficient, task specific fine-tuning. By integrating retrieval augmented samples without the need for additional retrieval-specific parameters, we show that the model acquires retrieval properties that are effective across multiple tasks. Our results and extensive ablations across retrieved modalities for the image captioning and VQA tasks indicate significant performance improvements compared to non retrieved baselines +1 CIDEr on MSCOCO, +4 CIDEr on NoCaps and nearly a +3\% accuracy on specific VQA question types. This underscores the efficacy of applying RAG approaches to VLMs, marking a stride toward more efficient and accessible multimodal learning.
QuaLLM: An LLM-based Framework to Extract Quantitative Insights from Online Forums
May 08, 2024



Online discussion forums provide crucial data to understand the concerns of a wide range of real-world communities. However, the typical qualitative and quantitative methods used to analyze those data, such as thematic analysis and topic modeling, are infeasible to scale or require significant human effort to translate outputs to human readable forms. This study introduces QuaLLM, a novel LLM-based framework to analyze and extract quantitative insights from text data on online forums. The framework consists of a novel prompting methodology and evaluation strategy. We applied this framework to analyze over one million comments from two Reddit's rideshare worker communities, marking the largest study of its type. We uncover significant worker concerns regarding AI and algorithmic platform decisions, responding to regulatory calls about worker insights. In short, our work sets a new precedent for AI-assisted quantitative data analysis to surface concerns from online forums.
A First Look: Towards Explainable TextVQA Models via Visual and Textual Explanations
Apr 29, 2021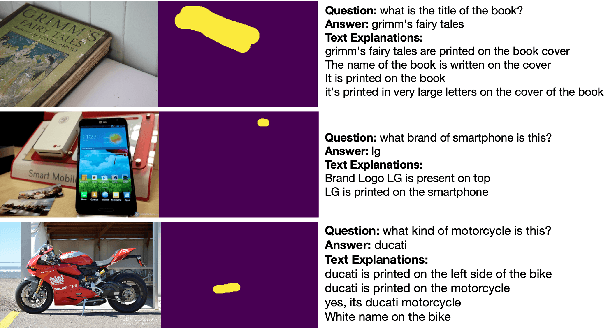
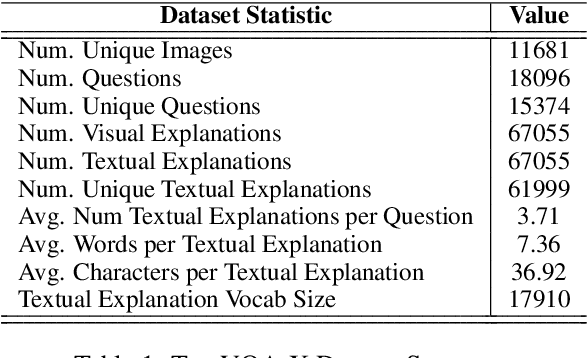
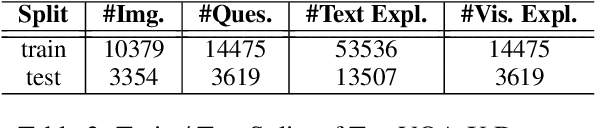
Explainable deep learning models are advantageous in many situations. Prior work mostly provide unimodal explanations through post-hoc approaches not part of the original system design. Explanation mechanisms also ignore useful textual information present in images. In this paper, we propose MTXNet, an end-to-end trainable multimodal architecture to generate multimodal explanations, which focuses on the text in the image. We curate a novel dataset TextVQA-X, containing ground truth visual and multi-reference textual explanations that can be leveraged during both training and evaluation. We then quantitatively show that training with multimodal explanations complements model performance and surpasses unimodal baselines by up to 7% in CIDEr scores and 2% in IoU. More importantly, we demonstrate that the multimodal explanations are consistent with human interpretations, help justify the models' decision, and provide useful insights to help diagnose an incorrect prediction. Finally, we describe a real-world e-commerce application for using the generated multimodal explanations.